一種具有容錯機制的MapReduce模型研究與實現
2014-01-17 05:42:54史椸耿晨齊勇
西安交通大學學報 2014年2期
關鍵詞:進程
史椸,耿晨,齊勇
(1.西安交通大學電子與信息工程學院,710049,西安;2.中航工業西安飛行自動控制研究所,710065,西安)
MapReduce[1]編程模型在任務處理的過程中,個別節點容易出現錯誤,出錯節點對整個系統性能的影響較大。傳統MapReduce模型的容錯機制較為簡單,對錯誤的處理容易產生重復計算,造成計算資源的浪費。在容錯時如果使用傳統的進程檢查點機制,則開銷較大并且難以保證恢復數據的安全性。
隨著多核技術[2-3]的發展,多核資源越來越豐富,且呈現分布式的趨勢。如何能夠充分利用多核服務器的計算能力和硬件資源是一個隨之而來的問題。現代操作系統通過不斷增加系統的復雜性[4-5]來適應持續發展的硬件資源,虛擬化技術的出現在一定程度上解決了現有系統眾多影響計算機性能的問題。虛擬化技術可以提高服務器資源利用率,同時減少服務器數量,以降低管理和維護的開銷,降低能源消耗[6]。同時,虛擬化技術提供了很好的隔離性,使得虛擬機之間互不干擾,提高了系統的安全性和可靠性。
基于上述問題,本文通過分析現有MapReduce的實現方式,將多核平臺與虛擬機技術相結合,提出了一種基于多核虛擬機的MapReduce模型(Virtual Machine Based Fault-Tolerant Mechanism,VMBFTM)。
1 任務分配模型
1.1 系統狀態模型與分析
基于多核虛擬機的具有容錯機制的MapReduce,其系統狀態模型如圖1所示。
通過虛擬機監控器的虛擬化,在多核服務器上形成多個操作系統。其中一個操作系統叫做控制域,這個控制域把必要的接口暴露給用戶,以便用戶進行編程和數據處理。服務器管理員通過這個控制域對整個多核服務器進行維護,提交計算任務,調節整個系統負載,并對安全問題進行處理。其他操作系統受到控制域的監控,對網絡或者外設的訪問需要受到控制節點的限制。MapReduce模型中調度節點Master進程運行在控制域OS0。首先,用戶在控制節點提交需要處理的數據,Master進程對數據進行Split分割操作,劃分成N個數據塊。數據塊的個數和整個多核服務器中Worker工作節點個數相同。然后Master和每個操作系統中的守護進程監控者進行通信,發出啟動 Worker的命令。監控者收到命令之后,啟動 Worker,然后每個 Worker創建指定個數的線程,對分配給它的數據進行Map映射操作。Map操作處理待處理數據中每個記錄,產生中間結果的鍵值對<key,value>,然后在相同key的結果上執行Reduce操作。在執行Map操作的過程中,根據用戶指定或者系統默認的策略,進行檢查點的設置。