基于關聯數據的高校圖書館知識服務探討
2013-08-21 01:24:14賀令輝
圖書館研究 2013年1期
賀令輝
(中山大學圖書館,廣東 廣州 510275)
1 引言
隨著語義網的發展,關聯數據近年來受到政府、新聞媒體、公司、學術界等領域的廣泛關注。《紐約時報》從2009年開始以關聯開放數據(LOD)的形式發布包括人物(People)、組織機構(Organizations)、地點(Locations)、主題描述(Subject Descriptors)的新聞詞匯的信息,這些數據分別以RDF文檔和Web頁面發布,用戶可以在網站上下載或按照首字母瀏覽。上海圖書館學會通過舉辦“2010圖書館前沿技術論壇:關聯數據與書目數據的未來”學術會議,商討圖書館如何將書目數據轉換為關聯數據。武漢大學信息管理學院邀請美國肯特州立大學圖書情報學院教授曾蕾在該院作了題為 “關聯數據的發展以及圖書館和信息知識服務的前景”的報告,介紹了圖書館和信息服務領域關聯數據的應用。關聯數據促進了數據的大規模集成,并支持機器處理富含語義的數據,從而提高了用戶信息獲取的全面性和準確性。本文在分析國外圖書館應用關聯數據現狀的基礎上,探討了高校圖書館基于關聯數據的知識服務策略,旨在推動我國圖書館界積極投入關聯數據的開發應用中,以促進圖書館服務水平的提高。
2 關聯數據概述
關聯數據是一種萬維網上發布數據的方式,是W3C推薦用來發布和聯接各類數據、信息和知識的一種規范。關聯數據采用RDF(資源描述框架)數據模型,利用URI(統一資源標識符)命名數據實體,并在網絡上發布,從而可以通過HTTP協議揭示并獲取這些數據。關聯數據的功能主要體現在兩個方面:(1)數據整合,即通過關聯數據將各種數據源無縫地關聯起來,成為一個廣域分布的數據庫;(2)數據發現或挖掘,關聯數據對關系形式化描述,形成一張關系地圖,使得機器可以通過理解和處理數據之間的各種關系,發現新的數據。萬維網上存在著大量非結構化數據和采用不同標準的結構化數據,關聯數據是一種簡單的語義網實現技術,其重要價值在于通過RDF數據模型,將網絡上的非結構化數據和采用不同標準的結構化數據轉換成遵循統一標準的結構化數據,以便機器理解。高校圖書館可利用RDF數據模型在萬維網上發布結構化數據,利用RDF鏈接不同數據源的數據,加強網絡資源整合,面向用戶開展知識服務。
3 國外圖書館關聯數據應用現狀分析
自從2006年蒂姆·伯納斯·李(Tim Berners-Lee)在《關聯數據構建筆記》一文中提出關聯數據概念以來,國際圖書館界紛紛開展了相關的研究。2010年5月28日,W3C成立了圖書館關聯數據孵化小組,該小組由來自圖書館、博物館、檔案館、出版業等相關領域的關聯數據技術專家組成,關注關聯數據技術及其應用,幫助圖書館將有價值的數據(如書目數據、規范文檔等)發布到互聯網中,實現同其他機構數據之間的互操作,以帶動更多的圖書館及相關領域的人參與語義網活動。目前,W3C已完成收集和編寫近50多個案例,幾乎涵蓋圖書館行業數據,內容涉及規范控制、詞表發布、書目數據、參考引文、檔案和異構數據、資源集合等。美國國會圖書館以簡單知識組織系統(SKOS)格式將國會標題表(LCSH)全部關聯數據化,并且提供LCSH詞表的下載。