面向智能搜索的動態知識網絡建模*
2014-02-28 06:12:56許洪波賈巖濤程學旗
電信科學 2014年10期
劉 劍,許洪波,賈巖濤,程學旗
(1.中國科學院計算技術研究所網絡數據科學與技術重點實驗室 北京100190;2.中國科學院大學 北京100190;3.解放軍外國語學院語言工程系 洛陽471003)
1 引言
近年來,隨著移動互聯網的高速發展,傳統基于個人電腦的上網方式正在加速向基于智能移動終端的方式轉變,移動互聯網已經成為人們獲取信息的主要途徑。來自中國互聯網絡信息中心(CNNIC)的報告顯示[1],截至2013年12月,中國搜索引擎用戶規模達到4.9億戶,手機搜索網民數達到3.65億人,移動式搜索成為不斷興起的新型應用之一。與此同時,網絡空間(cyberspace)中各類應用的層出不窮引發了數據規模的爆炸式增長,形成了網絡空間的大數據[2]。隨著互聯網數據的爆炸式增長和網民獲取信息需求的不斷增強,傳統的“關鍵詞”搜索局限性逐漸暴露,基于互聯網的海量搜索在移動搜索領域已經難以滿足用戶需求,用戶對于搜索結果的直接性要求體現得很明顯,精準信息才是移動式搜索用戶最想要的。在整合海量互聯網碎片化信息的基礎上,如何基于用戶的片段輸入準確理解用戶搜索意圖,然后從海量顯性和隱性知識資源中按照人們需求,有針對性地提煉知識內容或問題解決方案,從而以直接給出可能答案或者更為豐富語義關聯信息的形式返回給用戶,這是移動搜索所面臨的巨大挑戰。
傳統Web資源中的語義信息以自由文本的方式存在,缺乏機器可理解的語義,搜索引擎難以自動有效地整合這些數據,同時資源間的語義關系以一種隱含的方式存在,這些語義信息由于缺乏明確的描述而丟失。因此,對于搜索引擎而言,準確理解數據符號背后所包含的語義信息變得至關重要。為了能夠將搜索結果準確地傳遞給用戶,需要引入語義技術,對搜索結果進行優化計算,從而理解用戶的搜索意圖。為了解決語義缺失問題,互聯網創始人Lee T B在XML2000國際會議上正式提出語義Web的體系框架[3],希望使網絡中的信息具有語義,以便計算機能夠自動地處理和理解數據。語義Web中“語義”的核心就是知識共享,知識共享實質上是基于語義技術的共享,而基于語義技術的智能搜索使得搜索引擎不再拘泥于用戶所輸入請求語句的字面本身,而是透過現象看本質,準確地捕捉到用戶所輸入語句后面的真正意圖,并以此進行搜索,從而更準確地向用戶返回最符合其需求的搜索結果。
在2013年5月 的Google I/O大會 上,Google的Amit Singhal提出了未來搜索引擎的設想:搜索引擎的3個主要功能需要改進,搜索將需要答案、對話、預測。未來的搜索引擎需要更智能地為用戶服務,這一切離不開富含語義信息的知識庫作為基礎支撐。語義Web希望賦予互聯網上所有資源唯一的標識,以一種明確、形式化的方式描述信息資源,從而在資源之間建立起機器可以處理的各類語義關聯,最終將萬維網中現存的信息發展成一個巨大的全球語義知識庫[4]。但是,面對海量的數據資源、豐富的文檔類型、形態各異的數據格式,數據資源的耦合度較低,也缺乏統一的管理,難以形成統一的語義知識庫。因此,基于現有的互聯網數據資源,構建大型的語義知識庫,為智能搜索提供語義知識支持成為切實可行的方案。本文面向開放的互聯網數據資源,結合現有技術應用,提出以超圖(hyper-graph)理 論 為 基 礎 的 動 態 知 識 網 絡(dynamic knowledge network,DKN)建模方式,從模型層面闡述了“知識+計算→智能”的智能搜索模式,通過計算算子實現基于知識的計算,從而對面向語義的智能搜索提供理論支持和模型支撐。