設置檢查點時,需要陷入虛擬機,把Map當前的中間結果保存在虛擬機維護的Map結果存儲區中,并記錄相關控制信息,例如當前節點已經完成的任務量等。設置完檢查點之后,返回操作系統,繼續進行 Map操作。完成Map任務之后,Map產生的全部中間結果保存在共享內存中,接著關閉Worker進程,監控者通知 Master本階段完成,請求進行Reduce化簡階段的處理。Master收到這個消息之后,重復上面的過程,進入Reduce階段。Reduce過程中,每個Worker需要讀取Map的結果作為自己的輸入。每個Worker通過訪問共享內存中Map結果存儲區,讀取屬于自己節點的數據進行Reduce操作,通過共享內存減少了傳遞大量中間結果帶來的時間開銷。在Reduce過程中,Reduce的結果也被不斷保存,以便在發生錯誤之后通過這些保存的數據進行恢復。
錯誤恢復模型如圖2所示。接收到Master向監控者發出的命令之后,啟動本節點內的Worker,Worker會創建多個線程進行Map或者Reduce操作。在此過程中,根據一定策略進行檢查點的設置,通過增量方式把當前Map或者Reduce執行的任務保存在由虛擬機維護的內存區域內。如果Worker檢測到錯誤發生則會通知監控者,監控者隨即關閉本節點內的Worker,并向Master發送消息,請求在本節點內重新啟動一個Worker。當Master發出啟動命令之后,監控者重啟Worker,先從虛擬機維護的內存中讀取已經做好的中間結果和原始分配的任務以及相應的控制信息等,然后對Worker進行初始化操作,完成錯誤恢復。系統就像沒有發生錯誤一樣,繼續執行Map或者Reduce操作。如果本節點內分配的任務已經做完,監控者關閉Worker。
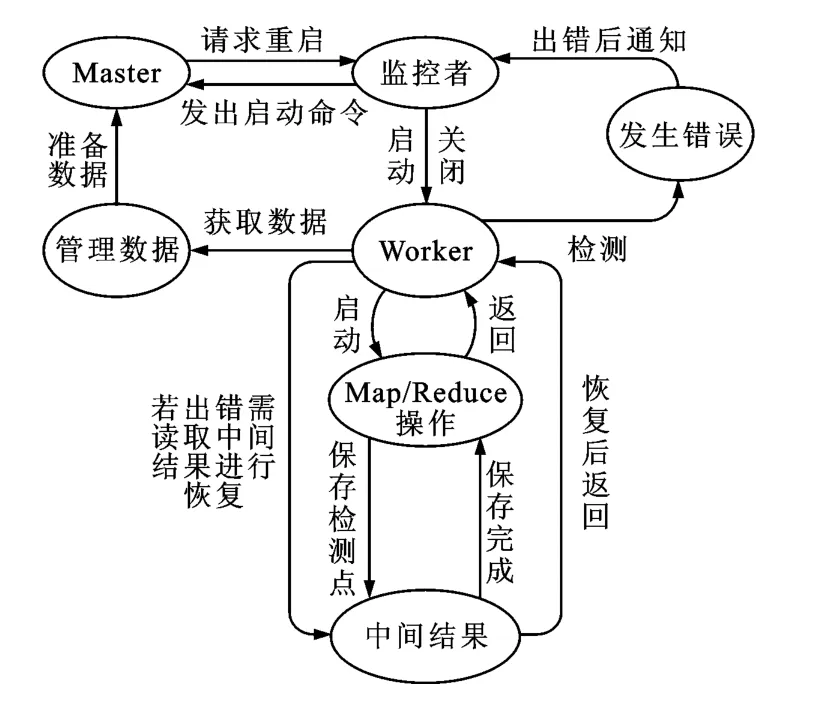
圖2 錯誤恢復過程模型
1.2 錯誤恢復開銷研究
基于多核虛擬機的具有容錯機制的MapReduce在Worker運行時通過對中間結果設置檢查點達到錯誤恢復的效果。假設在 Worker運行中,檢查點是均勻分布的,設每個檢查點間隔計算任務消耗的時間為ti,并且由于(key,val)的處理過程,每個檢查點之間的計算任務消耗的時間大致相等,即ti=TPA,TPA表示每兩個檢查點間隔計算任務消耗時間的平均值,TSA表示第1個檢查點,即單位時間內保存中間結果的時間,且TPA≈TSA,TRA表示對單位時間內生成的中間結果進行恢復需要的時間。FK是第K 次發生錯誤,n表示程序運行完成過程中需要建立n個檢查點。因此不設檢查點的Map或者Reduce的執行時間為
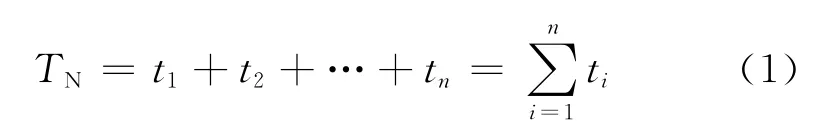
設置檢查點后,程序執行時間為
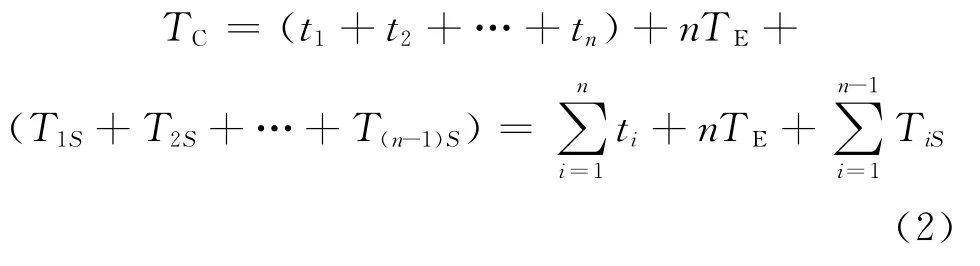