瑞典國家圖書館早在2008年便將瑞典聯合目錄(LIBRIS)發布為關聯數據,為圖書館、博物館和檔案館提供在線編目服務,并創建了與LCSH和維基百科(Wikipedia)等的相關鏈接。LIBRIS是世界第一個將書目數據發布成關聯數據的聯合目錄。匈牙利國家圖書館(National Széchényi Library,NSZL)將其OPAC、數字圖書館以及相應官方數據采用HTML和RDF兩種方式進行表示,并用CoolURI命名發布為關聯數據。英國圖書館將英國國家書目從MARC21格式轉換為關聯數據的RDF/XML格式,截至2011年7月,英國圖書館已將約49萬國家書目數據從MARC21格式轉換為關聯數據的RDF/XML格式。這一轉換既能發揮MARC格式的傳統功能又能發揮關聯數據的優勢,為圖書館提供新的服務集成數據。這些國家圖書館將圖書館資源發布為關聯數據,并利用關聯數據實現數據融合,實現了知識單元的有序組織、集成和關聯,深層展示了知識內容的關聯,為用戶提供多層次的知識關聯集成服務。
4 基于關聯數據的高校圖書館知識服務
關聯數據為圖書館提供了知識資源之間的鏈接,使發現和共享網絡中不同類型的知識資源成為可能。目前,關聯數據在圖書館界的應用主要集中在書目數據領域,將書目數據和規范數據以關聯數據的形式進行發布。高校圖書館可利用人員和技術優勢,將圖書館資源發布為關聯數據,進行跨網域的數據整合,擴展圖書館資源,為用戶提供知識服務。
4.1 關聯數據的構建與發布
構建和發布關聯數據是高校圖書館開展基于關聯數據知識服務的基礎。關聯數據通過URI、HTTP、RDF等語義網技術將網絡上相關的數據資源進行關聯,其最主要的特點是為不同數據集中的同一個實體對象建立關聯關系,并支持利用這種關系實現對相關信息對象的發現、識別以及融匯服務的提供。首先,圖書館應依據關聯規則創建關聯數據,用規范形式描述內容對象的內部結構、描述內容的語義(如作者、書名、出版社、內含數據集和圖表等),描述結果是依據元數據格式轉換的RDF關聯記錄。其次,構建關聯數據的關聯關系。圖書館收藏了大量同構數據和異構數據,對于同構數據,可通過分析數據對象實例的屬性值和語境相似度來發現并建立關聯關系,如應用字符相似度算法、字符串相似度算法、基于字典相似度算法等屬性值相似算法和基本算法聚合、分類模型等組合方法來判斷兩個對象實例是否等同。對于異構數據,關聯關系創建的基本策略是建立異構數據之間的架構映射,然后運用同構方法創建對象實例間的關聯,如采取基于圖相似度的映射和基于實體的文本映射方法建立關聯數據。最后,發布關聯數據。從技術角度分析,發布關聯數據并不復雜。利用RDF數據模型在萬維網上發布結構化數據,利用RDF鏈接不同數據源的數據。如對于儲存在關系型數據庫里的數據,可用D2R Server將數據轉換成RDF格式,并發布到網上。把圖書館的關聯數據集通過RDF links與網上其他數據集相連,使瀏覽器或搜索器能搜索和瀏覽圖書館發布的數據。對館藏資源建立關聯數據,揭示文章之間的學術關聯性,幫助研究者盡快找到最需要的期刊、文章等學術資源,是高校圖書館建立關聯數據的首要任務。
4.2 知識資源的整合
