改進(jìn)數(shù)據(jù)挖掘算法在入侵檢測(cè)系統(tǒng)中的應(yīng)用
2013-08-30 10:00:12趙艷君魏明軍
計(jì)算機(jī)工程與應(yīng)用 2013年18期
趙艷君,魏明軍
ZHAOYanjun1,WEIMingjun2
1.河北聯(lián)合大學(xué) 理學(xué)院,河北 唐山 063009
2.河北聯(lián)合大學(xué) 信息學(xué)院,河北 唐山 063009
1.College of Science,Hebei United University,Tangshan,Hebei 063009,China
2.College of Information Engineering,Hebei United University,Tangshan,Hebei 063009,China
1 引言
隨著網(wǎng)絡(luò)安全問(wèn)題在人們生活中的重要性不斷增強(qiáng),作為新一代網(wǎng)絡(luò)安全技術(shù)的入侵檢測(cè)技術(shù)在網(wǎng)絡(luò)安全中也發(fā)揮著越來(lái)越重要的角色。與此同時(shí),現(xiàn)有入侵檢測(cè)系統(tǒng)存在問(wèn)題日益突出。現(xiàn)有入侵檢測(cè)大多采用模式匹配的方式檢測(cè)攻擊,需要將待檢測(cè)的數(shù)據(jù)包與規(guī)則庫(kù)中的數(shù)據(jù)一一匹配,對(duì)已知攻擊行為檢測(cè)率較高,誤報(bào)率較低,但對(duì)于已知攻擊的變種或未知攻擊卻不能檢測(cè)出來(lái)。而且,模式匹配需要事先建立一個(gè)已知攻擊的檢測(cè)規(guī)則和模式庫(kù),并需要安全領(lǐng)域?qū)<也粩噙M(jìn)行規(guī)則庫(kù)的更新和維護(hù),否則就會(huì)造成系統(tǒng)的漏報(bào)率升高。因此,提高現(xiàn)有入侵檢測(cè)系統(tǒng)的檢測(cè)率、降低漏報(bào)率具有非常重要的現(xiàn)實(shí)意義。
依據(jù)檢測(cè)所使用方法的不同,可以將傳統(tǒng)入侵檢測(cè)模型分為基于誤用的入侵檢測(cè)模型和基于異常的入侵檢測(cè)模型兩種[1-2]。基于誤用的入侵檢測(cè)模型需要建立一個(gè)已知攻擊的規(guī)則庫(kù),并需要不斷對(duì)知識(shí)庫(kù)進(jìn)行更新,才能跟蹤攻擊技術(shù)的發(fā)展,及時(shí)將新的攻擊檢測(cè)出來(lái)。因此,誤用檢測(cè)模型檢測(cè)效果的好壞很大程度上依賴于模式庫(kù)的及時(shí)更新。由此,可以看出,誤用檢測(cè)只能對(duì)已經(jīng)發(fā)現(xiàn)的攻擊進(jìn)行防護(hù),它不具備感知未知攻擊的能力。而基于異常的入侵檢測(cè)模型是根據(jù)統(tǒng)計(jì)數(shù)據(jù),給正常行為建立一個(gè)模式庫(kù),一旦發(fā)現(xiàn)某種行為超出了正常行為的范圍,就會(huì)將其當(dāng)做入侵,做出相應(yīng)反應(yīng)[3-5]。此種檢測(cè)模型的好處是對(duì)于未知攻擊有著天生的良好感知能力。但是,由于系統(tǒng)的活動(dòng)行為是在不斷變化的,因此,需要對(duì)于正常行為模式庫(kù)也需要不斷調(diào)整,難于計(jì)算。對(duì)比這兩種檢測(cè)模型可發(fā)現(xiàn),異常模型難于進(jìn)行定量分析,不易實(shí)現(xiàn);而誤用模型會(huì)按照事先定義好的規(guī)則,將待檢測(cè)數(shù)據(jù)與規(guī)則庫(kù)中的數(shù)據(jù)做模式匹配,實(shí)現(xiàn)起來(lái)相對(duì)簡(jiǎn)單。因此,目前大多數(shù)的入侵檢測(cè)系統(tǒng)采用的是基于誤用的入侵檢測(cè)模型,而基于異常檢測(cè)的入侵檢測(cè)系統(tǒng)和二者結(jié)合的還比較少,多處于研究階段。