式中:TE表示每次進行檢查點時陷入和返回虛擬機的時間,每次都相等,共有n次;TiS表示每次保存中間結果所需要的時間。
不設檢查點出錯之后,程序直接終止,所消耗的時間為
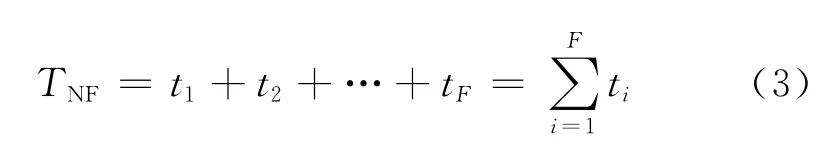
不設檢查點出錯后進行恢復時,出錯節點需要從頭開始計算,由于可能在運行過程中多次產生錯誤,設每次錯誤之后運行到tFi,因此整個過程消耗的時間為
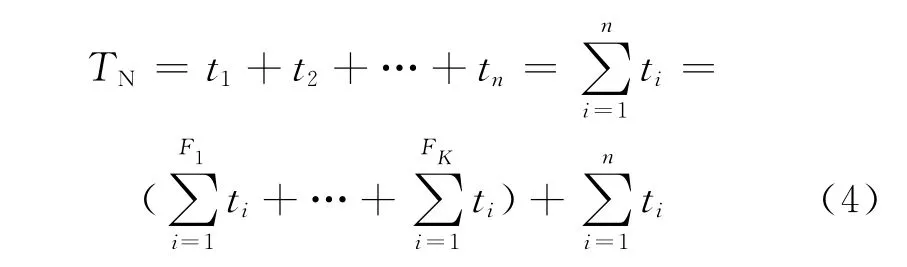
式中:當i>j時,Fi>Fj。進行檢查后,在F處出錯之后整個進程消耗時間為
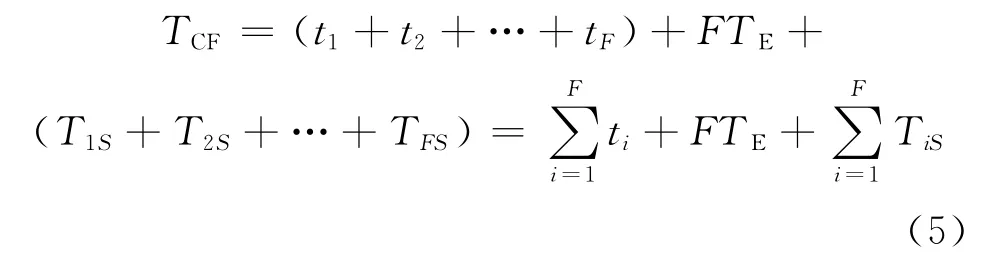
檢查點出錯后進行恢復時,發生錯誤次數為K,錯誤發生點為tFi,每次只要從最近的檢查點繼續執行即可,從最近檢查點進行恢復的時間為TFiR,所消耗時間為
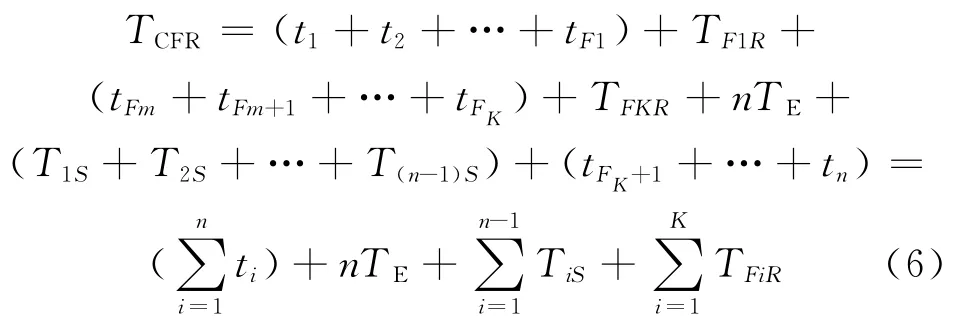
式中:TFiR表示從最近的檢查點進行恢復數據所需要的時間,TFiR和保存最近檢查點的數據所花費的時間大致相等。
為了比較不設置檢查點和設置檢查點之后恢復的效果,比較TNFR和TCFR,即
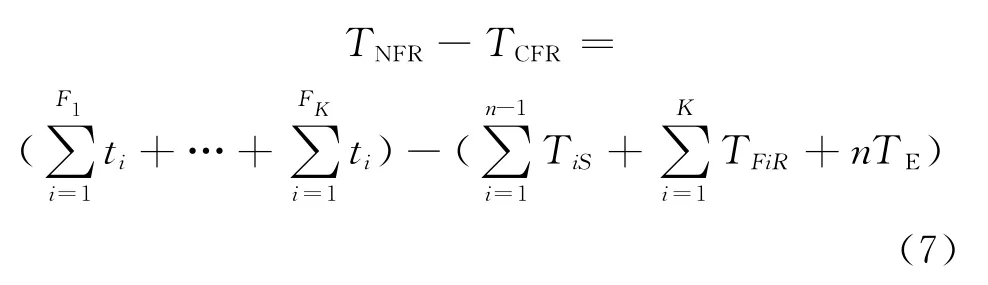
如前所述,ti=TPA,且每次檢查點保存和恢復的時間隨著中間結果的增長而線性增加,因此TiS=iTSA,所以可以進一步得出
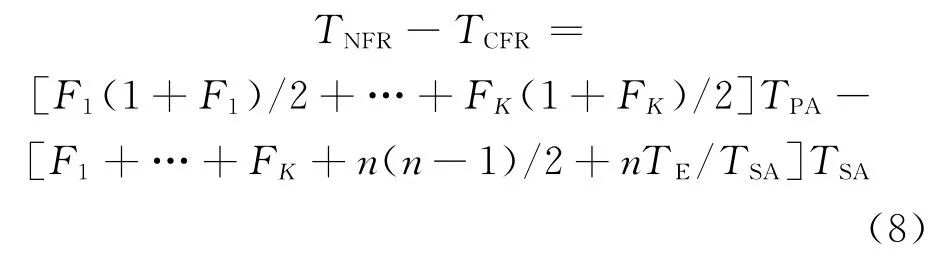
由于是輕量級虛擬機,虛擬機每次陷入和返回的時間和較短,因此nTE可以忽略。而且對使用MapReduce模型進行處理的應用來說,計算產生中間結果花費的時間遠遠大于把這些中間結果保存在內存中花費的時間,即TPA?TSA。進一步分析式(8)后,發現當n不太大的時候,TPA/TSA<5即可保證TNFR>TCFR成立,即本文設計的容錯機制相比傳統的MapReduce容錯機制更有優勢。
2 系統的設計與實現
本文所設計的系統需要3個部分支持:具有容錯機制的MapReduce引擎、用戶定制程序以及虛擬化的多核服務器。三者關系如圖3所示。前兩者是軟件支持,第3個是硬件平臺支持。具有容錯機制的MapReduce引擎是對MapReduce過程進行統一管理,對底層硬件平臺進行抽象,提供良好的通信機制和數據管理能力,包括Master端、Worker端以及監控者程序。用戶定制程序是用戶自己編寫的對不同的應用案例進行特定處理的程序,主要是用戶自定義的Split,Map和Reduce函數。虛擬化的多核服務器是運行系統的硬件平臺,為具有容錯功能的MapReduce系統提供硬件支持,這里是通過輕量級虛擬機監控器對多核服務器進行虛擬化,把多個隔離的操作系統作為隔離的節點,運行一個Master或若干Worker。為完成系統功能要求,需要解決3個問題:一是如何進行數據處理;二是任務調度和通信效率;三是容錯機制的建立。
