優(yōu)化的鄰近支持向量機在圖像檢索中的應用
2014-07-02 00:20:47王華秋王斌
重慶理工大學學報(自然科學) 2014年9期
關鍵詞:分類
王華秋,王斌
(重慶理工大學計算機科學與工程學院,重慶 400054)
優(yōu)化的鄰近支持向量機在圖像檢索中的應用
王華秋,王斌
(重慶理工大學計算機科學與工程學院,重慶 400054)
鄰近支持向量機由支持向量機衍生而來,它將支持向量機中二次規(guī)劃問題的求解轉換為線性方程組的求解,從而能在保證一定精度的情況下更加快速地得到分類器。傳統(tǒng)的非線性核鄰近支持向量機不能很好地解決多范圍數據的多分類問題。提出了一種鄰近支持向量機的優(yōu)化方法,并將其應用到圖像檢索中。它利用高斯函數將圖像特征數據映射到0~1之間以提高其差異化水平,并將其放入非線性核中,然后以加權K-means聚類算法選擇最優(yōu)參數,從而提高了非線性核PSVM的分類能力。實驗以coral圖像庫中的4類圖片作為圖片庫,對比了優(yōu)化前后的檢索命中率。實驗結果表明:優(yōu)化后的檢索效果優(yōu)于優(yōu)化前,說明將優(yōu)化的鄰近支持向量機應用于圖像檢索是有效的。
優(yōu)化的鄰近支持向量機;圖像檢索;高斯函數;加權聚類算法
SVM最初于20世紀90年代由Vapnik提出,它能夠很好地解決小樣本、非線性、高維模式識別問題,在解決“維數災難”和“過學習”等傳統(tǒng)困難問題方面表現相當出色[1-5]。但是SVM需要求解二次規(guī)劃問題,訓練時間較長。Fung和Mangasarian[6]于2001年在支持向量機的基礎上提出了鄰近支持向量(PSVM)這一概念,將支持向量機中的二次規(guī)劃問題的求解轉換為線性方程組的求解,因此該方法能夠在基本不損失精度的情況下提高學習速度。近年來,鄰近支持向量機在理論研究和算法實現方面都取得了突破性進展。2005年,莊東和陳英[7]將加權的鄰近支持向量機應用于文本分類,提高了PSVM對不平衡數據的處理能力,實驗結果證明該方法優(yōu)于傳統(tǒng)的SVM。2006年,Mangasarian和Wild[8]提出通過求解樣本矩陣特征值的方法構造分類超平PSVM,有效解決了交叉數據的二分類問題。2008年,張曦、閻威武等[9]將小波去噪核主元分析和鄰近支持向量機結合起來用于性能監(jiān)控和故障診斷,具有較好的監(jiān)控效果,并提出了核函數及其參數的選擇對診斷結果準確性具有較大的影響的結論。2012年,王至超、張化祥等[10]在GEPSVM的基礎上提出了最值間距支持向量機(TDMSVM),通過計算得到2個最優(yōu)超平面,使超平面滿足到本類樣例的平均距離最小,同時到另一類樣例的平均距離最大,進一步降低了時間復雜度。同年,魯淑霞等[11]提出了增量密度加權鄰近支持向量機,有效控制了鄰近支持向量機的稀疏性。
本文以coral圖像庫中4種類型的圖片作為圖片庫,在提取圖片特征時以每張圖片的灰度共生矩陣量化出來的4個標量作為特征值,在構造分類器時,每張圖片為一類。由于不同類型的圖片量化出的特征值所處范圍不同,而同類型圖片量化出的特征值較為接近,所以在使用統(tǒng)一的非線性核PSVM對這些圖片進行分類時往往出現部分類型的圖片分類效果較好,而另一部分分類效果差的情況,導致平均檢索命中率較低。為解決該問題,本文對PSVM算法進行了優(yōu)化。首先引入高斯函數將所有圖片的特征值映射到0~1內,使特征值差異化分布。結合數據挖掘技術[12],使用加權K-means聚類算法將指定范圍內的參數及其對應的檢索命中率進行聚類,并以檢索命中率最高的類中心所對應的參數作為最優(yōu)參數。實驗結果表明優(yōu)化后的鄰近支持向量機具有較好的多分類效果。
1 PSVM算法及優(yōu)化方法
1.1 PSVM算法
PSVM的基本原理是將每個點歸類于2個盡可能遠的平行平面中最接近的一個。該問題可以歸結為

