認知行為計算模型結合DM的教學質量提升
2014-04-03 01:45:18彭麗蓉
計算機工程與應用 2014年9期
彭麗蓉,周 磊
PENG Lirong1,ZHOU Lei2
1.重慶工業(yè)職業(yè)技術學院 科研處,重慶 401120
2.國際商業(yè)機器(中國)有限公司,浙江 寧波 315040
1.Scientific Research Office,Chongqing Industry Polytechnic College,Chongqing 401120,China
2.IBM(China)Company Limited,Ningbo,Zhejiang 315040,China
隨著教育的不斷發(fā)展,教學和管理工作中積累了大量的數(shù)據(jù),但這些數(shù)據(jù)并沒有得到有效利用。如果能將這些數(shù)據(jù)充分利用,則可以有效地提升教學質量[1]。數(shù)據(jù)挖掘是一種核心的、非教學的、客觀的評價技術,可用于基于學習及訓練系統(tǒng)的應用分析[2]。基于學習者表現(xiàn)的分類是一項重要的任務,可以節(jié)約學習者的時間和精力[3]。因此,如何將數(shù)據(jù)挖掘技術運用到教學中來提升教學質量顯得非常重要。
數(shù)據(jù)挖掘過程的目的是運用不同的技術從大量的數(shù)據(jù)集中去發(fā)現(xiàn)新的、有趣的及有用的知識,包括預測、分類、聚類聯(lián)合規(guī)則挖掘和序列模式[4-5]。學者們提出了許多不同的運用于教學的數(shù)據(jù)挖掘方法,例如,文獻[6]針對傳統(tǒng)的求總分統(tǒng)計成績方法的不足提出了一種基于K-Means算法的成績聚類分析算法,實驗結果表明,聚類方法比傳統(tǒng)的求總分方法更合理、更科學,聚類結果蘊含更多有用的信息,而且改進后的聚類方法降低了隨機選取初始聚類中心所產(chǎn)生的結果的不穩(wěn)定性,聚類效果更好。文獻[7]根據(jù)本科學生的知識體系不夠完善的問題提出了經(jīng)濟管理類本科生“數(shù)據(jù)挖掘”課程有針對性的教學方法,實踐表明,這種注重數(shù)據(jù)挖掘方法思想及實踐的方法在該課程的教學質量及實效方面起到了良好的推動作用。文獻[8]將數(shù)據(jù)挖掘技術中的關聯(lián)規(guī)則挖掘算法Apriori應用于教學評價中,通過對這些數(shù)據(jù)的分析,表明了高校教師的教學效果與教師的年齡、職稱、學歷等密切相關。文獻[9]在現(xiàn)有教學評估系統(tǒng)研究的基礎上,重點論述了基于數(shù)據(jù)挖掘技術的教學評估智能輔助決策平臺設計的相關方法,并對該平臺的應用情況進行了分析,結果表明該平臺能智能化提升教學質量。這些數(shù)據(jù)挖掘方法都集中在自適應學習[7]上,分析學習解決方案,進而在在線學習中尋找最佳的學習路徑。文獻[10]提出,學習者的學習行為和他們感覺滿意的互動對于涉及和評估這些活動顯得尤為重要。