為了改善現(xiàn)有入侵檢測(cè)系統(tǒng)的性能,本文將誤用檢測(cè)與異常檢測(cè)結(jié)合起來(lái),構(gòu)建一個(gè)基于誤用檢測(cè)和異常檢測(cè)相結(jié)合的混合入侵檢測(cè)模型。數(shù)據(jù)挖掘的最大特點(diǎn)在于它能夠從繁雜的數(shù)據(jù)中發(fā)現(xiàn)人們未知的知識(shí)和規(guī)律,并且具有分析過(guò)程自動(dòng)化、快速等優(yōu)點(diǎn)。本模型中采用數(shù)據(jù)挖掘技術(shù)[6]實(shí)現(xiàn)以上提出的對(duì)入侵檢測(cè)系統(tǒng)的改進(jìn)。利用數(shù)據(jù)挖掘中的聚類分析算法對(duì)網(wǎng)絡(luò)數(shù)據(jù)進(jìn)行處理,建立正常行為類,以排除大部分正常數(shù)據(jù)。利用關(guān)聯(lián)規(guī)則算法實(shí)現(xiàn)規(guī)則集的自動(dòng)擴(kuò)充機(jī)制。最后使用實(shí)驗(yàn)數(shù)據(jù)對(duì)兩個(gè)改進(jìn)算法進(jìn)行了功能驗(yàn)證。
2 構(gòu)建基于改進(jìn)數(shù)據(jù)挖掘算法的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)模型
2.1 系統(tǒng)組成
基于以上設(shè)計(jì)思路,本文構(gòu)建了一個(gè)基于改進(jìn)數(shù)據(jù)挖掘算法的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)模型,如圖1所示。
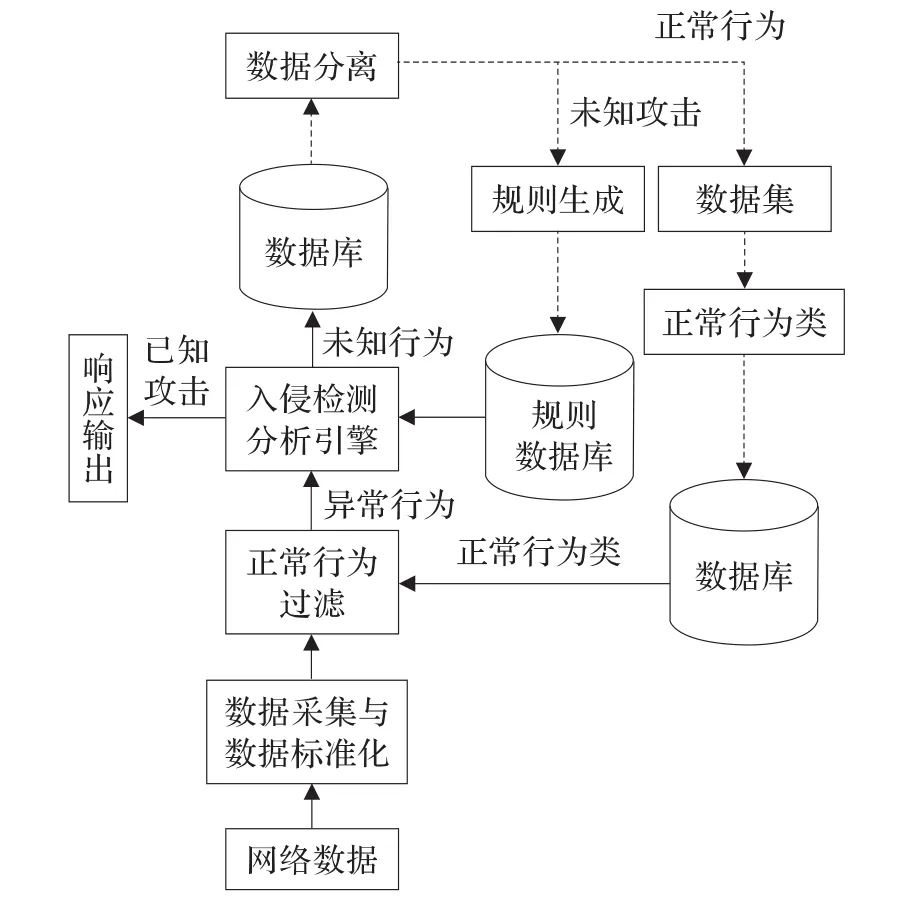
圖1 基于數(shù)據(jù)挖掘的入侵檢測(cè)系統(tǒng)模型
圖1 中,實(shí)線表示實(shí)時(shí)部分,虛線表示非實(shí)時(shí)的部分。
模塊的基本功能與設(shè)計(jì)說(shuō)明如下:
(1)數(shù)據(jù)采集與數(shù)據(jù)標(biāo)準(zhǔn)化模塊:該模塊主要負(fù)責(zé)采集網(wǎng)絡(luò)數(shù)據(jù)并將數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理,為攻擊檢測(cè)做好準(zhǔn)備。
(2)正常行為類模塊:該模塊的作用是將收集的數(shù)據(jù)作為訓(xùn)練數(shù)據(jù),通過(guò)采用改進(jìn)的聚類分析算法K-means,把訓(xùn)練數(shù)據(jù)歸為幾類,提取出形成的正常行為類的特征作為類的標(biāo)志,形成正常行為類模式,并將其做為正常行為過(guò)濾模塊的依據(jù)。
(3)正常行為過(guò)濾模塊:該模塊作為網(wǎng)絡(luò)數(shù)據(jù)在進(jìn)入檢測(cè)分析引擎前的預(yù)處理程序。它利用正常行為類模塊生成的正常行為類模式,對(duì)即將要進(jìn)入檢測(cè)分析引擎的數(shù)據(jù)包進(jìn)行過(guò)濾,將符合正常行為類的數(shù)據(jù)過(guò)濾出來(lái),這樣可以大大降低分析引擎的工作量。
