改進的SDT算法
2013-07-25 02:28:10邢銳,祁奇,鄭滔
計算機工程與設計 2013年2期
關鍵詞:數據庫
邢 銳,祁 奇,鄭 滔
(南京大學軟件學院,江蘇南京210093)
0 引言
在工業生產過程中長期積累的數據是工業現場寶貴的資源,為診斷和處理故障提供了第一手資料,并同趨勢分析、報警記錄、報表打印等服務緊密結合。因此,普遍存在著存儲和利用這些海量生產數據的應用需求。將數據全部存儲到數據庫中明顯是不合適也是不現實的,因此需要進行壓縮。
當前有三類實時數據庫系統壓縮算法:有損壓縮、無損壓縮和結合前兩種方法的二級壓縮。無損壓縮不能滿足存儲海量數據要求。而最著名的有損壓縮算法是PI的旋轉門算法。本文針對旋轉門算法進行了分析,改進了旋轉門中由于必須存儲原始數據點而限制壓縮比的缺點。實驗證明改進后的算法確實能夠在不提高壓縮誤差的情況下有效提高壓縮比。
1 有損壓縮算法介紹
1.1 工業標準死區壓縮算法[1]
很早提出的線性有損壓縮算法,基本思想是:如果當前點和最后一個記錄點的差值在一個閾值范圍以內,就壓縮當前點,否則記錄當前點,向后壓縮。
該算法最大的好處就是簡單,實現起來沒有任何難度,而缺點也很明顯,壓縮直線的選取過于單一,如果某一段內的點都分布在某條斜率不為0的直線周圍,使用該方法得到的結果很差。另外也有人將該算法與后面介紹的算法結合起來,獲得了比較好的效果[2]。
1.2 兩點式壓縮算法[3]
同樣也是很早提出的線性有損壓縮算法,其基本思想是,采用當前記錄的兩個點的延長線來預測后面的數據,如果使用這條延長線插值得到的數據和當前數據的值之間的偏差在一個閾值范圍以內,就壓縮當前點,否則記錄當前點,用當前點和前一個點向后壓縮。
該方法較工業標準死區壓縮算法的好處就是直線的選取不再使用單一的平行于x軸的直線,而采取了兩個點的連線。這樣在一定程度上改善了工業標準死區算法中的缺點。但由于直線是采用了之前已經存儲的兩個點來確定的,因此過早確定直線導致該算法的預后性較差。沒有通過后來的點來調整這條直線位置的缺陷也導致了該算法在效果上不如后面介紹的一些算法。
1.3 旋轉門壓縮算法[4]
美國OSI軟件公司研發的用于實時數據庫的有損壓縮算法[4],對于旋轉門壓縮算法來說,先由上一保存數據項和當前數據項來畫出一條直線 (在二維坐標圖上),如果待保存數據項不在當前數據項和上一保存數據項的壓縮偏差范圍之內,則待保存數據項被保存。就算法的具體實現來說,有基本的旋轉門壓縮算法和基于斜率比較的旋轉門壓縮算法。旋轉門壓縮算法是根據數據構建一個又一個的高度 (高度即有損壓縮的閾值)固定的平行四邊形去“套住”數據,在不能“套住”時將前一個點進行歸檔 (存儲)。圖1為旋轉門壓縮算法的示意圖。
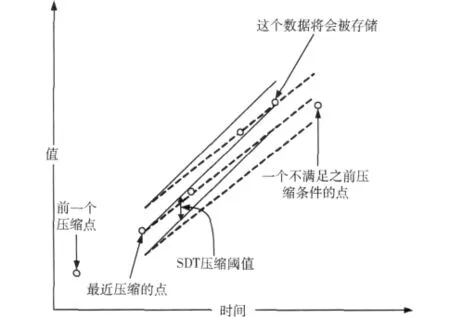
圖1 旋轉門壓縮算法示例
該方法改善了兩點式壓縮算法中過早確定直線的不足,采用該方法能夠根據后面新來的數據調整直線的位置。這樣能夠很好的根據數據的發展趨勢進行壓縮。
但就直線的選取方法來說,仍顯得有些單一。如果不限定壓縮的直線必須采用首尾點的連線的話,就可以在某個壓縮區域內壓縮更多的點。
1.4 一些基于旋轉門壓縮算法的改進算法
在旋轉門壓縮算法基礎上,有人提出了一些其它的算法,比如動態調整旋轉門壓縮算法中的閾值來適應數據的方法[5],限制一次壓縮的數據長度等方法[6],識別噪聲點的算法[7],使用曲線進行擬合的算法[8]以及增量型 SDT算法[9]。
2 改進的旋轉門算法
算法思想介紹
