三維蟻堆算法在視頻關鍵幀提取中的應用
2014-05-10 06:07:13吳開興沈志佳
河北工程大學學報(自然科學版) 2014年1期
吳開興, 沈志佳
(河北工程大學 信息與電氣工程學院, 河北 邯鄲 056038)
隨著計算機的普及和網絡技術的不斷發展,越來越多的視頻數據不斷涌現。如何對這些數據進行高效的存儲、瀏覽和檢索便顯得十分重要[1-2]。在基于內容的視頻檢索中,關鍵幀提取是最關鍵的技術之一。目前關鍵幀提取技術方法很多[3-10],但多數存在提取效果不理想或算法復雜等問題。本文主要是在傳統蟻堆算法的基礎上,提出了一種改進的三維蟻堆算法,將傳統算法的螞蟻運動路徑擴展到三維平面。則三維平面與三維視頻幀特征向量的幀數一致,從而提高了聚類的查全率和查準率。
1傳統的蟻堆算法
螞蟻是一種社會性昆蟲,具有自組織、自適應、分布式、相互通信、相互合作等特點。模擬螞蟻的這些特性,我們可以解決許多很復雜的問題。Deneubourg等人從螞蟻堆積尸體中受到啟發,提出了一種基本模型BM(Basic Model)。Lumer和Faieta在BM的基礎上進行了改進,增加了數據對象的相似性表達式,提出了用于數據聚類的LF算法。LF算法的基本思想如下:將N個數據對象隨機的投入到M×M的網格中,將A只螞蟻也隨機的投入到該網格中,螞蟻沿著網格隨機移動,螞蟻遇到數據對象后,根據該數據對象與螞蟻可視范圍內數據對象的相似度,以一定的概率負載數據對象,負載數據對象的螞蟻沿著網格隨機移動,當遇到空網格后,根據負載與可視范圍內數據對象的相似度,以一定的概率卸載負載,然后未負載的螞蟻繼續隨機移動。
設螞蟻的可視范圍為r,則相似度計算函數為如下公式[8]:
(1)
d(oi,oj)為數據對象oi與oj的距離,通常用歐式距離,a為相似性參數,neigh(r)表示以r為半徑的圓形區域。
Pp和Pd分別為螞蟻拾起對象和放下對象的概率,計算如公式(2)(3)[8]所示。
(2)
(3)
2 改進的蟻堆算法在關鍵幀提取中的應用
傳統的蟻堆算法,是基于二維平面的,數據對象是以隨機的方式投入到二維網格上。本文在傳統蟻堆算法的基礎上,將其擴展到三維平面,數據對象以其在H-S-V空間中的三維特征向量為坐標,分布在三維立體網格上。這樣,數據對象之間的歐式距離,便是其在三維空間中的直線距離,距離近的數據對象聚集在一起,因此,數據對象已在一定程度完成了初始聚類。
首先進行視頻幀特征向量的提取。視頻幀的每個像素均可以在H-S-V空間中表現出來,其中H的取值范圍為[0,360],S和V的取值范圍均為[0,1],為了使視頻幀的距離計算更加有效,將S和V的取值乘以360,使S和V的取值范圍也擴展到[0,360],這樣就得到了關于每個象素的三維特征向量。計算第n幀整幅圖像的平均特征向量Xn,兩幀之間的歐式距離d(oi,oj)便可由公式(4)表示:
(4)
其中xnk為特征向量Xn的k維分量。
將每一個視頻幀映射到三維的歐式空間,這樣,兩幀之間的歐式距離便可由三維空間中兩點的直線距離表示。
一段鏡頭便可由三維空間中一系列的散點表示,如下圖1。
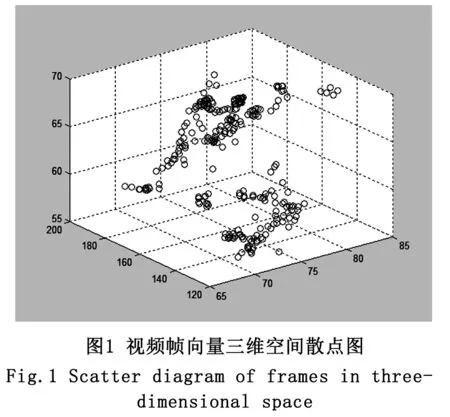
