基于預測極性動態變換的分支預測框架研究
2013-05-27 08:47:16陳志堅孟建熠嚴曉浪
電子與信息學報 2013年4期
陳 晨 陳志堅 孟建熠 嚴曉浪
(浙江大學超大規模集成電路設計研究所 杭州 310027)
1 引言
隨著高端嵌入式應用對處理器的性能要求越來越高,超深流水線、超標量、多指令發射等技術紛紛應用于高端嵌入式處理器設計中。高效準確的分支預測框架是上述技術潛能得到發揮的前提和基礎[1]。基于神經網絡的分支預測方法[2,3]具有很高的分支預測精度,但神經網絡算法復雜度高,資源消耗大,不適合于嵌入式應用。當前高端嵌入式應用中廣泛采用的分支預測方法為二級自適應分支預測方法[4],該方法將分支指令地址和分支歷史信息進行組合,從分支模式表中索引得到分支預測結果。分支模式表為每個動態運行的分支指令分配一個分支預測器[5],預測器通過訓練記錄對應分支指令最近的分支跳轉信息,為分支指令再次執行提供預測信息。
分支預測錯誤的主要原因是破壞性分支重名[6,7],因此很多研究將重點放在減小破壞性分支重名概率上。文獻[8]改變分支模式表中預測器的表征意義,表征的內容由原本的分支跳轉方向改變為分支跳轉方向是否和分支目標緩存器(BTB)中的偏置比特一致,該方法減小了破壞性分支重名概率,其缺點是需要結合BTB協同工作,設計復雜度高。文獻[9]將分支模式表分為一個跳轉型子表和一個非跳轉型子表,再增設一個選擇模式表來決定使用哪個子表的預測結果,該方法使每個子表中發生破壞性分支重名的概率降低,缺點是該方法基于兩次預測的疊加,一定程度上增加了預測不確定性。文獻[10,11]在TAGE分支預測方法[12]的基礎上增加輔助預測器,彌補主預測器針對特定應用的不適應性,解決了包括破壞性分支重名在內的多種影響分支預測精度的因素,但該方法硬件資源耗費很大。文獻[13]通過設立錯誤分支表來記錄預測錯誤分支指令的地址和間距,通過計數機制探測預測錯誤分支指令并對其進行糾正,從而消除分支預測錯誤,但該方法同樣基于兩次預測的疊加,增加了預測不確定性。
本文結合程序局部性原理,從研究分支預測錯誤的行為特征出發,針對分支預測錯誤在時間上的局部性分布規律,提出一種通過動態調整分支預測器預測內容從而降低預測錯誤率的分支預測方法。該方法對未經極性變換的原始分支預測結果進行采樣,并以分支預測錯誤率50%為閾值進行研究,定義原始動態分支預測錯誤率高于該閾值的局部時間段為預測錯誤高峰期。動態監測預測錯誤高峰期的出現,并實時變換預測錯誤高峰期內分支預測器的預測極性,即原本預測跳轉的變換為預測不跳轉,反之亦然。本文通過實時監測預測錯誤高峰期并動態調整預測極性,降低了經過極性變換的最終動態分支預測錯誤率,提高了分支預測的穩定性與整體效率。