旋轉門壓縮算法的基本思想是,存儲的數據均為原始數據。然而有損壓縮算法本身就對誤差有一定的容忍,經過實驗發現,存儲處理后的數據而非原始數據可以達到甚至超過旋轉門壓縮算法的壓縮效果。
可以不存儲原始數據而存儲處理過的數據,這個是該改進算法重要思想之一。而其他的大部分的旋轉門壓縮改進算法都是基于原來的旋轉門壓縮算法做一些新的處理。比如控制閾值,限制長度等。
在壓縮完一段數據以后重新選擇起始點是該改進算法的另一個重要思想。由于數據變化的連續性,上一個失效的壓縮點的數據失效是因為數據的發展趨勢發生了變化,而此時使用上一個壓縮區段的最后點來進行存儲會較大的影響壓縮的效果。因此在該算法中,壓縮完一段數據后,重新選擇下一個數據點作為下一區段的起點。
算法介紹
算法保存由當前可壓縮的點組成的點集Q,每來一個新的點p和Q構成新的點集Q’。判斷Q’能否用一條線段來壓縮。如果可以則用Q’替換Q,繼續讀入新的點。如果不行則存儲用于擬合點集Q中數據的線段信息,清空Q,將p添加到點集Q中,然后讀入新的點,開始下一段壓縮。
判斷點集Q能否用線段壓縮的方法:
在本題目的要求下,點集Q能夠被線段壓縮的條件等價于:
條件1 能夠找到一條直線L,滿足:Q中的所有的點到L的豎直距離不超過MAX_ERROR(MAX_ERROR為壓縮算法當中的閾值)。
如果有一條直線L滿足條件1,顯然可以使用L來壓縮和恢復數據。而如果Q可以被某條線段壓縮,該線段所在的直線L顯然滿足條件1。
條件2 能夠找到兩條平行的直線L1、L2,滿足:Q中所有的點都在L1的下方 (包括在L1直線上)、L2的上方 (包括在L2直線上),同時L1、L2在豎直方向的距離d不超過2*MAX_ERROR。
顯然條件1和條件2是等價的。
在滿足條件2的L1、L2當中一定有某一對L1、L2,它們之間的豎直距離是最小的。假設這個距離為dMin,將對應dMin的L1和L2記為MinL1和MinL2。
條件3 Q中的MinL1、MinL2的豎直距離dMin不超過2*MAX_ERROR。
顯然條件2和條件3也是等價的。
下面證明MinL1和MinL2的兩個性質:
性質1 MinL1和MinL2各自至少經過Q中的一個點。
性質2 MinL1和MinL2中至少有一條經過了Q中的兩個點。
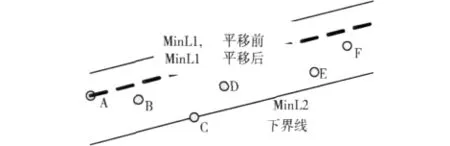
圖2 性質1說明
性質1證明:用反證法來證明。
不妨設MinL1沒有經過點集當中的點,如圖2所示。則很明顯將MinL1向下平移至經過A點的直線MinL1’后也滿足條件 (2)。而此時兩條平行線的距離明顯小于之前的兩條平行線的距離。因此之前的兩條平行線不是dMin最小的兩條平行線,而這與假設矛盾,因此MinL1必定經過Q中的某個點。同理可證,MinL2必定經過Q中的某個點。
證畢。
性質2證明:仍然用反證法證明。
性質1,可假設MinL1和MinL2各自都只經過了Q中的一個點,如圖3所示。設MinL1經過的點為A(xA,yA),MinL2經過的點為C(xC,yC)。假設MinL1的斜率為k,則通過計算可得,MinL1和MinL2在豎直方向的距離
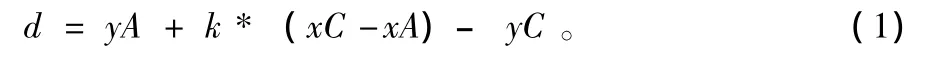
由于在某個時間點上只能有一個數據,因此Q中所有的點均不可能有相同的橫坐標。
不妨設A點在C點左邊,即有xA<xC。那么由 (1)式可知,k的值越小,d也就越小。也就是說看這兩條線能否繞著A點及C點順時針旋轉。