2.1 數據處理過程
數據處理的前提是建立域間共享內存,它是整個系統的核心,也是其他模塊運行的基礎和前提條件。共享內存為多核系統SMM[7]提供簡單編程模型,并且可以兼容大部分當前已有的應用程序和操作系統。共享內存系統[8]可使各個模塊平等地訪問系統中的物理內存。
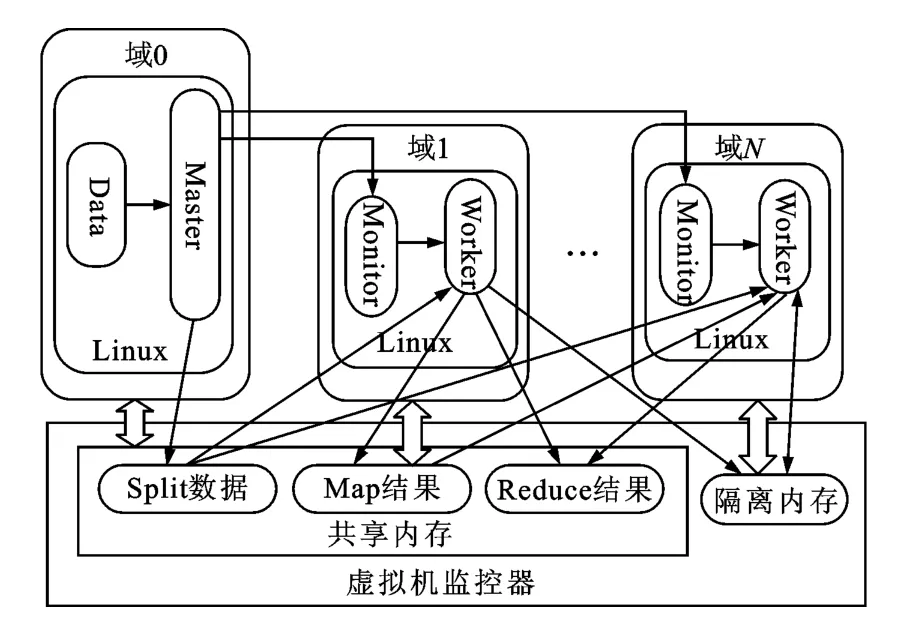
圖3 基于多核虛擬機的具有容錯機制的MapReduce
在OS內核中需要建立共享內存到內核空間的映射,然后建立用戶地址空間和內核地址空間的映射,這樣OS中的Master和Worker進程就可以自由地使用共享內存在不同OS之間通信。
數據處理模塊把系統的控制信息等敏感數據保存在共享內存中;任務調度模塊根據共享內存中的控制進行任務調度;節點通信模塊使用共享內存進行節點之間的通信和交互;檢查點模塊把恢復數據保存在各個節點都能訪問到的共享內存中,便于在出錯后使用錯誤恢復模塊進行恢復。
在數據輸入階段,對于Master節點,計算任務的數據一般以文件的形式提供,先存放在Master節點硬盤中。數據處理模塊需要把計算任務文件讀入內存,然后根據一定的規則進行分割,把這些數據存放在虛擬機維護的內存區域中。對于Worker節點,每個節點的輸入數據是本節點需要處理的數據,由虛擬機調用。通過虛擬機維護的共享內存,Worker進程可以對本節點的數據進行操作。由于每個節點只映射自己所要處理的數據的內存,不會對其他節點的數據進行影響和破壞。Map階段和Reduce階段類似,從共享內存中讀入本節點需要處理的數據,通過任務調度分發給每個線程,進行計算后輸出到共享內存中,中途需要根據一定策略對中間結果進行必要的保存。
2.2 任務調度和通信
任務調度模塊是在系統運行時,完成任務調度和負載均衡的功能。任務調度的過程包括監控者開啟和關閉Worker進程,Worker進程開創多個線程進行Map或者Reduce操作,操作完畢之后通知完成工作。通過使用進程和線程結合的方式,在每個子域的操作系統上運行一個 Worker,然后每個Worker又創建多個線程,每個線程處理一塊數據。這樣能夠很好的利用多進程和多線程的優勢。
節點通信模塊主要負責節點之間的通信,保證Master能夠準確地控制Worker節點的執行,并在Worker節點的任務執行的過程中和完成任務之后,Master節點能夠及時了解此Worker節點的任務狀態信息。
