一種面向不確定圖的SimRank算法
2014-06-15 17:06:24董宇欣王瑩潔寧鵬飛張耀元
哈爾濱工程大學學報 2014年11期
關鍵詞:搜索引擎
董宇欣,王瑩潔,寧鵬飛,張耀元
(哈爾濱工程大學計算機科學與技術學院,黑龍江哈爾濱150001)
一種面向不確定圖的SimRank算法
董宇欣,王瑩潔,寧鵬飛,張耀元
(哈爾濱工程大學計算機科學與技術學院,黑龍江哈爾濱150001)
針對以往的搜索引擎日志分析都主要集中在用戶行為分析、查詢推薦及搜索引擎評價等方面,采用社會網(wǎng)絡分析法對搜索引擎進行日志分析。以不確定圖的方式邏輯表示搜索引擎的日志中查詢詞和網(wǎng)頁的鏈接關系,通過基于不確定圖的SimRank算法,計算查詢詞與網(wǎng)頁的相似度,最終以相似度和查詢詞的加權方式建立網(wǎng)頁描述庫。針對概率抽樣的3點基本要求,提出一種漸進式的抽樣策略,從而保證采用抽樣技術對于不確定圖中SimRank值計算的準確性。實驗表明該算法具有較好的準確率和可行性。
搜索引擎;社會網(wǎng)絡;不確定圖;SimRank;相似度;抽樣策略
傳統(tǒng)搜索引擎在商用過程中,都設計一套日志系統(tǒng),記錄下用戶在搜索引擎上的使用信息。用戶每進行一次查詢及在查詢結果中的瀏覽信息,日志系統(tǒng)會將用戶查詢詞、點擊URL、用戶ID、查詢時間、瀏覽時間等信息記錄下來。搜索引擎的長期運行,使得日志文件中記錄信息極為豐富,龐大的日志信息量背后蘊藏著很多知識、經(jīng)驗及用戶行為。
關于社會化排序算法,多數(shù)研究是利用社會網(wǎng)絡中的社會標注改進搜索引擎排序結果。Hotho等[1]提出的FolkRank算法是面向社會標注系統(tǒng)的網(wǎng)頁排序,社會標注系統(tǒng)在該算法中被視作用戶、資源和標簽三元集合關系圖,是對PageRank算法的一種改進。包勝華等[2]提出了利用社會標注計算用戶、網(wǎng)頁及標注間的相似度排序算法SSR和標注網(wǎng)頁排序算法SPR,這種算法類似于SimRank算法的相似傳播矩陣迭代計算。劉凱鵬等[3]提出一種基于社會性標注的網(wǎng)頁排序算法,這是一種有機結合網(wǎng)頁和用戶的查詢相關性與互增強關系的網(wǎng)頁排序算法。微軟的研究人員Liu等[4],提出一種BrowseRank算法,以日志中所記錄的用戶的搜索行為來計算網(wǎng)頁權重,融入了社會網(wǎng)絡中用戶的參與。
針對以往的搜索引擎日志分析都主要集中在用戶行為分析、查詢推薦及搜索引擎評價等方面,本文采用社會網(wǎng)絡分析法對搜索引擎進行日志分析,以不確定圖的方式邏輯表示搜索引擎的日志中查詢詞和網(wǎng)頁的鏈接關系,通過基于不確定圖的SimRank算法,計算查詢詞與網(wǎng)頁的相似度,最終以相似度和查詢詞的加權方式建立網(wǎng)頁描述庫。此外,針對概率抽樣的三點基本要求,論文提出一種漸進式的抽樣策略,從而保證采用抽樣技術對于不確定圖中SimRank值計算的準確性。
1 日志數(shù)據(jù)的邏輯表示
搜索引擎用戶在進行一次查詢請求時,會在搜索結果中主動篩選出自己認為內容相關的網(wǎng)頁進行瀏覽,搜索引擎的設計者會將這些查詢?yōu)g覽信息記錄下來保存到日志文件當中。
搜索引擎日志文件中一般包括用戶ID、搜索時間、查詢關鍵詞、用戶所點擊的鏈接URL、該鏈接在返回結果中的排名等信息[5]。日志中蘊藏著豐富的用戶興趣、群體發(fā)現(xiàn)、行為評價等信息,需要采用多種手段進行日志挖掘,這都為搜索引擎的演化改進提供了有力的支撐[5-7]。
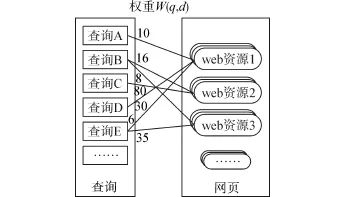
圖1 搜索引擎日志二部圖Fig.1 Bigraph of search engine log