在圖2中,由于兩條直線都只經過點集Q中的一個點。明顯可以通過將MinL1順時針旋轉至MinL1'(MinL1'經過了點集中的另一個點 F),而將 MinL2順時針旋轉至MinL2'。其中F是兩條線同時旋轉時它們首先碰到的Q中的其它點。明顯 MinL1'和 MinL2'是滿足條件2的,而MinL1'和MinL2'的距離d小于MinL1和MinL2的距離。這與之前假設的MinL1和MinL2是最有壓縮的條件矛盾,因此說明假設不成立。說明MinL1和MinL2至少有一個經過了點集Q中的兩個點。
對于A點在C點右邊的情況,同理可證明。
證畢。
由以上證明過程也可以看出:
性質3:MinL1和MinL2中至少有一條是點集Q中某兩個點的連線L,而且 L能夠將點集Q中所有的點分隔在L的一邊 (包括在L上)。
由以上三條性質可知:條件3等價于條件4:
條件4:在點集Q中所有滿足條件5的L中,至少有一個L滿足條件6。
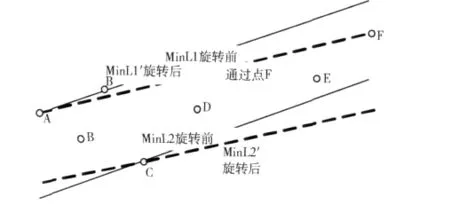
圖3 性質2說明
條件5:L是Q中的某兩個點的連線,而且L能夠將Q中點分隔在L的一邊。
條件6:Q中的點到L的最大豎直距離dmax不超過2*MAX_ERROR。
壓縮算法流程
壓縮算法的過程:
根據以上的分析,壓縮算法設計如下:
使用一個數組LArray記錄Q中所有滿足條件5和條件6的L(包括直線斜率k,y軸截距b,Q中的點到L的最大豎直距離的dmax,點集Q中點和它的位置關系的一個bool變量location,點在上方為true,下方為false),使用MinL記錄LArray中dmax最小的L。
步驟1 將Q和LArray置空,讀入新數據至newPoint,存儲newPoint,同時將它添加到點集Q中。
步驟2 判斷有沒有新來點,如果沒有則跳至步驟9。
步驟3 讀入新數據至newPoint,并將其添加到Q中,將LArray中由于添加了newPoint而不再滿足條件5和條件6的L移除。
步驟4 在newPoint和點集Q中其它點構成的直線當中,選出斜率最大的直線 kMaxL,和斜率最小的直線kMinL。顯然在這些直線中,有且只有kMaxL和kMinL能夠滿足條件6。(如圖4所示,FH和CH為kMinL和kMaxL)。
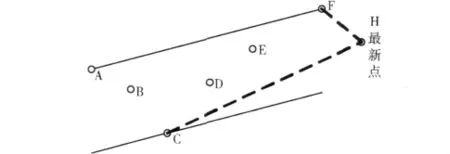
圖4 新點H的加入
步驟5 判斷kMaxL是否滿足條件6,如果滿足則將它添加到LArray當中。其中的location為true。
步驟6 判斷kMinL是否滿足條件6,如果滿足則將它添加到LArray當中。其中的location為false。
步驟7 判斷此時LArray是否為空,如果不為空,取出dmax最小的一個L保存到MinL中,并跳至步驟2。
步驟8 將MinL向location表示的方向平移dmax/2的距離,得到直線LStore。存儲用來恢復數據的LStore。將Q和LArray清空,存儲newPoint并將newPoint添加至Q中,跳至步驟2。
步驟9 將MinL向location表示的方向平移dmax/2的距離,得到直線LStore。存儲用來恢復數據的LStore。將點集Q中最右邊的點存儲,算法結束。
壓縮算法可行性分析:
步驟1、2、3都是簡單的基本步驟,可以在O(1)時間完成。
將LArray中由于新點的加入而不再滿足條件 (5)或條件 (6)的L移除。需要進行以下過程,對LArray中的每條直線判斷是否滿足條件 (5)和條件 (6)。需要進行點和直線位置判斷、點到直線豎直距離計算基本步驟。設LArray中有K條直線,則該步可以在O(K)時間內完成。假設此時點集中點數據為N,那么容易知道點集Q中滿足條件 (5)的直線不會超過N個,即K<=N。O(N)時間內完成。
