關系型本體轉換為關聯數據技術方案比較研究
2014-01-16 01:09:23濮德敏任瑞娟
圖書館理論與實踐 2014年12期
●濮德敏,任瑞娟,米 佳,張 欣
(1.河北大學a.管理學院,b.圖書館,河北保定071002;2.天津空港經濟區文化中心,天津300308)
關系型本體轉換為關聯數據技術方案比較研究
●濮德敏1,b,任瑞娟1,a,b,米 佳b,張 欣2
(1.河北大學a.管理學院,b.圖書館,河北保定071002;2.天津空港經濟區文化中心,天津300308)
關系型本體;關聯數據;轉化;Ⅴirtuoso;Triplify;D2R
論述了關系型本體向關聯數據轉化的可行性,在此基礎上分別論述了Ⅴirtuoso Universal Server、Triplify、D2R三種主流的轉化技術方案并進行了比較分析,得出結論:D2R方式是當前規模化轉化的優選方式,并將國內成功實現的研究機構——河北大學知識組織與知識管理實驗室作為本研究的成功案例進行了介紹。
關系型數據庫是結構化數據的存儲方式,也是規模化本體存儲的常用格式,在其中的數據屬性間和表與表間主鍵連接中蘊含大量的關聯關系,此關聯關系是完全可以采取自動或半自動方式提取并加以定義為互聯網語義化組織所廣為應用的。因此,本論文的研究就是針對這種關系型數據,利用關聯數據技術,實現自動或半自動提取數據的關聯關系并加以定義、映射和發布,實現基于關聯數據技術的語義化信息發布,并作為關鍵詞查詢的補充,提高語義查找效率,最終提高搜索結果的語義理解并扶持決策。[1]從本體出發,依據其語義關系,采用關聯數據技術方案是知識檢索的最佳方案,而解決問題的核心是將本體和關聯數據相結合。[2]
1 關系型本體向關聯數據轉化可行性
1.1 關系型數據庫
關系模型的實體以及實體之間的關系都可以用二維表來表示,其屬性間的關系可以看成是一種單一的結構關系。依關系模型中實體間聯系的復雜程度,分成三種:一對一聯系,一對多聯系和多對多聯系。實體關系模型利用圖形的方式呈現,即,實體-關系圖(圖1)來表示數據庫的結構及概念設計。
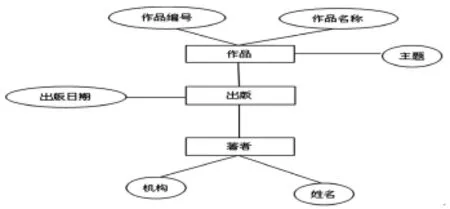
圖1 實體-關系圖
在上述關系模型的實例中,通常將每一個實體設計為一個表,方框中的三個實體則分別存儲著者、出版、作品三類不同實體,橢園內為實例,在關系模型中表現為表的屬性。
1.2 關系型本體
本體能夠體現出知識和知識之間的語義關系,本研究的本體是指由詞表、術語等改造而成的輕量級本體。基于文件系統存儲本體的方式簡單,但檢索效率低,且難適應數據大的情況。采用關系型數據庫存取本體,這適合規模化語義應用系統,能支持大數據下的高效語義查詢。關系型本體依其采用水平或垂直存儲形式的程度,分為水平型存儲、垂直型存儲或混合存儲,表及其屬性根據對術語的含義以及術語之間的關系加以定義。[2]由此,可用關系表來表示某個特定領域的知識。圖2是關系型本體庫的關系圖示。關系表Knowledge中的領域名稱、描述信息、子領域概念、領域公理集和上述本體定義相對應。領域中概念都由概念名稱、屬性、屬性值、實例組成,關系表Sub-WordKnowlege中的名稱、描述信息、關系、屬性集、實例集、子領域概念集和上述子本體組成元素對應。而本體庫中的關系、屬性、實例分別由關系表Relationship、Property、Ⅰnstance來表示。利用這種對應關系,采用關系型數據庫存儲本體。
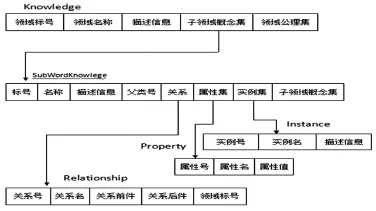
圖2 關系數據庫和本體庫之間的對應關系
1.3 關聯數據組織模式