式(1)、(2)中:A∈Rm×n是m個n維的特征矩陣,v為懲罰因子;e為單位列向量;D是m×m的對角矩陣,其對角線上每一行的值對應A中樣本所屬的類別1或-1,其余元素為0。其解由拉格朗日泛函:

的梯度置零獲得。
ui為拉格朗日乘子。對wi,γi,yi,ui求導并令其等于0,可以得到如下4個矩陣式表達式:

由上述4個式子可以得到:

將式(8)~(10)代入式(7)得

將式(11)代入(8)、(9)中得到w,γ。
為了得到非線性分類器,需要把線性分類器中的變量w用其對偶等價w=ATDu替換,并將線性核AAT替換為非線性核k(A,AT),即

滿足約束:

其中:k(A,AT)=(AAT+c)d;c為大于等于0的常數;d原定義為任意正整數,本文將其定義為大于等于0的常數。當c>0時,該核為非齊次多項式核;當c=0時,為齊次多項式核。
在使用線性分類器對新樣本進行分類時,通過wTx-γ的符號來確定該樣本屬于哪一類。在使用非線性分類器對新樣本進行分類時,則通過K(xT,AT)u-γ的符號來確定。在優(yōu)化的PSVM中特征矩陣A中的值Aij=Gauss(Aij),其中Gauss(Aij)表示經過高斯函數處理過的特征值。
1.2 PSVM優(yōu)化方法
1.2.1 最優(yōu)參數選擇
用于訓練的特征值是線性不可分的,這里使用非線性核k(A,AT)=(AAT+c)d。在非線性核中包含2個參數c,d,為了得到更高的檢索命中率,c,d的確定至關重要。
為了得到較優(yōu)的參數c和d,首先獲取在c∈[0,8],d∈[0,8]的范圍內以0.2為梯度的所有參數下的檢索命中率。在候選集合中假設c=ci,d= di所對應的平均檢索命中率為Si,然后用加權K- means聚類算法將三維向量(ci,di,Si)進行聚類,在計算樣本之間相似度時使用了加權的歐氏距離,其中賦予Si較高的權值。

這樣就得到了高檢索命中率所對應參數的集中分布情況,有效地區(qū)分了距離較近但命中率差距較大的數據。所有類中心中Si最大的中心所對應的c,d值能在一定程度上代表檢索命中率最高的參數,本文稱之為最優(yōu)參數。
1.2.2 特征值預處理
由于使用非線性核的鄰近支持向量機不能很好地解決多范圍數據的多分類問題,為了減少誤差,引入高斯函數:

式(15)中:z為比較中心;σ為函數的寬度參數,其值根據訓練特征值及相對差距而定。其中,接近z的特征值在處理過后更接近1,與z差距稍大的更接近于0,σ用來控制相對差距。這樣可以將特征值差異化的分布在0~1之間。該方法不僅能起到擴大類與類之間特征值相對差距的作用,而且可規(guī)范化數據,將所有特征值映射到0~1,從而提高各類圖片的檢索命中率。
1.2.3 多分類PSVM
由于二分類的鄰近支持向量機往往不能滿足圖像檢索的需求,所以本文引入多分類的鄰近支持向量機。
多分類鄰近支持向量機同樣基于二分類鄰近支持向量機,目前常用的有以下兩種:
算法11-a-1(one against one)[10]:假設有n類樣本,每兩類樣本構造一個分類器,則該方法需要構造n(n-1)/2種分類器。
算法21-a-r(one against rest)[11]:假設有n類樣本,則該方法構造n個PSVM分類器w,第k個分類器在訓練時將第k類定為1,其余的定為-1。
考慮到1-a-r法在類別數較多的情況下會出現正負樣本不均衡的情況,本文采用1-a-1多分類方法,這樣就有2種對新樣本分類的決策方法:投票算法、有向無環(huán)圖算法。
2 圖像檢索流程設計
圖像檢索的一般方法是首先將檢索范圍內的圖片特征進行提取并存儲,再將檢索樣本的特征提取出來與檢索范圍內圖片特征進行相似性比對,將相似性最高的圖片返回給用戶[13]。本文將多分類的鄰近支持向量機用于圖像檢索,不僅要提取圖像的特征信息,還要對這些特征進行分類訓練,得到若干分類器。當對新樣本進行分類決策時,則用每個分類器對新樣本進行分類決策,最終根據決策算法得出新樣本所屬類別[14-15]。具體過程如圖1所示。
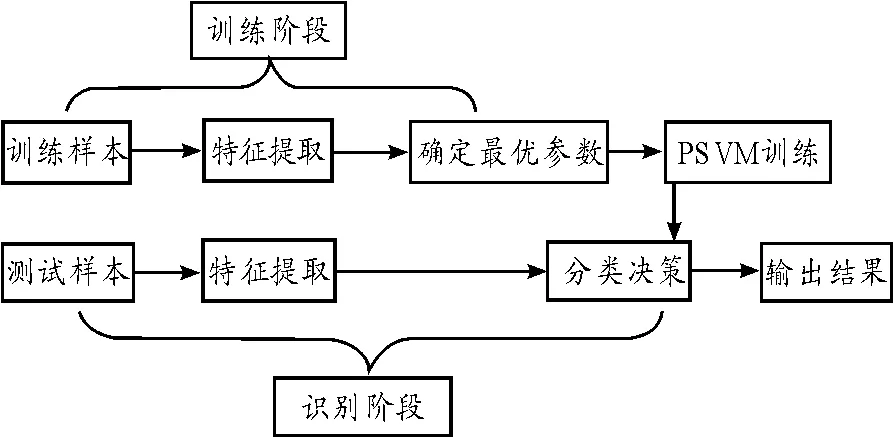
圖1 圖像識別流程
3 圖像特征獲取方法
由于紋理可以通過研究灰度的空間相關特性來描述[16],因此本文主要以灰度共生矩陣的方法來獲取圖片的紋理特征。
灰度共生矩陣是對圖像上保持距離d的兩像素分別具有某灰度的狀況進行統(tǒng)計得到的。在得到灰度共生矩陣之前首先要將RGB圖轉換為灰度圖,轉換公式如下:

得到灰度值后為了減少計算量,需要將灰度值(0~255)轉換為灰度級(0~15)共16級。

假設圖片共有M×N個像素點,從某像素點(x,y)開始該像素點的灰度級為i,灰度共生矩陣即統(tǒng)計與其在方向角為θ,距離為d,灰度級為j的像素點同時出現的概率。假設f(xm,xn)為像素點(xm,xn)所對應的灰度級,Count(M)表示M情況出現的次數,由此可將灰度共生矩陣的獲取方法概括如下:

為了更直觀地反映紋理的特征,可以根據灰度共生矩陣得出一些標量來表征灰度共生矩陣的特征。下面是用到的幾種特征值:①能量特征;②對比度;③逆差距;④熵。本文所用的方法是取以上4個特征值分別在θ=0°,θ=45°,θ=90°,θ= 135°的值作為訓練集,在對新樣本進行分類決策時以新樣本4個方向上各特征值的平均值作為特征向量。
4 實驗過程及結果
4.1 實驗環(huán)境
本實驗取Coral圖片庫中的100張恐龍類圖片、100張花類圖片、100張汽車圖片、100張馬圖片共400張圖片作為圖片庫。實驗在WIN7操作系統(tǒng)下進行,使用Visual Studio 2010開發(fā)環(huán)境進行圖像檢索系統(tǒng)的設計。實驗的硬件環(huán)境為:CPU為Intel酷睿2,2.2 GHz雙核處理器;內存為2 G。
4.2 實驗方法及結果
首先,對圖片庫中所有圖片的特征進行提取,并計算出每張圖片所生成的灰度共生矩陣量化出來的4個標量。
然后,從每類圖片中隨機抽取10張作為圖片庫進行先驗性測試實驗,獲取各類圖片在c∈[0,8],d∈[0,8]的范圍內以0.2為梯度的所有參數對應的檢索命中率。所有圖片在引入高斯函數前后各參數的平均檢索命中率等值線如圖2、3所示。