(4)入侵檢測(cè)分析引擎模塊:該模塊將來(lái)自正常行為過(guò)濾模塊的異常行為進(jìn)行進(jìn)一步分析,主要采取模式匹配的方法與規(guī)則數(shù)據(jù)庫(kù)中的已知攻擊規(guī)則進(jìn)行匹配,若為攻擊則響應(yīng)輸出;若不是,則是未知行為,存入數(shù)據(jù)庫(kù)待下一步處理。
(5)數(shù)據(jù)分離模塊:該模塊處理的數(shù)據(jù)是經(jīng)過(guò)分析引擎處理過(guò)的數(shù)據(jù),這部分?jǐn)?shù)據(jù)中會(huì)包含未知攻擊數(shù)據(jù)和正常數(shù)據(jù),需要將兩部分?jǐn)?shù)據(jù)進(jìn)行分離,將未知攻擊數(shù)據(jù)提供給規(guī)則生成模塊,正常數(shù)據(jù)保存起來(lái),用以更新正常行為類。采用的算法仍然是改進(jìn)的K-means算法。
由于該模塊的功能與正常行為類模塊的實(shí)質(zhì)相同,只是所處理的數(shù)據(jù)源不同,流程及過(guò)程不再重復(fù),只需將數(shù)據(jù)換為日志記錄即可,將正常數(shù)據(jù)保存到數(shù)據(jù)集中,攻擊數(shù)據(jù)傳送給規(guī)則生成模塊。
(6)規(guī)則生成模塊:該模塊采用改進(jìn)的Apriori算法,對(duì)來(lái)自數(shù)據(jù)分離模塊的未知攻擊數(shù)據(jù)進(jìn)行關(guān)聯(lián)規(guī)則挖掘,將發(fā)現(xiàn)的未知入侵行為模式表示成規(guī)則,并將其保存到規(guī)則庫(kù)。
(7)規(guī)則數(shù)據(jù)庫(kù):規(guī)則數(shù)據(jù)庫(kù)用于存放入侵檢測(cè)分析引擎進(jìn)行模式匹配所需要的規(guī)則。
(8)數(shù)據(jù)集:開(kāi)始時(shí)使用的是初始數(shù)據(jù)集KDD CUP1999。
2.2 系統(tǒng)工作流程
以上提出的基于數(shù)據(jù)挖掘的入侵檢測(cè)系統(tǒng)模型的運(yùn)行過(guò)程可以分為以下幾步:
(1)建立正常行為類:①利用基于誤用的入侵檢測(cè)系統(tǒng),如snort來(lái)收集網(wǎng)絡(luò)正常行為數(shù)據(jù)作為前期的訓(xùn)練數(shù)據(jù)。②利用數(shù)據(jù)挖掘中聚類分析算法,對(duì)收集的數(shù)據(jù)進(jìn)行處理,將其聚類成幾類,形成正常行為類,將其存儲(chǔ)到數(shù)據(jù)庫(kù)中。
(2)入侵檢測(cè):①利用網(wǎng)絡(luò)嗅探器收集網(wǎng)絡(luò)數(shù)據(jù)包。②將數(shù)據(jù)包解碼,并將數(shù)據(jù)字段存入相應(yīng)的數(shù)據(jù)結(jié)構(gòu)當(dāng)中。③數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化處理,為正常行為過(guò)濾做準(zhǔn)備。④將數(shù)據(jù)與正常行為類進(jìn)行比較,如果屬于其中的某類,則表明是正常數(shù)據(jù),將其丟掉;如果不是,則將其轉(zhuǎn)交給檢測(cè)引擎進(jìn)行模式匹配,作進(jìn)一步分析。⑤模式匹配,如果成功,則為攻擊,那么相應(yīng)模塊會(huì)做出設(shè)定措施;若不是,則該數(shù)據(jù)中可能包含新攻擊,將數(shù)據(jù)存儲(chǔ)起來(lái)作為產(chǎn)生新規(guī)則的數(shù)據(jù)集。
