基于人工神經(jīng)網(wǎng)絡(luò)的堿性蛋白酶水解乳清蛋白預(yù)測模型的建立
2014-05-10 06:05:18蘇玉玲劉雯田波馮志彪
食品工業(yè)科技 2014年7期
關(guān)鍵詞:模型
蘇玉玲,劉雯,田波,*,馮志彪
(1、東北農(nóng)業(yè)大學食品學院,黑龍江哈爾濱 150030;2、東北農(nóng)業(yè)大學理學院,黑龍江哈爾濱 150030)
乳清蛋白營養(yǎng)價值極高,是國際上公認的人體最優(yōu)質(zhì)蛋白質(zhì)補充劑之一[1]。其不僅容易消化,且具有較高的生物活性。大量研究表明,通過酶解乳清蛋白,不僅可以改善其功能特性,且在水解過程中能釋放許多有著特殊生物活性的肽段。因此,有目的地控制乳清蛋白的水解進程,可獲得不同分子量的小肽,對于開拓乳清蛋白的應(yīng)用具有重要意義[2]。
蛋白質(zhì)的水解度(Degree of hydrolysis, DH)是衡量蛋白質(zhì)水解程度的一個重要指標[3]和重要性狀參數(shù),用于評價蛋白肽腱的斷裂的情況以及肽的平均分子量的變換。蛋白的水解程度與蛋白功能特性的改善或是釋放出某種生理功能的生物活性肽有很大關(guān)系。在實際應(yīng)用過程中所有的水解并非要達到最大的水解度最有益,有限水解對改善含蛋白質(zhì)體系質(zhì)構(gòu)特征的加工藝技術(shù)的研究有著較大的實用意 義。張雅麗[3]等人對大豆蛋白芝麻蛋白的合成類蛋白質(zhì)研究中指出最佳的底物為水解度為 80%水解物,并非最大的水解度 90%的水解物。劉佳[4]也在大豆蛋白ACE抑制肽的研究中得出:水解度與ACE抑制活性之間存在一定的對應(yīng)關(guān)系,水解度的較低和較高都會降低ACE的抑制活性。彭新顏[5]也指出,并不是水解度越大,所得產(chǎn)物的抗氧化效果越好,而是只有在特定的水解度下,水解物具有最大的抗氧化能力。因此,為了優(yōu)化操作,縮短試驗時間,便于試驗條件選擇,需要對有限水解過程進行模型化研究。
神經(jīng)網(wǎng)絡(luò)(Artificial neural networks,ANNs),是一種仿效腦的神經(jīng)網(wǎng)絡(luò)行為特征的數(shù)據(jù)分析方法。神經(jīng)網(wǎng)絡(luò)以神經(jīng)元陣列來模擬生物體學習和記憶的方式,通過改變網(wǎng)絡(luò)的突觸鏈接點的連接關(guān)系對信息進行編碼。ANNs應(yīng)用于一個實際問題通常需要五個步驟,在每個步驟中,研究者必須要選擇適當?shù)木W(wǎng)絡(luò)參數(shù)[6,7]。每個步驟的選擇都基于經(jīng)驗以及現(xiàn)存的指導(dǎo)準則和應(yīng)用實例。第一步,對于網(wǎng)絡(luò)拓撲結(jié)構(gòu)和每層的神經(jīng)元數(shù)量的選擇[8,9]。