基于Hive的數據管理圖形化界面的設計與實現
2014-02-08 03:48:31左譜軍朱曉民
電信工程技術與標準化 2014年1期
左譜軍,朱曉民
(1 北京郵電大學網絡與交換技術國家重點實驗室,北京 100876;2 東信北郵信息技術有限公司,北京 100191)
基于Hive的數據管理圖形化界面的設計與實現
左譜軍1,2,朱曉民1,2
(1 北京郵電大學網絡與交換技術國家重點實驗室,北京 100876;2 東信北郵信息技術有限公司,北京 100191)
本文提出了一種對Hive進行圖形化界面管理的設計方案,實現了用戶對Hive數據倉庫的數據表管理,數據查看檢索,以及用戶對數據庫的權限管理等功能,使用戶可以友好的訪問屬于自己權限Hive數據內容。
Hive;圖形化界面;數據管理
為了處理海量的原始數據,很多大型數據倉庫開發者和程序員在過去5年內實現了數以百計的、專用計算方法。這些計算方法可實現類似網絡爬蟲程序的文檔抓取,Web請求日志處理等操作;也可處理各種類型的衍生數據。上述大多數數據處理運算由于輸入的數據量巨大,想在可接受的時間內完成運算,現行條件下的單臺機器無法滿足要求,需要采取分布處理技術,亦即將這些計算分布在成百上千的主機上完成。
針對大規模和超大規模數據的分布式計算處理技術成為倍受關注的工程研究課題。工程研發界普遍關注在互聯網領域得以廣泛應用的Hadoop技術,Hadoop是一個分布式系統基礎架構,由Apache基金會開發,其主要子項目包含HDFS和MapReduce,HDFS是Hadoop的分布式文件系統,而MapReduce是Hadoop分布式計算框架[1]。
分布式數據存儲倉庫Hive是基于Hadoop的一種數據倉庫基礎框架。因此在功能上有些不同于傳統意義上的Orical和Mysql數據庫,不支持隨機插入記錄和刪除記錄的操作。它能提供應用工具來支持數據提取,轉化和加載(ETL),可用來查詢,存儲和分析存儲在Hadoop中的大規模數據集。使用簡單的類SQL語言,稱為HQL(Hive Query Language,Hive查詢語言)。
1 Hive技術構架
Hadoop兩個基礎構架HDFS(Hadoop Distributed File System,Hadoop分布式文件系統)和MapReduce同樣是Hive架構的根基。如圖1所示,Hive架構包括如下組件: CLI(Command Line Interface,命令行接口)、JDBC/ODBC、Thrift Server、Hive Web Interface、Metastore和Driver(Complier、Optimizer和Executor),這些組件按照功能來分可以分為兩大類:服務端組件和客戶端組件。
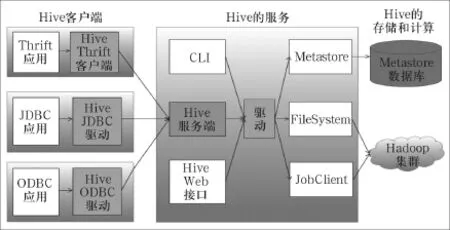
圖1[2][3]Hive系統框架圖
1.1 服務端組件
(1)Driver組件:該組件包括Complier、Optimizer和Executor,它的作用是將HQL(類SQL)語句進行解析、編譯優化,生成執行計劃,然后調用底層的MapReduce計算框架。
(2)Metastore組件:元數據服務組件,所謂元數據,指的是Hive數據庫或者數據表的屬性信息,包括表結構,表名以及字段名等等信息。Metastore這個組件用來管理Hive的元數據,Hive的元數據信息持久化在關系數據庫里,目前最新版本Hive-0.12.0支持的關系數據庫有Derby、Mysql。元數據對于Hive十分重要,因此Hive支持把Metastore服務獨立出來,安裝到遠程的服務器集群里,這樣一來可以解耦Hive服務和Metastore服務,保證Hive運行的健壯性。
為了能夠存儲和管理Hive的元數據,從結構上說,Metastore組件包括兩個部分:Metastore服務和后臺數據的存儲。后臺數據存儲的介質就是關系數據庫,用例如Hive默認的嵌入式磁盤數據庫Derby,還有Mysql數據庫。Metastore服務是建立在后臺數據存儲介質之上,并且可以和Hive服務進行交互的服務組件,默認情況下,Metastore服務和Hive服務安裝在一起,運行在同一個進程當中。也可以把Metastore服務從Hive服務里剝離出來,Metastore獨立安裝在一個集群里,Hive遠程調用Metastore服務,這樣可以把元數據這一層放到防火墻之后,客戶端訪問Hive服務,就可以連接到元數據這一層,從而提供了更好的管理性和安全保障。使用遠程的Metastore服務,可以讓Metastore服務和Hive服務運行在不同的進程里,這樣也保證了Hive的穩定性,提升了Hive服務的效率。(3)Thrift服務:Thrift是Facebook開發的一個軟件框架,它用來進行可擴展且跨語言的服務的開發,Hive集成了該服務,能讓不同的編程語言調用Hive的接口。