(3)添加新規(guī)則:利用聚類分析算法對(duì)存儲(chǔ)的數(shù)據(jù)進(jìn)行聚類,排除小部分正常數(shù)據(jù)。然后,利用數(shù)據(jù)挖掘中的關(guān)聯(lián)規(guī)則算法作關(guān)聯(lián)分析,發(fā)現(xiàn)新規(guī)則并將其添加到規(guī)則庫(kù)中。
3 入侵檢測(cè)系統(tǒng)中算法的實(shí)現(xiàn)
基于改進(jìn)數(shù)據(jù)挖掘算法的網(wǎng)絡(luò)入侵檢測(cè)系統(tǒng)中采用的算法是聚類分析算法(K-means)和關(guān)聯(lián)規(guī)則算法(Apriori),并對(duì)兩種算法分別進(jìn)行了改進(jìn)。
3.1 改進(jìn)K-means算法
K-means算法[7-11]是硬聚類算法,是典型的基于聚類準(zhǔn)則函數(shù)的聚類方法的代表,它把每個(gè)數(shù)據(jù)對(duì)象到各個(gè)類中心的某種距離之和作為進(jìn)行優(yōu)化的目標(biāo)函數(shù),同時(shí)采取函數(shù)求極值的方法獲得進(jìn)行迭代運(yùn)算的調(diào)整規(guī)則。該算法的最終目的是根據(jù)輸入的聚類個(gè)數(shù)k,將數(shù)據(jù)對(duì)象劃分為k個(gè)類。
K-means算法思想簡(jiǎn)單、計(jì)算復(fù)雜度小,能夠滿足入侵檢測(cè)對(duì)于實(shí)時(shí)性的要求,實(shí)現(xiàn)起來(lái)比較簡(jiǎn)單。但該算法本身也存在著一些急需解決的問(wèn)題:
(1)無(wú)法自主確定聚類個(gè)數(shù),需要事先輸入確定的k值。在K-means算法開(kāi)始聚類前,它必須要預(yù)先確定聚類的個(gè)數(shù)k,同時(shí)隨機(jī)選擇相同個(gè)數(shù)的數(shù)據(jù)對(duì)象作為初始聚類中心。這樣的話就會(huì)造成劃分的類不是很準(zhǔn)確,而且自主確定聚類個(gè)數(shù)也很困難,有時(shí)還需要結(jié)合相關(guān)領(lǐng)域的先驗(yàn)知識(shí)作為參考。同時(shí),網(wǎng)絡(luò)入侵檢測(cè)的過(guò)程是實(shí)時(shí)的,所以可能沒(méi)有辦法事先知道聚類的個(gè)數(shù)k,這樣也就無(wú)法選擇用做初始聚類中心的k個(gè)數(shù)據(jù)對(duì)象。
(2)通過(guò)K-means算法聚類出來(lái)的類不能確定哪個(gè)類是正常的,哪個(gè)類是異常的。但是在進(jìn)行檢測(cè)的過(guò)程中卻需要通過(guò)正常行為類來(lái)排除正常數(shù)據(jù)包,減輕檢測(cè)引擎的工作量。
針對(duì)K-means算法存在的缺點(diǎn),作出一些改進(jìn)。
在改進(jìn)的K-means算法中,引入了聚類引導(dǎo)函數(shù) f(xi),該函數(shù)可以幫助確定聚類向著點(diǎn)密度高的方向進(jìn)行聚類。
定義1(曼哈頓距離)
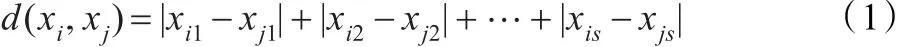
式中,xi=(xi1,xi2,…,xis),yj=(yj1,yj2,…,yjs)都是s維的數(shù)據(jù)對(duì)象。
聚類引導(dǎo)函數(shù)中r的計(jì)算:
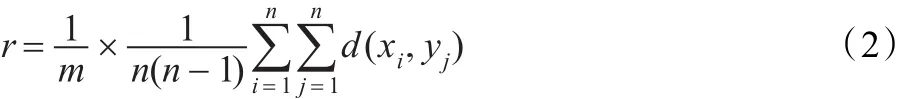
其中,m為正數(shù),可調(diào)節(jié),通常情況下為2。