本文提出的方法與上述相關工作的區別在于:對比于文獻[8,9],本文提出的方法不以減小破壞性分支重名的概率為目的,而是通過研究分支預測錯誤本身的行為特征進而提高分支預測精度,因而可以針對包括破壞性分支重名在內的所有導致分支預測錯誤的因素進行優化;對比于文獻[10,11],本文提出的方法沒有采用輔助預測器,因而在硬件資源上具有更高的利用效率;對比于文獻[13],本文通過動態地監測分支預測錯誤率,采用自適應的監測機制探測預測錯誤高峰期,因而具有更好的實時性。
2 分支預測錯誤的時間局部性分析
根據程序局部性原理,一部分代碼會在短時間內被反復執行,這部分代碼稱為程序熱點。不同程序熱點的交替執行占據了整個程序的大部分運行時間。一旦程序熱點中存在破壞性分支重名等特殊的分支行為,則會導致程序在短時間內集中出現大量分支預測錯誤。本文以嵌入式測試基準程序Powerstone[14]作為目標程序對分支預測錯誤行為進行分析。表1是基準程序的簡單介紹。
采用二級自適應分支預測方法對目標程序進行分支預測,分析程序運行過程中分支預測錯誤的行為特征。分支模式表共有213個分支預測器,以單個分支預測器為研究對象,分別對213個預測器進行動態監測。對于每個預測器,選取時間上連續10次訪問作為一個局部監測時間段,實時統計該時間段內的動態分支預測錯誤率;同時統計程序運行結束后該預測器整體的靜態分支預測錯誤率。為了保證有足夠的分支預測錯誤次數以便分析其行為特征,將每個目標程序運行過程中發生分支預測錯誤次數最多的預測器作為研究樣本,并選取各個樣本在程序運行過程中發生分支預測錯誤較多的一段時間進行預測錯誤行為分析。圖1是每個研究樣本在選取時間內的分支預測錯誤率,本文將圖中所示未經極性變換的分支預測錯誤率定義為原始分支預測錯誤率(包括動態和靜態),同時將原始動態分支預測錯誤率高于 50%(閾值)的時間段定義為預測錯誤高峰期。從圖中可以看出各個目標程序中研究樣本的動態分支預測錯誤率以靜態分支預測錯誤率為界限上下抖動,無論靜態分支預測錯誤率高或低,都會多次出現動態分支預測錯誤率高于 50%(閾值)的時間段,即預測錯誤高峰期。在圖中未顯示的其余大部分時間段中,分支預測錯誤次數相對較少,也較少出現預測錯誤高峰期。因此預測錯誤高峰期具有集中出現的特點。
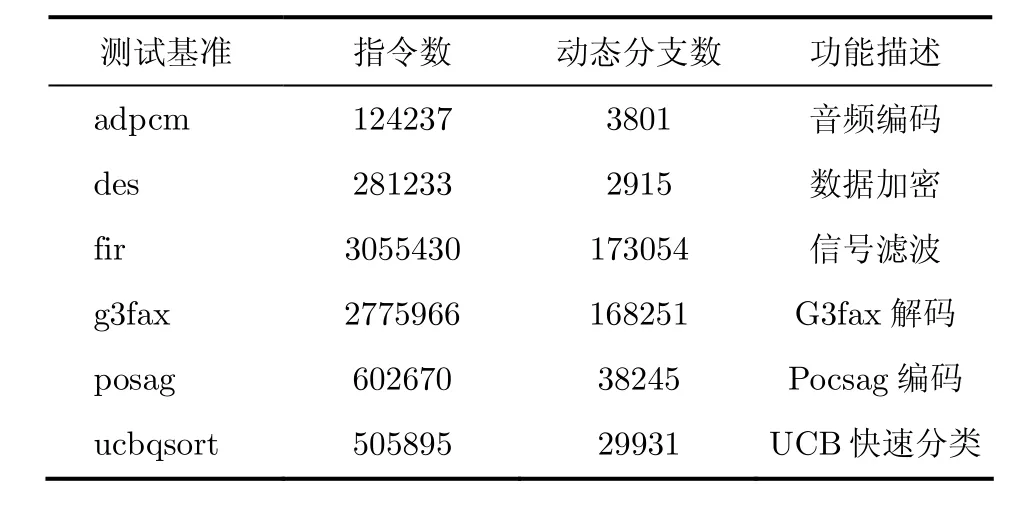
表1 Powerstone測試基準程序簡介
通過對比分析分支模式表中除研究樣本以外的其他分支預測器,發現上述預測器研究樣本的分支預測錯誤行為具有普遍意義,表現為:對于各個預測器,在未經極性變換的情況下,在程序運行過程中動態分支預測錯誤率在時間上分布不均勻,并以靜態分支預測錯誤率為界限抖動,另外,無論該預測器靜態分支預測錯誤率高或低,預測錯誤高峰期都容易在一段時間內集中出現。即分支預測錯誤具有時間上的局部性。
3 預測極性動態變換分支預測框架
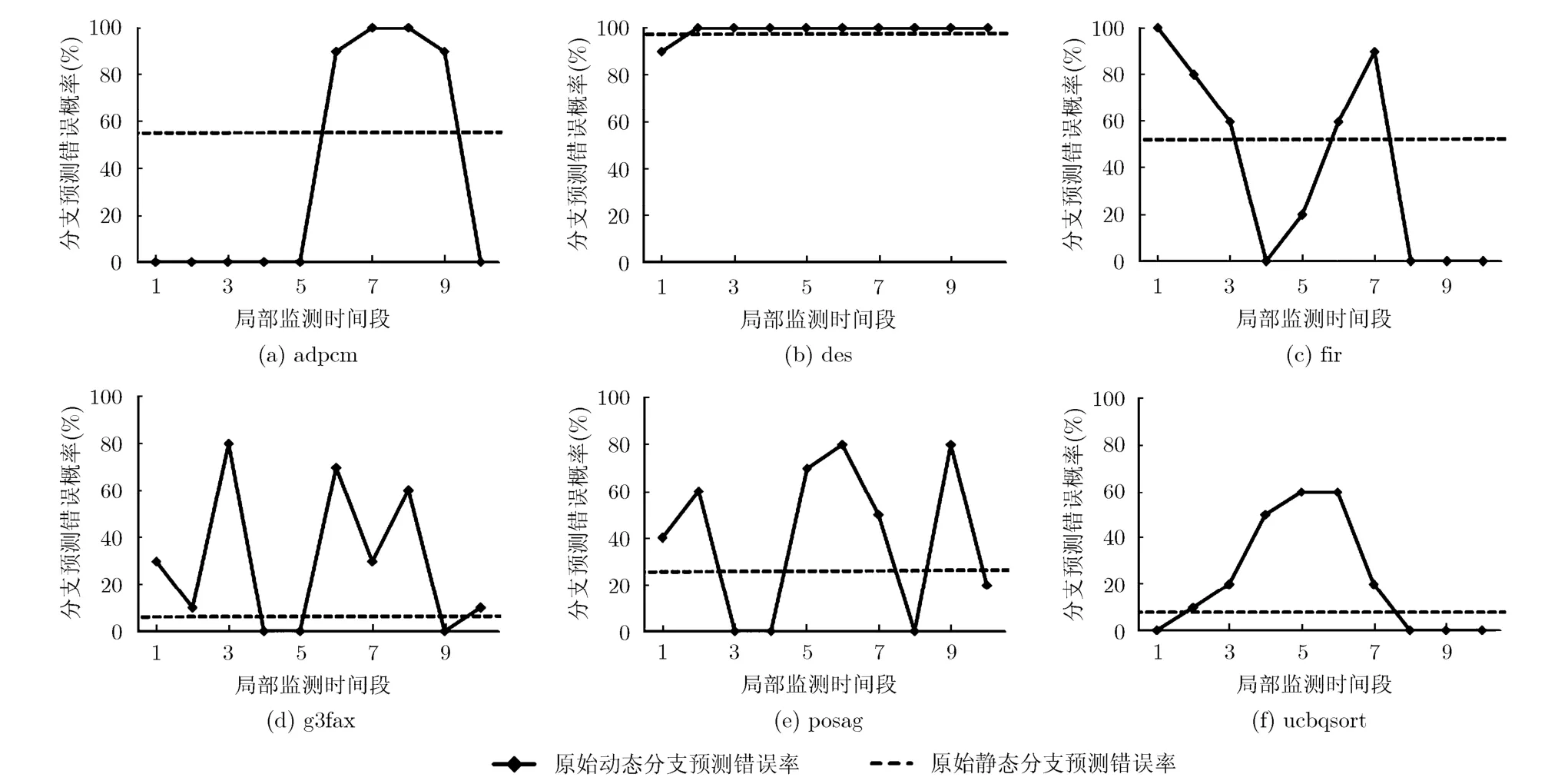
圖1 分支預測錯誤的時間局部性
