GPU在眼科FD-OCT系統實時圖像顯示及數據處理中的應用
2013-12-05 09:38:06劉巧艷李躍杰徐秋晶趙金城王立偉高用賀
中國醫療器械雜志 2013年1期
【作 者】劉巧艷,李躍杰,徐秋晶,趙金城,王立偉,高用賀
1 北京協和醫學院,北京市,100730
2 中國醫學科學院生物醫學工程研究所,天津市,300192
3 天津市眼科醫學設備技術工程中心,天津市,300384
0 引言
光學相干層析成像技術(Optical Coherence Tomography),自上世紀90年代被成功用于眼科疾病診斷[1]后,得到了迅速發展:由時域OCT階段發展到頻域OCT階段[2];由組織結構成像向組織功能成像發展[3-4];由眼科診斷拓展到心血管、皮膚、口腔、組織工程等領域中的應用[5-6]。
隨著超高速CMOS線陣掃描相機的發展,頻域OCT光譜譜線轉換及線采樣率已經可以達到300 k線/s[7],為臨床OCT系統實時成像提供了前提。目前影響眼科OCT系統實時成像的技術瓶頸是需要先將采樣數據進行頻譜域空間(λ空間)到波數空間(K空間)變換,進行插值變換和FFT變換,然后再將變換后的數據進行2D或3D成像。由于成像的數據量很大,特別是進行C模式掃描成像(如眼底視網膜en-face成像模式)時,需要先將獲得的3D圖像數據進行處理后,再將得到的數據成像。因此,如何提高數據處理的速度,成為眼科OCT系統實現實時成像的關鍵。
為了克服眼科OCT系統實時成像的技術瓶頸,近年來研究人員進行了大量研究,并提出了一些相關的解決方法。有研究人員將多核CPU引入到OCT系統進行采樣數據的并行處理,對于1024個采樣點模式OCT系統,非均勻K空間數據處理的速度可達到80 k線/s[8],均勻K空間數據的處理速度可達到207 k線/s[9]。也有研究人員通過在原有系統中增加DSPs[10]或者FPGAs[11]硬件模塊,加快實現數據處理過程。隨著圖形處理單元(GPU)技術的發展,其運算能力和可編程性得到大幅度提高,它除了在傳統的圖像處理領域應用繼續保持優勢外,作為通用的并行計算處理器已被廣泛用于科學計算、工程、金融以及其他領域中。目前,有研究人員將GPU引入到OCT系統中,利用它強大的并行計算能力來加速采樣數據處理過程,解決OCT系統實時成像的技術瓶頸。Kang Zhang和Jin U.Kang將GPU引入到OCT系統中,在專業圖像工作站平臺上采用線性插值算法,在1024個采樣點模式下數據處理速度達到680 k線/s,2048個采樣點模式下數據處理速度可達到320 k線/s,達到了3D實時成像對于處理速度的要求[12]。現階段將GPU應用于OCT系統還處于實驗室研究階段,為獲得更高處理速度,往往需要配置高性能的專用圖像工作站(配置多核處理器)和GPU,硬件成本較高。
本課題在不改變實驗室現有硬件平臺的條件下,把低成本GPU引入到我們正在開發應用的眼科OCT儀器中,實現儀器性能的大幅度提高,解決眼科OCT系統實時成像的問題。
1 系統組成和工作原理
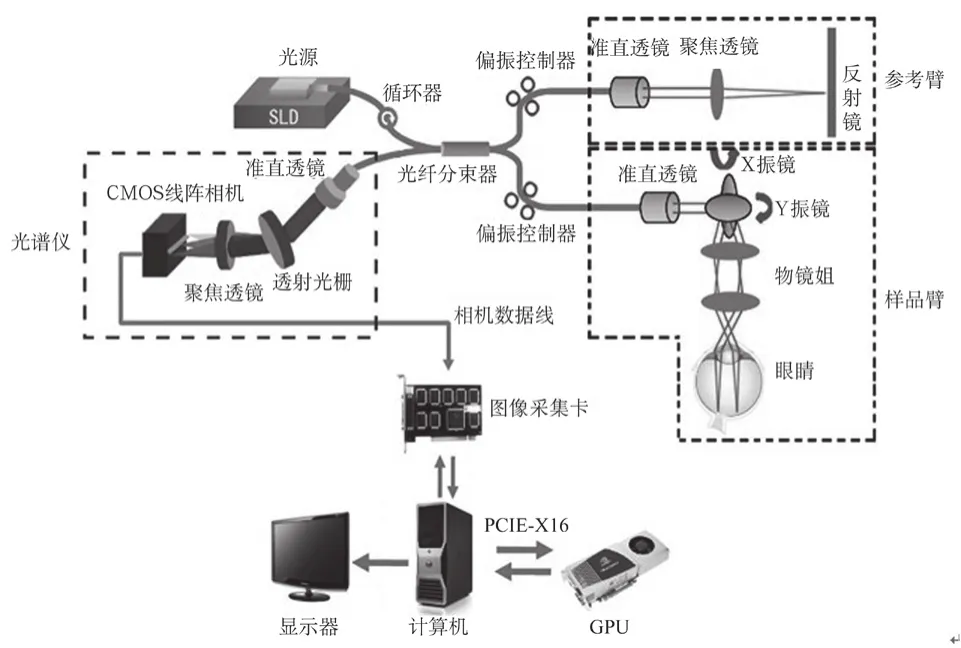
圖1 FD-OCT成像系統組成Fig.1 FD-OCT imaging system configuration
1.1 系統組成
