標準文獻語料庫構建研究
2013-12-10 03:16:32李國鵬程永紅
圖書館理論與實踐 2013年12期
●李 景,李國鵬,汪 濱,劉 華,程永紅
(1.中國標準化研究院;2.中國科學院 文獻情報中心;3.中國科學技術信息研究所,北京 10088)
語料庫,指存放原始語言材料的數據倉庫。一般的語料庫其語料加工來源非常廣泛,包括叢書、詞典、專著、辭源等。標準文獻語料庫的加工主要以標準文獻和技術法規為主。知識庫,是用于知識管理的一種特殊的工具,以便于有關知識領域知識的采集、整理以及提取。知識庫中的知識對象,是求解問題所需專業領域知識的集合,包括基本事實、規則和其他有關信息。
語料庫、知識庫和知識組織體系的構建,是知識管理和知識服務的基礎、前沿和熱點,語料庫的根本目的是為實現語義標引、機器翻譯、知識關聯、數據挖掘、智能檢索等功能和模塊提供基礎和支撐。國家標準館作為國家重點支持、面向全國服務的國家級標準文獻服務機構,不但在迅速實現館藏資源數字化、服務模式網絡化的轉變方面負有責無旁貸的重任,而且面臨著以國家級館藏文獻資源提供知識服務,滿足全國企業和用戶標準信息需求的使命。以國家標準館數字資源為用戶提供知識服務,直接關系著國家的標準文獻資源建設能否持續穩定發展,關系著全國用戶能否更加便捷、高效的利用標準文獻數字資源,也關系著國家標準館能否順應知識經濟時代要求,實現可持續發展。
1 研究和構建方法
現代網絡條件下,語料庫的構建通常以基礎術語數據庫和相關領域文獻素材中的敘詞為素材,輔以專業詞典,提煉語料。對已提煉的語料進行標注和注釋,通過審核后,錄入語料庫,并逐步建立和完善語料素材間的關聯關系。標準文獻語料庫的構建分為兩部分:一是語料數據庫(簡稱“語料庫”)的構建;二是語料庫原型系統的開發。
1.1 語料庫構建方法
(1)文本抓取和準備:標準文本和Web信息的獲取和數字化文本的準備。(2)語料提取:從標準文獻中提取語料信息。(3) 標注和注釋。① 標注:將文本信息中的語料(概念,知識對象)進行標記和表示,分為詞法標注,語義特征標注,雙語(中英文)的對應。② 注釋:為概念添加定性描述。(4)建立數據庫:將語料素材錄入數據庫,并建立雙語語料映射表。(5)更新、維護和修復:不斷補充完善語料素材,填充數量,提高質量,校正語料(知識對象)之間的關系,使之更加符合邏輯性。
1.2 語料庫原型系統的開發
原型系統總體設計采用通用的B/S(客戶端/瀏覽器)結構,系統支持通用格式數據庫的導入導出。(1) 客戶端(實現):語料的錄入、注釋,語料庫的編輯、校正,中英文文本的對照,實現對語料庫中語料素材(知識對象)的調用,對文檔的管理與標引,對譯文模板進行調用。(2)服務器端(實現):語料素材(知識對象)的集中存儲、語料庫版本的管理與配置。
1.3 國家標準館進行標準文獻語料庫的構建基礎
在標準文獻資源方面,依托“標準文獻譯文數據庫建設”項目,國家標準館擁有經過篩選鑒別的國家標準和等同采用 (IDT) 國際標準的數字化文本10956件的數據庫,擁有譯文數字化資源文本36519件 (BS:2161件;DIN:3957件;GOST:4312件;IEC:3577件;ISO:10289件;ITU:5649件;JIS:674件,截至2011年1月27日),擁有中英文對照敘詞表等語料素材38663條。等同采用的標準文本經過比對后,可以提煉出規范的譯文模版和準確的雙語種術語對照,敘詞表則可以作為構建語料庫的素材和基礎。