如圖1所示為搜索引擎日志二部圖。本文處理搜索引擎日志,剔除多余內容,只保留查詢關鍵詞與網(wǎng)頁鏈接兩部分內容。同時,根據(jù)日志中兩項的對應關系建立查詢詞到網(wǎng)頁的鏈接關系,鏈接上標注對應關系出現(xiàn)的次數(shù)。
圖1中搜索引擎日志二部圖就是一個不確定圖,本文采用不確定圖刻畫搜索引擎日志,下面介紹不確定圖。
不確定圖一般由3個要素組成,圖中的節(jié)點、邊以及邊存在的概率。形式化表示就是G=<V,E,P>,其中G代表不確定圖,V和E代表圖中結點和邊的集合,概率函數(shù)P代表圖中2個節(jié)點存在連接的概率。對于不確定圖G的每一條邊,其存在的概率是p(e),不存在的概率是1-p(e),則P(g)=表示不確定圖一部分節(jié)點存在,另一部分節(jié)點不存在派生的新圖g的概率,圖g叫做不確定圖G所對應的確定圖,也叫做不確定圖的可能世界。
不確定圖G中的邊的關聯(lián)概率函數(shù)P,由圖1搜索引擎日志二部圖中的邊的權重W(q,d)通過歸一化處理計算得到。連接關鍵詞qi和網(wǎng)頁dj的邊的存在概率為
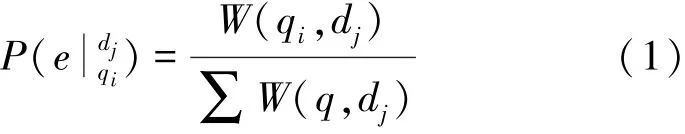
此外,本文通過社會網(wǎng)絡分析法進行日志挖掘獲取網(wǎng)頁理想關鍵詞的一個構想。分析搜索引擎觀點、用戶觀點、關鍵詞流行度這3部分內容,正是根據(jù)長尾理論的思想挖掘日志文件中網(wǎng)頁的理想關鍵詞[8]。其中,搜索引擎觀點是通過WEB爬蟲爬取網(wǎng)頁HTML文件中的關鍵詞標簽內容得到,用戶觀點由在日志文件的一條查詢記錄得到體現(xiàn),關鍵詞的流行度可通過日志文件的邏輯圖描述方法統(tǒng)計分析。基于長尾理論獲取的網(wǎng)頁理想關鍵詞最能夠描述網(wǎng)頁的主體內容,它不再由網(wǎng)頁的制作者決定,而是社會網(wǎng)絡中用戶共同決定[9]。
2 提取網(wǎng)頁描述信息的策略
社會網(wǎng)絡的長尾理論揭示了社會群體對于一個發(fā)散特征的事物的描述方法。將這種方法轉移到提取網(wǎng)頁描述信息,往往一個網(wǎng)頁會擁有若干關鍵詞,這些關鍵詞根據(jù)與網(wǎng)頁內容的相似程度可以分為主關鍵詞與長尾關鍵詞,如圖2所示,正是對一個介紹蘋果手機的網(wǎng)頁的若干關鍵詞的分布所構成的長尾曲線,這些關鍵詞可能不是網(wǎng)頁中出現(xiàn)過的內容,像智能手機、Siri就是社會網(wǎng)絡大眾對于網(wǎng)頁內容的個性理解,它們都是長尾關鍵詞,都是對網(wǎng)頁信息的潛在描述。
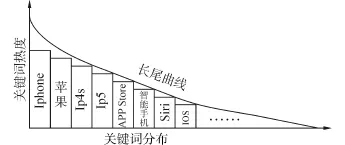
圖2 長尾模型下的網(wǎng)頁關鍵詞分布Fig.2 Keywords distribution of webpage under longtail model
相關聯(lián)的事物之間有一定的相似度。在第1節(jié)日志數(shù)據(jù)的邏輯表示方法中,查詢關鍵詞與網(wǎng)頁是相互鏈接的,可以通過SimRank算法[10-14]計算關鍵詞與網(wǎng)頁的相似度來獲取到網(wǎng)頁的主關鍵詞與長尾關鍵詞。本節(jié)將改進SimRank算法,其基本思想是,同一個類型下的2個對象,如果經(jīng)常連接到相同的其他對象,那么這2個對象的相似性應該很高。基于這種思想,SimRank算法可以用來計算任意2個對象之間的相似度,這種相似度的度量取決于相互連接的節(jié)點的上下文節(jié)點,建立在與它們相鄰節(jié)點的關系基礎之上。更進一步說,SimRank算法認為:如果2個節(jié)點與相似的節(jié)點都有連接關系,那么這2個節(jié)點也是相似的。
不確定圖中節(jié)點相似度的計算問題:在不確定圖G=<V,E,P>中,計算集體V中節(jié)點之間的相似度。首先,關于面向不確定圖的SimRank算法的若干定義。
