統一并行體系結構實驗平臺研制
2013-12-23 05:40:14周春云羅秋明
實驗技術與管理 2013年2期
蔡 曄,周春云,羅秋明
(1.深圳大學國家高性能中心深圳分中心,廣東深圳 518060;2.揚州萬方電子技術有限責任公司,江蘇揚州 225006)
1 并行體系結構的發展
近年來,隨著微處理器技術的發展和進步,主流并行計算體系結構獲得了飛速發展。目前多核處理器已經成為主要的計算單元,傳統的并行體系結構底層逐步向片內過渡,并行計算的并行層次相應增加。另外,混合異構結構迅速發展,快速標量部件、向量部件、FPGA、GPU 等加速部件已充分應用到在并行體系結構上[1]。
SMP(symmetric multi-processor)結構是傳統并行體系結構中高性能服務器和工作站架構提升性能的有效手段。SMP當前發展趨勢是逐步向片內多核過渡,將SMP系統實現在一塊芯片內部。由于多個處理器集成在一塊芯片上,故采用共享緩存或者內存的方式,同時利用片內的高帶寬總線來替代片外總線,可以有效降低多線程通信延遲。CC-NUMA(cache-coherent NUMA)結構主要針對SMP結構在可擴展上的局限性,實現在更大規模上的并行計算。傳統CC-NUMA互連技術一般使用多級交叉開關結構來減少連接代價,由于受物理通信鏈路數量以及并行總線頻率增長的約束,以及專用互連芯片帶來了額外的延遲,早期的結構在多核處理器出現后,處理器間通信能力很難適應日益增長的片上通信帶寬,因此出現了處理器間直接互連技術(direct link)。direct link的主要技術特點:一是首先處理器集成內存控制器,可讓主內存響應時間更快,同時可降低緩存大小以及芯片制造的成本;二是通過專用連接通道實現處理器間直接通信,避免了專用橋或路由芯片的使用,可減少系統成本和轉發帶來的延遲;三是基于先進的串行通信技術來提供高速連接,通過一路或多路并行來保證互連帶寬。
在系統級互連方面,典型結構依然為機群CLUS-TER 結構以及MPP(massively parallel processor)結構,CLUSTER 是一種松耦合結構,MPP 為緊耦合結構。MPP處理器之間通常由伸縮性較好的特制的互連網絡(如Mesh、交叉開關網絡等)相連,每個處理器之間通過消息傳遞的方式進行通信和協調。機群系統將大量同一品種的工作站或微機通過高速網絡互連,以構成廉價的高性能計算機系統。MPP 和CLUSTER 結構在多核處理器出現后,面臨著新的挑戰,多核作為一種新的并行層次出現,并行軟件需要相應的發展變化,或尋求從底層來應對,對多核加以隱藏,或是把高端計算里面并行程序設計語言和環境(如MPI和OpenMP)組合起來用,根據多核的特點,充分利用新的體系結構的優勢加以性能優化。另外,混合異構結構的普遍出現和應用,導致軟件基礎架構的關鍵部分難以跟上變化的步伐,也給傳統并行算法的設計和教學帶來了機遇和挑戰。
計算機并行體系結構和并行軟件日新月異的發展,導致高校在進行并行體系結相關課程教學時,首先要及時跟蹤國內外并行體系結構領域的主流技術和最新進展,并反映到課堂教學上;其次要不斷更新相關的實驗室設施、設備,以及實踐方法和手段,以適應不斷變化的并行體系結構的教學需求。