根據分支預測錯誤的時間局部性,本文提出一種基于預測極性動態變換的分支預測方法。本方法的核心思想是:對未經極性變換的原始分支預測錯誤率進行自適應監測,篩選出程序運行過程中原始動態分支預測錯誤率高于50%的預測錯誤高峰期,將預測錯誤高峰期內的預測極性進行變換,即原本預測跳轉的變換為預測不跳轉,反之亦然,使得經過極性變換的最終動態分支預測錯誤率在程序運行過程中始終保持在50%以下,減小最終動態分支預測錯誤率抖動幅度,降低整體分支預測錯誤率。
基于預測極性動態變換的分支預測方法中,最基本的硬件單元是預測錯誤高峰期監測器。預測錯誤高峰期會根據具體應用和輸入數據不同而動態出現。本文通過自適應的動態監測機制來判斷預測錯誤高峰期,監測器通過狀態機控制。一種狀態機的狀態轉換圖如圖2所示。圖中C(Correct)表示未經極性變換的原始分支預測結果(即預測器自身)和正確分支跳轉結果一致,M(Mismatch)表示未經極性變換的原始分支預測結果和正確分支跳轉結果不一致。初始狀態為IDLE,每當確認C發生后,直接越過相鄰狀態跳轉到下一個狀態,例如從 M4到M2,從M2到IDLE等;每當確認M發生后,跳轉到相鄰狀態,例如從C3到C2,從M1到M2等;程序運行過程中,處于圖2虛線左側狀態(M3, M4)的時刻均為預測錯誤高峰期。此狀態機的運行方式加強了C發生的影響權重,這便于篩選出預測錯誤率較高(例如 90%)的預測錯誤高峰期。這樣的設計更利于整體性能的提高,因為對于預測錯誤率較低(例如 60%)的預測錯誤高峰期,由于動態監測機制本身具有一定的誤差性,若強行對預測器進行極性變換,往往達不到理想效果。
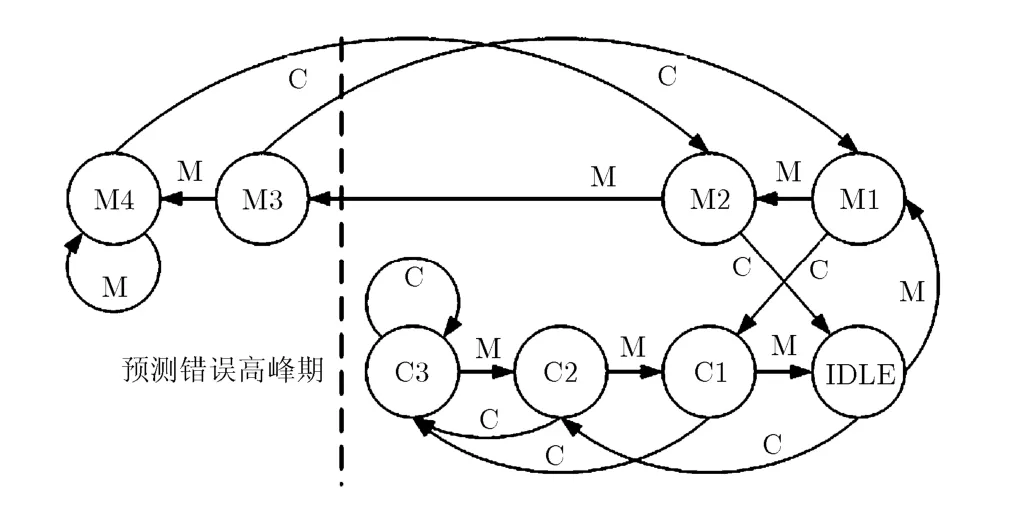
圖2 監測器狀態轉換圖
基于預測極性動態變換的分支預測框架的一種實現如圖3所示,預測電路由分支模式表、監測器表和數據選擇器組成。分支模式表由分支預測器構成;監測器表由圖2所示的狀態機構成。分支歷史信息和分支指令地址進行異或操作后得到索引值,從分支模式表中讀出一個分支預測器的值作為原始分支預測結果;同時用該索引值的一部分索引監測器表,從中讀出一個狀態機的狀態作為數據選擇器的選通信號,根據該狀態決定最終分支預測結果:若狀態顯示處于預測錯誤高峰期,則將原始分支預測結果的極性變換后作為最終分支預測結果,反之則直接將原始分支預測結果作為最終分支預測結果。
監測器表中的狀態機在分支預測信息被后級流水線確認后被更新,每次僅更新被確認分支指令所對應的狀態機,根據原始分支預測結果是否與正確分支跳轉結果一致對狀態進行轉換,狀態轉換方式如圖2所示。分支模式表中的預測器僅當其輸出的原始分支預測結果與正確分支跳轉結果不一致時被更新為正確分支跳轉結果。
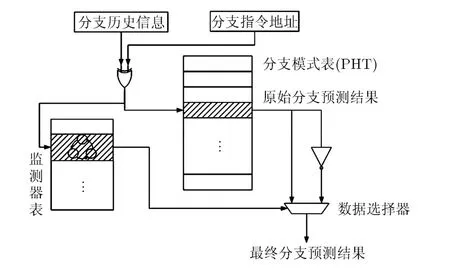
圖3 基于預測極性動態變換的分支預測框架結構