2 標準文獻語料庫構建的功能需求分析和功能實現
2.1 瀏覽功能
原型系統中實現了分專業領域瀏覽語料資源,點擊圖1頁面左側菜單可以分專業領域導航,瀏覽不同專業領域的語料(見圖2)。
原型系統中實現了對逐項語料進行瀏覽,在圖1顯示的界面中點擊一條語料,如“中醫學”,能夠顯示該條語料的詳細信息。
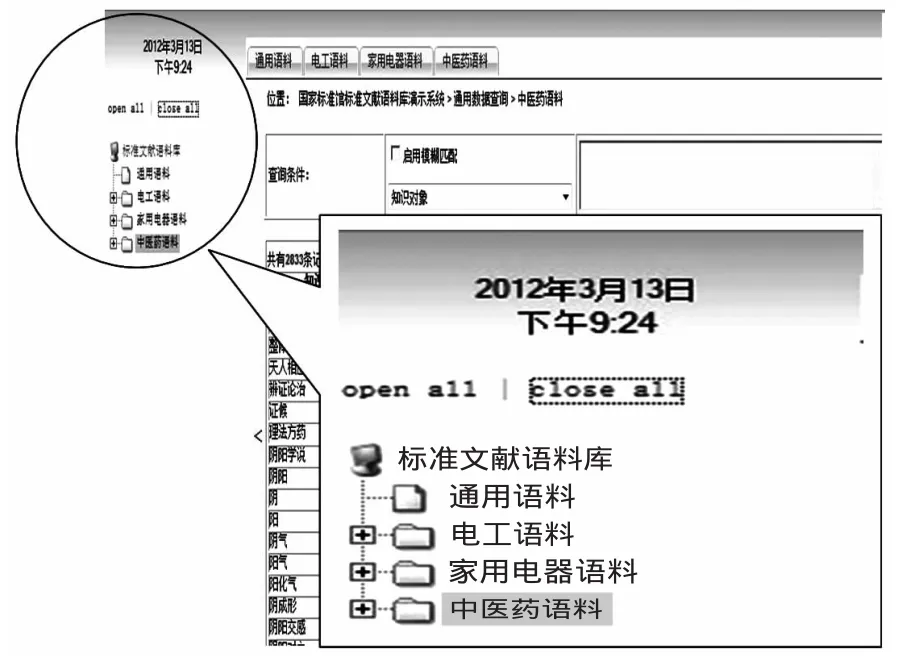
圖1 分專業瀏覽語料的原型系統頁面
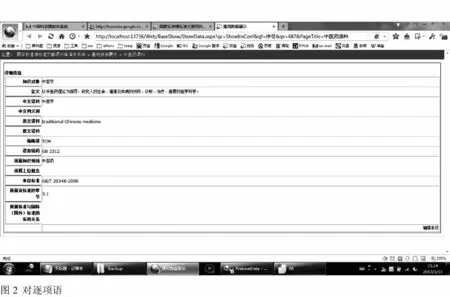
圖2 對逐項語料進行瀏覽的原型系統頁面
2.2 檢索功能
(1)功能需求。① 模糊檢索功能:實現雙語輸入的模糊檢索功能。② 關鍵詞檢索功能:輸入中英文關鍵詞,查詢對應的語料。③ 標準號檢索功能:輸入標準號,查詢該標準中包含的語料素材。
(2) 功能實現。功能需求 ① 的實現見圖3,該功能通過原型系統主頁面檢索框實現。功能需求 ②的實現見圖4。通過在查詢界面輸入關鍵詞,“啟用模糊匹配”功能,如輸入“中醫”,可以查詢到包含“中醫”的“中醫學”和“中醫基礎理論”兩條術語。需求功能 ③ 的實現見圖5。在查詢界面輸入標準號,可以顯示該標準中包含的語料素材。
圖3 原型系統首頁(簡單檢索界面)

圖4 關鍵詞檢索功能的原型系統頁面

圖5 利用標準號檢索的原型系統頁面
2.3 語料錄入和編輯功能
(1)語料錄入功能,能夠在原型系統中增加新的語料記錄。
(2)語料編輯功能,能夠對系統里有的語料進行修改、編輯、操作、保存等功能。
3 系統架構
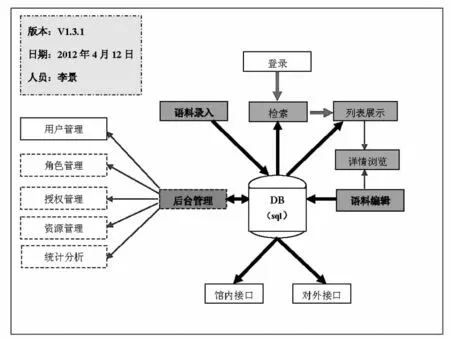
圖6 原型系統架構圖
以語料數據庫為中心數據庫,實現檢索、語料記錄概覽(列表展示)、詳情瀏覽、語料錄入和編輯、以及后臺管理(數據的批量導入和導出),見圖6。其中的檢索、語料記錄概覽(列表展示)、詳情瀏覽、語料錄入和語料編輯、以及后臺管理(部分)功能為已實現功能。后臺管理中的用戶管理、角色管理、授權管理、資源管理、統計分析等功能,以及館內接口和對外接口,由于經費和時間所限,留待后續研究中實現。
4 標準文獻語料庫的應用前景
4.1 支持標準文獻翻譯
本文的研究,促進標準化術語信息資源的建設和標準化術語應用系統的研發,可以有效幫助標準制定人員的工作,促進我國標準化工作整體水平的提升。同時為廣大用戶(包括政府部門、企業、個人)提供便捷、高效、準確、全面的標準術語編寫和信息服務,以保證標準文本中術語的協調性和一致性,從而促進標準質量的提升。
通過實施本課題完善標準術語數據資源、標準文獻語料庫及其相關的資源建設,為進一步開展標準中術語的推廣普及和相關研究構建了一個技術支撐平臺。研究形成的提供支持翻譯功能的語料庫,能夠在翻譯服務中,提高翻譯文本的質量。同時還能夠提供翻譯文本與原標準文本的比對功能,達到校核質保的目的,提高譯文質量。