深圳大學國家高性能中心深圳分中心致力于國產個人高性能計算機的研制,先后和相關單位聯合研制了KD 系列[2-3]和SD 系列[4]個人高性能計算機(personal high performance computer,PHPC)系統[5]。從2010年起,結合科研優勢,在本科教學層次成立了高性能計算特色班,立足為高性能計算發展和并行計算培養高素質的基礎學術性人才和應用型綜合人才。為了滿足教學和實驗的需求,結合研制PHPC 系統的技術積累,和相關公司聯合設計了一種統一并行體系結構實驗平臺。“統一實驗教學”平臺的概念由清華大學計算機實驗教學中心提出[6-7],并設計了計算機硬件統一實驗平臺,完成了對計算機硬件課程實驗的整合,支持計算機硬件系列課程中的主干課程實驗(數字邏輯、計算機組成原理和計算機系統結構)。實踐表明,有效減少了教學資源的硬件浪費,縮短了學生熟悉實驗設備的時間,提高學生實驗的系統性。
本文研制的統一并行體系結構實驗平臺(以下簡稱實驗平臺)基于“統一實驗教學“的思想,采用國產高性能多核處理器龍芯3A(4核)或3B(8核)[8]進行設計。該實驗平臺具有以下特點:(1)便攜性,采用PHPC技術,在單一定制機箱(440 mm×420 mm×320mm)單元內可支持高達萬億次的并行計算能力;(2)靈活性,可通過系統配置支持最新的各種并行體系機構以及互聯結構,并實現功能擴展;(3)統一性,可將計算機并行體系結構相關的多門課程和實驗教學統一到一個實驗平臺上;(4)開放性,從系統硬件、BIOS、操作系統以及并行計算基礎平臺都進行了開源,可支持更深入的教學或科研工作;(5)先進性,符合當前計算機并行體系結構發展的最新進展。
2 統一并行體系結構實驗平臺設計方案
該實驗平臺的設計目標是利用PHPC 技術,設計便攜的面向并行體系結構教學和實驗用的儀器平臺,系統峰值性能可達萬億次,不但能滿足教學和實驗的需求,而且能提供給科研人員使用。并行體系結構實驗平臺采用了國產龍芯3號處理器,龍芯3號的互連接口采用了擴展的HyperTransport(HT)[9]協議,既可以連接IO,也可以實現多芯片間的直接互連(direct-link)。龍芯3 號在單芯片上同時提供了板級互連接口(HT0,16位,可拆分為2個8位通道使用)以及系統級的互連接口(HT1,16位,可拆分為2個8位通道使用)。在統一并行體系結構實驗平臺中,HT0用來實現2個處理器直接互連以實現CC-NUMA 結構,而HT1則拆分為2個8位通道,其中高8位HT1通道用于連接系統北橋和南橋,進行網絡IO 接口擴展,擴展后的網絡IO 接口信號連接到背板的FPGA芯片上進行交換;低8位HT1通道則直接連接到背板的FPGA 互聯芯片上,支持通過處理器前端總線直接高效地進行交換。背板通過FPGA 實現10個處理器的互連,通過配置可實現不同的互連方式和拓撲結構。該實驗平臺可滿足并行體系結構相關課程,包括:計算機高級體系結構[10],并行計算機體系結構,并行算法的設計與分析,并行算法實踐,并行程序設計等[11-14]的教學和實驗需求。
2.1 實驗平臺總體結構