步驟4中,需要進行N-1次斜率計算和2* (N-2)次比較,同樣可以在O(N)時間內完成。
步驟5和步驟6個需要N-1次距離計算和N-2距離的比較,O(N)時間完成。
步驟7需要一次判斷,可能需要K-1次比較,和一次存儲,O(N)時間完成。
步驟8和步驟9可以在O(1)時間內完成。
由以上分析過程可知,算法是可行的。
擬合算法流程
擬合算法的過程:
讀取數據庫中的兩個點P1、P2,并讀取存儲的一個LStore信息,使用LStore來恢復P1和P2之間的數據 (不包括P1和P2),然后讀取新的點P3和一個LStore信息,使用LStore恢復P2和P3之間的數據 (不包括P2和P3)。依此類推,直到數據庫中沒有新的點可以讀取時,算法結束。由以上描述可知,恢復算法的運行時間為O(M),M為壓縮前點的個數。
3 算法性能分析
對數據樣本壓縮的有關參數評估。
測試的數目為6000個數據,誤差范圍為分別為1和0.5。表1為誤差范圍為1時效果比較,表2為0.5時效果比較。
由此看來,該算法確實能夠在不增加最大誤差的情況下,減少壓縮點的數目并減少絕對值平均誤差,完成有損壓縮的要求。
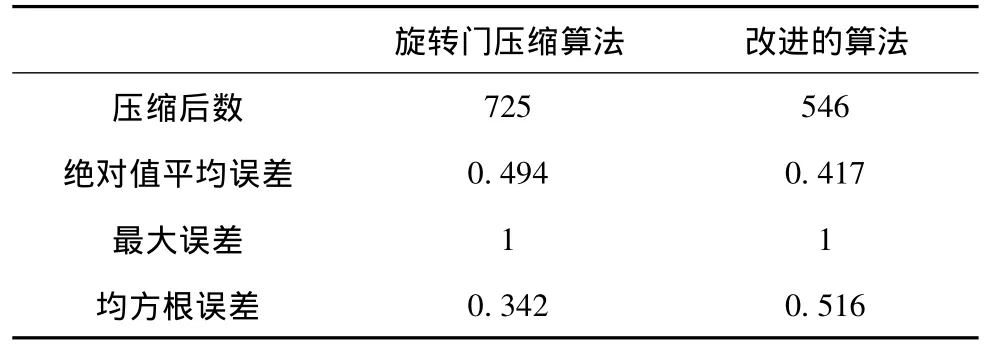
表1 誤差范圍為1時效果比較
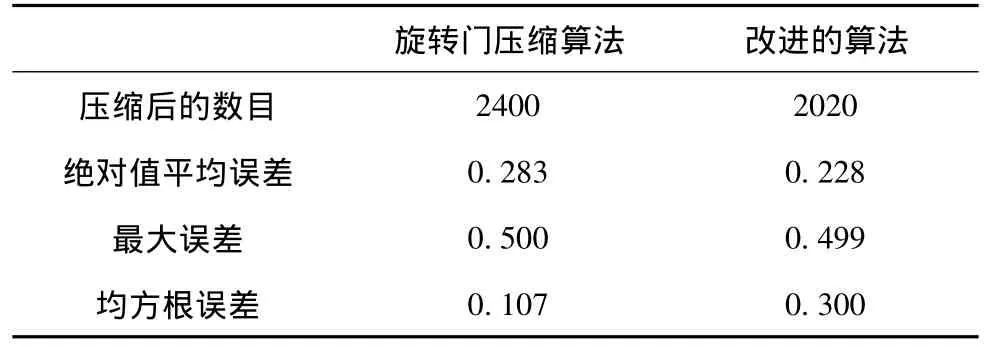
表2 誤差范圍為0.5時效果比較
4 結束語
本文提出了一種改進的旋轉門壓縮算法,并編寫了程序對合成數據和實際過程數據進行了仿真計算,解決了旋轉門算法中保存原始數據點和起始點選取過于單一的問題,實驗數據證明該算法確實能夠在不增加最大誤差的情況下,減少壓縮點的數目并減少絕對值平均誤差,完成有損壓縮的要求。改進的SDT算法計算量小,運行速度很快;并且很容易被工程技術人員所接受;它不僅可以用在過程壓縮過程中,而且也可以用于過程趨勢分析和識別等等。如果壓縮后的數據用于壓縮的話,還可以采用WinZip等軟件進一步壓縮的方法[10]。
[1]WANG Jun.Research and improvement of loss linear compression algorithms in the real-time database[J].Micro Computer Application,2011,32(7):13-18(in Chinese).[王君.基于實時數據庫的有損線性壓縮算法研究與改進[J].微計算機應用,2011,32(7):13-18.]
[2]ZHANGXiuxia,HAOJialong,WANGShuangxin.Analysis and implementation of rea-l time historical database of supervisory control and data acquisition configuration software[J].North China Electric Power,2009(11):50-54(in Chinese).[張秀霞,郝佳龍,王爽心.工業監控組態軟件實時歷史數據庫的分析與實現[J].華北電力技術,2009(11):50-54.]
[3]Sivalingam S.Effect of data compression on controller performance monitoring[C]//Trondheim,Norway:Norwegian Univ of Sci&Technol,2011:594-599.