受文獻[10]的啟發(fā),為了更好地改善教學質量,提出了基于認知行為計算模型的數(shù)據(jù)挖掘模型,搜索了一些技術去確定學習課程的目標、詳細的互動內容及學習行為隨時間推移而發(fā)生的變化,通過學生類別選取實驗表明了所提模型的有效性。
1 問題描述
本文著重關注學習策略問題以及使用數(shù)據(jù)挖掘方法的學習表現(xiàn),以更好地支持教師的教學工作。該問題由所收集的六個感知參數(shù)和三個行為參數(shù)描述。對于輸入來說,三個感知參數(shù)和三個行為參數(shù)很重要。數(shù)據(jù)挖掘(Data Mining,DM)幫助提取和分析各種感知與行為參數(shù)之間有意義的關系,并且它提供基于307條記錄的有關參數(shù)的相對重要性。根據(jù)應用在C&RT的實驗,有兩種規(guī)則用于分類(上、中和下),對于C&RT而言,其算法的整體精度為100%。
2 計算模型提出
2.1 認知計算模型
很多學者都對認知計算模型進行過研究,考慮到心理狀態(tài)、心理參數(shù)和認知參數(shù)會在一般性的任務中體現(xiàn)出來,開發(fā)了BDI(信念、意愿及決心)理論用于在認知任務中對精神狀態(tài)進行建模。
(1)表現(xiàn)成績:根據(jù)學生回答問題的優(yōu)秀類數(shù)目、相對較好類數(shù)目、無缺陷類別數(shù)目,對學生的表現(xiàn)成績進行計算:
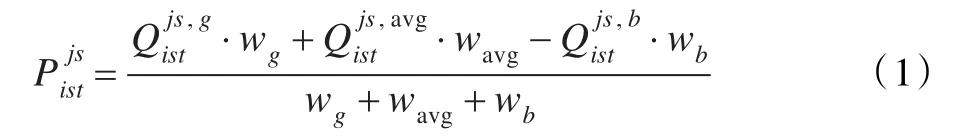
該問題中,假定 wg=0.4,wavg=0.15,wb=0.45。 wb取較高數(shù)值時,式中起消極作用。
(2)性能(帶難度權重):用wd乘以,wd與問題的難易程度相關,表現(xiàn)成績(帶難度權重)定義為:上式中,是帶難度權重的表現(xiàn)成績,wd根據(jù)難易程度的難度權重值確定。

(3)能力:它是在表現(xiàn)成績、難度權重、帶難度的表現(xiàn)成績及回答問題的總數(shù)基礎上計算得到的,能力值體現(xiàn)了某個特定的學生可以回答問題的多少。能力由下式定義:
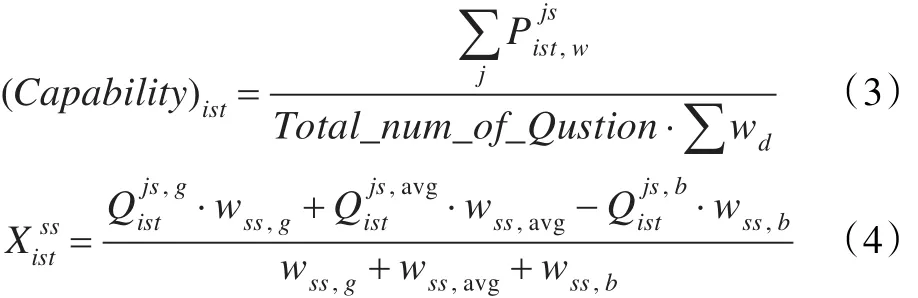
該問題中,假定 wg=0.4,wavg=0.15,wb=0.45,wss,b取較高數(shù)值時,在式中起消極作用。
(4)意愿:它表征了學生回答問題的意愿,基于總因子X和難度權重。意愿由下式定義:
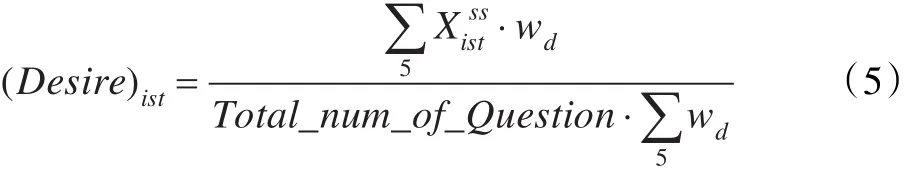
(5)取向:一個學生的取向在社會實踐推理中起著積極的作用,選擇問題并用決心去完成它。取向由下式定義:
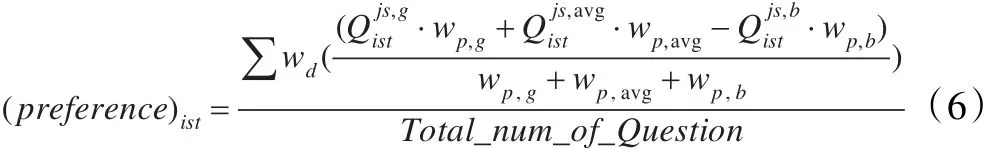
該問題中,假定 wg=0.4,wavg=0.15,wb=0.45,wb取較高數(shù)值時,在式中起消極作用。
(6)決心:決心表示學生承諾去完成的一些問題,是基于選擇(意愿)和取向計算得到的。決心如下定義:
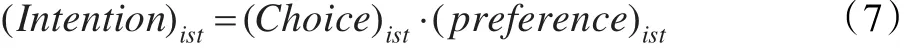
(7)承諾:它意味著將你自己綁定到某種行動中。承諾如下定義:
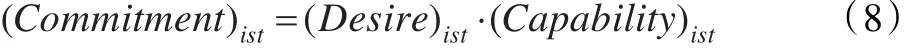
(8)認知指數(shù)因子(Cognize Index Factor,CIF):認知指數(shù)因子是基于學生的承諾和能力計算得到。感知指數(shù)因子如下定義:
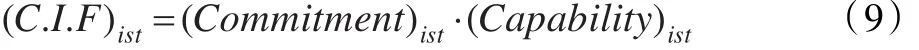
2.2 行為計算模型
(1)愉快:通常,“愉快”這個詞語表示一種高興的狀態(tài)和自我享受的感覺,這里指的是學生行為的積極性。
(2)疲勞:疲勞是指一種極度勞累的狀態(tài),可通過觀察學生的面部表情發(fā)現(xiàn),當重復地問問題時,他們一般不能全部回答出來。
(3)扭曲:意思是通過拉或者扭,形狀改變。這里用于定義一種行為參數(shù)。
(4)行為表達指數(shù)因子(Behavior Expression Index Factor,BEIF):借助行為表達指數(shù)因子,可以針對特定的問題選取學生,它是基于愉快、疲勞、扭曲計算得到的,由下式定義:
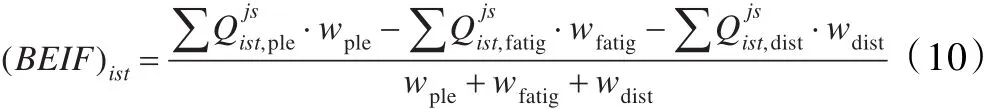
上式中,wdist>wfatig。
2.3 學生指數(shù)因子
學生指數(shù)因子(Students Index Factor,SIF):借助于學生指數(shù)因子可以針對特定的問題選取不同類別的學生,它是基于感知指數(shù)因子和行為表達指數(shù)因子計算得到的。α是一個調控指數(shù)因子,通過α可以控制SIF,一般0<α<1,這里,α=0.5。SIF如下定義:
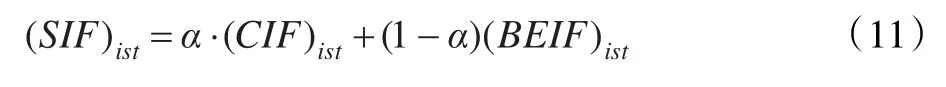
3 數(shù)據(jù)挖掘模型構建
根據(jù)以上分析,考慮既要較全面描述學生,又便于實現(xiàn),基于認知計算模型和行為計算模型,得到一個綜合學生模型,數(shù)據(jù)結構如圖1所示。

圖1 學生數(shù)據(jù)結構
在該模型中,引入了認知模型的成分,每個單元學習并測試后都要計算認知能力,以確定后續(xù)學習內容的難度以及調整知識學習的次序;同時,考慮了行為因素(如情緒等),由于對影響學習心理因素的劃分,心理因素對學習的影響也僅僅是停留在一些簡單的定性認識上,這里只考慮學習積極性、回答問題的表情及行為參數(shù)。