Master進程直接和子域中的監控者進程進行通信。監控者是守護進程,一直運行在子域中,負責監聽Master信號,在收到Master發過來的啟動命令之后,啟動本節點中Worker進程。在節點內部多線程執行任務的過程中,如果發生錯誤,Worker進程崩潰,監控者進程發現Worker崩潰后,需要在全局任務控制表中屬于本節點的表項中注明錯誤發生,同時Master進程會不斷掃描全局任務控制表項。由于全局任務控制表是存放在各個域之間的共享內存中,因此Master通過定時掃描就可以及時發現狀態的改變,并有效地對 Worker進行監控和管理。
2.3 建立容錯機制
本文給出的MapReduce的容錯機制包括兩方面:檢查點設置和錯誤恢復。
在檢查點時刻把當前線程的計算結果保存在虛擬機指定的隔離內存空間,出錯之后在出錯節點重新啟動Worker進程,從最近的檢查點讀取中間結果數據和本節點任務的進度信息繼續運行。由于(key,val)的特點,key和產生它的進程以及所在的節點無關,因此可以由任意的線程繼續對它進行處理。
這些恢復數據存放在由VMM指定內存中,OS系統是無法感知和訪問的,這樣就形成了隔離屏障,保證當Worker進程甚至整個OS異常終止或者崩潰之后,這些恢復數據不會受到破壞和影響。VMM接受虛擬機調用之后,在虛擬機里把線程已經處理好的數據保存在指定的專門存放中間結果的內存中,這塊內存通過資源的隔離性保證了恢復數據的安全性。
在恢復的過程中,通過讀取存放在全局任務控制表中的任務進度信息,Worker進程創建線程并讀取任務進度信息從而使每個線程恢復到設置檢查點時的狀態。由于(key,val)和線程狀態無關,因此新的線程可以繼續執行出錯前任意一個線程的任務。由于檢查點時刻的任務都保存在VMM維護的隔離內存中,因此需要陷入虛擬機,用保存的中間結果恢復OS中的所有線程共同操作的中間結果池。
3 實驗結果與分析
測試的硬件平臺是基于SUN的32核、主頻為2.38GHz、內存為128GB的服務器。硬件之上運行著本課題組設計實現的虛擬機監控器OSV。相比于傳統的虛擬機監控器,我們設計的OSV虛擬機監控器是輕量級的,易于維護,并且性能更高。虛擬機監控器對其上的操作系統分配資源,并且阻止其他操作系統未授權的訪問,形成了資源的隔離。節點之間可以通過一般的TCP/IP進行通信,而對于大量的數據,通過虛擬機維護的共享內存進行數據交流在一定程度上提高了數據交互的性能。為了降低虛擬化對系統帶來性能上的影響,虛擬機只是對資源進行訪問控制,而沒有對資源進行虛擬化。由于VMM在OS運行時處于掛起狀態,并且OS對授權的硬件資源直接進行訪問,因此相比于沒有虛擬機的多核服務器,性能損耗很小。
3.1 MapReduce應用性能測試
wordcount應用是用來測試MapReduce性能的一個比較普遍的測試用例,其功能是對一個存放英文單詞的大文件進行處理,統計其中的英文單詞出現的頻率,得出出現單詞的種類和各個單詞出現的次數。使用wordcount應用對基于多核虛擬機的具有容錯機制的MapReduce在多核平臺上進行測試,并和兩種不同模式的多線程實現方式以及Phoenix系統進行對比。
