基于遺傳算法和神經網絡的矮小兒童智能診斷研究
2014-05-10 06:09:10張京軍邵偉東高瑞貞
河北工程大學學報(自然科學版) 2014年1期
張京軍,王 健,邵偉東,高瑞貞
(1. 河北工程大學 信息與電氣工程學院,河北 邯鄲 056038;2. 石家莊展望未來科技有限公司,河北 石家莊 050081)
矮小是危害人們身心健康的主要外在表現之一,它不僅僅是患者的個人問題,又是不得不面對的社會問題。而通過先進的信息技術將具有該領域醫療專家水平的計算機輔助診斷系統應用到醫療機構,一方面可以大大提高診斷效率與準確率,另一方面也有利于患者的及時就診。從20世紀70年代末開始至80年代中期,我國先后出現一批醫學診斷專家系統軟件[1],早期的有上海計算所的中醫婦科診斷系統、吉林大學和白求恩醫科大學合作的婦科專家系統等。近期的有上海中西醫結合醫院與頤圣計算機公司聯合開發具有咨詢和輔助診斷性質的計算機輔助診療系統等。當前的人工智能技術發展已經較為成熟,尤其是神經網絡技術在諸多工程領域的應用日趨廣泛,而利用遺傳算法來優化神經網絡并應用到醫學輔助診斷領域的研究尚處于初級階段。鑒于此,本文利用遺傳算法來優化矮小兒童智能診斷的神經網絡模型。
1 臨床數據預處理
1.1 矮小癥病例樣本數據規范化
本文采取石家莊展望未來科技長期跟蹤監測研究數據(所有檢查結果均來自于國內各地正規醫院),對影響兒童身高發育的病因進行分析訓練和仿真。根據資料分析以及專家經驗確定影響兒童身高發育的主要因素[2]和檢查項目,并將之列為神經網絡的輸入數據:患兒性別,實際年齡,體重,現身高,CHN骨齡,BMI(Body Mass Index身體質量指數)評價,父身高,母身高,生長激素水平(GH),血清總三碘甲狀腺原氨酸(TT3),血清總甲狀腺素(TT4),促甲狀腺激素(TSH),促黃體生成素(LH),胰島素樣生長因子1(IGF-1),胰島素樣生長因子結合蛋白3(IGFBP-3),微量元素,腦CT。其中患兒性別、微量元素、腦CT都是非數值形式,不能直接被BP網絡識別,必須對其進行數值化。分別用1,0代表性別屬性中的男和女,微量元素的不缺乏和缺乏,腦CT影像檢查結果的正常和異常。
診斷結果為8種常見的矮小病因類型,并將其作為神經網絡的期望輸出模式:遺傳性矮小(0 0 0),體質性青春期發育遲緩(0 0 1),原發性GHD(0 1 0),甲狀腺功能障礙(0 1 1),營養性矮小(1 0 0),繼發性GHD(1 0 1),性早熟(1 1 0),其他疾病(1 1 1)。
1.2 實驗數據歸一化
對于樣本數據屬性的差異問題運用數據歸一化方法對神經網絡輸入數據進行預處理,使數據分布在[-1,1]的區間上,以便于神經網絡的快速收斂從而得出正確的診斷結果[3]。