關聯數據的數據模型是RDF一階謂詞模型。RDF模型可以用三元組的方法來表示,即主語、謂語、客體構成,稱為RDF陳述。例如:張老師教信息檢索課。其中,張老師是主語,是需要描述的資源,教是謂語,它可以看成描述主語與其某個屬性的關系,信息檢索課是客體,它其實可以看成是屬性的值或者關系的值。但不管是主語還是謂語最后都表示成HTTP URⅠ。而客體不僅可以是用HTTP URⅠ標識的資源,也可是文本。即:主語可被認為是類資源,謂語可被認為是類資源的屬性,而客體或者是類資源或者是文字型資源。由客體的種類決定了三元組的分類,即分為文字型三元組以及非文字型三元組。
1.4 可行性分析
把主語和客體看作節點,屬性看成是一條邊,則一個RDF陳述可表示成一個RDF有向圖。RDF實質是一種二元關系的表達,其中屬性和屬性值類似于關系模型,因此RDF數據模型可以被用來描述任何復雜的關系。實際上,屬性和屬性值都可以包含URⅠ,通過URⅠ可以訪問任何可以被標識的事物,因此,RDF能聯系萬維網上各類事物,鏈接萬維網上的各種資源。Linked Data強調通過豐富的RDF鏈接,構建資源的“語境”。[3,4]用戶可通過RDF命名域和值來表達與資源有關的簡單聲明,自定義一些詞匯,然后用這些詞匯來描述資源。
由于關系型數據和關聯數據的概念模型都是基于實體、屬性及其關系而構建,兩者具備建立映射和實現轉換的可能性,這種可能性是基于二者之間的關系確立。關系模型和RDF三元組之間的轉換關系從兩個方面入手:一是概念轉換,二是數據轉換(如表1)。
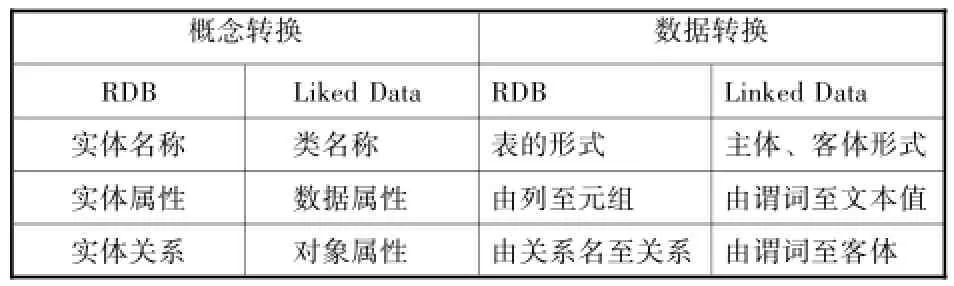
表1 關系模型與三元組之間的映射關系
因此,在關系模型和RDF三元組的轉換中,類名稱、數據屬性與實體名稱、實體關系的映射較明了。從表1可以看出:首先是類與實體的轉換表現為二維表與RDF三元組中類的轉換,也就是二維表轉換為RDF三元組中的主體或客體,而表的主鍵轉換為主語或對象的URⅠ;其次是數據屬性的轉換,也就是二維表的列轉換為三元組中的謂詞,而二維表的行數據,轉換成文本對象。對象屬性的轉換較復雜,在關系數據庫中,實體內部及實體之間的關系有不同的表達和構建方式,且在設計轉換過程中根據實際需求有獨特的應用設計。而在關聯數據中,資源描述框架鏈接表示對象之間的語義關系。因此,對象屬性的映射,是關系數據庫與關聯數據語義組織模式映射的關鍵。[5]關系型數據轉換關聯數據的構建方式、模式轉換、語義映射分析如下。
(1)不同表之間的關聯關系。在關系型的某數據庫中,會用很多不同的表來代表不同的實體,而表與表之間的關系可以看成是實體與實體之間的關系。在關聯數據的資源描述框架中,通過關聯鏈接來表達不同表間的關聯關系。這些關系型數據,根據其不同表之間的關系種類可以劃分為以下兩種。①通過外鍵標引的表間關系。例如在書目數據表中,書目數據的keyword屬性,引自主題詞表的keywordsⅠD,主題數據的母體即keywords屬性,引自本體庫關系敘詞表的subjectⅠD。對這些數據進行關聯數據發布時,應表達這些在數據庫中顯性構建的關聯關系。②通過屬性來關聯的表間關系。例如書目數據表和教師信息表都有name屬性,表明兩者存在一定的關系,使用SQL檢索的語句如下:
select*from書目數據表,教師信息表where書目數據表.name=教師信息表.name
通過上面的SQL檢索語句,可得到書目數據表和教師信息表中相同作者姓名的關聯關系。如果再增加一定的限制條件,還能夠動態獲得某些關聯關系。
(2)同一表內部的關聯關系。①二維表中的列,看以看成一個實體及其屬性之間存在的一對多的映射,表1中的實體屬性和數據屬性的映射轉換。例如關系敘詞表與其諸多列之間,存在一對多的內在聯系。②兩個行列相同二維表,是指可以通過將一個表邏輯上拆分為兩個表,基于屬性相等的條件,構建兩個不同實體的邏輯關系。