之后,我們通過對傳統蟻堆算法進行改進,使其適應于H-S-V三維空間。具體的改進方面如下,
(1)將數據對象按照其在H-S-V中的坐標放在三維數據空間中,由于數據對象在三維空間中的實際距離,即是其歐式距離,從某種程度說,數據對象,已經完成了初始聚類。
(2)由于數據對象在三維空間中已經有一定的聚類性質,初始放置螞蟻時,將螞蟻均勻的分布在三維空間中,并且使每一只螞蟻,在一個已有數據對象的網格內,避免螞蟻對于負載的饑餓。
(3)數據對象周圍的數據對象有很大幾率屬于同一聚類,因此,螞蟻放下負載后,自動尋找與此數據對象最近的負載點,減少螞蟻的無意義運動。
(4)螞蟻拾起負載后,有很大概率,在其負載周圍再次放下負載,因此,螞蟻以負載初始位置為圓點,在半徑r1為1的球面內運動,如果在此球面內不能放下負載,則半徑r1+1,直到螞蟻放下負載為止。此改進點的目的是使螞蟻在較短的步數內,在正確位置放下負載,這也是因為數據對象之間的歐式距離就是其實際距離,歐式距離近的數據對象已經聚集在一起的緣故。
(5)如果螞蟻欲放下負載的位置已有其它的數據對象,則在此位置的鄰域內求其放下對象的概率。如果所有的領域都不能放下,則螞蟻回到原先的運動路徑,繼續在以r1為半徑的球面內移動。
(6)定義數據對象的優先級,如果,螞蟻經過較少的步驟,即放下數據對象,說明數據對象已經在其正確位置,則此數據對象需要再次移動的概率很低,我們就賦予此數據對象較低的優先級,否則賦予較高的優先級,當條件一樣時,即步驟3中存在多個最近負載點時,螞蟻優先負載優先級較高的負載點,如果優先級一致則隨機選取。
(7)參數a的確定非常依賴使用者的經驗,使算法缺少普適性。算法中a初始值設為0.1,如果迭代時,螞蟻放下對象失敗次數與迭代次數的比值大于0.99,則a增加0.01,否則減少0.01。
(8)當蟻堆算法迭代到一定次數t后,數據對象已完成了進一步的聚類,按照文獻[11]所述方法,再一次提取每一幀的H-S-V顏色直方圖。之后以每一幀中H-S-V顏色直方圖的72維特征向量為標準,以蟻堆算法提取的聚類中心和聚類個數作為參考,通過K-均值聚類算法完成最終的聚類。則最終聚類中,距離每一個最終聚類中心距離最小的維特征向量所代表的視頻幀,即為我們所需要的關鍵幀。最終聚類選取72維顏色直方圖作為特征向量是因為,采用72維特征向量,比前述三維特征向量在計算歐式距離時更精確,最終聚類的結果也會更準確。
3 實驗結果與討論
利用三維蟻堆算法提取出的基于前圖1所代表鏡頭的關鍵幀如下圖2所示。

可見提取出的關鍵幀分別代表了停車場某一個車位,汽車的動態變化,提取出的關鍵幀具有代表性。
利用本算法提取出的某個演講鏡頭的關鍵幀如圖3所示。

由于該演講鏡頭內視頻內容變化很少,所以僅提取出了唯一的關鍵幀,由此可見,本算法具有自適應性,能夠根據鏡頭內容的復雜程度,自適應的提取出不同數量的關鍵幀。
為了驗證算法的有效性,本文采用了120個不同的鏡頭來對算法進行分析。具體的實驗結果如下圖4、圖5所示。

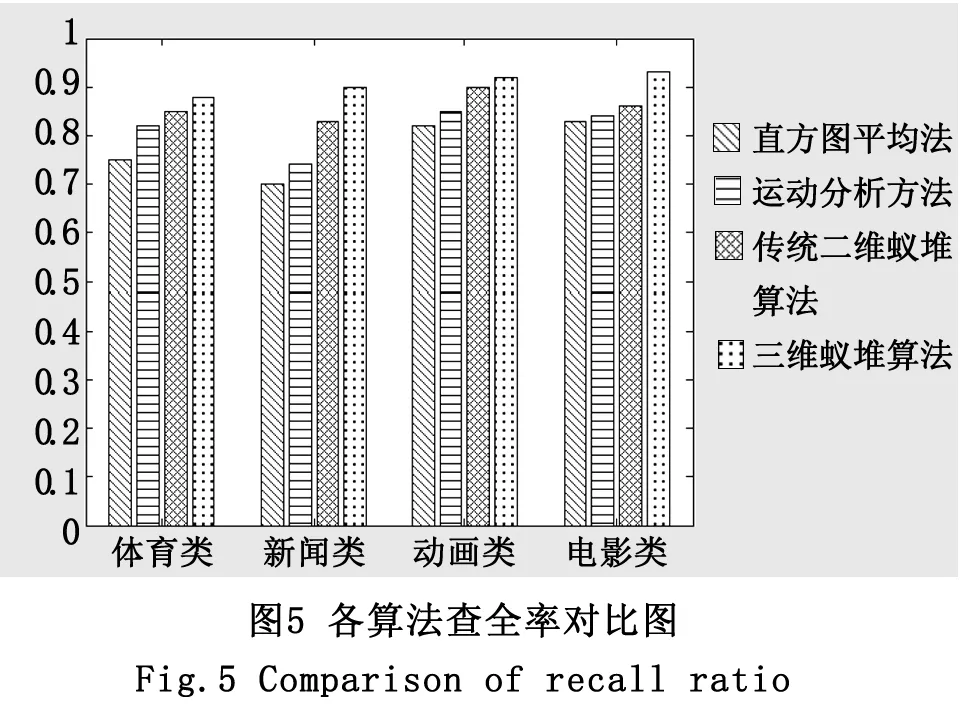
可見,無論是在體育類,新聞類,動畫類,電影類的視頻中,本文算法的查全率和查準率,都優于其它的傳統算法。