Pn=2*(P-minp)/(maxp-minp)-1
(1)
Tn=2*(T-mint)/(maxt-mint)-1
(2)
這里,P和T分別為樣本中待處理的輸入數據和原始的目標數據,Pn和Tn為經過歸一化處理后的輸入數據和目標數據。矮小兒童病例數據歸一化后的結果如下表1所示:
2 矮小兒童智能診斷模型
矮小兒童智能診斷的數學模型是基于BP算法[4]的數學模型。BP網絡的學習是信息的正向傳遞和誤差的反向傳播,通過不斷修正權值來使目標輸出與期望輸出更加接近。
三層感知器中,輸入向量為x=(x1,x2,…,xn)T,其中x0=-1是為隱層神經元引入閾值而設置的;隱層的輸入向量為y=(y1,y2,…,ym)T,其中y0=-1是為輸出層神經元引入閾值而設置的;輸出層輸出向量為o=(o1,o2,…,ol)T;期望輸出向量為d=(d1,d2,…,dl)T。輸入層到隱層之間的權值矩陣用v=(v1,v2,…,vm)T表示;隱層到輸出層之間的權值矩陣用w=(w1,w2,…,wi)T表示。
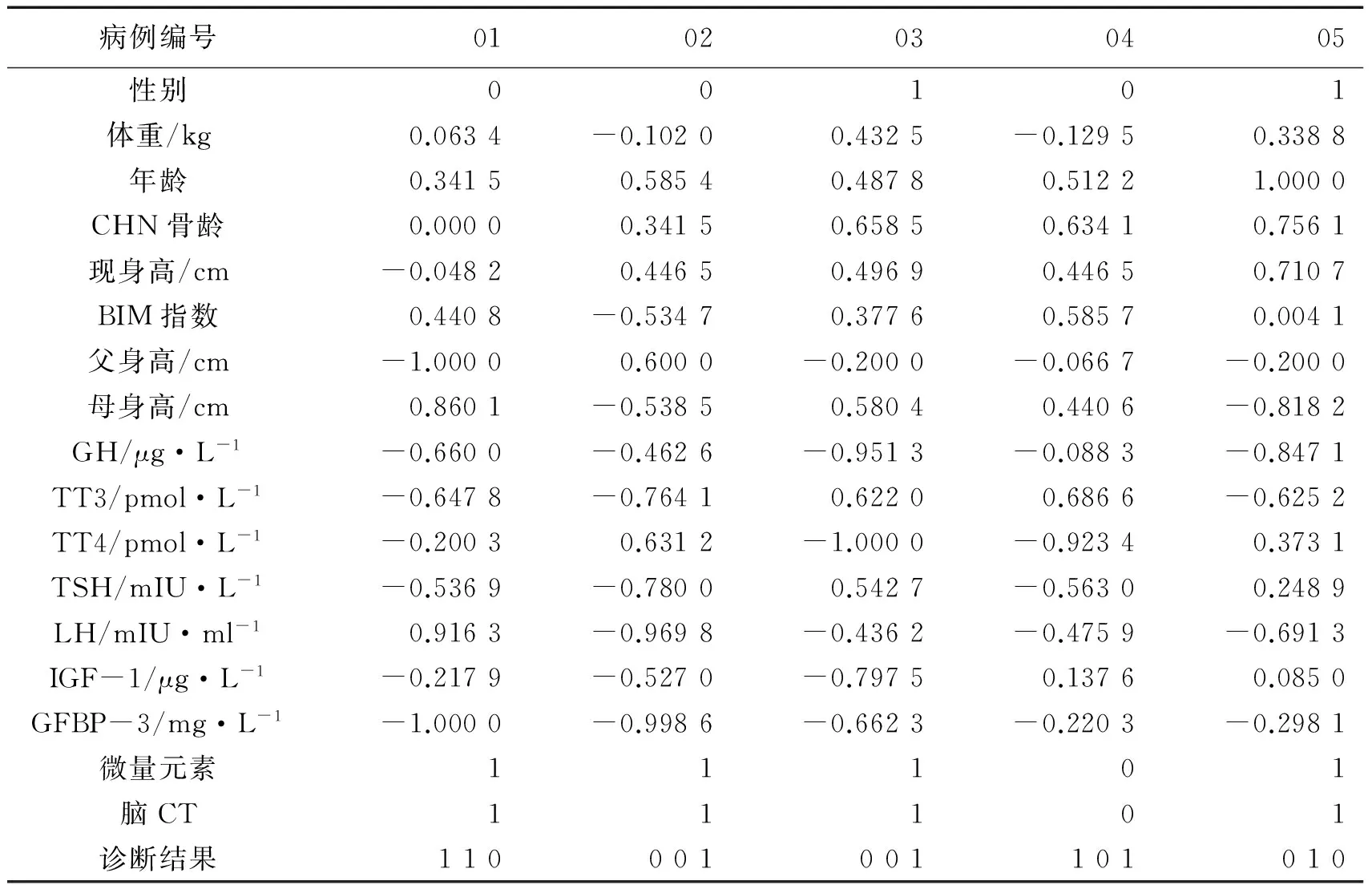
表1 病例樣本歸一化數據表
對于輸出層,有
ok=f(knet)
(3)
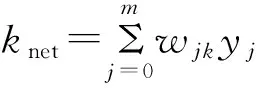
對于隱層,有
yj=f(jnet)
(4)
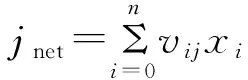
當網絡輸出與期望不等時,存在輸出誤差E,定義如下:
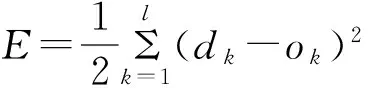
(5)
將式(3)擴展至隱層與輸入層,有

(6)

(7)
相應得出的三層感知器的BP學習算法權值調整計算公式為
Δwjk=ηδk0yj=η(dk-ok)ok(1-ok)yj
(8)
(9)
3 實例分析與仿真實驗
3.1 BP網絡結構設計
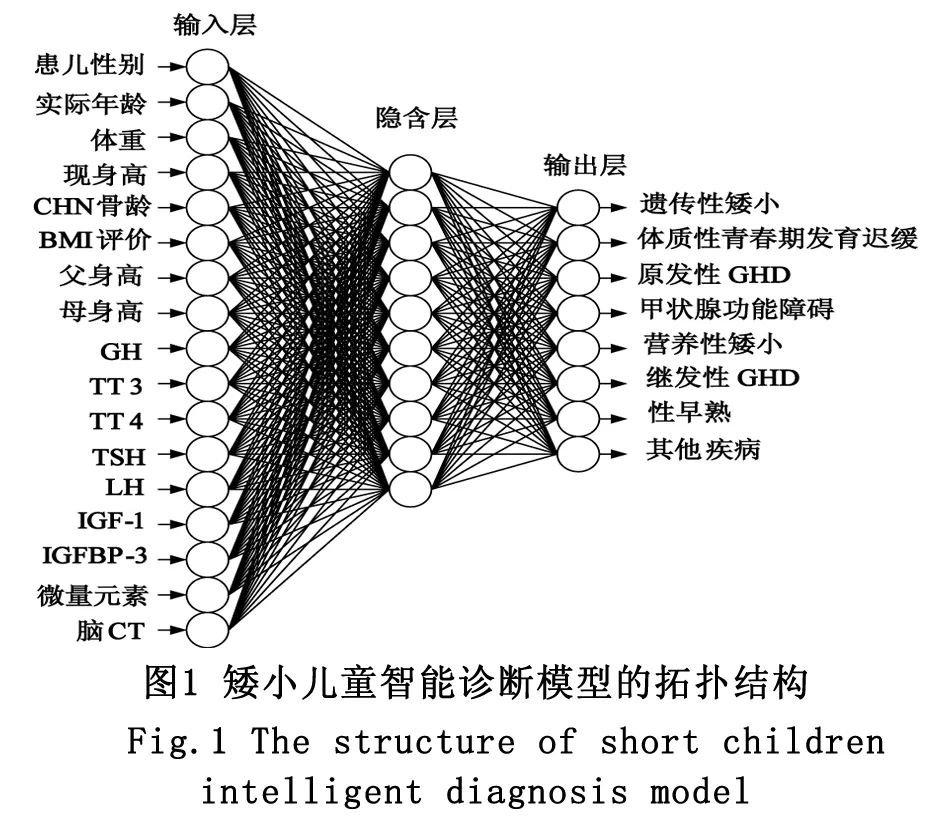
對于基于BP神經網絡的矮小兒童智能診斷模型而言,神經網絡的輸入信息為影響兒童矮小的屬性特征,總共有17個屬性;神經網絡的輸出信息為最終診斷后的兒童矮小癥的病因類型(如上文1.1所述)。考慮到基于BP祌經網絡的矮小兒童智能診斷模型的輸入變量和輸出變量的規模較小,因此在這里選用一層隱含層即可滿足網絡的性能要求。通過試算法比較不同的隱層神經元數下網絡的訓練情況,最終設定隱含層數目為10。至此得到網絡的拓撲結構為17 - 10 - 8,如圖1所示。
3.2 模型重要參數的設置