本文首先結合信息技術的發展介紹了互聯網搜索技術的現狀,分析了基于語義技術進行智能搜索的發展前景。在此基礎上,提出以超圖理論為基礎、以計算算子為技術支撐,進行世界知識建模的動態知識網絡建模方案,闡述了該模型的理論基礎、結構模式、系統模型及其特點以及基于動態知識網絡支撐智能搜索的基本結構框架,最后,對今后研究工作中所面臨的主要問題和挑戰進行了展望。
2 研究現狀
隨著計算機與通信技術的迅速發展,互聯網上的信息呈現指數型增長,在互聯網信息越來越豐富、用戶使用方式也越來越多變的同時,龐大并且關聯的信息讓大部分用戶感到無所適從,搜索的價值也就越來越明顯。面對海量信息,基于分類目錄和關鍵詞的搜索方式越來越難以適應用戶的搜索需求,迫切需要將檢索方式從基于詞層面提高到基于語義層面,實現基于語義理解的智能搜索。智能搜索不僅要求提升檢索技術,還向著信息服務的智能化、個性化、可互動的方向發展,因此,需要實現查詢請求和目標資源的語義理解。本體作為知識的承載者被信息科學領域引入,并作為語義Web的核心技術,對網絡信息資源進行語義表達和標注。根據本體技術在搜索引擎中的作用,將目前的智能搜索劃分為3類[5],具體介紹如下。
·基于傳統搜索的增強型搜索:這一類搜索的核心還是傳統的搜索引擎,通過本體技術對用戶查詢詞的處理來提高搜索效果,如IBM與蘋果公司等合作開發的OntoSeek系統[6]、美國斯坦福大學與IBM等研究機構聯合開發的Tap系統[7]等,還有研究將wordnet作為查詢擴展和約束,以改善搜索的效果[8]。
·基于本體推理的知識型搜索:這一類搜索是基于構建的本體知識庫,通過本體推理技術實現知識的自動發現和關聯,如美國馬里蘭大學開發的SHOE系統[9]、上海交通大學提出的SPARK[10]、清華大學提出的細粒度語義網絡檢索模型[11]等。
·其他類型的搜索:還有一些其他類型的搜索模型,如美國華盛頓大學開發的KnowItAll系統[12]、華中科技大學提出的應用在安全訪問控制領域的搜索模型[13]、上海交通大學與香港科技大學共同提出的一種增強的語義搜索模型[14]等。特別值得一提的是,Wolfram在2009年發布了Wolfram|Alpha系統,該系統一經發布就引起很大的反響,甚至有人認為它會取代Google的搜索霸主地位。
近年來,隨著Linking Open Data等項目的全面展開,語義數據源的數量激增。互聯網正從僅包含網頁與網頁間超鏈接的文檔萬維網(document Web)轉變為包含描述各種實體與實體之間豐富關聯的數據萬維網(data Web)。在此背景下,谷歌、微軟、百度和搜狗等搜索引擎公司紛紛以此為基礎構建知識圖譜,分別為Knowledge Graph、Probase、知心和知立方,以此來改進搜索質量,從而拉開了智能搜索的序幕。
3 動態知識網絡建模
網絡時代人們在探討數據、信息、知識之間的相互關系時,認識到數據是事物屬性及其相互關系等的抽象表示,信息則是有目的、有意義、有用途的數據,而知識是通過對信息進行深度加工,經過邏輯或非邏輯思維,認識事物本質而形成的經驗與結論[15]。互聯網蘊含著豐富的知識資源,不論是信息直接所包含的知識還是信息背后所隱含的知識,都反映在網絡中。維娜·艾莉[16]曾經指出,“我們可以把自己的個人知識看成一張認識的‘網’,很多想法、感覺、思想、概念和信仰都在這里交織在一起”。因此,可以從知識的這種網狀結構特征得到啟發,互聯網中也包含著一張巨大的知識網絡,經過數據的采集和清洗、信息的提煉和抽取、知識的描述和集成,最終可以利用一個開放的知識網絡將其呈現出來。基于這一思想,本文提出“知識+計算→智能”的智能搜索模式,如圖1所示。