圖2 處理前平均檢索命中率等值線

圖3 處理后平均檢索命中率等值線
圖2、3中:x軸代表非線性核(AAT+c)d中參數c的值;y軸代表參數d的值。等值線所代表的檢索命中率從外向內依次遞增。對比圖2、3發(fā)現,引入高斯函數后的檢索命中率較高的參數的范圍明顯大于引入前。
得到各參數對應的檢索命中率后,根據參數值及其對應的檢索命中率利用加權的K-means算法進行聚類,以得到最優(yōu)參數。
各類圖片在使用最優(yōu)參數的PSVM分類后的檢索命中率如圖4所示。

圖4 最優(yōu)函數下檢索命中率(全部樣本)
從圖4的結果可以看出,引入高斯函數的鄰近支持向量機的檢索效果要優(yōu)于引入前。
表1、2給出了引入高斯函數前后最優(yōu)參數(各表中第1行參數)與最優(yōu)參數附近參數所對應的檢索命中率。對比后發(fā)現,最優(yōu)參數雖然在某一類中的檢索命中率不是最高,但具有最高的平均檢索命中率,能夠較好地滿足各類圖片的需求。

表1 引入高斯函數前檢索命中率對比(全部樣本)

表2 引入高斯函數后檢索命中率對比(全部樣本)
在核函數k(A,AT)=(AAT+c)d中,c值對檢索命中率的影響較小,d值影響較大,且在引入高斯函數前,選取的參數略大或略小都會較大幅度地降低檢索命中率。而在引入高斯函數后,當d略小時,對檢索命中率的影響較小。對照圖2、3不難發(fā)現其原因:引入高斯函數前,檢索命中率的坡度在d值增加和減少方向均較大,而在引入高斯函數后,檢索命中率的坡度在d值增加方向較大,在減小方向較小。因此,引入高斯函數很好地擴大了非線性核鄰近支持向量機較優(yōu)參數的范圍,從而提高了非線性核鄰近支持向量機在多分類時的分類效果。
5 結束語
本文對鄰近支持向量機進行了一系列的優(yōu)化并將其應用到圖像檢索中。實驗結果表明優(yōu)化后的PSVM具有更好的多分類效果,將多分類鄰近支持向量機應用于圖像檢索中是有效可行的。
但該方法仍然存在一定的局限性。例如,該算法在數據量較小時表現較為出色,具有較高的檢索命中率,但當數據量變大時,各類圖片的檢索命中率均出現一定程度的降低,且部分類型圖片的檢索命中率下降明顯。這說明該方法對于圖像檢索還不具有普適性。所以若將該方法廣泛應用于圖像檢索領域還有很多地方需要改進,如核函數的選取及優(yōu)化,分類及決策算法的優(yōu)化、選取更加適合于該方法的特征提取算法等。下一步的研究工作將主要圍繞改進PSVM的核函數和獲取更適合于該方法的圖像特征兩個方向展開。
[1]丁世飛,齊丙娟,譚紅艷.支持向量機理論與算法研究綜述.電子科技大學學報.2011.40(1):2-7.
[2]余珺,鄭先斌,張小海.基于多核優(yōu)選的裝備費用支持向量機預測法[J].四川兵工學報,2011(6):118-119.
[3]萬輝.一種基于最小二乘支持向量機的圖像增強算法[J].重慶理工大學學報:自然科學版,2011(6):53-57.
[4]鄔嘯,魏延,吳瑕.基于混合核函數的支持向量機[J].重慶理工大學學報:自然科學版,2011(10):66-70.
[5]崔建國,李明,陳希成.基于支持向量機的飛行器健康診斷方法[J].壓電與聲光,2009(2):266-269.
[6]Fung G,Mangasarian O L.Proximal Support Vector Machine Classifiers[C]//Knowledge Discovery and Data Mining.New York:Association for Computing Machinery,2001:77-86.
[7]莊東,陳英.基于加權近似支持向量機的文本分類[J].清華大學學報:自然科學版,2005,45(S1):1787-1790.
[8]Mangasarian O L,Wild EW.Multisurface Proximal Support Vector Machine Classification Via Generalized Eigenvalues[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2006,28:69-74.
[9]張曦,閻威武,趙旭,等.基于小波去噪核主元分析和鄰近支持向量機的性能監(jiān)控和故障診斷[J].上海交通大學學報,2008,48(2):181-185.
[10]王至超,張化祥.最值支持向量機[J].計算機科學,2012.39(4):205-209.
[11]魯淑霞,崔芳芳,忽麗莎.增量密度加權近似支持向量機[J].計算機科學,2012,39(11):194-197.
[12]Han Jiawei.Data Mining:Concepts and Techniques,Third Edition[M].Morgan Kaufmann Press,2011.
[13]劉穎,范九倫.基于內容的圖像檢索技術綜述[J].西安郵電學院學報,2012,17(2):1-8.