在MATLAB的神經網絡工具箱中,提供了多種不同的訓練函數,在本網絡中選擇trainlm對網絡進行訓練,該函數的學習算法為Levenberg-Marquardt優化算法,其優點在于收斂速度很快,能夠很好的達到預期的效率。選取purelin為神經元上的傳遞函數,誤差界值設置為0.01。為了平衡速率與精度之間的關系,將學習率初步設置為0.1。
3.3 遺傳算法對系統的優化設計
遺傳算法[5]對系統的具體優化設計單元中,具體步驟如下:
(1) 初步確定BP神經網絡連接的取值范圍;
(2) 對網絡連接的取值進行二進制編碼;
(3) 以目標函數最大值作為遺傳算法的適應度函數,即:
(10)
(4) 采用BP神經網絡算法對所有權值組分別進行訓練,如果該N組權值至少有一組滿足精度的要求,那么尋優算法結束,不然就轉入步驟(4)繼續學習。
(5) 在訓練好的N組較好的權值中隨機選擇N組新的權值,與原來N組權值組合在一起,構成一個完整的基因群體,這樣就共得到2N組權值。
(6) 將這2N組權值進行遺傳操作(復制、雜交、變異)。
(7) 對經過遺傳操作后獲得的新2N組權值進行排序,并從中選出N組較好的權值,跳轉到步驟(3)。
遺傳算法的優化[6],首先需要設置一些具體的算法參數如:種群規模、迭代次數、交叉率、變異率等;其次要對每一個具體算子的內部參數進行相關設計和確定。采用實驗數據與BP網絡相同,30例樣本數據的前20例用于訓練,10例用于檢測。根據網絡模型的拓撲結構得到權值共有17×10+10×8=250個,閾值10+8=18個,遺傳算法染色體編碼長度[7]為250+18=268。確定好染色體編碼長度后,對種群進行初始化,GA的編碼程序可以實現初始化操作[8],最后將遺傳算法優化后的權值閾值傳遞給BP網絡。
3.4 矮小兒童智能診斷的MATLAB仿真
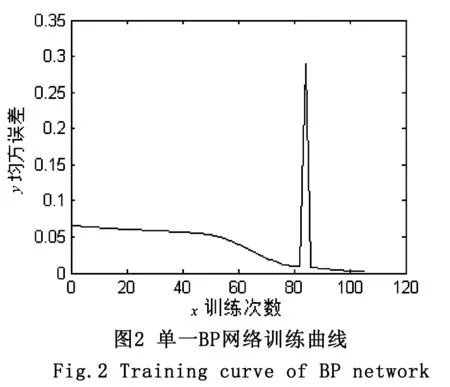
將實驗數據用于單純BP算法,網絡的訓練結果如圖2所示。由實驗仿真圖可以看到,網絡在訓練到80次時達到期望的誤差界值,但是仿真曲線顯示在網絡訓練到大約82次時發生了振蕩,這對實驗結果的準確率產生一定影響。
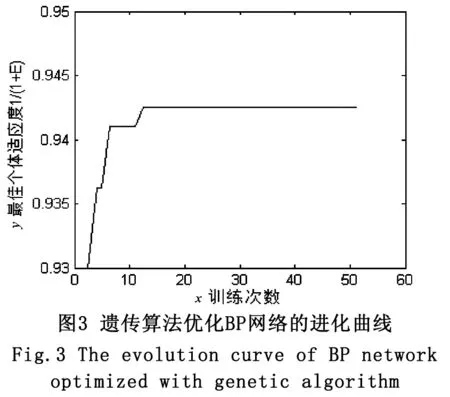
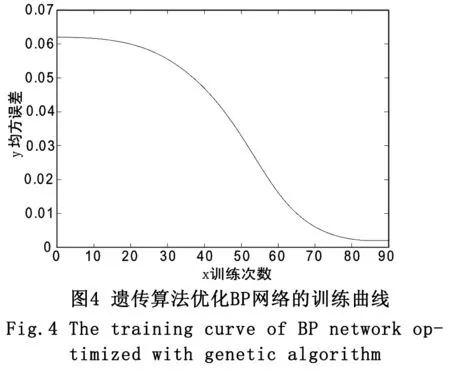
然后將相同的網絡規模和拓撲結構運用到遺傳算法的優化中,遺傳算法優化BP網絡的進化曲線如圖3所示,優化算法的訓練次數為50次,得出BP網絡的平均收斂次數為85。遺傳算法優化BP網絡的訓練曲線如圖4所示,與傳統BP網絡相比,收斂明顯加快,也沒有發生訓練振蕩。
4 結論