其基本思想是:基于互聯網的各類數據資源,構建動態知識網絡,以此為基礎,結合定義好的各類計算算子的靈活組合,響應用戶需求,實現對用戶真實查詢意圖的語義理解和問題解答,從而實現通過一個事實知識庫和一系列計算算子得到一個可計算的網絡世界的構想。
3.1 動態知識網絡的理論基礎
關于“知識網絡”這個概念,最早是由瑞典工業界在20世紀90年代提出來的[17],不同時代、不同學科和不同領域的學者,對“知識網絡”概念的內涵和外延有著不同的認識[18]。王眾托院士通過對無處不在的網絡社會的分析[15],認為一個知識網絡應該有3個層次:技術層面的技術網絡、知識資源內部聯系的知識網絡、知識在人際間傳播的人際關系網絡。依據此理論,本文主要研究知識資源自身存在內在關聯的知識網絡。知識網絡目前還沒有明確的定義,它是一個集合概念,指的是知識的空間結構集合,即它是由知識節點和知識關聯所構成的集合。其中,知識節點(以下簡稱節點)一般代表知識單元的存儲單位,由概念或者事物組成;知識關聯(以下簡稱邊)可分為內部關聯和外部關聯。內部關聯構成知識個體,表達知識的內涵聯系,外部關聯是知識個體之間的外延聯系,構成知識網絡的各種鏈接關系。因此,知識網絡是由節點和邊構成的網狀結構,這種網狀結構的表現形式多種多樣,有樹型結構、星狀結構、環型結構、單向關系網絡、多向交叉復合關系網絡等。
典型的知識網絡主要考慮知識節點之間的二元關聯,即兩個知識節點之間的關聯。通常,事物之間的關聯不僅僅是單一和單向的簡單關系,而是一個復雜和多向的網絡。鑒于網絡世界中知識節點之間關聯的復雜性,一般的二元網絡圖難以完全刻畫網絡世界中知識的特征,因此,出現了超越一般網絡的網絡系統問題。本文研究的知識網絡規模巨大、連接復雜,知識節點具有異質性,可以稱為超網絡(hyper-network),本文用超圖來定義該類超網絡[19]。超圖這一概念是Berge在1970年提出的[20],超圖不同于一般圖論中的無向或有向圖,后者的每一個邊只連接兩個節點,而超圖中的邊可以連接兩個以上的節點,稱為超邊。因此,本文提出的動態知識網絡的模型是用超圖表示的超網絡。下面給出超圖在數學上的嚴格定義,見定義1。
定義1設V={v1,v2,…,vn}是一個有限集,若滿足以下條 件,則稱二元關系H=(E,V)為超圖。V={v1,v2,…,vn}是超圖的頂點集,E={e1,e2,…,en}是超圖的邊集,集合ei={vi1,vi2,…,vij}(i=1,2,…,m)為超圖的邊。如果在超圖的邊集中定義了方向,那么超圖就是有向超圖;反之,則是無向超圖。
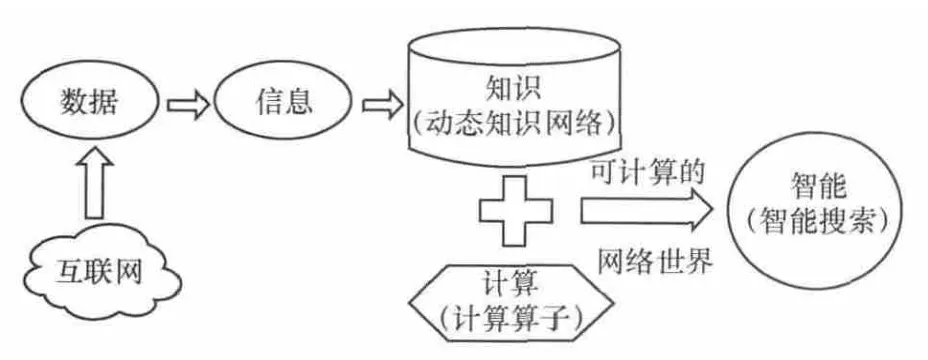
圖1 智能搜索模式的設想
定義2(超路徑)超圖H中的頂點和超邊交錯序列{v1,E1,v2,E2,…,Eq,vq+1}稱為具有長度為q的超路徑,若滿足以下條件:
·{v1,v2,…,vq+1}在超圖H中彼此不同;
·{E1,E2,…,Eq}在超圖H中彼此不同;
·vk,vk+1∈Ek,k=1,2,…,q。
同時q≠1且vq+1=v1,則這一條超路徑稱為長度為q的超回路。