第二步,為隱藏的神經(jīng)元選擇變換算符[6]。第三步是初始分配的權(quán)重。第四步是訓(xùn)練過程,最常見的訓(xùn)練技術(shù)是反向傳播技術(shù)。最后,是利用未被用于訓(xùn)練的數(shù)據(jù)(測試集)檢驗所建立的神經(jīng)網(wǎng)絡(luò)的效果。測試結(jié)果也可以預(yù)測網(wǎng)絡(luò)運行過程和監(jiān)測系統(tǒng)的效力[7]。
ANNs的特點不僅可以處理嘈雜、不完整的數(shù)據(jù)和非線性問題,也可以在訓(xùn)練過程之后立即進行預(yù)測和歸納[8]。即使反應(yīng)的機理不明確這種技術(shù)仍可以準確預(yù)測[10,11];ANNs優(yōu)于其他模型之處還在于可以一邊辨識網(wǎng)絡(luò)構(gòu)造參數(shù),一邊學習和適應(yīng)樣本。在食品科學研究中,ANNs用于估計預(yù)測食品性質(zhì)和加工中相關(guān)的因素,例如葡萄糖淀粉酶對淀粉的水解模型,酶失活的動力學模型,利用視覺技術(shù)及氣味分辨技術(shù)評價食品質(zhì)量、品質(zhì)等[12-14]。本實驗的研究目標是建立堿性蛋白酶促乳清分離蛋白水解的ANNs預(yù)測模型。
1 材料與方法
1.1 材料與設(shè)備
Alcalase堿性蛋白酶 丹麥NOVO公司;乳清分離蛋白WPI 美國HILMAR公司。
PHS-3C型pH計 上海雷磁儀器廠;磁力加熱攪拌器 杭州儀表電機廠。
1.2 乳清蛋白的水解
稱取一定量的乳清蛋白,加入蒸餾水中,攪拌均勻,80℃加熱10min,作為儲備液。儲備液在恒溫磁力水浴鍋50℃水浴,加酸(HCl)或堿(NaOH)達到預(yù)定的pH值,加入試驗設(shè)計量的 Alcalase酶進行水解,水解時間為試驗設(shè)計的時間。水解過程保持不斷地攪拌,加入NaOH以維持pH值的變化在規(guī)定范圍的±0.05內(nèi),達到預(yù)定時間后,加入2mol·L-1HCl調(diào)節(jié)pH值至4.0,使未水解的蛋白沉淀下來,100℃水浴15min對酶進行滅活,然后迅速冷卻至室溫,置于離心機中,以4000r·min-1離心20min,分離出上清液[15]。
1.3 水解度的測定
水解過程中通過從滴定管中連續(xù)的添加少量1mol·L-1NaOH保持pH為試驗設(shè)定值。添加量如下:第一次是水解5min后,隨后在120min內(nèi)每次間隔10min,120min后每次間隔20min。水解度計算公式為[16]:
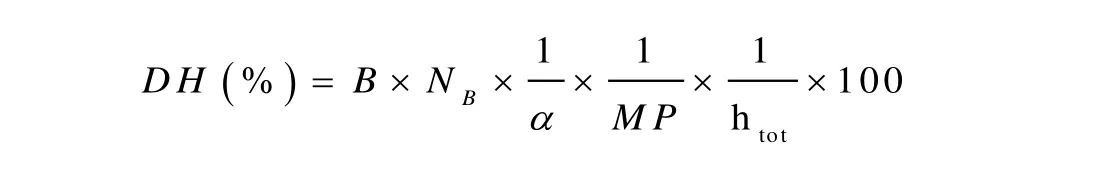
式中,B為NaOH用量(mL);
NB是NaOH的標定濃度(mol·L-1);
α是α-氨基基團的平均離解度;
MP是水解蛋白的質(zhì)量(g);
htot是蛋白質(zhì)總肽鍵數(shù).