1.2 客戶端組件
(1)CLI:Command Line Interface,命令行接口,用于操作Hive數據庫和數據表。
(2)Thrift客戶端:上面的架構圖里沒有寫上Thrift客戶端,但是Hive架構的許多客戶端接口是建立在Thrift客戶端之上,包括JDBC和ODBC接口。
(3)WEBGUI:Hive客戶端提供了一種通過網頁的方式訪問Hive所提供的服務。這個接口對應Hive的hwi組件(Hive web interface),使用前要啟動hwi服務。
2 平臺設計的實現
本文致力于開發一個基于Hive的數據管理圖形化界面,底層以Hadoop和Hive平臺為依托,針對輕技術人員,即普通的業務人員,使其可通過該平臺實現數據管理。系統架構可以分成3個層次,如圖2所示。
2.1 客戶端
客戶端實現的是對于數據表的基本操作,包含數據表的操作、數據庫的操作以及數據展示,將客戶端操作轉化為相應的指令,提交到服務端執行。
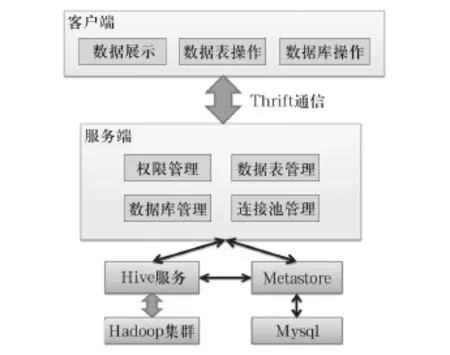
圖2 基于Hive操作的圖形化平臺系統架構
(1) 數據表的操作,Hive表是以數據和Hive表元數據分離的形式實現的,當創建一個數據表的時候,需要創建這兩部分信息,Hive表的元數據存儲在Mysql數據庫,而數據存儲在Hadoop集群上,以分布式文件的形式存在,由于Hadoop不支持對文件數據的隨機修改,因此對于Hive表數據的添加只能以整個文件的形式上傳,不支持對Hive表數據單條數據的插入,數據的刪除同樣不支持對單條數據記錄的刪除。Hive表的原數據包含的是數據表的屬性,數據表是否是外部表,所謂外部表,就是修改的內容僅限于元數據,存儲的位置,列名,列的類型,數據間隔等等。數據表的操作,包含清空,創建,刪除,更改。
(2) 數據的展示,數據展示所需要的是Hadoop集群上的數據,如果文件中數據需要正確展示,那么它數據的格式必須得匹配數據表的元數據,否則數據無法正確顯示,例如,當文件中數據間隔以“ ”為間隔,而元數據設置數據表的格式以“u0001”為間隔,在客戶端就不能顯示正確的數據。數據顯示一次性顯示100條數據,隨著滾動條下拉,每次增量顯示200條數據。數據表同時展示整個數據表內容所占空間的大小。
(3) 數據庫操作,對于不同的用戶,擁有對不同數據庫的操作權限,默認一個用戶只能擁有3個數據庫,但是操作的數據庫格式不限,用戶可以將一個數據庫的操作權限賦予其他的用戶,被賦予操作權限的用戶只能對數據庫的數據表進行操作,不能刪除數據庫,只有數據庫的擁有者才能刪除數據庫。數據庫里面包含數據表,數據庫之間數據表可以相互移動。
2.2 客戶端和服務端的通信
客戶端和服務端通信是通過Thrift工具實現,Thrift是一個服務端和客戶端的架構體系,Thrift具有自己內部定義的傳輸協議規范(TProtocol)和傳輸數據標準(TTransports),通過IDL腳本對傳輸數據的數據結構(struct) 和傳輸數據的業務邏輯(service)根據不同的運行環境快速的構建相應的代碼,并且通過自己內部的序列化機制對傳輸的數據進行簡化和壓縮提高并發、大型系統中數據交互的成本,圖3描繪了Thrift的整體架構,分為6個部分:
(1)業務邏輯實現(Your Code),業務邏輯的實現需要自己編寫特定的thrift-code。
(2)客戶端和服務端對應的Service,對于每一個客戶端為建立一個連接。
(3)執行讀寫操作的計算結果,由服務端執行,將結果返回給客戶端。
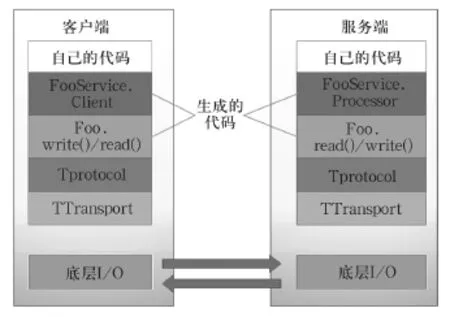
圖3 Thrift的整體架構
(4)TProtocol,定義數據格式協議,包含二進制編碼協議TBinaryProtocol 和高效率的、密集的二進制編碼格式進行數據傳輸TCompactProtocol 。
(5)TTransports,定義數據傳輸方式,包含阻塞式I/O進行傳輸TSocket和非阻塞方式TFramed Transport,底層只有一個服務,所以傳輸方式選擇的事阻塞式I/O。
(6)底層I/O通信,底層通信協議。
2.3 服務端
服務端處于整個系統的中間層,往上負責和客戶端通信,接收客戶端的請求,并且將執行結構返回給客戶端;往下負責和底層服務溝通,將執行指令提交到底層服務執行,另外管理一些緩存的內容,主要完成的功能是權限管理,數據表管理,數據庫管理以及連接池管理。