超圖是對圖的一種擴展,其在描述多個節點之間擁有復雜多元關系的動態知識網絡時,具有極大的優勢。比如有8個知識節點V={v1,v2,v3,v4,v5,v6,v7,v8},構成4個多元關系E={e1,e2,e3,e4},其中,e1={v1,v2,v4},e2={v2,v3,v4},e3={v4,v5,v8},e4={v5,v6,v7,v8},用超邊表示多元關系,可以得到如圖2所示的超圖。

圖2 超圖表示的多元關系
3.2 動態知識網絡的系統建模方案
3.2.1 動態知識網絡的結構模式
動態知識網絡是對互聯網域空間知識的描述,是表示知識節點及節點間相互關聯的復雜網絡系統。本文基于超圖理論對動態知識網絡進行建模,拓展了普通圖中的節點和關系的類型,能夠更加靈活地實現知識的概念化描述。為了實現知識的語義表達,需要從結構上對其模式進行分析,解釋知識網絡的模式是如何由一些簡單的子模式(模式基元)組合而成的。表1為動態知識網絡的結構子模式示例。
通過對節點和關系描述的拓展,動態知識網絡能夠描述更加復雜的結構,也使得對子模式的提取具有更加豐富的語義信息。結合超點和超邊子模式,還可以衍生更加抽象和復雜的子模式。在一些應用中,通過這些子模式進行動態知識網絡的分解和縮減可以簡化結構的復雜性,從而在更高層次上分析網絡結構的特性。
3.2.2 動態知識網絡的系統模型
面向開放網絡數據環境,本文結合相關研究[21],提出動態知識網絡的系統模型,針對海量數據中知識的各種特征表現和復雜關聯進行語義知識表達和操作。動態知識網絡的系統模型使用一個七元組表示,即DKN=(V,E,A,Val,F,G,O),其中,V是知識節點的非空有限集合,E是知識關聯的非空有限集合,A是知識節點和知識關聯屬性的非空有限集合,Val是屬性的值域集,F是知識節點和知識關聯上的屬性值映射函數集,G是知識節點上的關聯映射函數集,O是針對知識網絡的各類操作,即計算算子的集合。下面分別對該模型的組成元素進行介紹。
(1)知識節點V
知識節點由在認識上具有獨立性的知識元素構成,具有層次性,其最小粒度可以稱為知識元,是獨立不可再分的知識元素,如人名、城市名等。知識元是最小的知識節點,多個知識元通過知識關聯可以構成更大的知識節點,知識節點的集合可以構成知識體系。對于V={v1,v2,…,vn},知識節點vi代表一個簡單或者復雜的事物或概念。
(2)知識關聯E
知識關聯是構成動態知識網絡的知識節點之間的關聯關系,這種關聯表現為以一種拓撲形式存在的網絡結構,其網絡性體現在知識因為本身的某種聯系而相互聚集形成網絡。E={e1,e2,…,en}是帶有標簽的有向超邊和無向超邊的集合,超邊ei代表一個簡單或者復雜的知識關聯,其最小粒度是獨立不可再分的關聯關系。有向超邊ei=<(ri),(λi)>是一個序偶,ri是ei中輸入變量的集合,λi是ei中輸出變量的集合;無向超邊ei={v1,v2,…,vm}是一個多元無向邊集合。通常有3種基本的知識關聯類型:同一性關聯,知識節點間具有某種共同性質形成的關聯,主要表現為知識節點間的繼承性,知識節點的等同性是同一關聯的特殊表現;隸屬性關聯,構成知識節點的單個知識元或者知識元集合隸屬某個概念、類別和范疇的邏輯關系,主要表現為知識節點間的屬性關系、分類關系、包含關系等;相關性關聯,是在同一性關聯、隸屬性關聯之外的,知識節點間大多具有的相互依存、相互作用的關聯,主要表現為工作、家庭、應用、影響等各種關系,這種關系不是嚴格固定的,其數量關系也是不完全確定的,它使得知識節點間在橫向上形成關聯網絡。
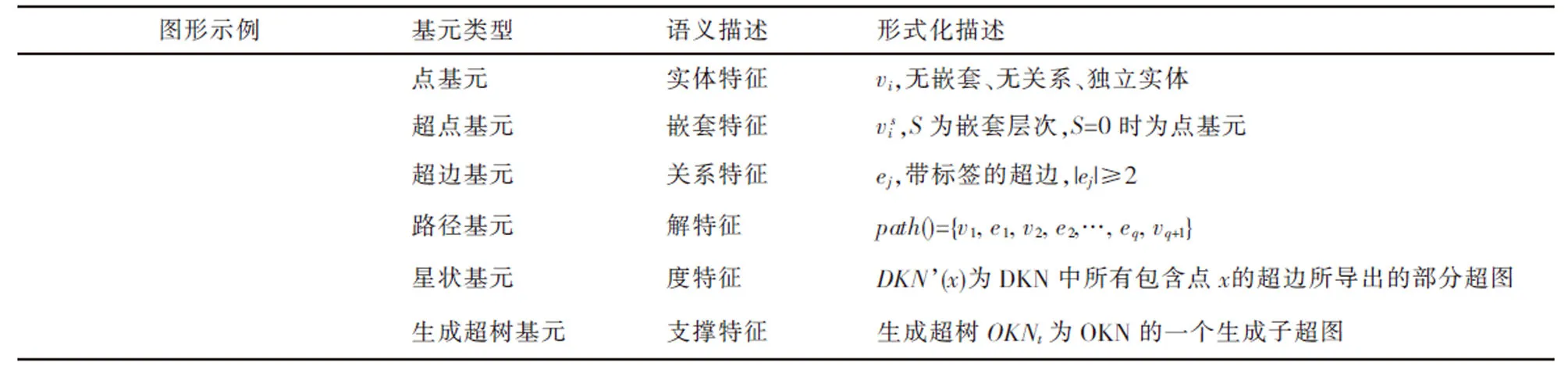
表1 動態知識網絡的結構子模式示例