定義2(聚類引導(dǎo)函數(shù))
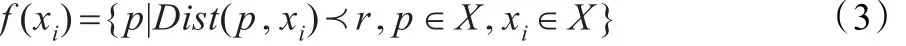
式中,X是數(shù)據(jù)對(duì)象集合,Dist(p,xi)為數(shù)據(jù)對(duì)象 p到數(shù)據(jù)對(duì)象xi的距離,r代表距離半徑,采用曼哈頓距離計(jì)算。
數(shù)據(jù)集中的每個(gè)對(duì)象可以根據(jù)以上定義的計(jì)算方法計(jì)算出對(duì)應(yīng)的聚類引導(dǎo)函數(shù)值,該值將會(huì)被用做聚類中選擇聚類對(duì)象的依據(jù)。
改進(jìn)的K-means算法基于找到一個(gè)小范圍內(nèi)具有最大聚類引導(dǎo)函數(shù)值 f(xi)的對(duì)象,即點(diǎn)密度最高的對(duì)象作為所在類的代表,每個(gè)類將會(huì)是由代表點(diǎn)所代表的對(duì)象和屬于該代表點(diǎn)的對(duì)象組成。
改進(jìn)K-means算法的整個(gè)算法描述如下:

過(guò)程:
根據(jù)輸入的數(shù)據(jù)對(duì)象,計(jì)算出r及每個(gè)對(duì)象的聚類引導(dǎo)函數(shù);
將每個(gè)對(duì)象看做一類,這樣就形成了n個(gè)類,每個(gè)類中只有一個(gè)代表點(diǎn);
Do
對(duì)于每個(gè)類代表點(diǎn) xi,尋找對(duì)象 xj,i≠j,xj到 xi的距離小于r,且 f(xj)是所有小于r對(duì)象中 f(xj)最大的;
比較 f(xi)和 f(xj),若 f(xi)?f(xj),則類 xj歸入類 xi中,否則,類xi不變;
Until對(duì)于每個(gè) i=1,2,…,n ,類 xi不再發(fā)生變化。
3.2 改進(jìn)Apriori算法
Apriori是由R.Agrawal等人提出的數(shù)據(jù)挖掘中經(jīng)典的關(guān)聯(lián)規(guī)則算法,Apriori采取多次掃描數(shù)據(jù)庫(kù)的方法來(lái)產(chǎn)生頻繁項(xiàng)目集[12]。具體做法是:第一次掃描后只產(chǎn)生寬度為1的候選項(xiàng)目集,然后通過(guò)比較每個(gè)項(xiàng)目的支持度與最小支持度,將不低于最小支持度的1-階候選項(xiàng)目集添加到頻繁項(xiàng)目集中,此時(shí)形成了只包含1-階項(xiàng)目的最初的頻繁項(xiàng)目集。此后,每一次掃描,都要根據(jù)前一次產(chǎn)生的頻繁項(xiàng)目集,先構(gòu)造出本次的候選項(xiàng)目集,然后再掃描數(shù)據(jù)庫(kù),從候選項(xiàng)目集中確定出本次的頻繁項(xiàng)目集。重復(fù)以上過(guò)程,直到不再產(chǎn)生新的頻繁項(xiàng)目集為止。
Apriori算法是一個(gè)通用的數(shù)據(jù)挖掘算法,并不支持入侵檢測(cè)的多屬性問(wèn)題。Apriori算法中的各個(gè)事務(wù)中的項(xiàng)目之間不存在相互關(guān)系,一個(gè)項(xiàng)目的存在不會(huì)影響另一個(gè)項(xiàng)目,任何項(xiàng)目組合都可以。但是,對(duì)于入侵檢測(cè)數(shù)據(jù)庫(kù)中的數(shù)據(jù)并不是如此。如果直接使用該數(shù)據(jù)庫(kù)的數(shù)據(jù)進(jìn)行關(guān)聯(lián)規(guī)則,由于中間過(guò)程中會(huì)產(chǎn)生無(wú)效候選項(xiàng),可又需要掃描數(shù)據(jù)庫(kù)計(jì)算其支持度,會(huì)大大降低該算法的效率。