1.4 正交試驗
正交表L25(56)設(shè)計試驗,取四個主要因素pH值、酶用量、底物濃度、水解時間,每個因素設(shè)為五個水平,設(shè)一個誤差列考察試驗誤差,列出影響因素與水平表1,每個試驗重復(fù)三次。用Excel對正交試驗結(jié)果進行分析。

表1 L25(56)的影響因素與水平Table 1 Factors and levels of orthogonal experiment
1.5 人工神經(jīng)網(wǎng)絡(luò)模擬
在正交試驗的基礎(chǔ)上,對正交試驗所得到的的25組數(shù)據(jù)和驗證組7組數(shù)據(jù),總計32組數(shù)據(jù),使用Matlab的nnet工具包中的nftool建一個神經(jīng)模型。實驗相關(guān)參數(shù)設(shè)定如下:一般屬性為 4個, 分別是乳清蛋白水解的pH值、酶用量、底物濃度、水解時間, 目標屬性是水解度(DH/%);將數(shù)據(jù)集隨機的分為三組:訓(xùn)練集、測試集和驗證集(80%,10%,10%);在訓(xùn)練過程中設(shè)定隱含層節(jié)點數(shù)為15。由于nftool包的初始值為隨機值,因此每次擬合的效果有一定的隨機性,因此需要多擬合幾次,從中選擇效果較好的擬合曲線作為訓(xùn)練出的網(wǎng)絡(luò)。
2 結(jié)果與討論
2.1 水解度的正交結(jié)果
根據(jù)表 1 的因素和水平進行正交實驗設(shè)計,按照設(shè)計的實驗點進行實驗,測得各因素水平組合下的水解度(DH),結(jié)果見表 2,結(jié)果進行3 次重復(fù)。
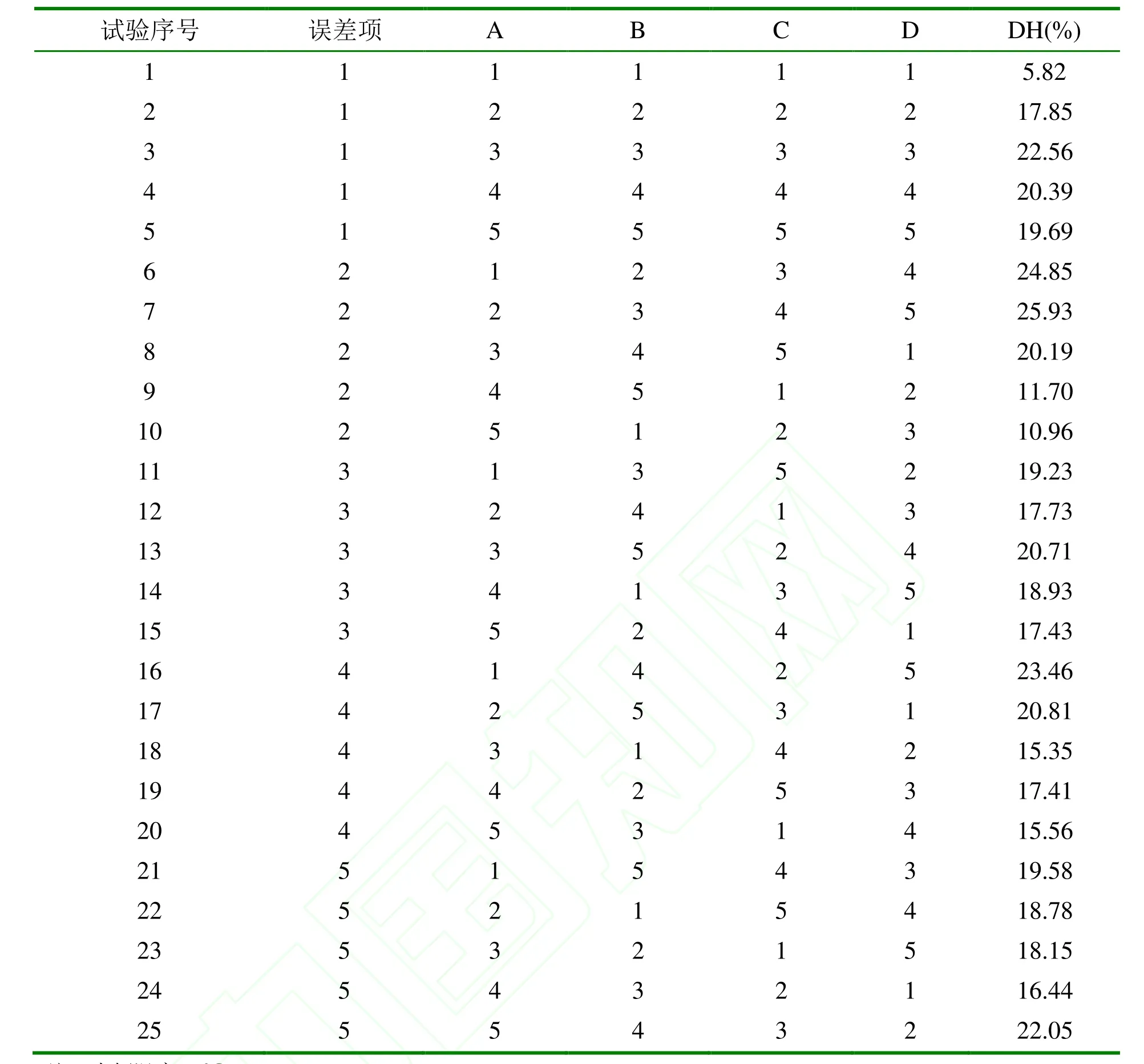
表2 正交試驗結(jié)果Table 2 Results of orthogonal test
2.2 神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu)及參數(shù)選擇
