基于多核處理器的并行雷達(dá)數(shù)據(jù)處理研究
2013-06-08 08:41:32朱海濤倪世道杜南山
雷達(dá)與對(duì)抗 2013年1期
關(guān)鍵詞:數(shù)據(jù)處理
朱海濤,倪世道,杜南山
(中國(guó)電子科技集團(tuán)公司第三十八研究所,合肥 230088)
0 引言
未來(lái)戰(zhàn)爭(zhēng)中的電磁環(huán)境將異常復(fù)雜,雷達(dá)會(huì)受到各種形式的欺騙和干擾,產(chǎn)生大量的雜波,并且需要檢測(cè)的目標(biāo)日益增多,目標(biāo)的運(yùn)動(dòng)速度越來(lái)越快,機(jī)動(dòng)性也越來(lái)越靈活[1]。上述情況的出現(xiàn)將會(huì)大大增加雷達(dá)數(shù)據(jù)處理的運(yùn)算量,而雷達(dá)數(shù)據(jù)處理系統(tǒng)作為一個(gè)實(shí)時(shí)系統(tǒng),必須在規(guī)定的時(shí)間內(nèi)計(jì)算出結(jié)果。這對(duì)數(shù)據(jù)處理的計(jì)算能力提出了很高的要求。
一直以來(lái),處理器芯片廠商通過(guò)不斷地提高主頻來(lái)提高處理器性能。但是,隨著芯片工藝的不斷進(jìn)步,傳統(tǒng)的處理器體系結(jié)構(gòu)技術(shù)已經(jīng)面臨瓶頸,晶體管的集成度已經(jīng)超過(guò)上億個(gè),很難單純地通過(guò)提高主頻來(lái)提升性能,而且主頻的提高同時(shí)也帶來(lái)功耗的增 加。從應(yīng)用需求來(lái)看,日益復(fù)雜的科學(xué)計(jì)算、多媒體、虛擬化等多個(gè)應(yīng)用領(lǐng)域都迫切需要強(qiáng)大的計(jì)算能力。在這樣的背景下,各處理器廠商將芯片從提高主頻轉(zhuǎn)向多核、多線程[2]。
目前,雷達(dá)數(shù)據(jù)處理系統(tǒng)普遍采用單核處理器時(shí)代的串行架構(gòu),不能充分利用多核處理器的計(jì)算資源,早已不適應(yīng)計(jì)算機(jī)技術(shù)的發(fā)展。本文基于多核處理器研究并行雷達(dá)數(shù)據(jù)處理架構(gòu)的可行性,以提高雷達(dá)數(shù)據(jù)處理計(jì)算性能。
1 并行處理介紹

圖1 多核處理器結(jié)構(gòu)
典型的多核處理器結(jié)構(gòu)如圖1所示[3-4],包含多個(gè)相同的處理器核,每個(gè)處理器核有自己的高速緩存,所有處理器核共享內(nèi)存資源。這種結(jié)構(gòu)屬于對(duì)稱(chēng)多處理器(Symmetric Multi-Processor,SMP)。
在SMP處理器結(jié)構(gòu)中,一般采用共享存儲(chǔ)并行編程模型,對(duì)需要并行的代碼段創(chuàng)建多線程進(jìn)行計(jì)算,線程之間通過(guò)共享內(nèi)存進(jìn)行通信。
由于線程共享同一進(jìn)程的內(nèi)存空間,多個(gè)線程可能會(huì)同時(shí)訪問(wèn)同一個(gè)數(shù)據(jù)。如果沒(méi)有正確的保護(hù)措施,對(duì)共享數(shù)據(jù)的訪問(wèn)會(huì)造成數(shù)據(jù)的不一致和錯(cuò)誤。
假設(shè)有一個(gè)共享變量counter 初始值為1,線程A執(zhí)行counter++,線程B 執(zhí)行counter--。這兩條語(yǔ)句實(shí)際是分別通過(guò)多條語(yǔ)句完成的:
線程A線程B
temp1=countertemp2=counter
temp1=temp1+1temp2=temp2-1
counter=temp1counter=temp2
兩個(gè)線程一種可能的執(zhí)行序列如下:
(1)線程A:temp1=counter(temp1=1)
(2)線程A:temp1=temp1+1(temp1=2)
(3)線程B:temp2=counter(temp2=1)
(4)線程B:temp2=temp2-1(temp2=0)
(5)線程A:counter=temp1(temp1=2)
(6)線程B:counter=temp2(temp2=0)
counter 正確的結(jié)果應(yīng)該為1,但在兩個(gè)線程交叉執(zhí)行時(shí)就可能出現(xiàn)0 或2的錯(cuò)誤結(jié)果。為了避免這種錯(cuò)誤的發(fā)生,在多個(gè)線程訪問(wèn)共享數(shù)據(jù)時(shí)需要進(jìn)行同步。常用的同步機(jī)制包括臨界區(qū)、信號(hào)量和互斥量,比較常用的同步方法是互斥量和信號(hào)量[2]。
作為一種互斥設(shè)備,互斥量有兩個(gè)狀態(tài):上鎖和空閑。在同一時(shí)刻只能有一個(gè)線程能夠?qū)コ饬考渔i。對(duì)于一個(gè)已經(jīng)加鎖的互斥量,當(dāng)另一個(gè)線程試圖對(duì)它加鎖時(shí),該線程會(huì)被阻塞,直到互斥量被釋放。
Linux 操作系統(tǒng)的IEEE POSIX 標(biāo)準(zhǔn)Pthreads 庫(kù)提供了互斥同步函數(shù)pthread_mutex_lock、pthread_mutex_unlock 等。
上述舉例通過(guò)互斥量同步機(jī)制可以得到正確的結(jié)果,如表1所示。假設(shè)線程A 首先獲得鎖。

表1 線程A和B的同步方法
并行算法(程序)執(zhí)行速度相對(duì)于串行算法(程序)執(zhí)行速度加快的倍數(shù)稱(chēng)為并行加速比[2]。假設(shè)Sp是加速比,T1是單處理器下的運(yùn)行時(shí)間,Tp是在有P個(gè)處理器并行系統(tǒng)中的運(yùn)行時(shí)間,則

并行程序的效率Ep為

當(dāng)Sp=P時(shí),加速比被稱(chēng)為線性加速比。在實(shí)際應(yīng)用中,由于線程間同步、通信等額外的開(kāi)銷(xiāo)導(dǎo)致Sp往往小于P。
2 數(shù)據(jù)處理流程分析
雷達(dá)數(shù)據(jù)處理系統(tǒng)接收到信號(hào)處理送來(lái)的點(diǎn)跡,一般按照?qǐng)D2所示流程進(jìn)行處理[5]。

圖2 數(shù)據(jù)處理流程
圖2所示的各個(gè)步驟是一個(gè)順序的過(guò)程,不能并行執(zhí)行。接下來(lái)對(duì)每個(gè)步驟進(jìn)行分析,判斷是否適合并行處理。
(1)點(diǎn)跡預(yù)處理
把點(diǎn)跡從目標(biāo)量測(cè)坐標(biāo)系轉(zhuǎn)換到數(shù)據(jù)處理所在坐標(biāo)系。該步驟是一個(gè)循環(huán)操作,每個(gè)循環(huán)對(duì)單個(gè)點(diǎn)跡進(jìn)行坐標(biāo)變換,循環(huán)之間沒(méi)有數(shù)據(jù)依賴(lài)關(guān)系,適合并行處理。