斯坦福大學在多核服務器上實現了Phoenix[9]系統,直接運行在多核服務器上的一個操作系統,它是基于共享內存的MapReduce,使用多個線程完成Worker的任務。
第一種多線程方式運行在多核服務器上唯一的操作系統中,這個操作系統完全掌控所有的硬件資源,即單操作系統多線程方式,通過使用Pthread多線程進行wordcount應用的處理。第二種多線程方式是在多核平臺上使用虛擬機監控器進行資源隔離,運行多個操作系統,每個操作系統上運行一個Worker進程,每個 Worker進程創建4個線程,即多操作系統多線程方式。每個操作系統相當于分布式環境下單獨的一個計算節點,借助MapReduce思想進行wordcount處理。
對4線程、8線程、12線程、16線程4種情況測試1GB大小的wordcount文件的計算時間,結果如圖4所示。可以看出,Pheonix性能略高,而單操作系統多線程方式和基于多核的具有容錯機制的MapReduce性能類似,并且性能與Pheonix相差不大,而多操作系統多線程方式的性能最差。
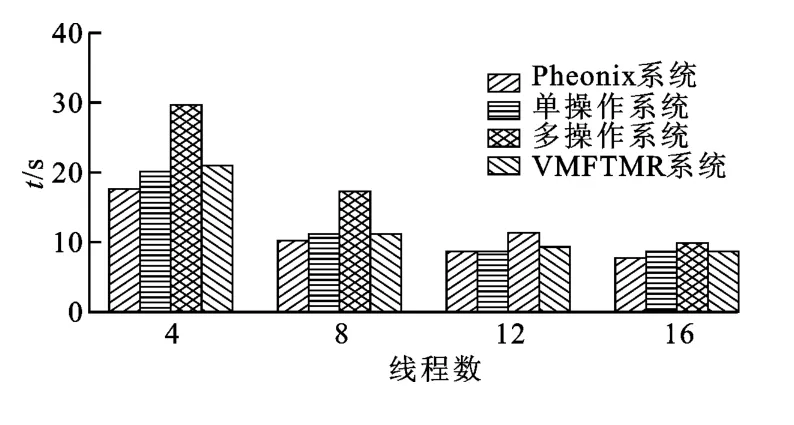
圖4 4種方式進行wordcount計算的執行時間
基于多核虛擬機的具有容錯機制的MapReduce和Phoenix性能差距較小。由于通過使用節點之間的共享內存進行數據傳遞比通過網絡傳輸速度更快,而且作為Reduce輸入數據的中間結果保存在節點之間的共享內存中,執行Reduce的Worker可以直接對這塊內存進行操作,避免了對硬盤訪問帶來的開銷。
3.2 錯誤恢復測試與評價
由圖5可見,當錯誤發生之后,監控者進程迅速發現Worker進程出錯,提示出錯 Worker進程的PID,并重啟 Worker進程繼續執行;如果 Worker進程發生多次錯誤,每次出錯之后監控者進程可以立即感知,啟動新的Worker進程繼續計算,直到完成整個任務。相比發生一次錯誤的情況,出現兩次錯誤的執行過程所耗費的時間沒有明顯增加。

圖5 錯誤恢復過程
圖6為不同出錯次數情況下各種并行計算方式出錯后重啟并完成計算所耗費的時間。
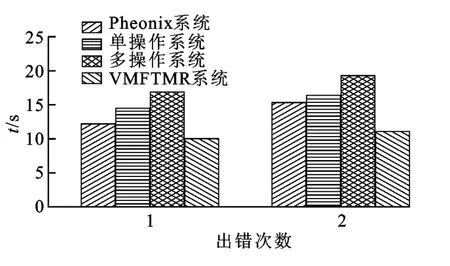
圖6 不同出錯次數的恢復時間比較
基于多核虛擬機的具有容錯機制的MapReduce在出錯之后可以立即重啟并繼續執行,已完成的結果沒有丟失,不會造成計算任務的浪費。由圖6可見,多次恢復之后,本模型相對于其他3種方式,完成計算任務的時間最短,性能最優。
3.3 安全隔離功能測試與評價