[14]Glenn Fung,Olvi LMangasarian.Proximal Support Vector Machine Classifiers,proceeding,KKD,2001(8):77-86.
[15]Hsu CW,Lin C J.A comparison ofmethods for multiclass support vector machines[J].PPIEEE Transactions on Neural Networks,2002,13(2):415-425.
[16]劉舒,姜琦剛,邵永社,等.應用灰度共生矩陣的紋理特征描述的研究[J].科學技術與工程,2012.12(33): 8909-8914.
(責任編輯 楊黎麗)
Application of Optim ized Proximal Support Vector Machine in Image Retrieval
WANG Hua-qiu,WANG Bin
(College of Computer Science and Engineering,Chongqing University of Technology,Chongqing 400054,China)
Proximal support vectormachine(PSVM)is derived from support vectormachine(SVM) and converts the quadratic programming problem into linear equations,so that it can ensure the classifiermore quickly under the condition of certain precision.The multi-class classification problem of multi range data can notbe solved well by the original nonlinear kernel PSVM.This paper presents an optimization method for PSVM,and applied the optimized algorithm to image retrieval.The Gauss function is used to image feature datamap to the range of0~1 to enhance their difference level,then the different data is put into nonlinear kernel function,finally weighted K-means clustering algorithmis used to select the optimal parameters of PSVM.Experiments are carried out on 4 types of images from coral image database as the picture library,and the hit rate is compared between the original PSVMand the optimized algorithm.Experiments show that the performance of optimized PSVMis better than original algorithm,and it is effective to use the optimized PSVMinto image retrieval.
optimized proximal support vectormachine;image retrieval;Gauss function;weighted clustering algorithm
TP391
A
1674-8425(2014)09-0066-06
10.3969/j.issn.1674-8425(z).2014.09.015
2014-01-07
教育部科學研究青年基金資助項目(10YJC870037);國家社會科學基金資助項目(14BTQ053)
王華秋(1975—),男,博士,教授,主要從事數據挖掘和智能控制研究;王斌(1991—),男,碩士研究生,主要從事數據挖掘研究。
王華秋,王斌.優(yōu)化的鄰近支持向量機在圖像檢索中的應用[J].重慶理工大學學報:自然科學版,2014 (9):66-71.
format:WANG Hua-qiu,WANG Bin.Application ofOptimized Proximal Support VectorMachine in Image Retrieval[J].Journal of Chongqing University of Technology:Natural Science,2014(9):66-71.
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