(3)與外部數據的關系。關聯數據即為從文檔網絡向數據網絡轉化的一種優化策略,在關聯數據標準下,其可成為目前最好的發布和連接結構化數據的規則。[6,7]在關系型數據轉換為關聯數據過程中,數據關聯化表示與外部更多的數據相關聯時,需將這些數據與已知的URⅠ建立關聯,關聯數據就是通過URⅠ、HTTP、RDF等語義網技術將網絡上相關的數據資源關聯起來。RDF用URⅠ標識事物,用簡單的屬性(Property)及屬性值來描述資源,這使得資源描述框架可以將關于資源的簡單陳述中的一個或多個表示為一個由節點和弧組成的圖。其中,節點和弧代表資源、屬性或屬性值。本質上,RDF數據模型所描述是包含主體、謂詞和客體的三元組。RDF模式定義語言(Resource Description Framework Schema,簡稱RDFS)和網絡本體語言(Ontology Web Language,簡稱OWL)來建立描述實體及其聯系的詞表的基礎。任何人都可以建立網絡數據詞表,但這些數據須用RDF三元組表示,并可與其他詞表相關聯。
2 關系型數據的關聯化轉化主流技術方案
雖然關聯數據在進行數據的語義查詢時帶來了便利,但目前很多現有的數據并不滿足關聯數據的準則。要想把現有的數據發布成關聯數據,須借助自動化工具,Linked Data推動者促使相應工具的產生,常見的主流軟件有D2R、Drupal、Ⅴirtuoso、Triple等,且這些軟件都是開源的。
2.1 Ⅴirtuoso Universal Server方式
Ⅴirtuoso Universal Server系統屬于應用程序服務,其架構為一種網絡實時程序設計架構。Ⅴirtuoso是一種開放鏈接軟件、支持跨平臺應用操作系統,主要功能是提供網絡查詢與瀏覽服務。數據以被稱為三元組的形式存儲(subject-predicate-object)類型,支持導入/導出RDF文件來對數據進行操作。
Ⅴirtuoso具有通用操作系統的特點,提供硬件虛擬化,是一種嵌入式實時操作系統。ⅤirtuosoⅠDE中對于應用程序的編譯、加載、運行可自動完成,并為程序調試提供所有目標的動態信息,程序運行的結果可調用實時庫函數,通過主機實現輸出操作。Ⅴirtuoso Universal Server由關聯數據界面或一個SPARQL端點將數據轉化為RDF數據,且直接存儲在Ⅴirtuoso中。Ⅴirtuoso具備混合體系結構能夠提供以下幾個方面的功能模塊:關系數據管理、RDF數據管理、XML數據管理、文字內容管理和全文索引、文件Web服務器、鏈接數據服務器、Web應用服務器、部署Web服務(SOAP或REST),支持SPARQL查詢。[6]
2.2 Triplify方式
Triplify,是AKSW(The Agile Knowledge and Semantic Web,簡稱ASKW)研究組最近發布的產品,目的在“為萬維網的‘語義化’提供建筑單元”。Triplify是發布從關系數據庫到RDF并且鏈接web數據的一個簡單方法,是基于關系數據庫的映射并可以通過HTTP-URⅠ進行查詢。Triplify為輕量級組件,易集成,易被Web應用程序廣泛部署。不支持SPARQL,不支持發布更新日志。Triplify為小型Web插件,能將關系型數據庫發布成RDF數據。
Triplify可將關系型數據轉換成RDF語句,并在網絡上公布,它提供不同的RDF序列化,特別是為關聯數據。Triplify能夠以RDF、JSON或者Linked Data格式提供數據庫的內容,屬小型Web應用插件,能揭示出關系數據庫中存儲的數據語義結構。通過Triplify插件和在查詢中調整數據列,Triplify可以分析查詢所返回的數據,并以前面提到的格式對外提供數據。基于重新映射HTP URⅠ請求,Triplify可以分析查詢所返回的數據,能將HTML DOM數據以RDF格式序列化輸出,從而揭示出關系數據庫中所保存數據的語義結構。不需維護大規模語義定義,支持Web環境下拓展關聯數據應用。
2.3 D2R方式
D2R(Database to RDF,簡稱D2R)軟件是目前使用廣泛的工具,能夠支持多種主流關系型數據如Oracle、MySQL、PostgreSQL、Microsoft SQLServer、Microsoft、Access等。它的功能是把關系型數據庫發布成Linked Data。