基于認知計算模型、行為計算模型,通過本文提出的數(shù)據(jù)挖掘模型計算影響學生成績的指數(shù)因子、認知指數(shù)因子、行為指數(shù)因子,從而判斷學生指數(shù)因子受認知參數(shù)和行為參數(shù)的各自影響程度,傳統(tǒng)的教學中針對所有類別的學生都采取同樣的策略,只對部分學生有利,而運用本文提出的數(shù)據(jù)挖掘模型后,可根據(jù)學習影響因素將學生分為不同的類別,教師可以根據(jù)不同類別的學生采取不同的教學策略,具有很強的針對性。
上述數(shù)據(jù)結構描述了學生模型的靜態(tài)結構,而圖2則描述了學生模型的動態(tài)結構,動態(tài)結構表現(xiàn)了學習的過程中學生模型的四個因素的形成及其關系,以及在教學決策中的作用可以看出,學生模型是一個動態(tài)結構,它跟蹤學生的學習活動,通過對學生學習行為的分析,記錄并調整學生的知識結構、學習能力、學習習慣等描述學生個性化特征的信息,依此得出新的教學策略,其中,數(shù)據(jù)挖掘算法處于中心地位,其功能是有關數(shù)據(jù)庫的維護、決策的生成、決策沖突的消解等。
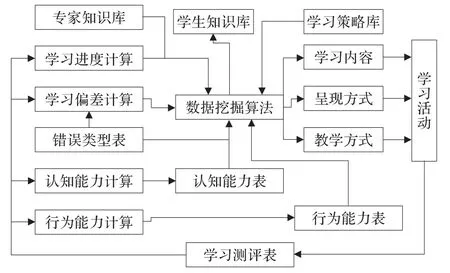
圖2 數(shù)據(jù)挖掘模型
從圖2可知,整個模型中,數(shù)據(jù)挖掘算法(如決策樹、人工神經(jīng)網(wǎng)絡等)處于核心地位,整體步驟如下:
步驟1根據(jù)認知能力計算模型、行為能力計算模型得到認知能力表、行為能力表,記錄每個學生的成績表現(xiàn)、能力、意愿、取向、決心、承諾、愉快、疲勞、扭曲等狀態(tài)。
步驟2根據(jù)認知能力表、錯誤類型表計算學生的學習偏差。
步驟3根據(jù)專家知識庫計算學生的學習進度。
步驟4基于認知能力表、行為能力表、學習進度、學習偏差,根據(jù)所搜集的六個認知參數(shù)及三個行為參數(shù),運用學習策略庫和數(shù)據(jù)挖掘算法得到學生知識庫。
步驟5給出學習內容、呈現(xiàn)方式、教學方式,結合各個學習活動得到學習測評表。
步驟6根據(jù)學習測評表、行為能力計算模型、認知能力計算模型將學生分為不同的類別,分析各類別學生中,不同的行為能力和認知能力對學生成績的影響因子。
如此,教師可根據(jù)不同類別的學生采取不同的教學策略,相比以往的教學模式,可明顯提高教學質量。
4 實驗
數(shù)據(jù)挖掘(Data Mining,DM)通常定義為,通過對大量的數(shù)據(jù)進行搜索、分析及篩選,找出關系、模式或者任意一些重要的統(tǒng)計相關性。隨著計算機、大型數(shù)據(jù)庫和互聯(lián)網(wǎng)的問世,可以很容易地收集到百萬、十億甚至萬億份數(shù)據(jù),可對其進行系統(tǒng)地分析,進而幫助尋找其中的相關關系,并且找出各種問題的解決方案。
4.1 決策樹法