通過對中間結果進行檢查點設置,可以在錯誤恢復的過程中通過讀取保存的數據進行恢復。傳統使用檢查點的保存方式是把數據保存在內存或者磁盤中,恢復的時候啟動恢復策略將已經保存的數據恢復出來,然而由于操作系統受到攻擊或者其他惡意程序,保存的數據受到污染,因此恢復之后的結果是錯誤的,如圖7a所示,而基于多核虛擬機的具有容錯機制的MapReduce系統可以進行正確的恢復,如圖7b所示。

圖7 恢復數據區對比圖
虛擬機監控器可以完全控制和管理多核平臺的內存,使操作系統無法直接訪問隔離的內存,因此需要恢復的數據不會受到操作系統內部各種錯誤的影響,保證了恢復數據的安全性。
4 結 論
本文充分利用了多核服務器架構和虛擬化技術的特點,設計并實現了基于多核虛擬機的具有容錯機制的MapReduce,通過虛擬機監控器進行安全數據隔離和恢復,對中間結果進行保存以提高錯誤恢復的性能,降低了節點之間的數據傳輸開銷。測試了系統的性能、錯誤恢復的能力以及安全數據隔離的效果,并與其他并行程序的性能進行相應的對比。結果表明,本文所提出的改進的MapReduce模型提高了錯誤恢復的性能,保證了恢復數據的安全性。下一步將優化檢查點策略,完善錯誤感知機制,減小保存和恢復過程中的性能損耗。
[1] DEAN J,GHEMAWAT S.MapReduce:a flexible data processing tool [J].Communications of the ACM,2010,53(1):72-77.
[2] MOHANTY R P,TURUK A K,SAHOO B.Analysing the performance of multi-core architecture[C]∥Proceedings of the first International Conference on Computing,Communication and Sensor Networks.New York,USA:IJCA,2013:28-33.
[3] MERRITT R.CPU designers debate multi-core future[EB/OL].(2008-02-06)[2012-10-02].http:∥www.eetimes.com/document.asp?doc_id=1167932.
[4] DESNOYERS M,MCKENNEY P E,STEM A S,et al.User-level implementations of read-copy update[J].IEEE Transactions on Parallel and Distributed Systems,2012,23(2):375-382.
[5] Receive-side scaling enhancements in windows server[EB/OL].(2008-11-05)[2012-10-15].http:∥www.microsoft.com/whdc/device/network/ndis_rss.mspx.