定義1 節(jié)點a與節(jié)點b關系閾值。設ε為判斷閾值,當2個節(jié)點a,b相似值小于給定閾值ε,即S(a,b)<ε時,就可以認為節(jié)點a和b基本不相似,這時稱a與b無關;否則,認為a與b是相關的。這一點采用了SimRank優(yōu)化算法的剪枝技術。
定義2 節(jié)點a與節(jié)點b在不確定圖G中的SimRank值的相關概率統(tǒng)計定義[15]。概率分布函數(shù):
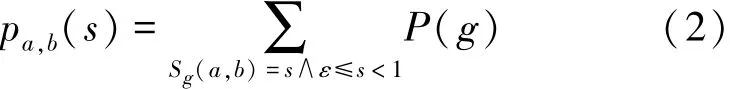
期望:
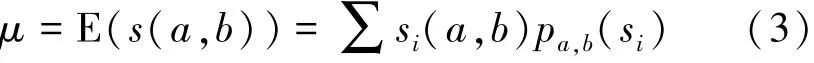
方差:
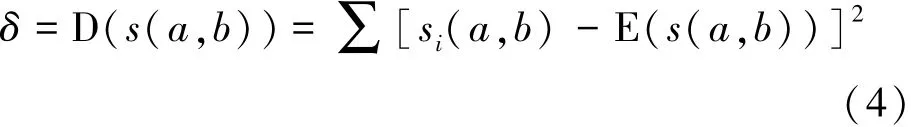
不確定圖G中,節(jié)點a與節(jié)點b并沒有確切的SimRank值,SimRank算法只適用于確定圖。通過第1節(jié)所介紹的不確定圖的性質可知,不確定圖G可以以一定的概率P(g)派生出確定圖g,在這個確定圖g上就可以進行SimRank計算。不確定圖的SimRank值是一個概率事件,雖然不能確切計算,但可以得到其概率分布函數(shù)、期望及方差值,這是非常有意義的。本文就是用期望值刻畫不確定圖中2個節(jié)點的相似關系的。
根據(jù)用戶行為在搜索引擎日志中的表現(xiàn),論證SimRank概率分布服從正態(tài)分布。
定理1 g1,g2,…是不確定圖G的所有可能世界,令它們代表獨立同分布的節(jié)點a和b的Sim-Rank值隨機變量序列,序列的均值為μ,方差為δ。當不確定圖G的可能世界的個數(shù)n充分大時,記G=g1+…+gn,則G~N(nμ,nδ2)。由中心極限定理可知,令Gn的分布函數(shù)的極限分布為標準正態(tài)分布函數(shù)Φ(x),故G服從正態(tài)分布。
不確定圖G所派生出來的所有可能世界g上的節(jié)點間的SimRank值,它們共同組成概率事件不確定圖G上的SimRank值,由定理1可知,不確定圖G上的SimRank值服從正態(tài)分布。
2.1 不確定圖中SimRank基本算法
輸入:不確定圖G,查詢點a,閾值ε
輸出:節(jié)點a與有關節(jié)點的信任關系
執(zhí)行流程:
for(i=0;i<2|E|;i++)
對不確定圖的每個可能世界g,計算節(jié)點a與其他節(jié)點的SimRank值;
求出可能世界g存在的概率P(g);
end for
根據(jù)定義3,求出點a與其他相關節(jié)點的Sim-Rank期望值。
基本算法比普通SimRank算法更為復雜,它包含了計算不確定圖的所有可能世界的任務,并在每個可能世界中都要進行一次SimRank計算。由上文對于SimRank算法效率的分析,可知每個可能世界SimRank計算的代價為O(|V|3)。在忽略不確定圖可能世界的計算代價的前提下,不確定圖中的SimRank計算的時間復雜度為O(2|E|·|V|3)。同時,算法的時間消耗會隨著節(jié)點個數(shù)的增加,以指數(shù)形勢增長。
針對SimRank限制傳播半徑的方法,本文又繼續(xù)提出如下定義。
定義3 半徑子圖與概率半徑子圖。子圖就是一個圖的子集,對于任意不確定圖G=<V,E>或者其對應的確定圖g=<V,E>,以點a為中心,由近及遠遍歷圖中的各個節(jié)點,限制遍歷路徑長度不超過r,將生成不確定圖G和其確定圖g的以a為中心,r為半徑的半徑子圖,簡稱子圖。其中不確定圖G的子圖也稱作概率半徑子圖,簡稱概率子圖。
定理2 設g′為確定圖g的一個以點a為中心、r為半徑的子圖,給定閾值ε,C代表SimRank公式中的衰減因子,則對于?b∈g-g′,當r>時,a與b無關。