預(yù)測乳清蛋白水解過程,采用擬動力神經(jīng)網(wǎng)絡(luò),見圖1。為了提高網(wǎng)絡(luò)模型性能,選用兩步反向結(jié)構(gòu),這種結(jié)構(gòu)被用于神經(jīng)網(wǎng)絡(luò)已經(jīng)有很長的歷史了。本實驗設(shè)置了15個隱藏神經(jīng)元,選用Levenberg-Marquardt訓(xùn)練算法(8個訓(xùn)練元;訓(xùn)練過程從隨機初始權(quán)重值開始,并被重復(fù) 100次,以獲得最佳的解決方案)[17],采用隨機分配的權(quán)重值,本實驗數(shù)據(jù)庫中包含32個數(shù)據(jù)用于神經(jīng)網(wǎng)絡(luò)模型訓(xùn)練。

圖1 人工神經(jīng)網(wǎng)絡(luò)的通用結(jié)構(gòu)Fig.1 The general structure of applied neural model
2.3 乳清蛋白水解神經(jīng)網(wǎng)絡(luò)擬合結(jié)果分析
誤差直方圖如圖2所示,縱坐標代表樣本點個數(shù),橫坐標代表誤差區(qū)間。各樣本點與零誤差線之間差距代表樣本點與預(yù)測值之間的誤差。可見絕大多數(shù)樣本點分布在零誤差線的區(qū)間內(nèi)。而由測試集的分布可知,首先,測試集樣本點在零誤差線左右都有分布,說明誤差分布均勻;再次,測試集有四個點分布在(±1.000)的范圍內(nèi)。說明測試集中的樣本點與預(yù)測所得輸出值之間誤差較小,說明預(yù)測效果良好,數(shù)據(jù)基本分布在擬合的曲線附近。

圖2 誤差分布直方圖Fig.2 Error Histogram
人工神經(jīng)網(wǎng)絡(luò)訓(xùn)練乳清蛋白水解模型其擬合回歸系數(shù)R-value,表現(xiàn)輸出數(shù)據(jù)與目標數(shù)據(jù)之間的相關(guān)狀況。圖3可知,Training、Test與All圖中R-value分別為0.98536、0.96239和0.97995,圖中實線為擬合效果曲線,與R-value =1的標準曲線基本吻合,斜率接近45°,測試點和樣品點均勻的分布在擬合曲線附近,因此說明此模型具有較好的訓(xùn)練效果、預(yù)測能力和整體擬合效果。Validation圖中R=1,說明當前設(shè)置的參數(shù)下,擬合結(jié)果隨機驗證效果優(yōu)良。對于訓(xùn)練數(shù)據(jù),不僅相關(guān)系數(shù)據(jù)在0.9600~0.9999范圍內(nèi),而且該模型是在實驗數(shù)據(jù)的基礎(chǔ)上得到的,總是包含噪聲,例如測量誤差等。因此我們可以認為本實驗所建立的人工神經(jīng)網(wǎng)絡(luò)的水解模型能夠準確地預(yù)測實驗結(jié)果。