(2)數(shù)據(jù)互聯(lián)
建立當(dāng)前時(shí)刻新點(diǎn)跡與歷史數(shù)據(jù)之間的關(guān)系,以確定這些點(diǎn)跡是否來(lái)自同一個(gè)目標(biāo),分為新點(diǎn)跡與航跡的互聯(lián)、新點(diǎn)跡與舊點(diǎn)跡的互聯(lián)。數(shù)據(jù)互聯(lián)方法主要有極大似然類(lèi)算法和貝葉斯類(lèi)算法。常用的最近鄰域算法及其改進(jìn)算法屬于貝葉斯算法[5-6]。在最近鄰域算法中,根據(jù)每一個(gè)目標(biāo)的預(yù)測(cè)位置設(shè)置該目標(biāo)的跟蹤門(mén)(相關(guān)波門(mén))。每一個(gè)新點(diǎn)跡與所有航跡一一進(jìn)行相關(guān),判斷其是否落入目標(biāo)的跟蹤門(mén)內(nèi),如果落入該目標(biāo)的跟蹤門(mén)內(nèi)則形成點(diǎn)航配對(duì),并根據(jù)新點(diǎn)跡與預(yù)測(cè)位置的距離差設(shè)置該配對(duì)的相關(guān)度,每個(gè)新點(diǎn)跡可能與多個(gè)航跡配對(duì)成功,按照相關(guān)度從高到低選擇最優(yōu)點(diǎn)航配對(duì)[6]。點(diǎn)點(diǎn)配對(duì)方法與點(diǎn)航配對(duì)相同。每一個(gè)點(diǎn)跡與所有航跡一一進(jìn)行相關(guān)。該操作是循環(huán)操作,循環(huán)體之間沒(méi)有數(shù)據(jù)依賴(lài),能夠采用并行處理方法。
(3)航跡起始
航跡起始是目標(biāo)跟蹤的第一步,主要包括暫時(shí)航跡形成和軌跡確定。航跡起始可以劃分成多個(gè)獨(dú)立的子任務(wù)并行處理。
(4)跟蹤
根據(jù)數(shù)據(jù)互聯(lián)步驟中選擇的點(diǎn)航配對(duì),對(duì)來(lái)自每個(gè)目標(biāo)的新點(diǎn)跡進(jìn)行跟蹤處理。目前,經(jīng)常采用的目標(biāo)跟蹤方法有交互式多模型算法、Jerk 模型算法等。濾波算法多使用卡爾曼濾波[5-6]。交互多模型算法通過(guò)多個(gè)目標(biāo)模型的有效組合來(lái)實(shí)現(xiàn)對(duì)目標(biāo)機(jī)動(dòng)狀態(tài)的自適應(yīng)估計(jì)[5-7]。跟蹤是根據(jù)數(shù)據(jù)互聯(lián)步驟選擇的點(diǎn)航配對(duì),對(duì)每個(gè)航跡的更新操作,各個(gè)航跡更新操作之間沒(méi)有數(shù)據(jù)依賴(lài),可以并行處理。
(5)點(diǎn)跡與航跡維護(hù)
對(duì)每個(gè)點(diǎn)跡和航跡進(jìn)行維護(hù),刪除滿(mǎn)足條件的點(diǎn)跡和航跡。該步驟以單個(gè)點(diǎn)跡和航跡為單位進(jìn)行操作,各個(gè)點(diǎn)跡、航跡之間沒(méi)有數(shù)據(jù)依賴(lài),可以并行處理。
根據(jù)上述分析可知,5個(gè)步驟內(nèi)部均可以采用多個(gè)線程并行處理的方法,如圖3所示。由于各步驟之間必須順序執(zhí)行,因此需要在每個(gè)步驟執(zhí)行結(jié)束時(shí)設(shè)置柵障(barrier),對(duì)并行處理的多個(gè)子任務(wù)進(jìn)行同步。