[4]ZHANG Wang,CHEN XinChu,LU DingXing.Research and application of improved process data compression algorithm-SDT [J].Industrial Control Computer,2009(8):1-3(in Chinese).[張望陳新楚盧定興.過程數據壓縮算法SDT的改進研究與應用[J].工業控制計算機,2009(8):1-3.]
[5]QU Yilin,WANGWenhai.Automatic parameter control sdt algorithm for process data compression [J].Computer Engineering,2010,36(22):40-42(in Chinese).[曲奕霖,王文海.用于過程數據壓縮的自控精度SDT算法[J].計算機工程,2010,36(22):40-42.]
[6]ZHANG Qiaofang,LI Guangyao,DING Meilin,et al.Three dimensional canning map generating algorithm from single image[J].Computer Technology and Development,2010,20(1):22-24(in Chinese).[張巧芳,李光耀,丁關林,等.基于單幅圖像的三維瀏覽圖生成算法 [J].計算機技術與發展,2010,20(1):22-24.]
[7]ZHANGJian,LIU Guangbin.An new data compression based on isdt algorithm and its performance analysis[J].Fire Control and Command Control,2007,32(2):81-82(in Chinese).[張健,劉光斌.ISDT算法的數據壓縮處理及其性能分析[J].火力與指揮控制,2007,32(2):81-82.]
[8]NING Hainan.A new process data compression algorithm based on sdt algorithm [J].Computer Technology and Development,2010(1):25-28(in Chinese).[寧海楠.一種基于SDT算法的新的過程數據壓縮算法 [J].計算機技術與發展,2010(1):25-28.]
[9]ZHAO Liqiang,YU Tao,WANG Jianlin.Process data compression method based on SQL database[J].Computer Engineering,2008,34(14):58-62(in Chinese).[趙利強,于濤,王建林.基于SQL數據庫的過程數據壓縮方法[J].軟件技術與數據庫,2008,34(14):58-62.]
[10]ZHOU Shuangying,YU Jianqiao.Research of secondary compression algorithm of RWM & DEWS data[J].Computer Engineering,2011,37(2):40-42(in Chinese).[周雙英,余建橋.RWM&DEWS數據二次壓縮算法研究[J].計算機工程,2011,37(2):40-42.]
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