證明:定義2個隨機游走者,分別從圖g中的節(jié)點a和b出發(fā),他們經(jīng)過k步后首次相遇的概率為Rk(a,b),由文獻[16]可知,節(jié)點a和b的SimRank相似度為
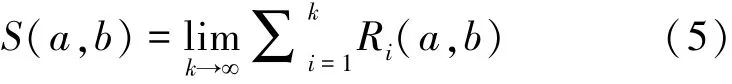
將圖分割為2個部分,一部分為以a為中心,半徑為r的節(jié)點構成的圖g′,另一部分為g′對于g的補集g–g′,b為補集中的一個點。那么游走者最早在步第一次相遇。此時相遇概率為
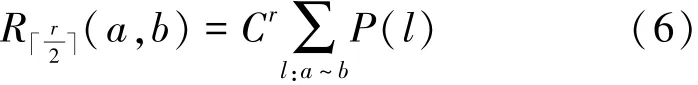
式中:l表示隨機游走第一次相遇的路徑,C為Sim-Rank公式中的衰減系數(shù),P(l)表示每條路徑存在的概率。則相遇路徑概率最大情況如圖3所示,假設這樣的路徑有k條,路徑長度為r,除了始點與終點的度數(shù)為k,路徑上其他節(jié)點度數(shù)為2,這種情況下,P(l)取得最大值。于是


圖3 相遇路徑概率最大情況Fig.3 Maximum probability for path to meet
根據(jù)式(7)推導得
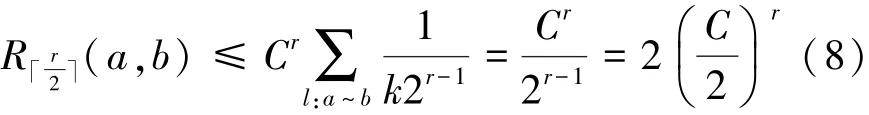
最終得出
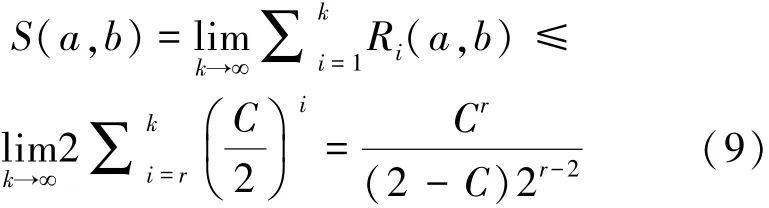
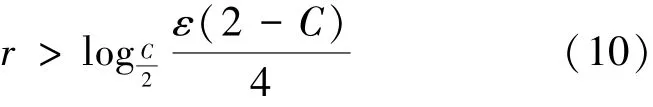
這就是限制傳播半徑優(yōu)化SimRank計算時間的方法。限制傳播半徑,不確定圖就會變?yōu)槠鋵母怕首訄D,概率子圖仍然是一個不確定圖,于是,在概率子圖上進行SimRank計算可以替代算法2.1。
2.2 在概率子圖上進行SimRank計算
輸入:不確定圖G、起始點a、閾值ε
輸出:點a與有關節(jié)點的信任關系
執(zhí)行流程:
1)計算限制傳播半徑r,將不確定圖G轉化為其對應的以r為半徑的概率子圖
2)采用概率抽樣中的系統(tǒng)抽樣法,對概率子圖所派生的所有確定圖進行抽樣,計算樣本中節(jié)點a與其他節(jié)點的SimRank值
3)對樣本確定圖的存在概率進行加權歸一化處理,獲得樣本確定圖新的存在概率
4)最后求出概率子圖中SimRank值的期望。
關于優(yōu)化算法中的構造概率子圖的方法,生成概率子圖的算法是在不確定圖G中,以查詢點a為起點,按照類似于圖的廣度優(yōu)化遍歷算法,使廣度優(yōu)化遍歷算法的每條路徑長度不超過r。將圖中的節(jié)點以a為中心按連接路徑長度進行層次劃分,取r層以內的所有節(jié)點。將所有記錄到的節(jié)點集合構成一個新的圖,如此,可得到以不確定圖G的以點a為中心,r為半徑的概率子圖。
概率抽樣以概率理論為基礎,對于事件總體空間內的每個個體,都會有一個預定的概率被抽到。抽樣過程是一種隨機化的流程,根據(jù)概率理論中的大數(shù)定律,當抽取的樣本達到一定數(shù)量時,隨機抽取的樣本在一定程度上可以替代總體,在這個樣本空間內的各種概率計算,都可以表示總體的性質。
進行概率抽樣應當遵循3個基本原則:1)隨機性,對總體抽樣時,每個個體被抽到的概率是相同的;2)可行性,抽樣在現(xiàn)實條件下是可操作的,不能超越實現(xiàn)情況;3)信息性,所抽到的樣本應當符合總體分布規(guī)律,反映出總體的分布特征。
概率抽樣包括簡單隨機抽樣、系統(tǒng)抽樣、分類抽樣、整群抽樣、多階段抽樣等多種抽樣方案。簡單隨機抽樣:在包含N個個體的總體中,以相同的概率逐一抽取M個樣本。簡單隨機抽樣在總體中的個體數(shù)較多的情況下顯得原始粗糙又耗時,系統(tǒng)抽樣則適用于這種情況,將總體分為均勻的M等份,在每一份中隨機抽取個體,可得到M個樣本。分層抽樣與系統(tǒng)抽樣類似,都是將總體分為M等份,充分考慮到總體的分布規(guī)律,對各等份依照比例采取抽樣。依據(jù)上述主要的概率抽樣類型的適用情況,不確定圖的概率子圖的派生樣本較多,且已知不確定圖中SimRank的概率分布規(guī)律,故系統(tǒng)抽樣方法是本文所面臨問題的理想方案。