基于預測極性動態變換的分支預測方法按照監測方式不同可以分為:全局監測(GM),按組監測(SM)和局部監測(PM)3種類型。各種類型的結構如圖4所示。對于全局監測,整個分支模式表對應一個監測器,該監測器負責篩選出全局的預測錯誤高峰期。對于局部監測,分支模式表中每個預測器都對應一個監測器,各監測器負責篩選出對應于各預測器的預測錯誤高峰期。全局監測的監測粒度較粗,對預測錯誤高峰期的探測靈敏度低,但只需要一個監測器,硬件資源耗費極小,而局部監測的監測粒度更細,對預測錯誤高峰期的探測靈敏度更高,但監測器的數量需要和預測器一致,硬件資源耗費很大。按組監測是上述兩種方式的折中,將分支模式表分為若干組,每組對應一個監測器,負責篩選出該組預測器對應的預測錯誤高峰期。此方式在監測靈敏度和硬件資源上相對比較平衡。
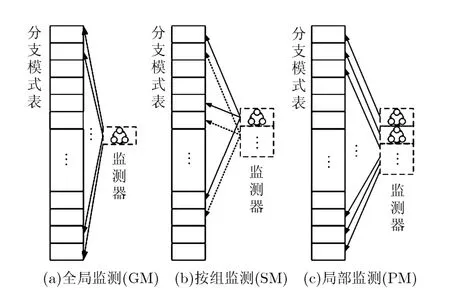
圖4 3種監測方式結構
4 實驗結果
本文以國產32位高性能嵌入式處理器CK610[15]及其平臺為基礎,分別實現本文提出的基于預測極性動態變換的分支預測方法和現有的 Gshare以及Bi-Mode分支預測方法,以Powerstone測試基準程序作為目標程序。先分析預測極性動態變換分支預測方法自身幾種監測方式的適用性,然后分析使用該方法后最終動態分支預測錯誤率的下降情況,最后給出該方法與Gshare以及Bi-Mode分支預測方法的綜合預測錯誤率比較結果。
首先對預測極性動態變換分支預測方法自身的幾種監測方式進行比較,圖5表示3種監測方式在各種硬件資源配置下對于目標程序的平均預測錯誤率。當硬件資源很小時(對應于圖5中小于4 kbit),全局監測最優;當硬件資源增加后(對應于圖5,在8 ~256 kbit之間),按組監測最優;而當硬件資源進一步增加(對應于圖5中大于256 kbit),局部監測最優。其原因在于,對于不同的監測方式,監測器所消耗的資源不同,因此分配到分支模式表上的資源也不同。當硬件資源很小,分支模式表的容量問題成為影響分支預測精度的最主要因素,全局監測可用于分支模式表的硬件資源最多,因此可獲得相對較好的分支預測結果;隨著硬件資源的增加,分支模式表的容量問題得到緩解,但對于局部監測來說,每個預測器都需要一個對應的監測器,可用于分支模式表的硬件資源仍然有限,而按組監測則在分支模式表和監測器的硬件資源分配上取得了較好的平衡,因此可獲得最好的分支預測結果;當硬件資源繼續增加達到一定程度后,分支模式表的容量對分支預測精度的影響進一步減小,具有最高監測靈敏度的局部監測方式將獲得最好的分支預測結果。現階段嵌入式處理器中分支預測可接受的硬件資源約在64 kbit以內,從圖5中可以看出按組監測方式在此區間內是最優的。