4 結論
(1)本算法能夠根據鏡頭內容的復雜程度,自適應地提取出不同數量,且具有代表性的關鍵幀。
(2)在體育類、新聞類、動畫類、電影類的視頻中,本文算法的查全率和查準率都優于傳統的直方圖法,運動分析法和二維蟻堆算法。
參考文獻:
[1] TANIGUCHI Y. An intuitive and efficient access interface to real- time incoming video based on automatic indexing [C]// Proc of ACM Multimedia. San Francisco,1995: 25-33.
[2] 汪 勤. 基于視頻圖像處理的無人值守變電站在線檢測的研究[J]. 四川理工學院學報: 自然科學版, 2013, 26(3): 91-94.
[3] 瞿 中, 高騰飛, 張慶慶.一種改進的視頻關鍵幀提取算法研究[J]. 計算機科學, 2012(8): 300-303.
[4] 柴饒軍, 馬彩文. 圖像序列中目標關鍵幀快速搜索算法[J]. 光子學報, 2004(10):1233-1235.
[5] WORF W. Key frame selection by motion analysis[C]//Proc of IEEE International Conference on Acoustics Speech and Signal Processing. Atlanta, 1996: 1228-1231.
[6] 顧家玉,覃團發,陳慧婷. 一種基于MPEG-7顏色特征和塊運動信息的關鍵幀提取方法[J]. 廣西大學學報: 自然科學版, 2010(2): 310-314.
[7] YANG SHUPING, LIN XINGGANG. Key frame extraction using unsupervised clustering based on a statistical model[J]. Tsinghua Science and Technology,2005(2): 169-173.
[8] HUA MAN, JIANG PENG. A feature weighed clustering based key-frames Extraction method[C]. // Proceedings of the 2009 International Forum on Information Technology and Applications. Piscataway,2009: 69-72.
[9] 張建明, 劉海燕, 孫淑敏. 改進的蟻群算法與凝聚相結合的關鍵幀提取[J]. 計算機工程與應用, 2013(3): 222-226.
[10] 賈存鋒, 朱加雷, 焦向東, 等. GMAW熔滴過渡高速攝像系統與熔滴邊緣提取[J]. 河北科技大學學報, 2013, 34(4): 316-319.
[11] 王 娟,孔 兵,賈巧麗,等. 基于顏色特征的圖像檢索技術[J]. 計算機系統應用, 2011(7):160-164.