根據(jù)入侵檢測(cè)領(lǐng)域知識(shí),可知同一特征下的不同屬性支持度為0這一性質(zhì),可對(duì)Apriori算法作如下改進(jìn):
將Apriori算法cand-gen()子程序改為:

4 驗(yàn)證算法功能
4.1 K-means算法性能驗(yàn)證實(shí)驗(yàn)
實(shí)驗(yàn)數(shù)據(jù)集:采用入侵檢測(cè)領(lǐng)域比較權(quán)威的測(cè)試數(shù)據(jù)KDD cup99[13]中的“kddcup.data_10.percent”10%數(shù)據(jù)集。
該實(shí)驗(yàn)數(shù)據(jù)集中主要包括DoS、U2R、R2L和Probe四大類攻擊數(shù)據(jù)。以下分別針對(duì)這四類攻擊數(shù)據(jù)對(duì)算法性能進(jìn)行檢測(cè)。
為了滿足檢測(cè)算法中兩個(gè)假設(shè)的需要,每次實(shí)驗(yàn)從相應(yīng)數(shù)據(jù)集中選擇2 000條記錄用于實(shí)驗(yàn),其中正常數(shù)據(jù)1 966條,入侵?jǐn)?shù)據(jù)34條,正常數(shù)據(jù)在所有數(shù)據(jù)中所占比例為98.30%,滿足了檢測(cè)算法對(duì)于正常數(shù)據(jù)的數(shù)量要遠(yuǎn)大于入侵?jǐn)?shù)據(jù)數(shù)量的假設(shè)的需要。將各數(shù)據(jù)集分別在K-means和改進(jìn)K-means上進(jìn)行實(shí)驗(yàn),比較算法性能。檢測(cè)率越高,誤檢率越低,說(shuō)明算法的檢測(cè)能力越好。
以下將采用兩種不同的角度對(duì)算法的性能進(jìn)行實(shí)驗(yàn),檢測(cè)算法的性能。一種是采用單一攻擊數(shù)據(jù)集,即數(shù)據(jù)集中的攻擊數(shù)據(jù)均屬于單一類別。另一種就是混合攻擊檢測(cè),即數(shù)據(jù)集中的攻擊數(shù)據(jù)是各種攻擊數(shù)據(jù)的混合,類別更豐富。
(1)算法對(duì)單一攻擊的檢測(cè)性能:K-means算法需要事先指定聚類個(gè)數(shù),且不同的聚類數(shù)對(duì)算法的聚類結(jié)果有很大的影響,所以需要進(jìn)行反復(fù)實(shí)驗(yàn)。通過(guò)調(diào)整聚類個(gè)數(shù)得出K-means算法在各種攻擊數(shù)據(jù)集上的聚類性能如表1所示。
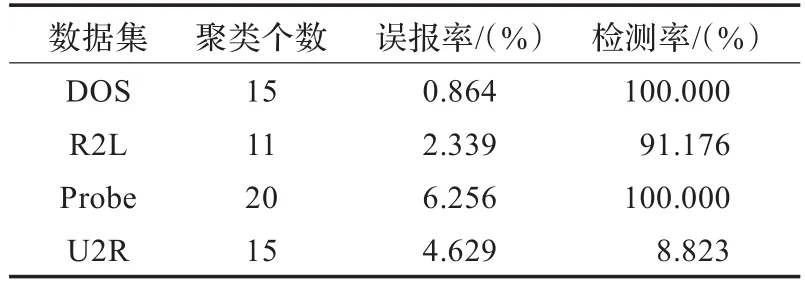
表1 K-means算法單一攻擊性能
改進(jìn)K-means算法不需要事先指定聚類個(gè)數(shù),可以根據(jù)數(shù)據(jù)集特定自主確定聚類個(gè)數(shù)。最終得出改進(jìn)K-means算法對(duì)各種攻擊的聚類性能如表2。
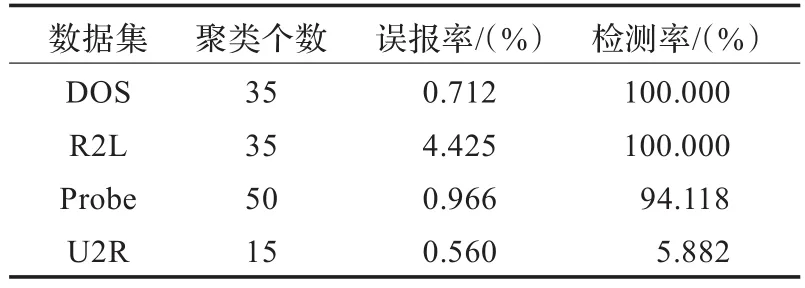
表2 改進(jìn)K-means算法單一攻擊性能
實(shí)驗(yàn)結(jié)果分析:從表1和表2中可以看出,和K-means算法相比,改進(jìn)K-means算法的單一攻擊性能中誤報(bào)率更低、檢測(cè)率更高。
(2)算法對(duì)綜合攻擊的檢測(cè)性能:K-means算法聚類性能如表3所示。
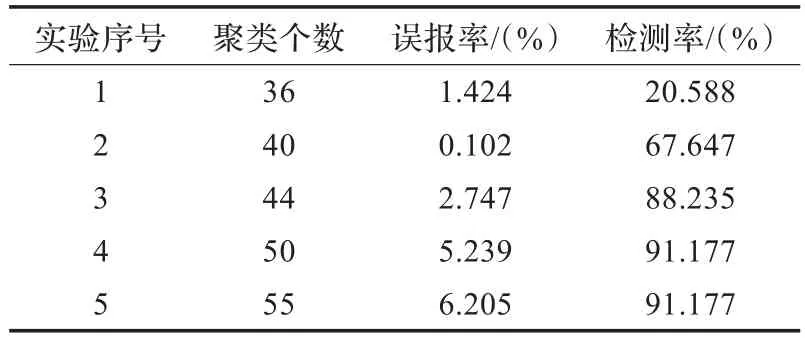
表3 K-means算法的綜合攻擊性能