為了檢驗經過極性變換的最終動態分支預測錯誤率低于未經極性變換的原始動態分支預測錯誤率,采用預測極性動態變換分支預測方法對第2節所研究的分支預測錯誤率重新進行監測,研究樣本和監測時間段均和圖1保持一致,局部監測時間段也和圖1保持一致,即選取時間上連續10次訪問作為一個局部監測時間段。采用按組監測方式,分支模式表包含 213個分支預測器,使用 29個監測器,監測器狀態轉換采用圖2所示方式。圖6顯示了各目標程序中原始動態分支預測錯誤率和最終動態分支預測錯誤率的比較情況,可以看出,通過極性變換,最終動態分支預測錯誤率在整體上明顯低于原始動態分支預測錯誤率。

圖5 3種監測方式預測錯誤率比較

圖6 最終動態分支預測錯誤率下降情況
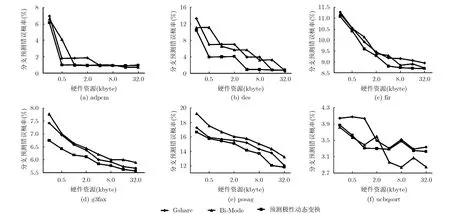
圖7 預測極性動態變換分支預測方法和其他分支預測方法的預測錯誤率比較
圖7顯示了預測極性動態變換分支預測方法與Gshare以及 Bi-Mode分支預測方法在各目標程序中分支預測錯誤率的比較情況。預測極性動態變換分支預測方法采用按組監測方式,當硬件資源小于1 kbyte時,分支模式表占用7/8的硬件資源,監測器表占用1/8的硬件資源;當硬件資源大于1 kbyte時,分支模式表占用3/4的硬件資源,監測器表占用1/4的硬件資源。監測器狀態轉換采用圖2所示方式。從圖中可以看出,對于大部分目標程序,預測極性動態變換分支預測方法均優于 Gshare和Bi-Mode分支預測方法,只有 ucbqsort程序中,Bi-Mode分支預測方法在特定硬件資源下產生最優的預測精度。另外,預測極性動態變換分支預測方法的預測精度優勢會在一定區間內達到最大值,但隨著硬件資源的增加,精度優勢會逐漸減弱,對于adcpm, des這兩個目標程序來說,當達到一定硬件資源時,3種分支預測方法的預測精度基本一致。其原因是,預測極性動態變換分支預測方法是以篩選出預測錯誤高峰期為基礎的,隨著硬件資源增加,未經極性變換的原始分支預測錯誤率自身便會達到很低的水平,從而使得程序運行過程中出現的預測錯誤高峰期數量減少,各個預測錯誤高峰期自身的預測錯誤率也會降低,這給預測極性動態變換帶來了困難。這也解釋了為何ucbqsort程序中Bi-Mode分支預測方法產生最優的預測精度,因為該程序未經極性變換的原始分支預測錯誤率已經很低。
5 結束語
本文通過研究程序運行過程中分支預測錯誤的行為特點,提出一種基于預測極性動態變換的分支預測方法。該方法監測未經極性變換的原始動態分支預測錯誤率,篩選出程序運行過程中的預測錯誤高峰期,將高峰期內預測器的預測極性進行變換后作為最終分支預測結果,從而降低經過極性變換的最終分支預測錯誤率。根據預測錯誤率監測方式不同可進一步分為全局監測、按組監測和局部監測 3種類型,在分支預測精度和硬件成本之間取得平衡。該方法可以滿足高性能嵌入式處理器在可控成本內實現高精度分支預測的要求。
[1] Hennessy J and Patterson D. Computer Architecture: A Quantitative Approach[M]. Fifth Edition, Beijing: China Machine Press, 2012: 162-167.