根據(jù)定理1可知,不確定圖中節(jié)點間SimRank值的概率公布服從正態(tài)分布,則由概率抽樣方法中的簡單隨機抽樣方法計算SimRank值。針對概率抽樣的3點基本要求,論文提出一種漸進式的抽樣策略,首先是確保抽樣個數(shù)達到一定程度,使得樣本在一定可信度下可以代替整體,其次是按正態(tài)分布的規(guī)律針對抽樣個數(shù)進行抽樣,在抽樣個數(shù)m確定的情況下,將樣本空間平均分為m份,每一份抽取一個樣本。
設優(yōu)化算法的抽樣個數(shù)為m,抽樣前第i個樣本確定圖的存在概率為pi,由于抽樣后樣本的存在概率的和不為1,所以需要歸一化處理,歸一化處理后第i個樣本確定圖的存在概率為pi′。算法2.2的第3步將按下進行:

定理3 對于不確定圖G=<V,E,P>,構造其以節(jié)點a為中心、r為半徑的概率子圖G′,并設ε為閾值。{G′}P是G′對于邊的存在概率集合P所派生出的m個可能世界的樣本集合,且在每個可能世界中的所有節(jié)點都是相關的,S(a,b)代表每一個可能世界中的節(jié)點對(a,b)的SimRank值,則對于任意的θ>0,當抽樣樣本個數(shù)會使得成立。
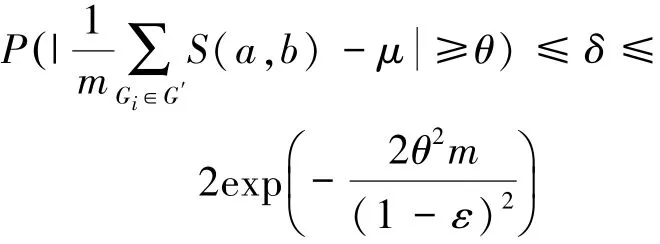
證明:由Hoeffding不等式可知,對于相互獨立的隨機變量ξ1,ξ2,…,ξN,滿足ai<ξi<bi,記則對于任意的θ>0,都有
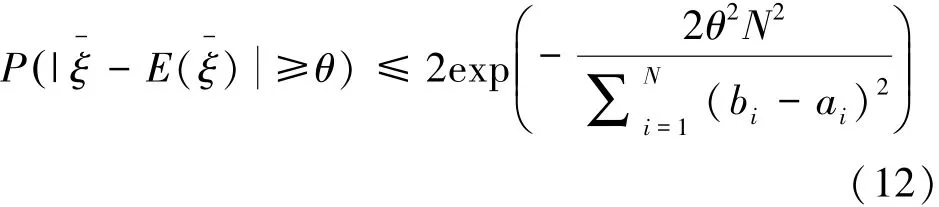
概率子圖G′基于概率P所派生的m個可能世界樣本,是相互獨立的隨機變量序列,根據(jù)定義1中的相關性可知,每一個可能世界的節(jié)點對(a,b)的SimRank值S(a,b)的取值范圍在都區(qū)間[ε,1]之內,并且樣本均值為μ,將這些條件依次代入Hoeffding不等式,可得
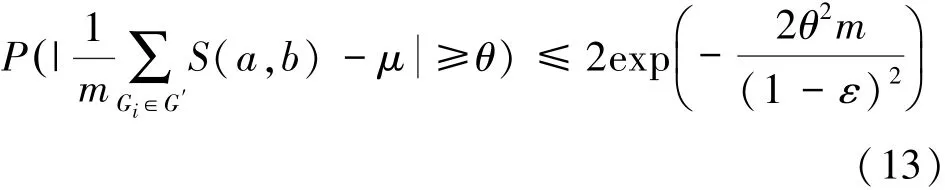
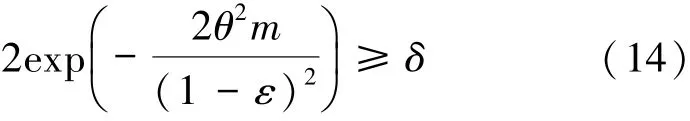
由式(14)推導可得
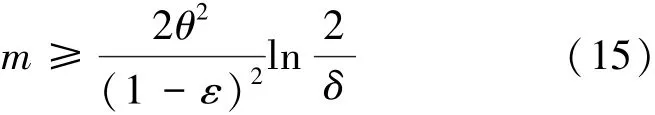
證畢。
由定理3,本文的抽樣方法保證了采用抽樣技術對于不確定圖中SimRank值計算的準確性。另外,在確定抽樣個數(shù)后,進行隨機抽樣,樣本很可能出現(xiàn)扎堆的現(xiàn)象,若繼續(xù)提高抽樣樣本的質量,還需要針對不確定圖中SimRank值服從正態(tài)分布這一規(guī)律,使所抽取到的樣本也大致服從正態(tài)分布。
前面已經(jīng)提供了獲取概率子圖的方法,再令概率子圖中的每一個節(jié)點以0.5的概率存在(即節(jié)點在概率子圖中存在和不存在是等可能事件),然后將存在的節(jié)點保留,不存在的節(jié)點剔除,依然保持所剩節(jié)點間的概率連接,所得到的圖即可作為一個抽樣樣本。以同樣的方式進行抽樣,進而可以抽取得到m個樣本,這些樣本出現(xiàn)扎堆現(xiàn)象的概率為,樣本個數(shù)越大,扎堆現(xiàn)象出現(xiàn)的概率就越低。
通過本文所提出的采樣技術進行不確定圖中SimRank計算,時間復雜度會大大降低。與Sim-Rank的基本迭代算法(2.1.1節(jié))相比,優(yōu)化算法(2.1.2節(jié))中增加了構建概率子圖和抽樣環(huán)節(jié),其中,生成概率子圖與子圖中的抽樣所需要的時間僅與限制傳播半徑后的子圖的節(jié)點數(shù)和邊數(shù)呈線性關系,而限制傳播半徑后的子圖規(guī)模與不確定圖相比已大大減小。所以優(yōu)化算法是在小規(guī)模圖中進行Sim-Rank計算,時間復雜度與樣本數(shù)量及子圖節(jié)點個數(shù)相關。在樣本數(shù)為m,子圖節(jié)點個數(shù)為v的情況下,時間復雜度為O(mv3),樣本m和子圖節(jié)點個數(shù)均遠遠小于不確定圖中節(jié)點個數(shù)n,與基本迭代算法的時間復雜度O(n4)相比,優(yōu)化算法的效率得到了顯著的提高。