(3)屬性A、屬性的值域集Val、屬性值映射函數F
一個具體的事物或者概念總是通過一些性質加以描述和區分,屬性用來描述知識節點和知識關聯自身的性質和特征。具體又可以將屬性分為數值型屬性和對象型屬性兩大類。A=AV∪AE,其中,AV是知識節點屬性集,AE是知識關聯屬性集。Val=ValV∪ValE,是知識節點屬性和知識關聯屬性的值域集合。F=FV∪FE,是知識節點、知識關聯與各自屬性值的映射函數,其中,FV:V×AV→ValV,FE:E×AE→ValE。比如V={v1,v2,v3}代表3個企業,組成的商業合作可以用一條超邊e1={v1,v2,v3}來描述,其中AV包含“公司名稱”、“成立時間”、“年營業額”等企業的屬性,AE包含該商業合作的屬性,如“組建時間”、“合作模式”等,屬性取值ValV包括 “中遠集運”、“中海集運”、“中國外運”等,ValE包括“2014年5月”和“合作經營”等。在動態知識網絡系統中,不同屬性的對應取值及取值約束通過F來確定,如F(組建時間)→Date(2014年5月)。另外,利用屬性值映射函數還可以實現節點間基于屬性的聚類。
(4)知識關聯映射函數G
動態知識網絡中各個知識節點按照需要的因素、層次、結構和功能等構成結構化的知識網絡系統,這種結構化的過程需要將知識節點通過某些方式關聯起來,即知識關聯映射。G是V上的關聯函數集合,G={g|g(v)=e},表示事物之間的不同關聯類型。當然,也可以理解為G是超邊構造函數,反映了知識節點間超邊的構造關系。構建知識節點間的知識關聯是建立動態知識網絡的關鍵環節,G決定了哪些知識節點在同一個知識關聯中以及知識關聯是如何劃分的。根據知識節點間關聯類型是否明確,可以有兩種構建方式:對于可以預定義的關聯模式,采用先知識關聯后知識節點的構建方式,即先確定動態知識網絡的關聯模式,描述為超邊,然后在知識節點集中搜索符合各關聯模式的知識節點對;對于關聯模式比較模糊的情況,可以通過對知識節點進行信息抽取,尋找它們之間的關聯模式,常用聚類、頻繁項集挖掘等方法。
(5)計算算子O
計算算子主要針對知識網絡完成各類運算操作,如同普通運算符號作用于數后,可以得到新的數,一個算子作用于一個輸入后,可以實現從一個知識網絡空間到另一個知識網絡空間(或它自身)的映射。根據實際需求,將算子分為兩大類:一是實現動態知識網絡內部元素動態構造的構建類算子,二是提供外部服務的應用類算子。基于外部信息輸入的計算算子模型如圖3所示。
結合新信息的輸入,計算算子封裝一些針對動態知識網絡常用操作的靈活組合,從而實現基于計算算子的運算。表2給出了一些針對動態知識網絡的常用算子示例。
3.2.3 動態知識網絡模型的特點
本文通過對網絡世界知識進行建模,提出基于超圖理論的動態知識網絡系統模型,該模型具有以下幾個方面的特點。
(1)可以描述復雜知識節點和知識關聯
動態知識網絡模型中允許定義復雜知識節點,知識節點和知識關聯在一定程度上可以相互轉化,因此,復雜知識節點可以是多個知識節點、知識關聯的集合。知識關聯復雜多樣,既有二元關聯,又有多元關聯。既有明確定義的關聯類型,又有難以明確描述的關聯類型,因此具有很強的知識描述能力,其完整形態是一個多元、異構、立體的超網絡。
(2)結構開放、靈活,可擴展性強
動態知識網絡模型描述的知識是可擴展的,可動態感知數據的變化,同時具有時效性,隨著新信息的加入而動態更新。另外,模型中允許定義新的知識關聯,通過關聯結構的可變實現網絡結構的靈活性,同時對未知關聯類型的包容性使得面對不確定的環境時,網絡結構也可以隨著信息的交互而發生演化。