本系統組成如圖1所示,主要包括眼科OCT信號采集系統和信號處理系統兩大部分。其中眼科OCT信號采集系統采用寬帶超亮發光二極管(SLD)(λ0=840 nm,△λ= 50 nm)作為系統光源,以2048像素CMOS線陣相機(采樣速率為70 k線/s)作為光譜儀的檢測器。信號處理系統由計算機和GPU組成。計算機CPU為 Intel Celeron Dual-Core E3400 @ 2.60 GHz,2 G內存;GPU采用 NVIDIA 公司的GeForce GTX 460顯卡(336個流處理器,1 GB顯存)。
1.2 系統工作原理
光源發出的光經過50:50的光纖分束器后,被均勻分成兩束光,分別進入OCT系統的參考臂和樣品臂。從樣品臂反射回來的信號光和從參考臂返回的參考光再次經過光纖分束器匯合后發生干涉。包含樣品不同深度信息的干涉信號光譜,經光譜儀的CMOS線陣掃描相機采集,并通過相機數據線傳輸到計算機,由計算機內的圖像采集卡對干涉信號光譜進行A/D轉換,并將轉換結果作為采樣數據存入到計算機內存中。將采樣數據通過PCIE×16總線傳輸到GPU顯存,借助GPU強大的并行數據處理能力進行數據處理,并將處理好的結果數據送回計算機進行圖像顯示。顯示的圖像包含了檢測樣品不同深度的結構信息。
2 基于GPU加速技術的數據處理流程
2.1 CUDA架構
CUDA(Compute Unified Device Architecture)是一種由NVIDIA公司推出的通用并行計算架構,該架構使GPU能夠解決復雜的計算問題。在CUDA架構下,開發人員可以通過CUDA C語言(CUDA C語言是對標準C語言的一種簡單擴展)對GPU編程[13]。
CUDA架構中,CPU作為主機(Host),GPU作為協處理器或者設備(Device)。在一個系統中可以存在一個主機和多個設備。 CPU 主要負責進行邏輯性強的事物處理和串行計算,GPU 則專注于執行高度線程化的并行處理任務。CPU 、GPU 各自擁有相互獨立的存儲器地址空間:主機端的內存和設備端的顯存;在CUDA程序中,將運行在GPU上一個可以被并行執行的步驟稱為kernel(內核函數)。

圖2 CPU-GPU系統數據處理流程圖Fig.2 Signal processing flow chart of CPU-GPU hybrid system architecture
2.2 數據處理過程
本系統的數據處理過程如圖2所示,其中實箭頭所指方向代表數據在不同設備間的流動方向,空箭頭所指方向代表數據在GPU內部的流動方向。系統數據處理過程包括對采樣數據進行預處理、頻譜域空間(λ空間)到波數空間(K空間)變換、插值變換、FFT變換和POST-FFT變換。
在頻域OCT系統中,采樣數據是通過對OCT的光路系統掃描由相機采集到的,掃描一次得到一列數據(一個A-SCAN)。處理時是一列一列數據進行處理的。針對每列數據彼此相互獨立、可以并行處理的特點,利用CUDA架構將OCT系統整個數據處理過程改寫成適合在GPU上執行的kernel函數,大大提高了數據處理速度,從而達到系統實時成像的要求。
2.3 程序設計
首先確定系統數據處理過程中的串行部分和并行部分,選擇合適的算法,并按照算法確定數據和任務的劃分方式,將每個需要并行實現的步驟映射為一個滿足CUDA兩層并行模型的內核函數。其中頻譜域空間(λ空間)到波數空間(K空間)變換模塊在主程序中執行;數據預處理、插值運算、POST-FFT運算需要重新改寫成適合在GPU上執行的kernel函數;FFT運算部分采用CUDA自帶的CUFFT庫函數來進行計算,CUDA4.1版本目前已經支持FFT雙精度運算。整個程序設計如下:
(1)給采樣數據和計算過程中的各個變量分配空間,包括內存空間和顯存空間,在Host端CPU程序中,準備好計算要用到的數據,將數據從主機內存傳輸到顯存中。
(2)數據預處理包括數據類型轉換和去噪運算。去噪運算是將每一列數據組成的數組(一個A-SCAN)都減去一列同大小的噪聲數組。
(3)插值運算實現了在進行FFT變換之前,采樣數據K空間分布的均勻化。系統最常用的插值算法包括最鄰近插值算法、線性插值算法和三次樣條插值算法。
(4)利用CUDA自帶的CUFFT庫函數對插值運算結果進行FFT變換。
(5)POST-FFT運算包括對FFT運算結果取模、取對數并進行歸一化。POST-FFT運算結果存儲在體積數組中。
(6)根據不同成像平面的需要,抽取體積數組數據作為GPU結果數據。
(7)將結果數據從顯存傳輸到主機內存中。
2.4 優化分析
在用CUDA對GPU上的kernel函數進行改寫時,采用了一些優化方法:
(1)為了使內存和顯存之間的數據傳輸速度更快,在分配主機端內存的時候采用了pinned memory。
(2)使用流運算來隱藏主機端和設備端數據通信的時間。
(3)合理利用讀取速度更快的shared memory來存放計算過程中的中間變量。
(4)將已經計算好的在插值運算過程中值保持不變的采樣數據的等間隔和非等間隔橫坐標值存放在常數寄存器里面。
(5)根據系統資源進行grid和block維度設計。
(6)使用CUDA profiler對CUDA程序進行性能測試,對耗時較長的模塊進行優化。
3 實驗結果
本系統采用Microsoft Visual Studio2010中集成CUDA Toolkit 32 bit 4.1、CUDA SDK 32 bit 4.1和Nvidia Driver for Windows732 bit為開發環境,對采樣數據進行B掃描模式和C掃描模式成像。
3.1 B掃描模式成像
B掃描模式成像圖像能提供視網膜斷層結構,能清晰地顯示視網膜各層細微結構及病理改變,并作出定性或定量分析,目前已成為視網膜疾病和青光眼強有力的診斷工具[14]。
我們采用100幀共計195 MB數據(每幀數據大小為500線×2048 像素/線×2 字節/像素)進行B掃描模式成像。分別采用線性插值算法和三次樣條插值算法,利用CUDA提供的計時函數分別對CPU模式和CPU-GPU模式下系統單幀B掃描模式圖像成像時間進行計時(計算100幀圖像成像時間取平均),實驗結果如表1所示。 從表1可知,采用GPU+CPU模式執行成像數據處理的速度較CPU模式執行同樣數據處理的速度提高超過一個數量級,其中采用線性插值算法速度提高了60倍,采用三次樣條插值算法速度提高了35倍。實驗成像效果圖如圖3所示,其中(a)為采用線性插值算法在CPU模式下系統成像圖像;(b)為采用線性插值算法在CPU+GPU模式下系統成像圖像;(c)為采用三次樣條插值算法在CPU模式下系統成像圖像;(d)為采用三次樣條插值算法在CPU+GPU模式下系統成像圖像。由圖3可知,采用相同的插值算法,在CPU模式和CPU-GPU模式下系統成像圖像質量無差異,采用三次樣條插值算法成像圖像質量比采用線性插值算法成像圖像質量要好。
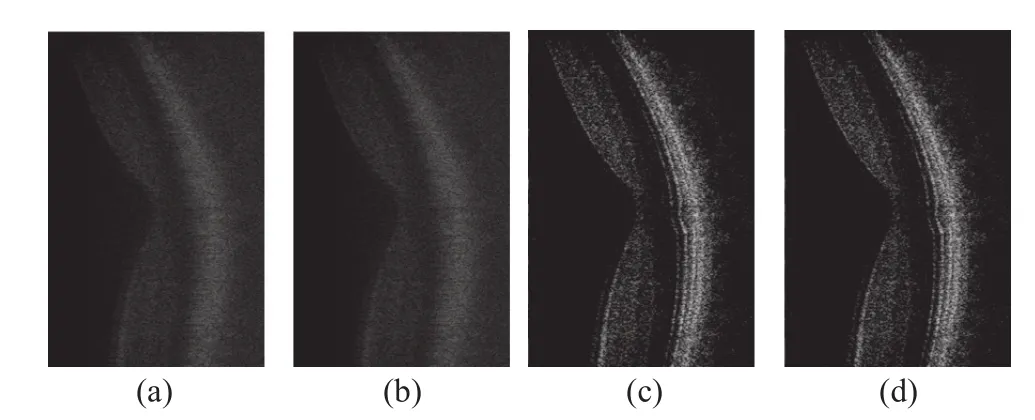