決策樹是一種用于決策的分析算法,尤其是在有潛在風險或者高成本的情況下更顯重要。本文試圖使用數(shù)據(jù)挖掘算法在磋商中駕馭某些屬性的重要性。決策樹法是一種視覺的、易于理解的,可代替其他決策分析算法中的數(shù)值圖或者統(tǒng)計概率,如電子表格。決策樹適應性強,這意味著可以把它們修改成新的決策去描述它們本身,或者修改成新的信息去變得可用,進而改變原來的方案。本文運用了決策樹中的分類回歸樹(Classification and Regression Tree,C&RT)算法[11],具體的實現(xiàn)步驟可見圖3。

圖3 通過決策樹(C&RT算法)對參與者分類規(guī)則的設定
4.2 人工神經(jīng)網(wǎng)絡法
人工神經(jīng)網(wǎng)絡(Artificial Neural Network,ANN)模型執(zhí)行時,使用快速法[12]、動態(tài)法[13]以及徑向基函數(shù)網(wǎng)絡(Radial Basis Function Network,RBFN)[14]。快速法產(chǎn)生更小的隱性層,隱性層訓練得更快,生成得更好。動態(tài)法創(chuàng)建初始拓撲,然后在訓練過程中通過增加或者移除隱性單元的方式去修改拓撲。RBFN采用類似K均值類聚算法根據(jù)目標的數(shù)值去劃分數(shù)據(jù)。比較這三種算法而言,動態(tài)法提供了最準確的情況描述,針對準確性而言,它優(yōu)于其他兩種算法。這種算法產(chǎn)生更小的隱性層,該隱性層訓練得更快,生成得更好。快速法中,有六個輸入?yún)?shù),并且所有參數(shù)都有絕對值。在這六個參數(shù)中,每個參數(shù)有三個階段。所以對于有三個階段的每個絕對值,有三個神經(jīng)元。因此,ANN中的輸入層的神經(jīng)元總數(shù)是(3×6=18)。所有組合的ANN方法如表1所示。
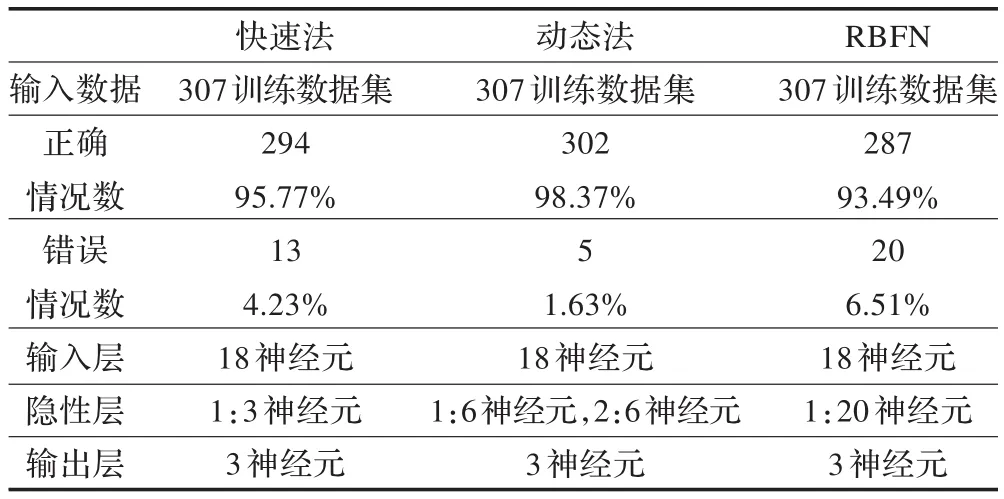
表1 所有聯(lián)合ANN法對比
4.3 靈敏度分析
靈敏度分析(Sensitivity Analysis,SA)[15]是一種分析和反映模型的輸出對于不同環(huán)境而發(fā)生分布變化的靈敏度算法。通過刪除一些對網(wǎng)絡訓練沒有影響或者影響很小的變量,靈敏度分析可以減少網(wǎng)絡結構的復雜性,也可以用于理解每個變量對網(wǎng)絡訓練的影響度。靈敏度越大,那么它對于人造神經(jīng)網(wǎng)絡的輸出的影響就越大。對于靈敏度分析,特征選擇節(jié)點有助于領域的識別,這在某個特定的輸出中是最重要的。它可能會隨著更快、更有效的算法而結束,這些算法使用更少的預測,執(zhí)行得更快,可能也更容易理解。對于靈敏度分析,特征選擇節(jié)點有助于領域識別,這在某個特定的輸出中是最重要的。ANN法的靈敏度分析如表2所示。