圖3 計算算子模型

表2 動態知識網絡的常用算子示例
(3)具有處理不確定、不精確信息的能力
動態知識網絡模型是基于超圖理論的,而超圖中的集合理論是其核心,因此,基于集合的表達方式適合描述非明確定義的關系和規則。對于難以被明確定義和精確描述的知識關聯,該模型采用無向超邊進行描述,同時,模型中定義的計算算子可以實現對知識網絡的各類操作,使得能夠利用圖理論來處理網絡環境下不確定、不精確的信息。
(4)具有較強的可計算性
基于圖理論,動態知識網絡模型中定義了多種類型的圖操作,通過這些圖操作的靈活組合,計算算子可以實現動態知識網絡構建和應用過程中的模式識別、路徑分析、子模式構建等各種計算功能。另外,在特定的應用需求驅動下,基于一定的規則和約束條件,還可以進行知識的推理計算。
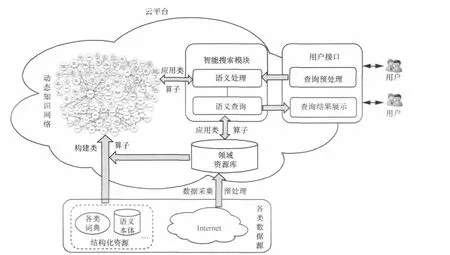
圖4 基于動態知識網絡的智能搜索框架
4 基于動態知識網絡的智能搜索
新一代的智能搜索致力于建立一個智能化、個性化和互動的搜索模式,這就需要實現對查詢請求的語義理解和對目標文檔的語義理解,而語義理解是建立在語義知識庫基礎之上的。本文提出動態知識網絡的系統建模方法,通過構建動態知識網絡,提高搜索引擎的語義理解能力,從而達到智能搜索的目標。基于動態知識網絡的智能搜索框架如圖4所示。
其基本思想是:充分利用現有各類數據資源,基于動態知識網絡系統模型,結合機器學習和數據挖掘等技術,構建動態知識網絡,并以此為語義基礎,支持基于語義理解的智能搜索。動態知識網絡對智能檢索的語義支持通常包含以下兩個方面。
(1)語義的擴展與優化
用戶以自然語言輸入查詢,系統基于動態知識網絡進行語義分析,需要理解用戶提交關鍵詞搜索背后的真正意圖,主要包括分類、屬性、同義等語義關系的提取、歧義消解等,從而豐富查詢的語義信息。同時,在語義理解的基礎上,對數據資源進行整合處理,獲取真正符合語義的信息資源。
(2)語義的推理與計算
基于動態知識網絡,對用戶查詢的關鍵詞進行概念化或者實例化處理、相似性計算等,從而在更高層次或者更細粒度上建立語義關聯。同時,根據動態知識網絡的推理規則,進一步拓展語義的關聯和約束。
5 結束語
本文通過對現有信息檢索和語義處理技術的介紹,分析了基于語義技術進行智能搜索的發展前景。基于此,提出以超圖理論為基礎、以計算算子為技術支撐進行網絡世界知識建模的動態知識網絡建模方法,并詳細闡述了該模型的理論基礎、結構模式、系統模型及其特點,最后給出了基于動態知識網絡支撐智能搜索的基本結構框架,為基于語義的智能搜索應用提供了有效的模型和方法支持。盡管目前已經進行了一些探索性的研究工作,但未來的工作仍然面臨兩個重要挑戰:動態知識網絡系統模型的完善;動態知識網絡支撐的智能檢索應用。
1 中國互聯網絡信息中心.2013年中國搜索引擎市場研究報告,2013
2 李國杰,程學旗.大數據研究:未來科技及經濟社會發展的重大戰略領域——大數據的研究現狀與科學思考.中國科學院院刊,2012,27(6):647~657
3 Lee T B.Semantic web on XML.http://www.w3.org/2000/talks/1206-xml2k-tbl,2014
4 王本年,高陽,陳世福等.Web智能研究現狀與發展趨勢.計算機研究與發展,2005,42(5):721~727
5 文坤梅,盧正鼎,孫小林等.語義搜索研究綜述.計算機科學,2008,35(5):1~4