圖3 視網膜B掃描成像圖像Fig.3 B-scan imaging images of the retina
插值運算是系統數據處理過程中計算量最大、耗時最長的一個環節。插值算法的選取不僅影響系統加速比,也影響系統成像速度和成像圖像質量。采用線性插值算法,成像速度快,成像圖像質量差;采用三次樣條算法,成像速度慢、成像圖像質量好。

表1 CPU和GPU 成像速度對比Tab.1 Comparison of CPU and GPU imaging speed
3.2 C掃描模式成像
C掃描模式成像圖像能直觀地顯示眼底視網膜血管和黃斑等眼底組織的結構信息,臨床上可用于診斷眼底病變,如黃斑病變[15]、眼底神經組織結構變化等,可用于對視網膜下新生血管的深度和層次進行準確定位[16]。
進行C掃描模式成像時,我們先將采樣數據進行B掃描模式處理,并將處理后的結果數據組織成3D紋理數組存放在顯存之中。根據不同的需要,對3D數組進行切片提取顯示en-face單層圖像,或者通過多切片疊加取平均顯示眼底組織結構信息。
我們采用的3D數據塊為480幀共計204 MB數據(每幀數據大小為249線×896 像素/線×2 字節/像素)進行C掃描模式成像。3D數據塊平均成像速度為1.8 s,能快速實現視網膜en-face單層切片成像或en-face多切片疊加平均成像。成像效果如圖4所示,其中圖(a)~(c)分別顯示了視網膜en-face單層切片圖像;沿縱軸方向看,(b)切片比圖4(a)切片深約30 μm,(c)切片比(b)切片深約30 μm。圖4(a)~(c)清晰地顯示了視網膜血管、微血管、黃斑等眼底組織細微結構。視網膜en-face單層切片成像的軸向分辨率可達到5 μm。與眼底相機只能對眼底復合結構成像相比,視網膜en-face單層切片成像可以對眼底視網膜下的細微組織的深度和層次進行準確定位。圖4(d)~(f)分別顯示了視網膜11個en-face 切片疊加后再取平均的成像圖像。沿縱軸方向看,圖4(d)~(f)、分別以圖4(a)~(c)的切片為中心,前后各取5切片疊加后取平均所成圖像。從圖4(d)~(f)能清晰地觀察到視網膜血管、微血管、黃斑等眼底組織細微結構,與圖4(a)~(c)單切片成像圖相比,圖4(d)~(f)包含了更多的復合結構信息。
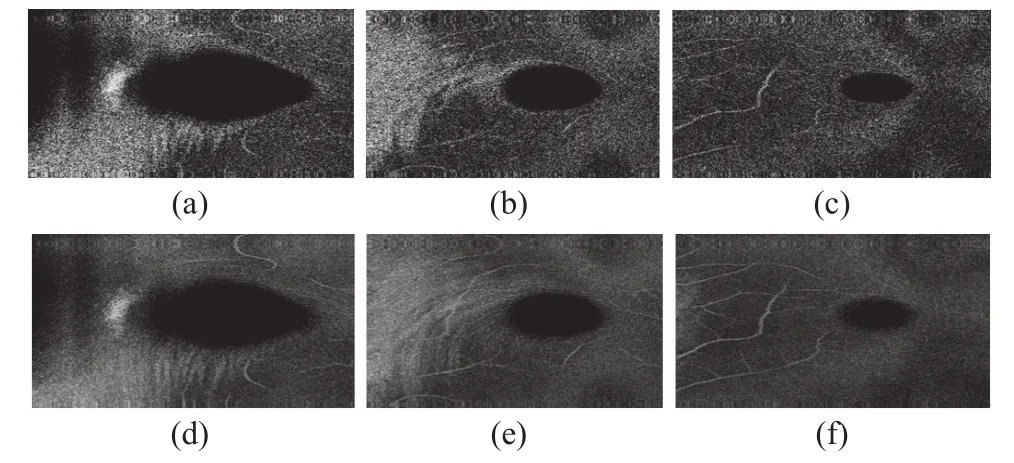
圖4 視網膜en-face成像圖像Fig.4 En-face imaging images of the retina
實驗結果表明:在成像圖像質量不變的前提下,在眼科OCT系統中,采用GPU+CPU模式實現成像數據處理的速度,較傳統的基于CPU平臺的串行計算和成像模式執行同樣數據處理的速度提高超過一個數量級。
4 結語
本文利用實驗室現有標準OCT系統平臺,在未增加硬件的基礎上,利用計算機通用顯卡GPU,并將基于GPU的統一計算設備架構(CUDA)引入到眼科OCT系統成像中的數據處理過程,借助GPU強大的并行數據處理能力和浮點計算能力,用CUDA對OCT系統數據處理過程進行改寫,使得眼科OCT系統的成像速度較基于CPU平臺處理成像速度提高了數十倍,達到了臨床2D實時成像的要求,為眼科3D實時成像打下了基礎。
[1]D.Huang,E.A.Swanson,C.P.Lin,et al.Optical coherence tomography[J].Science,1991,254(5035): 1178-1181.