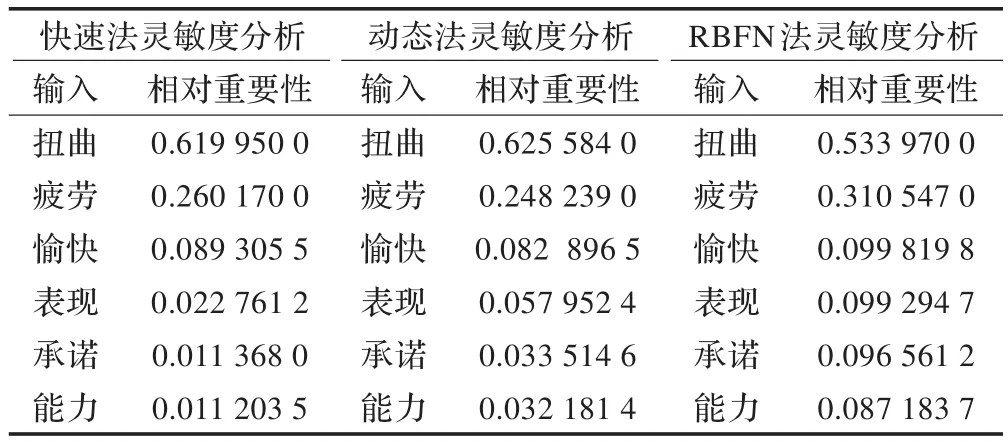
表2 ANN法靈敏度分析對比一覽
4.4 DM的特征選擇
本模式中,運用Clementine 11.1軟件的特征選擇節(jié)點來識別各個域。對于數(shù)百或者甚至上千個類別的預測,特征節(jié)點過濾、排列并且選擇這些預測,可能是最重要的。最終,它可能會以更快,更有效的模式結束,該模式下,會使用更少的預測,執(zhí)行得更快,可能也更易于理解。特征選擇的重要參數(shù)如表3所示。
4.5 執(zhí)行結果
本項研究中,開發(fā)了一個基于學習系統(tǒng)的網(wǎng)頁去執(zhí)行上面提出的算法。這里,設計了Window環(huán)境下的.net。利用Apache Tomcat作為服務器。執(zhí)行結果如表4所示。

表3 特征選擇的重要參數(shù)
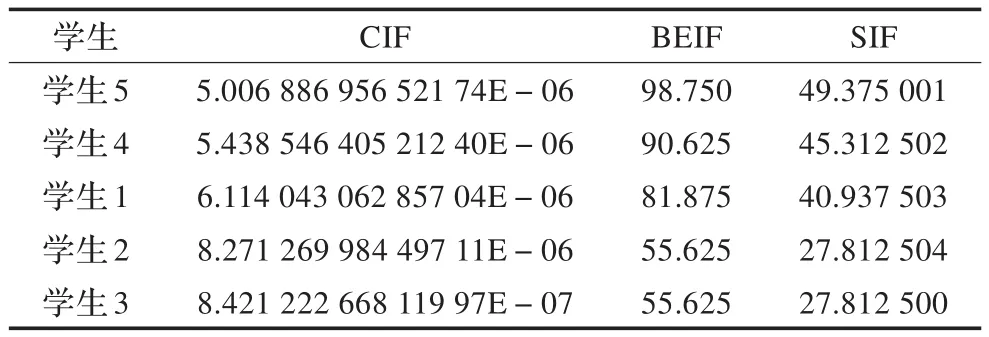
表4 所提出的在線學習系統(tǒng)執(zhí)行結果
從表4中可以看出,最好的學生指數(shù)因子SIF是49.375,各個學生的CIF相比BEIF,都非常低,又根據(jù)式(11)可得出,SIF取決于行為表達指數(shù)因子BEIF,而認知指數(shù)因子CIF可以忽略不計。
5 結束語
為了對學生進行精確的分類和范疇化,根據(jù)重要的認知、行為輸入?yún)?shù),將數(shù)據(jù)挖掘技術應用于學生數(shù)據(jù)集中,運用了人工神經(jīng)網(wǎng)絡、靈敏度分析、數(shù)據(jù)挖掘及分類回歸樹算法,聯(lián)合ANN模型(快速、動態(tài)、RBFN)去確定輸入問題類型的重要程度,將學生劃分成三種不同的類別。實驗結果表明,學生指數(shù)因子取決于行為表達指數(shù)因子,而認知指數(shù)因子可以忽略不計,由此可以得出結論,在學生分類問題中,行為參數(shù)遠比認知參數(shù)重要,教師可根據(jù)不同類別學生的愉快、疲勞、扭曲等行為表現(xiàn)對其施行不同的教學策略,從而提升各類學生的成績、改善教學質量。
未來會將基于人工神經(jīng)網(wǎng)絡的數(shù)據(jù)挖掘技術運用到其他的學生數(shù)據(jù)集上,改變參數(shù)的初始設置,進行大量的實驗,挖掘出更多有意義的信息,從而更好地在教育系統(tǒng)中支持教師的教學工作。
[1]方耀楣,何萬篷.可拓數(shù)據(jù)挖掘在高校教學質量評價中的應用[J].數(shù)學的實踐與認識,2009,39(4):82-87.
[2]阮衛(wèi)華.數(shù)據(jù)挖掘在教學系統(tǒng)中的應用[J].微計算機信息,2010(12):161-162.
[3]岳耀亮.數(shù)據(jù)挖掘在高校網(wǎng)絡教學平臺中的應用研究[J].中國教育信息化,2009,21(8):75-77.