[6] MATTHEWS J N,DOW E M,DESHANE T,et al.Running Xen:a hands-on guide to the art of virtualization[M].New Jersey,USA:Prentice Hall,2008:56-59.
[7] CHAPMAN M.HEISER G.vNUMA:a virtual sharedmemory multiprocessor[C]∥Proceedings of the 2009 USENIX Annual Technical Conference.San Diego,USA:USENIX Association,2009:349-362.
[8] GULATI A,MERCHANT A,VARMAN P J.MClock:handling throughput variability for hypervisor I/O scheduling[C]∥Proceedings of the 9th USENIX Conference on Operating Systems Design and Implementation.Berkeley,CA,USA:USENIX Association,2010:1-7.
[9] TALBOT J,YOO R M,KOZYRAKIS C.Phoenix++:modular MapReduce for shared-memory systems [C]∥Proceedings of the Second International Workshop on MapReduce and Its Applications.New York,USA:ACM,2011:9-16.
猜你喜歡
中國外匯(2019年20期)2019-11-25 09:54:58
中國外匯(2019年8期)2019-07-13 06:01:06
電腦愛好者(2018年15期)2018-08-23 17:24:06
民主與科學(2014年3期)2014-02-28 11:23:03
教育與職業(2014年7期)2014-01-21 02:35:04
計算機與網絡(2013年1期)2013-06-05 05:31:50
電腦迷(2012年24期)2012-04-29 00:44:03
中華女子學院學報(2012年6期)2012-03-25 13:52:27
俄羅斯問題研究(2012年1期)2012-03-25 09:54:45
杭州師范大學學報(社會科學版)(2011年3期)2011-04-04 08:58:20