該實驗平臺總體組成包括:440mm×420mm×320 mm 單一定制機箱;計算節點(雙路龍芯3/AB 8核處理器刀片)×5,集成10個(PE1—PE10)龍芯3A8核(或龍芯3B8核)處理器,系統峰值性能可達萬億次(采用龍芯3B);前置服務主板1個,提供系統引導、磁盤存儲、用戶登錄、任務調度等功能;系統支持雙交換通道,即16端口千兆以太網交換通道以及背板定制的FPGA 互連交換通道,其中16端口千兆以太網交換機用于系統內部管理,連接前置服務主板和5個龍芯計算刀片,而背板上定制的FPGA互連通道則用于計算節點之間計算和數據交換使用,可提供2種互連交換模式,一種為48端口以太網交換方式,在這種模式下,處理器通過南橋擴展的網絡接口直接連接到FPGA進行網絡交換;另一種為通過處理器前端HT總線直接進行交換的模式,即MPP互連模式,在MPP互連模式下,通過配置內部路由模塊的參數可實現計算節點間不同的系統互連和拓撲結構。系統總體結構參見圖1。
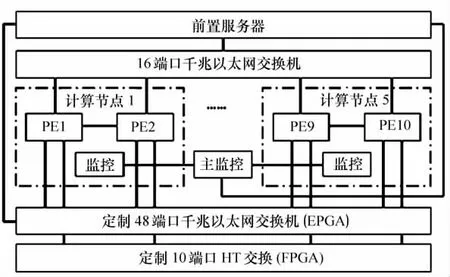
圖1 系統總體結構
2.2 計算節點結構
該實驗平臺的計算節點采用2 個龍芯多核處理器作為計算處理單元(PE),2 個龍芯多核處理器之間通過基于HT 總線的直接互連技術實現CC-NUMA 并行結構,該系統在設計時可同時兼容龍芯3A(4核)或龍芯3B(8 核)處理器。在采用龍芯3B 時的計算節點結構如圖2 所示,單處理器為8 核SMP結構,雙處理器之間使用直接互連技術,通過處理器前端HT 總線構成2 路CC-NUMA 結構,每個計算節點可實現16 核的CC-NUMA 結構的高性能并行系統。
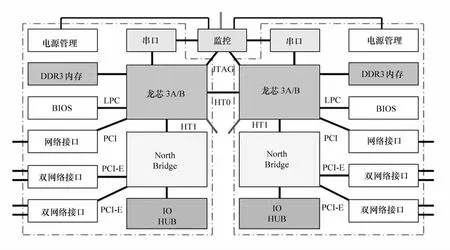
圖2 雙路龍芯CC-NUMA結構
與常規CC-NUMA 結構系統共享一個IO 套片不同,該實驗平臺每個處理器采用了獨立的IO 套片進行IO 功能擴展,每個處理器計算節點為每個處理器提供了高達5路千兆網絡互聯接口。因此系統并行結構在不使用處理器間CC-NUMA 互連通路時(通過軟件配置)可以配置為SMP-CLUSTER(MPP)兩級并行結構,在使用處理器之間互連時可以配置為SMP-(CC-NUMA)-CLUSTER(MPP)的三級并行結構。在表1 中列出了該實驗平臺支持的7 種并行體系結構。由于龍芯3B處理器內部采用了向量部件加速部件技術,在使用龍芯3B 處理器時,還支持基于向量部件的混合異構結構。每個計算節點提供了高速FLASH(SATA DOM 盤)本地存儲,也可利用外部共享磁盤陣列處理海量數據。
當采用MPP互聯模式時,可通過對FPGA 內部實現的路由器的連接和對參數進行靈活配置以實現不同的互聯拓撲結構。實現的路由器結構示意圖見圖3。每個處理器通過HT1 低8 位互連通道與FPGA內部實現的一個路由器(Router)相連接,路由器支持東、南、西、北和上、下總計6 個連接通路,用于和其他處理器的路由器連接,每個方向可根據實際需求連接和配置使用。因此可通過不同的配置實現常見的二維(使用東、南、西、北4個通道)、三維(使用東、南、西、北和上、下6 個通道)、環形(使用東、西2 個通道)以及樹形等拓撲結構,可在教學和實驗中讓學生實際配置,以及評估不同互連拓撲的結構特點并進行性能分析。
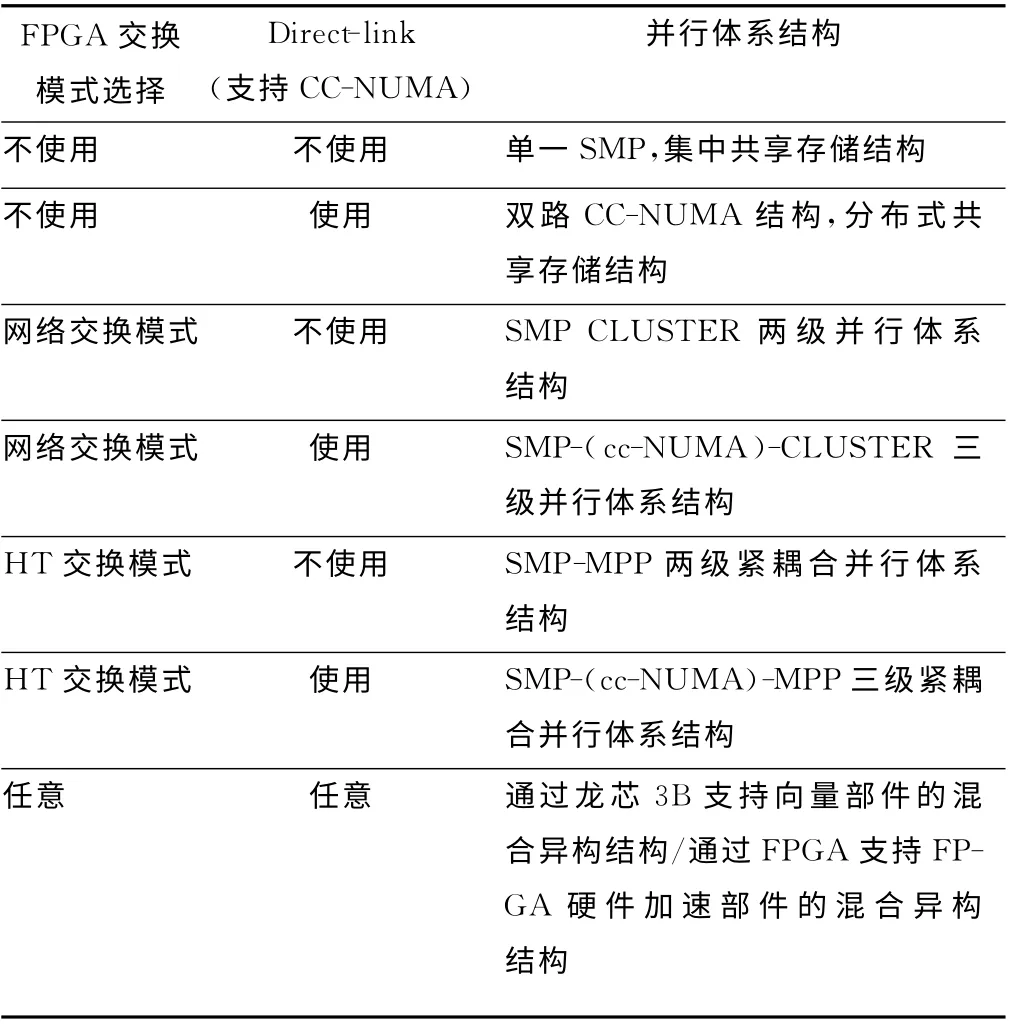
表1 統一并行體系結構實驗平臺并行體系結構的配置
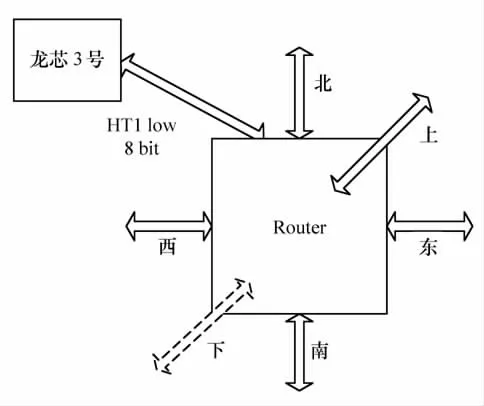
圖3 FPGA路由器結構示意圖
2.3 監控管理方案