[4]韓心慧,龔曉銳,諸葛建偉,等.基于頻繁子樹挖掘算法的網(wǎng)頁木馬檢測技術[J].清華大學學報:自然科學版,2011,51(10):1312-1317.
[5]陳偉,黃蕾,劉峰,等.雙語平行網(wǎng)頁挖掘系統(tǒng)的設計與實現(xiàn)[J].計算機工程,2009,35(14):267-269.
[6]劉美玲,李熹,李永勝.數(shù)據(jù)挖掘技術在高校教學與管理中的應用[J].計算機工程與設計,2010,31(5):1130-1133.
[7]鄧克文,喬興旺.高校經(jīng)濟管理類本科生“數(shù)據(jù)挖掘”教學研究[J].科教文匯,2011,23(9).
[8]李紅林,孔德劍.基于Apriori算法的高校教學評價數(shù)據(jù)挖掘[J].中國科技信息,2010,21(2):241-242.
[9]丁衛(wèi)平,王杰華,管致錦.基于數(shù)據(jù)挖掘技術的教學評估智能輔助決策平臺的設計與實現(xiàn)[J].電化教育研究,2009,32(4):90-92.
[10]Misra K,Misra R.Multiagent based selection of tutorsubject-student paradigm in an intelligent tutoring system[J].InternationalJournalofIntelligentInformation Technology,2010,5(1):46-70.
[11]方敏,牛文科,張曉松.分類回歸樹多吸引子細胞自動機分類方法及過擬合研究[J].計算機研究與發(fā)展,2012,49(8):1747-1752.
[12]林和平,張秉正,喬幸娟.回歸分析人工神經(jīng)網(wǎng)絡[J].吉林大學學報:信息科學版,2010(2):147-152.
[13]琚亞平,張楚華.基于人工神經(jīng)網(wǎng)絡與遺傳算法的風力機翼型優(yōu)化設計方法[J].中國電機工程學報,2009(20):106-111.
[14]朱福珍,李金宗,朱兵,等.基于徑向基函數(shù)神經(jīng)網(wǎng)絡的超分辨率圖像重建[J].光學精密工程,2010,18(6).
[15]侯建平,寧韜,蓋雙龍,等.基于光子晶體光纖模間干涉的折射率測量靈敏度分析[J].物理學報,2010,59(7):4732-4737.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
電力與能源(2017年6期)2017-05-14 06:19:37
山東工業(yè)技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
信息通信技術(2015年6期)2015-12-26 01:16:46