知識資源整合為高校圖書館開展知識服務提供了豐富的資源保障。目前,圖書館一般對網頁層面的信息進行簡單整合,關聯數據的出現改變了傳統的信息聚合方法,關聯數據技術提供了一種靈活且易實現的聚合方法。首先,高校圖書館應對“內部的數據”關聯起來,將圖書館管理系統、檢索平臺、參考咨詢系統的數據進行關聯,使圖書館能及時了解讀者需求。其次,整合圖書館內部和外部的資源。在關聯開放數據(LOD)項目的推動下,目前有超過130億條傳統網頁上的數據例如維基百科、地理數據集和政府數據集等,已經轉換成了關聯數據。圖書館可根據關聯數據的基本原理和關聯數據驅動的Web應用框架,將關聯數據進行整合。通過超鏈接的方式,讀者通過點擊相關按鈕關聯到文章全文或其他擴展服務。
4.3 知識資源的推薦
在對關聯數據整合的基礎上,高校圖書館可以利用關聯數據向讀者推薦最新的學術資源。如向讀者推薦最新圖書、最新學術動態。如圖1所示,圖書館將學術資源進行開發和數據提煉,建立圖書館推薦資源知識庫,通過關聯規則和數據挖掘,建立關聯規則知識庫,利用Web服務器,向用戶推薦關聯學術資源。該推薦系統主要由三大模塊來實現其功能,每一個模塊都有自己獨立的功能,其中最主要的模塊是關聯規則之數據挖掘模塊,它是整個圖書館學術資源推薦系統框架的核心部分。
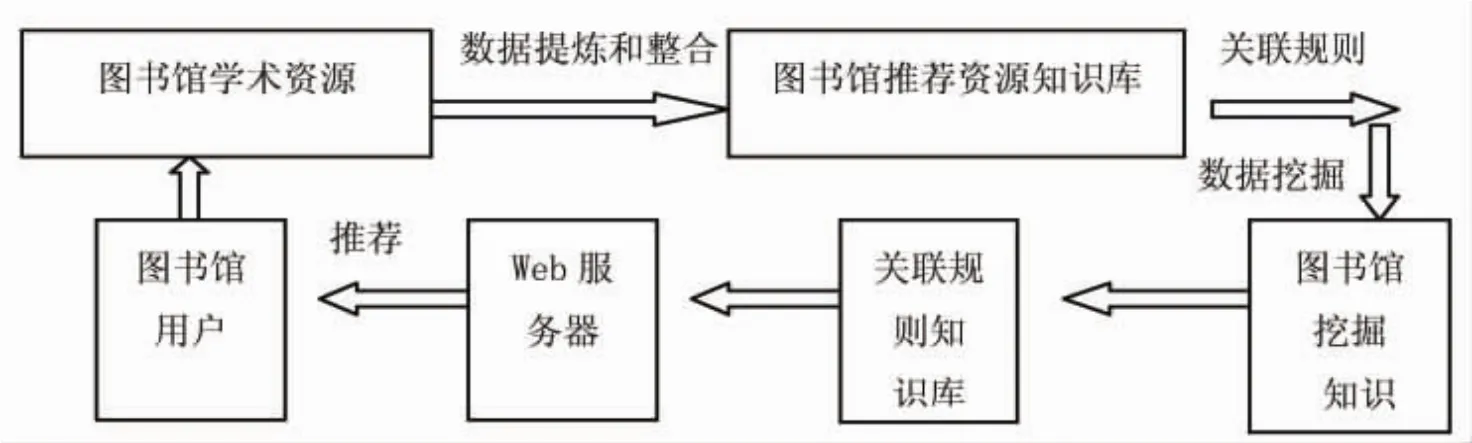
圖1 基于關聯數據的圖書館學術資源推薦系統框架圖
5 結束語
英國學者馬克斯·H·博伊索特認為,知識是創造財富的資產,是從數據中提取信息為基礎建立起來的一種能力;知識被結構化和被分享的程度構成一種文化。關聯數據在數據層建立了富鏈接機制,較完善地描述了數據的結構信息。關聯數據的推出,為圖書館網絡信息服務帶來了良好的機遇。隨著關聯數據規模的不斷擴展,高校圖書館可整合企業、檔案館、博物館、科研單位和政府發布的關聯數據,以更優質的資源、便捷的服務手段為用戶開展知識服務。
[1]王薇,歐石燕.關聯數據在圖書館領域的應用研究[J].新世紀圖書館,2012(9):25-28.
[2]管進.基于關聯數據的圖書館知識服務策略研究[J].圖書館理論與實踐,2012(6):9-11.
[3]劉煒.關聯數據:概念、技術及應用展望[J].大學圖書館學報,2011(2):5-12.
[4]黃永文,岳笑.劉建華.關聯數據應用的體系框架及構建關聯數據應用的建議[J].現代圖書情報技術,2011(9):7-13.
[5]鄭燃,唐義,戴艷清.基于關聯數據的圖書館、檔案館和博物館數字資源整合研究[J].圖書與情報,2012(1):71-76.
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
當代陜西(2021年17期)2021-11-06 03:21:36
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
資源再生(2017年3期)2017-06-01 12:20:59
讀者(2017年5期)2017-02-15 18:04:18
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