3 實驗與分析
3.1 數(shù)據(jù)獲取及預處理
目前,已有很多搜索引擎公司公開了自己的日志數(shù)據(jù),如AOL、搜狗等。本實驗所使用的查詢日志數(shù)據(jù)為搜狗公司的搜狗實驗室面向學術研究公開的搜狗搜索引擎查詢日志數(shù)據(jù),日志數(shù)據(jù)是2008年6月搜狗搜索引擎所記錄的用戶搜索請求關鍵詞及用戶所瀏覽的網(wǎng)頁鏈接集合。搜狗日志的數(shù)據(jù)格式為:訪問時間\t用戶ID\t[查詢詞]\t該URL在返回結果中的排名\t用戶點擊的順序號\t用戶點擊的URL。這份日志數(shù)據(jù)中包括了總共46 389 567條記錄。
實驗首先數(shù)據(jù)預處理,過濾冗余的和無效的查詢;剔除日志數(shù)據(jù)中無用的信息,只保留查詢詞與鏈接URL2列。將所得到的干凈的數(shù)據(jù)轉換為關鍵詞與網(wǎng)頁鏈接的二部圖,關鍵詞與網(wǎng)頁鏈接的共同現(xiàn)次數(shù)作為圖中各個邊的權重,通過式(1)中邊的存在概率的計算方法,生成日志不確定圖。圖中有關鍵詞節(jié)點4 605 412個,URL鏈接節(jié)點2 316 342個。
3.2 實驗設計與評價
SimRank是一個很耗時的算法,本文的改進算法就是要提高它在不確定圖上的計算效率,同時還需要保證結果的準確性。
根據(jù)2.1節(jié)中對于算法的時間分析可知,Sim-Rank算法的時間復雜度是O(n4),而優(yōu)化算法的時間復雜度為O(mv3),其中m為采樣個數(shù),v為子圖節(jié)點個數(shù)。驗證算法效率的提高,最直接的辦法就是比較n、m、v三者的關系。優(yōu)化算法就是期望抽樣個數(shù)的減少和子圖節(jié)點個數(shù)的減少。
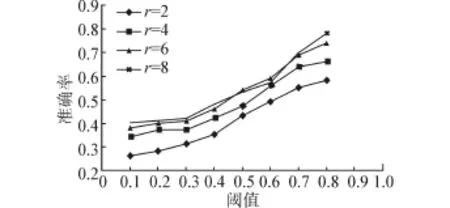
圖4 概率子圖上求SimRank值的準確率Fig.4 The accuracy of SimRank on probability graph
第1部分實驗,分析概率子圖節(jié)點個數(shù)和不確定圖中節(jié)點個數(shù)的比例,同時,由于采用的是剪枝優(yōu)化法,還需要分析概率子圖中邊的個數(shù)與不確定圖中邊的個數(shù)的比例。在這里,節(jié)點個數(shù)和邊的個數(shù)的減少都會降低概率抽樣方法的采樣個數(shù)。對于傳播半徑的分析,選擇性設置傳播半徑為2、4、6、8的4個值作對比,衰減系數(shù)設置與PageRank算法中C值相同同為0.85。在經(jīng)過預處理后的數(shù)據(jù)中,隨機選擇1 000條記錄,包括1 383個查詢關鍵詞、927個URL鏈接及1 564條邊,對這些查詢關鍵詞都進行優(yōu)化算法,然后計算準確率的平均值。
由圖4可知,隨著閾值的增大,優(yōu)化算法的準確率逐漸提高。同時,傳播半徑的延長,準確率也會隨之提高,但半徑越大,準確率的提高越不明顯。這也說明定理2對于傳播半徑限制的作用,半徑長度以外的其他節(jié)點對于SimRank值的影響可以忽略。
有了優(yōu)化算法準確率的保證,則在圖5中,概率子圖與不確定圖上的點和邊比例關系可以看出,使用采樣及剪枝方法后,節(jié)點和邊的個數(shù)大幅度減少,準確率則并沒有受到影響,且傳播半徑越大,這種節(jié)點和邊比例的變化越不顯著。