改進(jìn)K-means算法性能如表4。

表4 改進(jìn)K-means算法的綜合攻擊性能
實(shí)驗(yàn)結(jié)果分析:從表3和表4中可以看出,和K-means算法相比,改進(jìn)K-means算法的綜合攻擊性能中誤報(bào)率更低、檢測(cè)率更高。
綜上所述,改進(jìn)K-means算法在不需要輸入聚類個(gè)數(shù)的前提下,能夠根據(jù)數(shù)據(jù)特點(diǎn)找出比較適當(dāng)?shù)木垲悢?shù)量。它對(duì)單種入侵和混合入侵均表現(xiàn)出較低的誤報(bào)率和較高的檢測(cè)率,因此,改進(jìn)K-means算法是可行的。
4.2 Apriori算法性能驗(yàn)證實(shí)驗(yàn)
利用改進(jìn)的Apriori算法實(shí)現(xiàn)規(guī)則自動(dòng)擴(kuò)充能力。首先從數(shù)據(jù)集中挖掘出頻繁項(xiàng)目集,進(jìn)而形成關(guān)聯(lián)規(guī)則并將其存入規(guī)則庫(kù)中。
本次實(shí)驗(yàn)輸出規(guī)則采用的Snort規(guī)則的格式,因此,選擇duration,protocol_type,service,flag,src_bytes和dst_bytes這六個(gè)和Snort規(guī)則相關(guān)的字段。
實(shí)現(xiàn)規(guī)則自動(dòng)擴(kuò)充功能的程序界面如圖2所示。
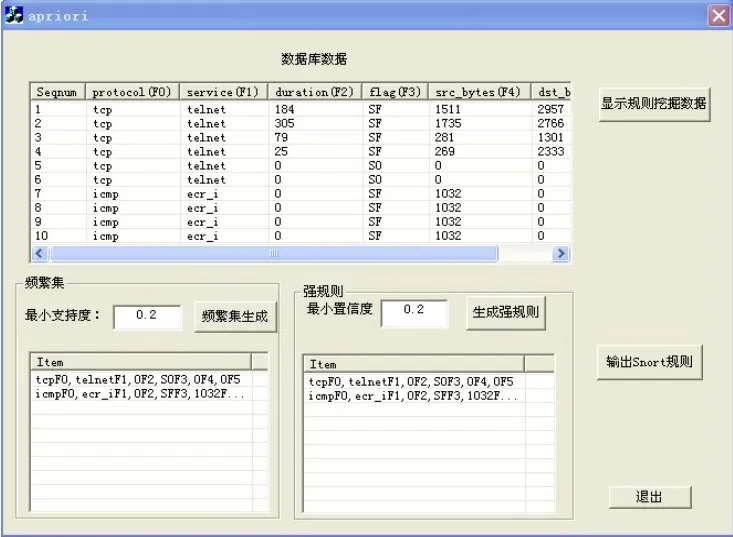
圖2 規(guī)則生成
根據(jù)圖2所示,生成規(guī)則的過(guò)程為:當(dāng)設(shè)定最小支持度為0.2時(shí),接著點(diǎn)擊“頻繁集生成”按鈕,在下面的列表框里會(huì)顯示出生成的滿足最小支持度階數(shù)最高的頻繁集,如圖2,生成兩個(gè)支持度大于0.2的頻繁集。然后,設(shè)置最小置信度為0.2時(shí),點(diǎn)擊“生成強(qiáng)規(guī)則”按鈕,在下面列表框里將會(huì)顯示生成的滿足最小置信度的規(guī)則。如圖2,剛剛產(chǎn)生的頻繁集都是強(qiáng)規(guī)則。最后,點(diǎn)擊“輸出Snort規(guī)則”,程序就會(huì)將剛剛生成的強(qiáng)規(guī)則按Snort規(guī)則的格式寫到文本文件rules.txt中。
結(jié)論,通過(guò)規(guī)則生成程序?qū)ξ粗魯?shù)據(jù)進(jìn)行關(guān)聯(lián)規(guī)則挖掘,可以實(shí)現(xiàn)入侵檢測(cè)系統(tǒng)規(guī)則庫(kù)的擴(kuò)充。
5 結(jié)束語(yǔ)
本文設(shè)計(jì)了一個(gè)基于數(shù)據(jù)挖掘的、將誤用檢測(cè)和異常檢測(cè)相結(jié)合的入侵檢測(cè)系統(tǒng)模型,并對(duì)相關(guān)模塊的工作流程及工作步驟進(jìn)行了詳細(xì)的介紹。針對(duì)模型中重點(diǎn)模塊要實(shí)現(xiàn)的功能,在數(shù)據(jù)挖掘算法中選擇了合適的算法。用改進(jìn)的K-means算法實(shí)現(xiàn)正常行為類及數(shù)據(jù)分離模塊,用改進(jìn)Apriori算法實(shí)現(xiàn)規(guī)則庫(kù)的自動(dòng)擴(kuò)充功能,并通過(guò)實(shí)驗(yàn)驗(yàn)證了兩個(gè)算法的功能。