D2R發布關聯數據時的映射機制主要分為兩大部分,第一部分是構建關系型數據庫與RDF三元組之間映射關系,即利用映射語言,將映射關系用RDF三元組的形式描述出來,形成映射文件;第二部分是構建關聯數據服務,應用第一部分中形成的映射文件對關系型數據進行轉化,并提供多種訪問模式。D2R主要包括三個核心部分:D2R Server、D2RQ Engine和D2RQ Mapping語言。[5,8]圖3是D2R總體框架及運行機制圖。

圖3 D2R總體框架及運行機制圖
3 主流轉化技術方案對比分析
3.1 相同點與不同點比較分析
通過對D2R、Ⅴirtuoso、Triple三種軟件的介紹,總結它們的異同,便于將關系型數據轉換成關聯數據時選擇最合適的方案,為本研究的實現搭建最優平臺(如表2)。
(1)相同點。①均為web服務,屬于B/S(Browser/Server,瀏覽器/服務器模式)模式,這種模式統一了客戶端,將系統功能實現的核心部分集中到服務器上,簡化了系統的開發、維護和使用。關聯數據發布到Web服務器,用戶只需有一臺能上網的電腦通過Web瀏覽器就能訪問客戶端。因此,系統的擴展性非常容易,只要能上網,再由系統管理員分配一個用戶名和密碼,就可以使用了。甚至可以在線申請,通過服務器內部安全認證后,系統可自動分配給賬號,不需要人工參與。②均為轉化RDF的專用工具。③均有對域名的依賴。D2R、Ⅴirtuoso、Triple三種軟件在發布關聯數據后,都需要通過Http或者URⅠ協議進行瀏覽訪問。
(2)不同點。①自動化程度不同。D2R自動化程度最高,Ⅴirtuoso屬于半自動化軟件,Triple是依靠人工操作多,自動化程度最低。②數據庫語義驅動類型不同。D2R和Ⅴirtuoso屬于可以手工定制數據庫驅動,Triple是只局限于自己的領域。③訪問的接口不同。D2R可以通過關聯數據和SPARQL兩種方式展示,Ⅴirtuoso則是依賴SPARQL,而Triple是直接用關聯數據形式訪問。

表2 三種方案的比較
(DB+M指,半自動方法即可以手動進行定制)
D2R是用來將關系數據庫中的內容發布到語義網上的一個工具,在語義網中,使用RDF對數據進行建模和表示,D2R Server使用一個可定制的D2RQ映射文件來將關系數據庫中的內容映射成RDF格式,并使這些數據可以被瀏覽和搜索到,這也是語義網中兩種主要的訪問模式。
3.2 D2R的優勢
作為一種致力于關系型數據庫的RDF映射框架,D2RQ由于其對環境(操作系統、數據庫版本等)的適應性、操作簡便性以及靈活的可配置性,仍不失為對現有數據內容完成關聯數據化發布的最佳選擇。D2R是其中一個非常流行的工具,它的作用是將關系型數據庫的數據轉換為虛擬的RDF數據進行訪問。D2R主要包括D2R Server、D2RQ Engine以及D2RQ Mapping語言。選擇D2R Server的原因如下。
(1)D2R Server沒有將關系型數據庫發布成真實的RDF數據,而是使用D2RQ Mapping文件將其映射成虛擬的RDF格式。它的好處是可以適時地使以大型關系數據庫為后端的應用系統可以提供語義服務,而不用事先將大量關系型數據庫存儲在專用RDF數據庫中。
(2)D2R Server是一個HTTP Server,是廣泛應用的關系數據庫內容發布成關聯數據的一種工具。用D2R Server發布的關聯數據集有:Berlin DBLP Bibliography Server;Hannover DBLPBibliography Server;歐盟國家和地區數據庫;歐洲研究和發展信息服務;歐洲就業服務;歐洲研究領域人才數據庫。D2RQ Engine并沒有將關系型數據庫發布成真實的RDF數據,而是使用D2RQMapping文件將其映射成虛擬的RDF格式。一般來講,數據庫的數據規模都比較大,且內容經常發生變化,轉換為虛擬的RDF數據空間復雜度會更低,更新內容更加容易,因此,D2R的應用更加廣泛。