第2部分實驗,驗證優(yōu)化算法的計算時間是否降低,其中隨機取5個查詢點,以不同的抽樣值m得到SimRank計算的平均時間。所采用的服務器配置為Intel i3 2350M處理器(主頻2.3 GHz),6 G內存,windows7SP1 64位操作系統(tǒng)。
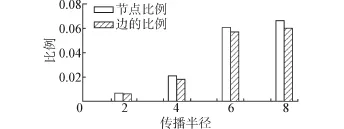
圖5 概率子圖與不確定圖上的點和邊比例Fig.5 The proportion of nodes and edges on probability graph and uncertain graph
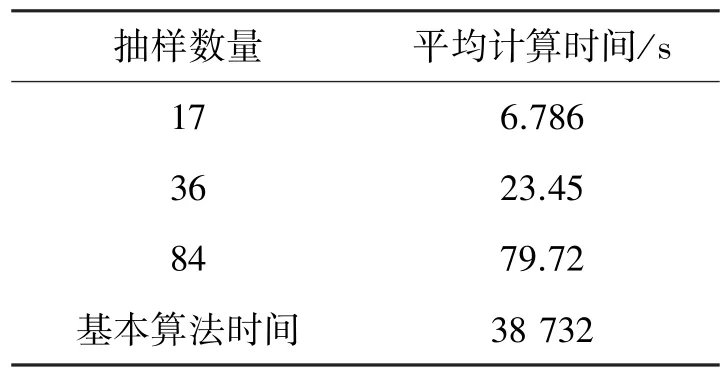
表1 不確定圖上的SimRank計算時間Table 1 SimRank computing time on uncertain graph
表1中,基本算法是不需要抽樣的,而優(yōu)化算法中選擇抽樣個數(shù)為17、36、84,在對隨機挑出的100個URL鏈接計算其相似的關鍵詞所需要的時間消耗求算術平均值,就是表中的平均計算時間。隨著抽樣個數(shù)的增加,平均計算時間也在增加,但遠遠低于基本算法的計算時間,可見本文所提的優(yōu)化算法相比基本算法可行性很強。
4 結束語
本文所研究內容由搜索引擎日志通過社會分析方法逐步形成網(wǎng)頁描述庫。網(wǎng)頁描述庫的建立是搜索引擎社會化的一個體現(xiàn),是本文社會化搜索排序的一個重要參考因素。著重介紹了如何將日志數(shù)據(jù)抽象為一個不確定圖,并用形式化語言表達了描述信息的組成。在日志不確定圖的基礎上改進Sim-Rank算法,提出了一種基于抽樣和限制傳播半徑的優(yōu)化算法,提高了算法的時間效率。
在今后的研究中,將進一步研究用戶的行為,建立更加準確的網(wǎng)頁描述庫,并進一步提高算法的時間效率。
[1]HOTHO A,J?SCHKE R,SCHMITZ C,et al.Folkrank:a ranking algorithm for folksonomies[C]//Proc FGIR.Hildesheim,Germany,2006:111-114.
[2]BAO S,XUE G,WU X,et al.Optimizing web search using social annotations[C]//Proceedings of the 16th International Conference on World Wide Web,ACM.Alberta,Canada,2007:501-510.
[3]劉凱鵬,方濱興.一種基于社會性標注的網(wǎng)頁排序算法[J].計算機學報,2010,33(6):1014-1022.LIU Kaipeng,F(xiàn)ANG Binxing.A novel page ranking algorithm based on social annotations[J].Chinese Journal of Computers,2010,33(6):1014-1022.
[4]LIU Y,GAO B,LIU T Y,et al.BrowseRank:letting web users vote for page importance[C]//Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,ACM.Singapore,2008:451-458.
[5]陳紅濤.基于搜索日志的用戶行為研究及應用[D].北京:北京郵電大學,2007:14-29.
[6]NOLL M,MEINEL C.Web search personalization via social bookmarking and tagging[J].The Semantic Web,2007,4875:367-380.