6 Guarino N.Ontoseek:content-based access to the web.IEEE Intelligent Systems,1999,5(6):70~80
7 Guha R,McCool R.TAP:a semantic web test-bed.Journal of Web Semantics,2003,1(1):81~87
8 Kruse P M,Naujoks A,Roesner D,et al.Clever search:a wordnet based wrapper for internet search engines.Proceedings of the 2nd GermaNet Workshop,Bonn,Germany,2005:367~380
9 Heflin J,Hendler J.Searching the web with shoe.Proceedings of AAAI-2000 Workshop on AI for Web Search,Austin,Texas,2000:450~455
10 周琦.基于關鍵詞的語義搜索.上海交通大學碩士學位論文,2009
11 吳剛,唐杰,李涓子等.細粒度語義網檢索.清華大學學報(自然科學版),2005,45(1):1865~1872
12 Cafarella M J,Downey D,Soderland S,et al.KnowItAll:fast,scalable information extraction from the web.Proceedings of the Conference on Empirical Methods in Natural Language Processing,Vancouver B C,Canada,2005:563~570
13 文坤梅.基于本體知識庫推理的語義搜索研究.華中科技大學博士學位論文,2007
14 Zhang L,Yu Y,Zhou J,et al.An enhanced model for searching in semantic portals.Proceedings of the International Conference on World Wide Web,Chiba,Japan,2005:453~462
15 王眾托.無處不在的網絡社會中的知識網絡.信息系統學報,2007,1(1):1~7
16 趙蓉英.論知識網絡的結構.圖書情報工作,2007,51(9):6~10
17 田占偉,張慶普,劉臣.語義知識網絡的結構分析與構建.情報理論與實踐,2011,34(10):113~118
18 劉向,馬費成,王曉光.知識網絡的結構及過程模型.系統工程理論與實踐,2013,33(7):1836~1844
19 王志平,王眾托.超網絡理論及其應用.北京:科學出版社,2008
20 王眾托.關于超網絡的一點思考.上海理工大學學報,2011,33(3):229~237
21 吳穎敏.市場機遇發現的超圖支持方法研究.華中科技大學博士學位論文,2009
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
學苑創造·A版(2018年11期)2018-02-01 06:29:20
讀者(2017年5期)2017-02-15 18:04:18
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