4D2R方案案例:河北大學知識組織與知識管理實驗室D2R項目
該項目組在國家社科基金與教育部人文社科基金支持下建立,通過在完成詞表本體化組織基礎上,通過D2R生成映射文件完成了關系型數據的二維組織模式轉換為RDF的三元組模式;通過關聯數據的統一語義描述方法(RDF)和統一存取機制(SPARQL),實現了對書目信息關聯化發布及在關聯發布與本體基礎上的語義化組織與語義化聚合。
項目組在實驗室通過D2R實驗實現了下述內容(網址:http://sinto.hbu.edu.cn/D2R)。
(1)書目數據的關聯化發布。初步實踐基于本體構建語義關聯,通過關聯數據的一致化語義描述方法(RDF)和統一存取機制(SPARQL)進行語義化組織,實現書目數據關聯化發布。
(2)映射的形成。將數據結構、約束條件轉換為本體的概念語義和規則語義,通過執行D2R生成映射文件的執行腳本Generate Mapping實現[9]了關系型數據的二維組織模式轉換為RDF的三元組模式。
(3)原有的語義關系的細化及書目數據的語義聚合。通過詞表本體化組織及關聯化發布,基于本體與實際語義邏輯修改MAPPⅠNG文件,實現書目原有語義關系的細化及細化關系后的書目數據的語義聚合。
[1]肖強,鄭立新.關聯數據研宄進展概述[J].圖書情報工作,2011(13):72-75,134.
[2]任瑞娟,等.分布式本體編輯系統(ADORES)的設計與實現[J].現代圖書情報技術,2011(3):9-16.
[3]白海燕,喬曉東.基于本體和關聯數據的書目組織語義化研究[J].現代圖書情報技術,2010(9):18-27.
[4]黃永文.關聯數據驅動的Web應用研究[J].圖書館雜志,2010(7):55-59.
[5]白海燕,梁冰.利用D2R實現關系數據庫與關聯數據的語義映射模式[J].現代圖書情報技術,2011(z1):1-7.
[6]孫鴻燕.圖書館關聯數據的綜合管理及其實現[J].圖書館學研究,2011(23):51-54,5.
[7]任瑞娟,等.基于概念云與本體的信息檢索系統(ⅠRSCCO)的設計與實現[J].情報學報,2011,29(6):992-999.
[8]Miller,et al.Linked data and libraries[J].Serials Librarian,2011,60(1-4):17-22.
[9]王毅喆,張力.金融領域基于本體模式的關聯數據轉換解決方案[J].計算機工程,2007,33(12):93-95.
G250.74
A
1005-8214(2014)12-0030-05
濮德敏(1968-),女,副研究館員,碩士,發表論文10余篇;任瑞娟(1970-),女,教授,博士在讀,發表論文及出版著作30多篇(冊);米佳(1976-),男,副研究館員,本科,發表論文20余篇;張欣(1986-),女,碩士,發表論文2篇。
2014-02-26[責任編輯]菊秋芳
本文系教育部人文社會科學研究一般項目規劃基金(項目編號:11YJA870019)和教育部“網絡時代的科技論文快速共享”研究資助項目(項目編號:201113)研究成果之一。
猜你喜歡
當代陜西(2021年17期)2021-11-06 03:21:36
開放教育研究(2020年2期)2020-03-31 01:54:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
財經(2017年2期)2017-03-10 14:35:35
讀者(2017年5期)2017-02-15 18:04:18
財經(2016年15期)2016-06-03 07:38:02
現代語文(2016年21期)2016-05-25 13:13:44
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