3 實(shí)驗(yàn)結(jié)果分析
根據(jù)上述分析,對(duì)雷達(dá)數(shù)據(jù)處理系統(tǒng)進(jìn)行了并行架構(gòu)設(shè)計(jì)以及實(shí)驗(yàn)測(cè)試。實(shí)驗(yàn)環(huán)境為L(zhǎng)inux 2.6.32 操作系統(tǒng),Intel Xeon W3565 4 核處理器,6 GB 內(nèi)存。在實(shí)驗(yàn)中,仿真了2000 幀數(shù)據(jù),每幀模擬2000個(gè)目標(biāo),隨機(jī)產(chǎn)生20000個(gè)雜波點(diǎn)。
圖4 是并行數(shù)據(jù)處理系統(tǒng)執(zhí)行時(shí)間以及加速比統(tǒng)計(jì)。從圖中可以看出,隨著線程個(gè)數(shù)增加,執(zhí)行時(shí)間逐漸降低。單線程串行程序執(zhí)行時(shí)間為510 s,4 線程并行程序執(zhí)行時(shí)間降低到174 s,加速比接近3,數(shù)據(jù)處理系統(tǒng)性能得到了明顯提升。
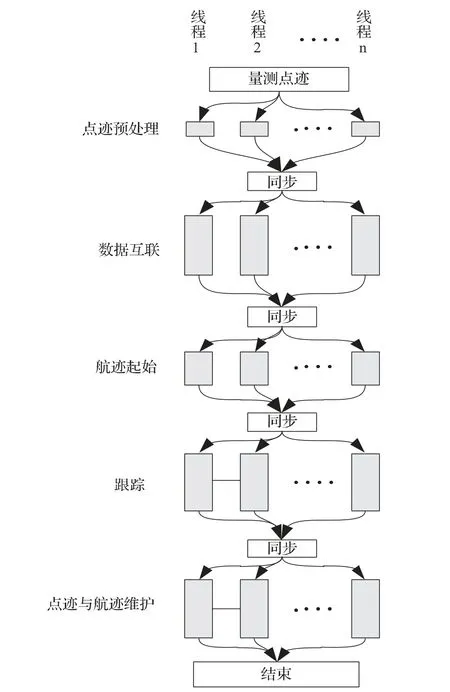
圖3 并行處理示意圖

圖4 并行運(yùn)算時(shí)間及加速比
根據(jù)第2節(jié)的分析可知,數(shù)據(jù)處理各個(gè)步驟均可以并行處理,因此4 線程并行程序加速比理論上應(yīng)達(dá)到4,效率應(yīng)達(dá)到1,而實(shí)驗(yàn)中4 線程并行程序的效率只有Ep=2.92/4=73%。接下來(lái)對(duì)并行加速比的損失進(jìn)行分析,圖5 是各個(gè)步驟執(zhí)行時(shí)間隨線程個(gè)數(shù)的變化情況。
點(diǎn)跡預(yù)處理、數(shù)據(jù)互聯(lián)、航跡起始和跟蹤中的數(shù)學(xué)操作易于劃分成多個(gè)子任務(wù)并行執(zhí)行,并且各個(gè)子任務(wù)之間數(shù)據(jù)依賴(lài)較少,增加線程數(shù)可以顯著的降低執(zhí)行時(shí)間。但是,由圖3 可知,每個(gè)步驟結(jié)束時(shí)都設(shè)置了barrier,只有等最慢的線程執(zhí)行結(jié)束時(shí)才會(huì)進(jìn)行下一個(gè)步驟,CPU 利用率達(dá)不到100%,因此加速比不能線性提升。

圖5 各步驟并行執(zhí)行時(shí)間統(tǒng)計(jì)
點(diǎn)跡與航跡維護(hù)主要是對(duì)共享數(shù)據(jù)結(jié)構(gòu)(如鏈表、堆等)的操作以及內(nèi)存的讀寫(xiě)。根據(jù)第2節(jié)的介紹可知,同時(shí)訪問(wèn)共享數(shù)據(jù)結(jié)構(gòu)會(huì)導(dǎo)致線程的阻塞,多個(gè)線程競(jìng)爭(zhēng)有限的內(nèi)存帶寬,每個(gè)線程實(shí)際利用帶寬都不高,因此點(diǎn)跡與航跡維護(hù)并行處理的效果不明顯。
4 結(jié)束語(yǔ)
