一種基于語義相關度的特征選擇方法
2013-09-19 09:22:26劉洋
網絡安全技術與應用 2013年4期
劉洋
桂林理工大學信息科學與工程學院 廣西 541000
0 引言
隨著網絡技術的迅猛發展,網絡上的信息量呈指數級增加,相關信息處理技術現已成為人們獲取有用信息時至關重要的工具,文本分類(Text Categorization)作為處理和組織大量文本數據的關鍵技術應運而生。因此,研究文本分類成為自然語言處理和數據挖掘領域中一項具有重要應用和理論價值的課題。文本分類是在預定義的分類體系下,根據文本的特征,將給定文本與一個或者多個類別相關聯的過程。文本自動分類問題的最大特點和困難之一是特征空間的高維性和文檔表示向量的稀疏性。尋求一種有效的特征提取方法,降低特征空間的維數,提高分類的效率和精度,成為文本自動分類中需要首先面對的重要問題。
特征選擇(Feature Selection,FC)作為文本分類關鍵一步,它的好壞將直接影響文本分類的準確率,特征空間的降維操作成為了提高文本分類準確率和效率的關鍵。好的降維不僅可以提高機器學習任務的效率,而且還能改善分類性能和節省大量的存儲空間。在進行維數約簡時,實際是將高維空間映射到一個小得多的低維空間,同時希望該低維空間一方面能盡可能多地保留原始信息中的重要信息,另一方面又能有效地把原始信息中的噪音、冗余數據過濾掉。本文提出一種基于《同義詞詞林》的詞語相關度的特征選擇方法,通過計算詞語之間的語義相關度,進行特征取舍,降低特征空間的高維性,并有效減少噪聲,得出最優特征空間,從而提高了分類精度。
1 特征選擇方法
傳統的特征選擇相關研究主要集中在降維的模型算法與比較,特征集與分類效果的關系,以及降維的幅度3個方面。在文本分類中,常用的特征選擇方法有基于閾值的統計方法,如文檔頻率方法(DF),信息增益方法(IG),互信息方法(MI),CHI方法,期望交叉熵,文本證據權,優勢率,基于詞頻覆蓋度的特征選擇方法等,以及由原始的低級特征(比如詞)經過某種變換構建正交空間中的新特征的方法,如主分量分析的方法等。基于閾值的統計方法具有計算復雜度低,速度快的優點,尤其適合做文本分類中的特征選擇。關于文本分類中的特征選擇問題, 比較有代表性的是Yang Yi ming和 Dunja Mladenic的工作(圖1)。
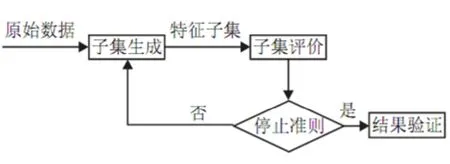
圖1 特征選擇示意圖
(1) 文檔頻率
詞條的文檔頻率(Document Frequency)是指在訓練語料中出現該詞條的文檔數。采用DF作為特征抽取基于如下基本假設:DF 值低于某個閾值的詞條是低頻詞,它們不含或含有較少的類別信息。將這樣的詞條從原始特征空間中移除,不但能夠降低特征空間的維數,而且還有可能提高分類的精度。文檔頻率是最簡單的特征抽取技術,由于其具有相對于訓練語料規模的線性計算復雜度,它能夠容易地被用于大規模語料統計。
(2) 信息增益
信息增益(Information Gain)在機器學習領域被廣泛使用對于詞條t和文檔C類,IG考察C中出現和不出現t的文檔頻數來衡量t對于C的信息增益。我們采用如下的定義式:
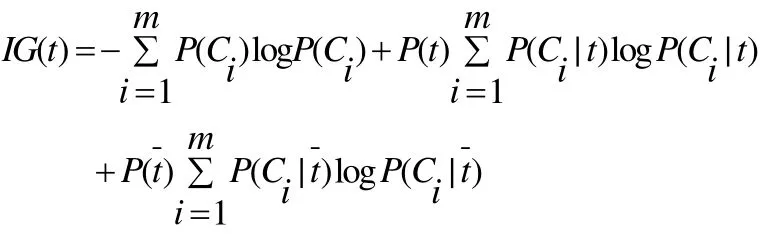
其中表示類文檔在語料中出現的概率,P(t)表示語料中包含詞條 t的文檔的概率,P(Ci|t)表示文檔包含詞條t時屬于Ci類的條件概率,P(t)表示語料中不包含詞條 t的文檔的概率,P(Ci|t)表示文檔不包含詞條t時屬于Ci的條件概率,m表示類別數。
(3) 卡方(CHI)統計
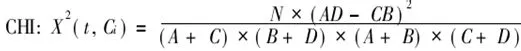
(4) 互信息
互信息(Mutual Information)在統計語言模型中被廣泛采用。如果用A 表示包含詞條t且屬于類別C的文檔頻數,B為包含t 但是不屬于C的文檔頻數,C表示屬于C但是不包含t的文檔頻數,N表示語料中文檔總數,t和C的互信息可由下式計算:
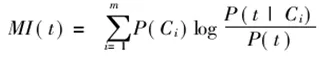
2 基于詞匯相關度計算的特征選擇
2.1 《同義詞詞林》介紹
《同義詞詞林》是梅家駒等人于1983年編纂而成,這本詞典中不僅包括了一個詞語的同義詞,也包含了一定數量的同類詞,即廣義的相關詞。由于《同義詞詞林》著作時間較為久遠,且之后沒有更新,所以哈爾濱工業大學信息檢索實驗室利用眾多詞語相關資源,完成了一部具有漢語大詞表的《哈工大信息檢索研究室同義詞詞林擴展版》。《同義詞詞林擴展版》收錄詞語近7萬條,全部按意義進行編排,是一部同義類詞典。