基于改進(jìn)數(shù)據(jù)挖掘算法的入侵檢測(cè)系統(tǒng)模型的研究實(shí)現(xiàn)了入侵檢測(cè)系統(tǒng)的檢測(cè)率的提高和漏報(bào)率的降低,改善了整個(gè)檢測(cè)系統(tǒng)的檢測(cè)性能。
[1]王艷,肖維民.數(shù)據(jù)挖掘技術(shù)在入侵檢測(cè)系統(tǒng)中的應(yīng)用研究[D].馬鞍山:安徽工業(yè)大學(xué),2010.
[2]Verwoerd T,Hunt R.Intrusion detection techniques and approaches[J].Computer Communications,2002,25(15):1356-1365.
[3]于琨.基于高頻統(tǒng)計(jì)的異常檢測(cè)方法的設(shè)計(jì)與實(shí)現(xiàn)[D].北京:北京郵電大學(xué),2006.
[4]蔡堅(jiān).基于人工神經(jīng)網(wǎng)絡(luò)的入侵檢測(cè)系統(tǒng)的研究與實(shí)現(xiàn)[D].貴陽(yáng):貴州大學(xué),2005.
[5]武濤,王新房.基于數(shù)據(jù)挖掘的入侵檢測(cè)研究[D].西安:西安理工大學(xué),2010.
[6]陳宇暉,傅明.基于數(shù)據(jù)挖掘的入侵檢測(cè)方法研究[D].長(zhǎng)沙:長(zhǎng)沙理工大學(xué),2010.
[7]李洋.K-means聚類算法在入侵檢測(cè)中的應(yīng)用[J].計(jì)算機(jī)工程,2007,33(14):154-156.
[8]張建萍.基于聚類分析的K-means算法研究及應(yīng)用[J].計(jì)算機(jī)應(yīng)用研究,2007,24(5):166-168.
[9]Chinrungrueng C,Sequin C H.Optimal adaptive k-means algorithm with dynamic adjustment of learning rate[J].IEEE Trans on Neural Networks,1995,6.
[10]嚴(yán)曉光.聚類在網(wǎng)絡(luò)入侵的異常檢測(cè)中的應(yīng)用[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2005(10):34-37.
[11]馬曉春,高翔,高德遠(yuǎn).聚類分析在入侵檢測(cè)系統(tǒng)中應(yīng)用研究[J].微電子學(xué)與計(jì)算機(jī),2005,22(4):134-136.
[12]Sun Ying.Using data mining technology solve intrusion detection of network[J].Computer Knowledge and Technology,2010,6(23):6463-6464.
[13]張新有,賈磊.入侵檢測(cè)數(shù)據(jù)集KDD CUP99研究[J].計(jì)算機(jī)工程與設(shè)計(jì),2010,31(22):4809-4812.
猜你喜歡
小獼猴智力畫(huà)刊(2022年3期)2022-03-29 01:09:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
大眾投資指南(2021年35期)2021-02-16 01:06:26
Coco薇(2017年11期)2018-01-03 20:59:57
電力與能源(2017年6期)2017-05-14 06:19:37
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