圖3 擬合回歸及驗證測試圖Fig.3 Plotregression and verification figure
2.4 預(yù)測結(jié)果對比
訓(xùn)練好的網(wǎng)絡(luò)經(jīng)過驗證可以判定其效果,5組數(shù)據(jù)的預(yù)測結(jié)果見表3。
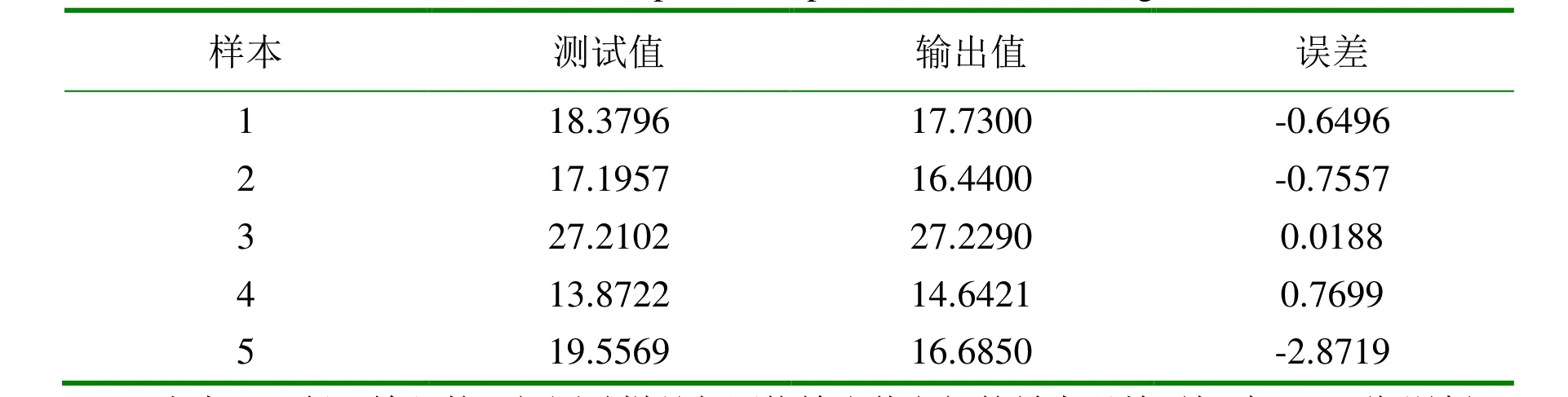
表3 預(yù)測結(jié)果對比表Table 3 Comparison of prediction results to target
由表3可得,輸入的5組測試樣品與網(wǎng)絡(luò)輸出值之間的最大誤差不超過3%,說明神經(jīng)網(wǎng)絡(luò)預(yù)測模型具有較高的預(yù)測能力和精度,模型可用于對水解程度的預(yù)測,對堿性蛋白酶有限水解乳清蛋白具有指導(dǎo)意義。
3 結(jié)論
本實驗在正交試驗所得數(shù)據(jù)的基礎(chǔ)上,選用3層人工神經(jīng)網(wǎng)絡(luò),設(shè)置了15個隱藏神經(jīng)元,選用ANN神經(jīng)網(wǎng)絡(luò)方法建立了水解模型,迭代計算后最終整體R-value=0.97995,結(jié)果表明該神經(jīng)網(wǎng)絡(luò)擬合效果很好,而對于測試集合的 R-value=0.96239,表明該水解模型有很好的預(yù)測能力,能夠完成實驗結(jié)果的預(yù)測。選用的測試組的實驗結(jié)果與神經(jīng)網(wǎng)絡(luò)輸出值之間的誤差均在±3%以內(nèi),說明其具有良好的預(yù)測能力。從以上結(jié)果可知,在有限水解范圍內(nèi),神經(jīng)網(wǎng)絡(luò)預(yù)測模型能夠很好的預(yù)測水解程度,可以用此模型進一步研究的蛋白功能特性和多肽的生理生物活性物質(zhì),并且更利于水解條件的選擇,還可以縮短必要的工藝時間。
[1]韓雪,孫冰.乳清蛋白的功能特性及應(yīng)用[J]. 中國乳品工業(yè), 2003,31(3):28-30.