(1) 權限管理,Hive本身不存在對數據表和數據庫的限制,為了限制不同用戶對Hive數據庫的使用,服務端建立了一套權限管理體系,用于管理不同用戶的數據庫和數據表,不同用戶對數據庫操作擁有不同的權限,這一部分信息存儲在Mysql數據庫當中。
(2) 數據表管理,數據表的元數據信息可以通過底層MetaStoreServer獲得,權限信息則需要通過權限管理體系獲取,數據表的信息經常要被訪問,為了能夠及時的反饋客戶端請求,服務端存儲了一份數據表的緩存信息,以減輕對底層Hive的操作次數。
(3) 數據庫管理,不同的用戶對Hive數據庫擁有兩種權限,一種是數據庫的擁有者,另外一種是數據庫的可操作者,數據庫擁有者能夠刪除自己創建的數據庫,而數據庫的可操作者權限,則需要數據庫擁有者賦予。
(4) 連接池管理,連接池為Hive操作提供連接,用于Java客戶端訪問元數據庫,在服務器端啟動Meta StoreServer,客戶端利用連接通過MetaStoreServer訪問元數據庫,為了保證連接有效性,對已經建立的連
接間隔一定的時間做信息發送操作,若連接中斷,則重啟連接服務,以保證服務的可靠性。
2.4 底層服務配置
底層服務由Hadoop為支撐,需要配置MetaStore服務和Hive服務,MetaStore服務底層是以Mysql為支撐,存儲Hive的元數據。Hive服務提供數據信息,底層依托Hdfs。
3 總結
Facebook主要依靠可以使業務開發者同時使用的Hadoop、標準商業智能工具的Hive以及由Facebook自主開發的閉源終端用戶工具HiPal等方式拓展業務。為了使業務人員更加方便的使用Hive,基于Hive的數據管理圖形化界面的實現解決了Hive數據操作圖形化的問題,能夠直接與Hive對話,并且具有數據查詢,數據刪除,數據庫管理功能。
[1] A. Gates, O. Natkovich ect. Building a high-level dataflow system on top of Map-Reduce: The pig experience[M]. In Proc. of VLDB, 2009:1414-1425.
[2] Tom White著,周傲英等譯. Hadoop權威指南(中文版)第二版[M].北京:清華大學出版社,2011.
[3] Tom White. Hadoop: The Definitive Guide[M]. Second Edtion O’Reilly Media, 2011.
Graphical data management design and implementation based on hive
ZUO Pu-jun1,2, ZHU Xiao-min1,2
(1 State Key Laboratory of Networking and Switching Technology, Beijing University of Posts and Telecommunications, Beijing 100876, China; 2 EBUPT Information Technology Co., Ltd., Beijing 100191, China)
This paper proposes a design of graphical interface that provides the user table management of Hive data warehouse, data view retrieval and the database user priority management functions, so that the user can access their own Hive data friendly.
Hive; graphic UI; data management
TN915
A
1008-5599(2014)01-0089-04
2013-12-05
國家973計劃項目(No. 2013CB329102);國家自然科學基金資助項目(No. 61372120,61271019, 61101119, 61121001, 61072057, 60902051);長江學者和創新團隊發展計劃資助(No. IRT1049);北京市支持中央高校共建項目——青年英才計劃。
猜你喜歡
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