該實驗平臺采用了遠程分布式實時監控方案,如圖4所示,前置管理服務器通過百兆網絡與底板的控制單片機AX11015通信,完成對整個系統的管理。其監控網絡由I2C 總線、UART 總線和若干控制總線組成,控制AX11015單片機可根據系統負載狀況,獨立關閉處理單元或者計算節點,以及自動調節散熱風扇的轉速,或通過串口獲取處理器的運行狀態,通過UART 轉TCP/IP機制發送到遠程服務器上。
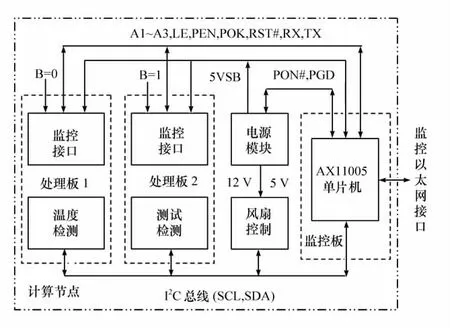
圖4 系統監控管理方案
3 基于該實驗平臺的教學思路
采用該實驗平臺實施并行體系結構相關課程的教學,有利于解決現在各課程獨立進行教學和實驗時存在的問題。傳統教學的各門課程教學和實驗內容各自獨立,相互之間缺少銜接性,學生在學習過程中無法建立系統的概念,而且現有的實驗設備缺少靈活性,無法跟上體系結構的實際發展,不能真實地提供不同并行體系結構和互連拓撲結構,而且很多實驗僅通過仿真軟件實現,實驗方式限制了學生的興趣和創造性。另外,不同課程總共需要的實驗設備和PC機型號相對較多,實驗室管理困難,維護成本較高。采用統一并行體系結構實驗平臺則能有效地解決這些問題。
深圳大學面向本科教學的并行體系結構系列課程主要有4門:并行體系結構、并行算法設計、并行數值算法以及并行程序設計和實踐。在引進該實驗平臺后,采取了“統一實驗教學”的思路,系列課程設定統一的教學目的,各課程的教學內容按總體目的分工劃分,但相對獨立,實驗內容統一在該實驗平臺上完成,并保證個課程實驗內容之間的銜接性。這樣學生在實驗時可以快速上手,充分激發學生學習并行體系結構和并行計算的積極性,縮小理論教學和實際應用能力之間的差距。
深圳大學設定的并行體系結構系列課程的統一教學目的為:系列課程以并行體系結構和并行計算為主題,要求講授并行計算的硬件平臺(當代并行計算機系統及其結構模型)、軟件支撐(并行程序設計)和理論基礎(并行算法的設計和并行數值算法)。在內容組織上,強調并行機結構、并行算法和并行編程為一體,著重討論并行算法的設計及其實現,并力圖反映本學科的最新成就和發展趨勢,體現并行機硬件和軟件相結合、并行算法和并行編程相結合的思想。在教學過程中采用統一的并行教學實驗平臺,各課程統一安排足夠數量的實踐內容,以鞏固和加深學生對并行算法理論、設計技術、分析方法和具體實現等各個環節的銜接性和整體理解。
根據系列課程的總體要求,具體課程總體實驗教學的總體要求如下:
(1)并行體系結構:通過該實驗平臺讓學生熟悉4種以上的主流并行計算平臺,包括共享存儲的多處理機(SMP)、分布存儲的多計算機(CC-NUMA)、目前流行的PC機群結構以及MPP并行結構,實現不同的互連拓撲結構并進行性能測試。要求學生能夠使用上述幾種并行計算平臺所提供的硬/軟件環境及工具來開展自己的實驗工作。
(2)并行程序設計和實踐:在該實驗平臺上熟悉Linux操作系統和并行編程環境,掌握至少2種并行程序設計語言標準,即分布存儲的MPI和共享存儲的OpenMP。另外,對面向大型科學和工程計算的HPF(高性能Fortran)也應盡量了解和熟悉。
(3)并行算法設計:選擇典型的非數值并行算法,使用并行程序設計和實踐用的并行編程語言標準,在不同的并行計算平臺上編程調試、分析和運行它們,要求通過不同特點的算法讓學生體會不同的并行計算平臺的優劣。