[2]Pouliot Y. Fractionation of whey protein hydrolysates using charged UF/NF membrans[J].Membr.Sci, 1999,158:105-114.
[3]張雅麗,王鳳翼,宋世廉等.蛋白質(zhì)酶法修飾的初步探討-大豆蛋白和芝麻蛋白的合成類蛋白質(zhì)研究[J]. 食品與發(fā)酵工業(yè), 1994,3:8-13.
[4]劉佳,大豆蛋白ACE抑制肽的研究[D]. 無錫: 江南大學, 2008.
[5]彭新顏 ,孔保華,熊幼翎.由堿性蛋白酶制備的乳清蛋白水解物抗氧化活性的研究[J]. 中國乳品工業(yè), 2008,36(4):8-13.
[6]Patnaik P R.Applications of neural networks to recovery of biological products[J]. Biotechnol.Adv,1999,17:477-488.
[7]Baugham D R, Liu YA. Neural Networks in Bioprocessing and Chemical Engineering[D].Virginia: Virginia Polytechnic Institute and State University , 1995.
[8]Morris AJ, Montague GA, Willis M J. Artificial neural networks: studies in process modelling and control[J]. Trans. I. Chem. Eng,1994,72A:3-19.
[9]Patnaik P R.Preliminary screening of neural network con-figurations for bioreactor applications[J]. Biotechnol Tech,1996,10:967-970.
[10]Huang J,Mei LH,Xia J.Application of artificial neural network coupling particle swarm optimization algorithm to biocatalytic production of GABA[J]. Biotechnol Bioeng,2007,96:924.
[11]Liu HL,Yang FC,Lin HY,et al.Arti fi cal neural network to predict the growth of the indigenous Acidthiobacillus thiooxidans[J]. Chem Eng J,2008;137:231.
[12]Geeraerd A H, Herremans C H, LR Ludikhuyze, et al. Modeling the kinetics of isobaric-isothermal inactivation of Bacillus subtilis a-amylase with artificial neural networks[J].Food Engineering,1998,36:263-279.
[13]Bryjak J, Murlikiewicz K, Zbicin′ski I, et al.Application of artificial neural networks to modelling of starch hydrolysis by glucoamylase[J]. Bioprocess Engineering, 2000,23:351-357.
[14]Du C J, Sun DW. Learning techniques used in computer vision for food quality evaluation: A review[J]. Food Engineering , 2006,72:39-55.
[15]Spellman D, McEvoy E, O’Cuinn G, et al.Proteinase and exopeptidase hydrolysis of whey protein:Comparison of the TNBS,OPA and pH stat methods for quantification of degree of hydrolysis [J]. International Dairy, 2003, 13 (6):447-453.
[16]Buciński A. Modeling the tryptic hydrolysis of pea proteins using an artificial neural network [J]. LWT-Food Science and Technology, 2008, 41(5 ):942-945.
[17]Hagan M T, Menhaj M B.Training feedforward networks with the Marquardt algorithm[J].Neural Networks, IEEE Transactions on ,1994,5: 989-993.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學報(2022年4期)2022-08-15 08:27:00
中學生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數(shù)學備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數(shù)學備考)(2020年9期)2021-01-04 00:25:14
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