(1)用遺傳算法優化的BP網絡和單純的BP網絡相比,無論是在收斂速度還是在訓練的穩定性方面都表現出優勢。
(2)將遺傳算法與BP神經網絡的結合充分發揮了遺傳算法的全局搜索能力優勢和BP神經網絡的非線性映射能力和泛化能力的優勢,提高了網絡的性能,得到理想的實驗效果,有效適用于對矮小兒童的智能診斷。
參考文獻:
[1] 魏海坤. 神經網絡結構設計的理論與方法[M]. 北京:國防工業出版社, 2005.
[2] 祁建勤, 凌 星, 李亞玲, 等. 矮小兒童發病因素臨床分析[J]. 中國兒童保健雜志, 2006,14(1):94-95.
[3] 王 華,胡學鋼.醫學數據挖掘中的數據預處理與Apriori算法改進[J]. 計算機系統與應用,2009,9(1):94-97.
[4] P KAELO, M M ALI. Integrated crossover rules in real coded genetic algorithms[J]. European Journal of Operational Research, 2007, 7(6):60-76.
[5] ZHEN GUOTU,YONG LU. A robust stochastic genetic algorithm for global numerical optimization[J]. IEEE Transactions on Evolutionary Computation, 2004, 8(5): 456-470.
[6] 王 南,張京軍,高瑞貞. 基于改進遺傳算法多體模型的汽車懸架參數優化[J].遼寧工程技術大學學報, 2007, 26(3):435-437.
[7] 張京軍,呂 品,高瑞貞,等. 單純同倫算法的改進遺傳算法 [J].遼寧工程技術大學學報, 2013,32(7):987-991.
[8] 熊 凌.基于遺傳算法的BP網絡全局收斂的混合智能學習算法[J].武漢科技大學學報, 2000,23(2):45-47.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
少兒美術·書法版(2021年11期)2021-10-20 06:23:28
少兒美術·書法版(2021年8期)2021-10-20 06:08:10
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
雜文選刊(2016年7期)2016-08-02 08:39:56
小天使·一年級語數英綜合(2016年6期)2016-05-14 12:21:05
現代企業(2015年2期)2015-02-28 18:45:09