(4)并行數值算法:選擇典型的數值并行算法,使用并行程序設計和實踐用的并行編程語言標準,在不同的并行計算平臺上編程調試、分析和運行它們,要求通過不同特點的數值算法讓學生體會不同的并行計算平臺的優劣。
這樣,通過該實驗平臺,相關課程的教學和實驗具有一定的銜接性和繼承性,使學生能在統一規劃下逐步掌握底層硬件和系統結構、基礎并行軟件平臺、并行應用開發的全過程。
4 小結
統一并行體系結構實驗平臺的研制成功,將給高校計算機專業并行體系結構系列課程的教學提供一個新的思路。統一并行體系結構實驗平臺能保證系列課程的實驗內容具有良好的銜接性,充分提高學生的實驗興趣和實驗的積極性,對進一步深化相關課程的教學改革、提高課程的教學水平和教學質量、促進課程的建設與發展具有重要意義。
(
)
[1]陳國良,孫廣中,徐云,等.并行計算的一體化研究現狀與發展趨勢[J].科學通報,2009,54(8):1043-1049.
[2]張俊霞,張煥杰,李會民.基于龍芯2F的國產萬億次高性能計算機KD-50-I的研制[J].中國科學技術大學學報,2008,38(1):105-108.
[3]張俊霞,李春生,張煥杰.KD-50-I-E:一臺增強型高性能計算機[J].中國科學技術大學學報,2009,39(8):894-896.
[4]陳國良,蔡曄,羅秋明.國產個人高性能計算機系統研制[J].深圳大學學報,2011,28(6):471-477.
[5]孫凝暉,陳國良.PHPC:一種普及型高性能計算機[J].中國科學技術大學學報,2008,38(7):745-752.
[6]全成斌,管曉培,李山山,等.計算機硬件實驗統一平臺設計[J].計算機教育,2008(18):3-5.
[7]湯志忠.清華“計算機專業實踐”課程的創新與實踐[J].計算機教育,2006(7):7-9.
[8]Hu W,Wang J,Gao X,et al.Godson-3:A Scalable Multicore RISC Processor with x86Emulation[J].IEEE Micro,2009(29):17-29.
[9]HyperTransportTM I/O Link Specification Revision 3.0[S].USA:HyperTransport Technology Consortium,2006.
[10]鄭緯民,湯志忠.計算機系統結構[M].北京:清華大學出版社,2001.
[11]陳國良.并行計算:結構·算法·編程[M].北京:高等教育出版社,2003.
[12]陳國良.并行算法的設計與分析[M].修訂版.北京:高等教育出版社,2003.
[13]陳國良.并行計算機體系結構[M].北京:高等教育出版社,2003.
[14]陳國良.并行算法實踐[M].北京:高等教育出版社,2003.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
哲學評論(2021年2期)2021-08-22 01:53:34
內蒙古教育(2021年20期)2021-03-08 01:09:14
計算機教育(2020年5期)2020-07-24 08:53:38
家庭影院技術(2019年11期)2019-12-09 09:14:30
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