[2]R.Leitgeb, C.K.Hitzenberger, A.F.Fercher.Performance of fourier domain vs.time domain optical coherence tomography[J].Opt Express,2003,11(8): 889–894.
[3]Ruikang,K.Wang.In vivo structural and flow imaging: US,US20100027857A1[P],2010-2-4.
[4]B.Cense,T.C.Chen,B.H.Park,et al.Thickness and birefringence of healthy retinal nerve fiber layer tissue measure measured with polarization-sensitive optical coherence tomography[J].Invest Ophth Vis Sci,2004,45(12): 2606-2612.
[5]N.D.Gladkova,G.A.Petrova,N.K.Nikulin,et al.In vivo optical coherence tomography imaging of human skin: norm and pathology[J].Skin Res Technol,2000,6(1): 6-16.
[6]L.Vabre,A.Dubois,A.C.Boccara.Thermal-light full-field optical coherence tomography[J].Opt Lett,2002,27(7): 530-532.
[7]B.Potsaid,I.Gorczynska,V.J.Srinivasan,et al.Ultrahigh speed spectral/Fourier domain OCT ophthalmic imaging at 70,000 to 312,500 axial scans per second[J].Opt Lett,2008,16(19): 15149–15169.
[8]G.Liu,J.Zhang,L.Yu,et al.Real-time polarization-sensitive optical coherence tomography data processing with parallel computing[J]. Appl Opt,2009,48(32): 6365–6370.
[9]J.Probst,P.Koch,G.Huttmann.Real-time 3D rendering of optical coherence tomography volumetric data[C].Proc SPIE,2009,7372,73720Q.
[10]A.W.Schaefer,J.J.Reynolds,D.L.Marks,et al.Real-time digitalsignal processing-based optical coherence tomography and Doppler optical coherence tomography[J].IEEE Trans Biomed Eng,2004,54: 186-190.
[11]T.E.Ustun,N.V.Iftimia,R.D.Ferguson,et al.Real-time processing for Fourier domain optical coherence tomography using a field programmable gate array[J].Rev Sci Instrum,2008,79:114301-114310.
[12]Kang Zhang,Jin U.Kang,Real-time 4D signal processing and visualization using graphics processing unit on a regular nonlinear-k Fourier-domain OCT system[J], Opt Express,2010,18(11): 11772-11784.
[13]Jason Sanders,Edward Kandrot.GPU高性能編程CUDA實戰[M].北京: 機械工業出版社,2011
[14]J.S.Schuman,M.R.Hee,C.A.Puliafito.et al.Quantification of nerve fiber layer thickness in normal and glaucomatous eyes using optical coherence tomography[J].Arch Ophth,1995,113(5): 586-596.
[15]M.Altaweel,M.Ip.Macular hole: improved understanding of pathogenesis,staging,and management based on optical coherence tomography[J].Semin Ophth,2003,18(2): 58-66.
[16]紀淑興,張軍軍,唐健,等.中心性滲出性脈絡膜視網膜病變的光學相干斷層掃描圖像[J].中華眼底病雜志,2002,18(2): 121-124.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
當代化工研究(2016年9期)2016-03-20 16:22:13
西華師范大學學報(自然科學版)(2015年3期)2015-02-27 15:31:22