[2] Jiménez D. An optimized scaled neural branch predictor[C].2011 IEEE 29th International Conference on Computer Design (ICCD), Amherst, 2011: 113-118.
[3] Jiménez D. Oh-snap: optimized hybrid scaled neural analog predictor[C]. Proceedings of the 3rd Championship on Branch Prediction, Detroit, 2011: 9-12.
[4] Yeh T and Patt Y. Two-level adaptive training branch prediction[C]. Proceedings of the 24th Annual International Symposium on Microarchitecture, New York, 1991: 51-61.
[5] Zhang Long, Tao Fang, and Xiang Jin-feng. Researches on design and implementations of two 2-bit predictors[J].Advanced Engineering Forum, 2011, 1(1): 241-246.
[6] Young C, Gloy N, and Smith M. A comparative analysis of schemes for correlated branch prediction[C]. Proceedings of the 22nd Annual International Symposium on Computer Architecture, New York, 1995: 276-286.
[7] Talcott A, Nemirovsky M, and Wood R. The influence of branch prediction table interference on branch prediction scheme performance[C]. Proceedings of the 3rd Annual International Conference on Parallel Architectures and Compilation Techniques, Manchester, 1995: 89-98.
[8] Sprangle E, Chappell R, Alsup M,et al.. The agree predictor:a mechanism for reducing negative branch history interference[C]. Proceedings of the 24th Annual International Symposium on Computer Architecture, New York, 1997:284-291.
[9] Lee C, Chen I, and Mudge T. The bi-mode branch predictor[C]. 30th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO,97), Research Triangle Park, NC,1997: 4-13.
[10] Seznec A. A 64 kbytes ISL-TAGE branch predictor[C].Proceedings of the 3rd Championship Branch Prediction,Detroit, 2011: 13-16.
[11] Seznec A. A new case for the TAGE branch predictor [C].Proceedings of the 44th Annual IEEE/ACM International Symposium on Microarchitecture, New York, 2011: 117-127.
[12] Seznec A and Michaud P. A case for (partially)-tagged geometric history length predictors[J].Journal of Instruction Level Parallelism, 2006, 8(1): 1-23.
[13] Sendag R, Yi J, and Chuang Peng-fei. Branch misprediction prediction: complementary branch predictors[J].Computer Architecture Letters, 2007, 6(2): 49-52.
[14] Scott J, Lea H, Arends J,et al.. Designing the low-power M*CoreTM architecture[C]. Proceedings of IEEE Power Driven Microarchitecture Workshop, Barcelona, 1998:145-150.
[15] Meng Jian-yi. C-SKY microsystems, 32-bit high performance and low power embedded processor[OL]. http://www.c-sky.com, 2012, 5.