未來(lái)日益復(fù)雜的電磁環(huán)境對(duì)雷達(dá)數(shù)據(jù)處理系統(tǒng)的計(jì)算能力要求將會(huì)非常高。為了提高數(shù)據(jù)處理的計(jì)算性能,本文基于多核處理器結(jié)構(gòu),對(duì)并行雷達(dá)數(shù)據(jù)處理架構(gòu)進(jìn)行了研究。從實(shí)驗(yàn)結(jié)果可知,并行處理架構(gòu)性能比傳統(tǒng)的串行系統(tǒng)有了明顯提升,在4 核處理器上,性能提高了將近3 倍。這表明雷達(dá)數(shù)據(jù)處理系統(tǒng)是適合并行處理的。但是,由于線程間同步、共享變量過(guò)多以及訪問(wèn)內(nèi)存競(jìng)爭(zhēng)激烈等原因,并行系統(tǒng)的效率沒(méi)有達(dá)到最優(yōu)。在未來(lái)的工作中,將針對(duì)上述問(wèn)題進(jìn)行深入研究,進(jìn)一步提高并行雷達(dá)數(shù)據(jù)處理系統(tǒng)的性能。
[1]俞志富,呂久明.基于航跡跟蹤的EKF 應(yīng)用研究[J].現(xiàn)代防御技術(shù),2007,35(2):113-117.
[2]多核系列教材編寫(xiě)組.多核程序設(shè)計(jì)[M].北京:清華大學(xué)出版社,2007.
[3]Franchetti F,Puschel M,Voronenko Y,Chellappa S,Moura J M F.Discrete fourier transform on multicore[J].IEEE Trans.on Signal Processing Magazine,2009,26(6):90-102.
[4]Hu Weiwu,Wang Jian,Gao Xiang.Godson-3:A Scalable Multi-core RISC Processor with X86 Emulation Support[J].IEEE Trans.on Micro,2009,29(2):17-29.
[5]何友,修建娟,張晶煒,等.雷達(dá)數(shù)據(jù)處理及應(yīng)用[M].2 版.北京:電子工業(yè)出版社,2009.
[6]蔡慶宇,張伯彥,曲洪權(quán).相控陣?yán)走_(dá)數(shù)據(jù)處理教程[M].北京:電子工業(yè)出版社,2011.
[7]Averbuch A,Bar-Shalom Y,Dayan J.Interacting multiple model methods in target tracking:a survey[J].IEEE Trans.on Aerospace and Electronic Systems,1998,34(1):103-123.
猜你喜歡
中學(xué)生數(shù)理化·自主招生(2022年9期)2022-05-30 10:48:04
心理學(xué)報(bào)(2022年4期)2022-04-12 07:38:02
水泵技術(shù)(2021年3期)2021-08-14 02:09:20
電子測(cè)試(2018年4期)2018-05-09 07:28:12
當(dāng)代化工研究(2016年9期)2016-03-20 16:22:13
中國(guó)慣性技術(shù)學(xué)報(bào)(2015年1期)2015-12-19 13:12:17
計(jì)算機(jī)工程(2015年4期)2015-07-05 08:28:04
西華師范大學(xué)學(xué)報(bào)(自然科學(xué)版)(2015年3期)2015-02-27 15:31:22
聯(lián)合國(guó)青年技術(shù)培訓(xùn)(2014年7期)2014-04-12 00:00:00
中國(guó)質(zhì)量與標(biāo)準(zhǔn)導(dǎo)報(bào)(2014年7期)2014-02-28 22:24:35