《同義詞詞林》按照樹狀的層次結構把所有收錄的詞條組織到一起,把詞匯分成大、中、小 3類,《同義詞詞林》共提供了5層編碼, 第1級用大寫英文字母表示;第2級用小寫英文字母表示;第3級用二位十進制整數表示;第4級用大寫英文字母表示;第5級用二位十進制整數表示。例如:“Ae07C01=漁民 漁翁 漁家 漁夫 漁父 打魚郎”,“Ae07C01=”是編碼,“漁民 漁翁 漁家 漁夫 漁父 打魚郎”是該類的詞語。
2.2 詞匯相關度計算
詞匯相關性計算在很多領域中都有廣泛應用,例如信息檢索、信息抽取、文本分類等等。詞匯相關性計算的兩種基本方法是基于世界知識(Ontology)或某種分類體系(Taxonomy)的方法和基于語料庫(Corpus-Based)上下文統計的方法。這兩種方法各有優缺點。但從某種意義上來說,專家所劃分的詞匯知識概念體系應該具有權威性,依賴這樣的概念體系進行詞匯相關性計算也更加合理。本文采用基于《同義詞詞林》的詞匯相關性計算是一種基于世界知識的方法。
2.3 改進的特征選擇方法
本文根據文獻5中算法指導,通過查找計算兩兩特征詞之間的語義關系(上下義位關系、整體-部分關系、反義關系、包含關系),從而確定特征向量的選擇。但是,針對具有同義關系的詞,我們就要進行合并處理,因為過多同義詞不但不能提高語義特性,反而會增加空間維數。根據《同義詞詞林》組織編排特點,基于《同義詞詞林》的語義相關度計算的主要思想是:基于《同義詞詞林》結構利用詞語中義項的編號根據兩個義項的語義距離,計算出義項相關度。
具體步驟如下:
(1) 經過分詞、詞干處理一系列文本預處理我們得到最初文本特征空間,對最初的在文本預處理得到的文本特征集的基礎上,對于一篇文本而言,首先讀取特征詞,通過查詢《同義詞詞林》,得到其各自對應分類結構樹,對于分類結構樹,逐一進行處理。
(2) 計算特征詞語義相關度。首先判斷在同義詞林中作為葉子節點的兩個義項在哪一層分支,即兩個義項的編號在哪一層不同。相同則乘1,否則在分支層乘以相應的系數,然后乘以調節參數cos(n ×)其中n是分支層的節點總數。詞語所在樹的密度,分支的多少直接影響到義項的相似度,密度較大的義項相似度的值相比密度小的相似度的值精確。再乘以一個控制參數(n-k+1)/n,其中n是分支層的節點總數,k是兩個分支間的距離。若兩個義項的相似度用sim表示。公式(1)、(2)分別對應義項是不是在同一棵樹上,a、b、c、d、e對應各自層數,分別取值為0.65,0.8,0.9,0.5,0.1。
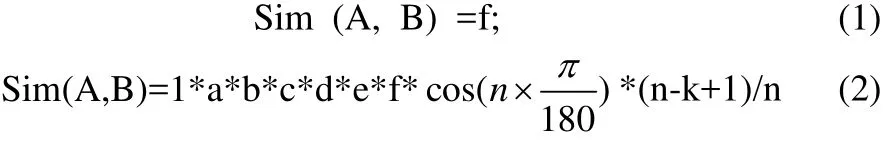
(3) 候選特征詞依據修正后的權重排序,選取前N個特征詞形成特征向量空間。
(4) 對詞形特征向量空間模型的規范化處理,采用一范數規范化處理方式進行歸一化處理,經過最后一步規范化處理后即得到了最終的向量空間模型。
3 實驗結果
我們在Weka平臺上,用譚松波等收集的中文語料集作為語料庫進行實驗。采用KNN分類器本文提出的基于《同義詞詞林》的文本特征選擇方法的效果進行評估。試驗中采用的評價參數如下:
分類準確率= 該分類的正確文本數/該分類的實際文本數。

表1 特征提取

表2 分類準確率提高
表1顯示出使用本方法進行特征提取時,最終的特征向量個數大幅度減少;從表2能看出分類準確率有明顯的提高。
4 結論
在《同義詞詞林》基礎上,我們進行了基于語義相關度的文本特征選擇的研究。與傳統的特征選擇方法進行了實驗比較, 實驗結果表明該方法有效的降低了特征空間的高維稀疏性和減少噪聲,提高了分類精度,體現出更好的分類效果。
[1]宗成慶.統計自然語言處理[M].北京:清華大學.2008.
[2]代六玲,黃河燕,陳肇雄.中文文本分類中特征抽取方法的比較研究[J].中文信息學報.2003.
[3]SU Jin-Shu,ZHANG Bo-Feng,XU Xin..Advances in Machine Learning Based Text Categorization[J] Journal of Software, Vol.17, No.9, September 2006.
[4]周茜,趙名生.中文文本分類中的特征選擇研究[J].中文信息學報.2003.
[5]田久樂,趙蔚.基于同義詞詞林的詞語相似度計算方法[J].吉林大學學報.2010.
[6]劉群,李素建.基于《知網》的詞匯語義相似度算[J]. Computational Linguistics and Chinese Language Processing.2002.
[7]http://sourceforge.net/projects/weak.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