從國家層面來講,希望能推動我國的國家標準走向國際,提供有力的工具。目前國標英文版的轉化工作困難重重,沒有大規模開展。雖然有多種原因,但缺乏多語種版本的語料和適當工具,是一個重要因素。通過這個課題建立標準文獻語料庫,希望對國標走向國際化產生實際的推動。同樣,語料庫的建立,對于國外標準翻譯成中文,或者是對我國的采標工作也將有所裨益。
4.2 支持標準文獻信息加工
可以將已有的語料加工合并入標準文獻信息加工流程中,增加標準文獻標引的深度和精度,改善數據加工質量,提高標準文獻的檢全率和檢準率。
4.3 支持標準文獻檢索
如將完備的語料記錄輸入數據庫底層,可以完善檢索用詞庫,增加用戶輸入檢索式時模糊匹配的精度,提高標準文獻的檢全率和檢準率。完備的語料庫,能夠反映詞匯的語義映射關系和語義限制。
如果僅僅按照用戶輸入的檢索詞進行檢索,肯定會造成“漏檢”。用戶輸入的檢索詞和用戶自身的知識背景、檢索能力以及檢索經驗相關,可能只是某一概念的若干同義詞、近義詞或是相關術語中的一個。研究者可以利用本體規范概念集自動地將檢索詞映射到它的同義詞、近義詞和相關詞上,利用一組規范的概念進行檢索。[1]
另一方面,一個詞可以有多個含義,用戶進行檢索時往往只是針對它的一個含義。如果只進行簡單匹配,會造成“誤檢”。例如,用戶輸入“牡丹”,可能會查找到花卉牡丹,也可能會找出牡丹江市、牡丹牌電視機等信息。就算是查找“植物”&“牡丹”,這兩個名詞也是用于多種不同科、屬植物的別名,如野牡丹科植物、毛茛科-芍藥屬-牡丹組植物,或者是一種名為“緋牡丹”的仙人掌科多漿植物,還有菊花品種“綠牡丹”等。這時,可以利用本體來分析用戶檢索詞匯和信息資源語義類型以及二者的語義匹配程度。在分析用戶檢索詞的語義時,可以直接向用戶提供輸入詞匯的語義類型或語義關系,讓用戶通過選擇加以明確。也可以利用用戶模式、用戶檢索式和用戶所選擇的信息資源的詞匯構成等,根據概念關系來判斷具體檢索詞的語義。[1,2]
4.4 支持標準文獻知識關聯
基于本體的語料庫(或稱知識庫)能夠表示信息內容與知識組織體系之間的鏈接。可以將本體知識庫與信息系統進行鏈接,從而使用戶在使用信息的過程中,更加便捷地利用本體來理解具體的概念(知識對象)并鏈接相關概念(知識對象)和相關資源。鏈接方式可以是靜態的(即有關鏈接事先嵌入到信息單元中,不能進行修改),也可以是動態的(即在需要時,由系統析取詞匯和鏈接相應的本體)。這類應用一般多用于專業領域,所以進行語義分析和選擇本體的工作都相對明確和簡潔。
[1]張曉林.走向知識服務——21世紀中國學術信息服務的挑戰與發展[M].成都:四川大學出版社.2001:22-50.
[2]李景.本體理論在文獻檢索系統中的應用研究[M].北京:北京圖書館出版社,2005:99-122.
猜你喜歡
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
電子制作(2018年18期)2018-11-14 01:48:06
現代語文(2016年21期)2016-05-25 13:13:44
專用汽車(2016年4期)2016-03-01 04:13:43
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