[7]靳延安,李瑞軒,文坤梅,等.社會標注及其在信息檢索中的應用研究綜述[J].中文信息學報,2010,24(4):52-62.JIN Yan'an,LI Ruixuan,WEN Kunmei,et al.A survey on social annotation and its application in information retrieval[J].Journal of Chinese Information Processing,2010,24(4):52-62.
[8]CHOOCHAIWATTANA W,SPRING M B.Applying social annotations to retrieve and re-rank web resources[C]//Proceedings-2009 International Conference on Information Management and Engineering,ICIME.Kuala Lumpur,Malaysia,2009:215-219.
[9]BALFE E,SMYTH B.An analysis of query similarity in collaborative web search[J].Advances in Information Retrieval,2005,3408:330-344.
[10]JEH G,WIDOM J.SimRank:a measure of structural-context similarity[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,ACM.Edmonton,Canada,2002:538-543.
[11]ANTONELLIS I,MOLINA H G,CHANG C C.SimRank++:query rewriting through link analysis of the click graph[C]//Proceeding of the 17th International Conference on World Wide Web 2008.Beijing,China,2008:408-421.
[12]李亞楠,許晟,王斌.基于加權SimRank的中文查詢推薦研究[J].中文信息學報,2010,24(3):3-10.LI Yanan,XU Sheng,WANG Bin.Chinese query recommendation by weighted SimRank[J].Journal of Chinese Information Processing,2010,24(3):3-10.
[13]CAI Y,LI P,LIU H,et al.SimRank:combining content and link information to cluster papers effectively and efficiently[J].Advanced Data Mining and Applications,2008,5139:317-329.
[14]馬云龍,林原,林鴻飛.基于權重標準化SimRank方法的查詢擴展技術研究[J].中文信息學報,2011,25(1):28-34.MA Yunlong,LIN Yuan,LIN Hongfei.A weight normalization based SimRank approach for query expansion[J].Journal of Chinese Information Processing,2011,25(1):28-34.
[15]張應龍,李翠平,陳紅,等.不確定圖上的kNN查詢處理[J].計算機研究與發(fā)展,2011,48(10):1850-1858.ZHANG Yinglong,LI Cuiping,CHEN Hong,et al.K-nearest neighbors in uncertain graph[J].Journal of Computer Research and Development,2011,48(10):1850-1858.
[16]MORRIS M R,PAEPCKE A,WINOGRAD T.Teamsearch:comparing techniques for co-present collaborative search of digital media[C]//Proceedings of the First IEEE International Workshop on Horizontal Interactive Human-Computer Systems,TABLETOP'06.Adelaide,Australia,2006:97-104.
An uncertain graph oriented SimRank algorithm
DONG Yuxin,WANG Yingjie,NING Pengfei,ZHANG Yaoyuan
(College of Computer Science and Technology,Harbin Engineering University,Harbin 150001,China)
In this paper,the social network analysis(SNA)method is adopted to analyze search engine logs according to previous search engine logs analysis that mainly focuses on user behavior,query recommendation and search engine evaluation.The objective of SNA is to exam the structure of relationships between social entities.This method uses an uncertain graph to logically indicate the link relationship between the query term and the webpage of search engine log.It also computes the similarities between query term and webpage based on the SimRank algorithm of an uncertain graph.As well as,establishes a webpage description library by similarity and query term in a weighted way.In addition,this paper proposes a progressive sampling strategy to ensure the calculation accuracy of the SimRank value in an uncertain graph.Experiments show that the algorithm has good accuracy and feasibility.Keywords:search engine;social network;uncertain graph;SimRank;similarity;sampling strategy
10.3969/j.issn.1006-7043.201305037
http://www.cnki.net/kcms/doi/10.3969/j.issn.1006-7043.201305037.html
TP301
A
1006-7043(2014)11-1390-07
2013-05-14.網(wǎng)絡出版時間:2014-10-30.
國家自然科學基金資助項目(61272186,61100007);黑龍江省基金資助項目(F200937,F(xiàn)201110);中央高校基本科研業(yè)務費專項資金資助項目(HEUCF100608);黑龍江省博士后基金資助項目(LBH-Z12068);哈爾濱市基金資助項目(RC2009XK010003).
董宇欣(1974-),女,副教授.
董宇欣,E-mail:dongyuxin@hrbeu.edu.cn.
猜你喜歡
計算機與網(wǎng)絡(2022年2期)2022-03-17 22:48:16
中國衛(wèi)生(2015年12期)2015-11-10 05:13:38
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經(jīng)濟與管理研究(2014年11期)2014-03-11 17:02:44
科學導報·學術論壇(2013年5期)2013-06-26 05:41:54
百科知識(2012年11期)2012-04-29 08:30:15
中原工學院學報(2011年4期)2011-12-27 09:19:14
微型計算機·Geek(2009年1期)2009-12-15 05:37:32
計算機應用文摘(2009年17期)2009-04-29 00:44:03
