多類分類預選取的SVM 在語音識別中的應用
2013-02-22 08:11:00賀元元張雪英劉曉峰
計算機工程與應用 2013年7期
關鍵詞:實驗
賀元元,張雪英,劉曉峰
1.太原理工大學 信息工程學院,太原030024
2.太原理工大學 理學院 數學系,太原030024
1 引言
語音識別技術是人機交互的基礎,隨著計算機科學技術的發展,語音識別技術取得顯著進步,逐漸開始從實驗室走向市場。支持向量機作為一種新型的模式識別方法,是建立在統計學習理論的VC維理論和結構風險最小原理[1-2]基礎上的,已經成功地運用到語音識別中。但是隨著語音識別系統規模的增加,支持向量機算法復雜度隨著所求解二次規劃問題規模的增大呈指數增長,且計算量大,訓練速度慢,其不適宜大規模數據問題的應用,已成為影響支持向量機發展的主要因素。
訓練樣本的支持向量(SV)預選取能夠將訓練樣本中對支持向量機所構造的判決函數有貢獻的樣本數據篩選出來。最近幾年來,人們對支持向量機中樣本預選取的關注越來越多,并提出了很多簡便有效的方法[3]。本文提出了基于核模糊C 均值聚類的樣本預選取算法,并且運用到語音識別中。本文方法減小了訓練樣本的規模,使得訓練時間得到了明顯的減少,進而增加了支持向量機的分類效率。
2 非線性支持向量機
對于非線性分類問題,給定訓練集T={(x1,y1),(x2,y2),…,(xl,yl)}∈(Rn×Y)l,其中引入核函數K(xi,xj)以及懲罰參數C >0,構造并求解凸二次規劃問題:
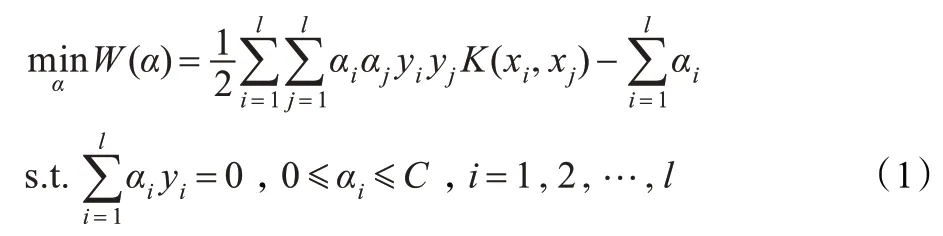
構造決策函數為:
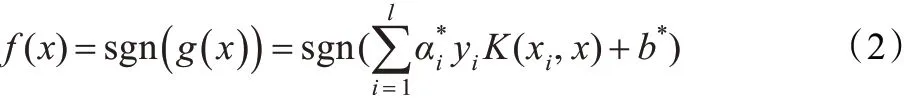
從決策函數表達式(2)可以看出,不是所有的訓練樣本都起作用,而只有對應于上述二次規劃問題的解α*的分量非零的那部分訓練樣本對決策函數起作用[4],即:只有支持向量對應的訓練樣本對決策函數有貢獻。
3 核模糊C 均值聚類樣本預選取算法
3.1 核模糊C 均值聚類
FCM(模糊C 均值聚類)算法是由硬C-均值(Hard C-Means,HCM)算法演化而來的,它基于誤差平方和目標函數準則,是一種常用的典型動態聚類算法。KFCM 算法把聚類歸結成一個帶約束的非線性規劃問題,通過優化并求解獲得數據集的模糊劃分和聚類。文獻[5]介紹了基于核函數的模糊C 均值聚類算法,其主要原理就是將常用的模糊C均值聚類算法中的歐式距離的計算用核模型來取代。
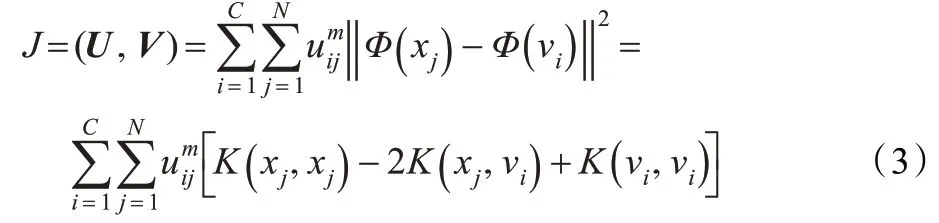
式中,U 為C×N 的隸屬度矩陣;V 為聚類中心矩陣;m 為權重系數(一般取為2);K( x,y )為核函數。
根據拉格朗日乘數法可求得uij和vi為:
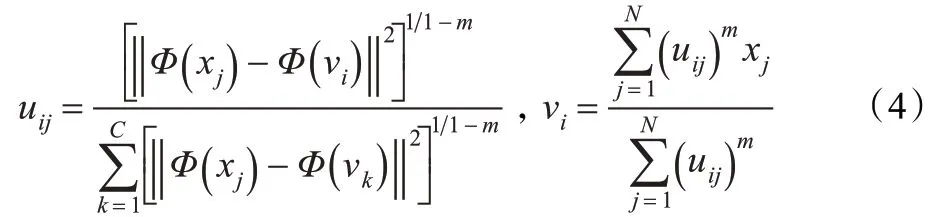
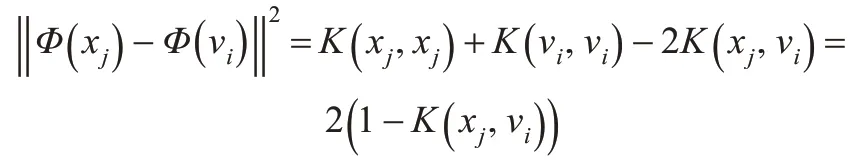
將上式帶入式(3)和式(4)中,可以得到目標函數:
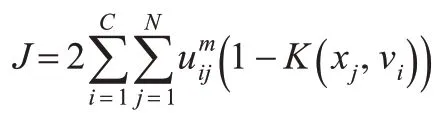
KFCM 算法增加了模式的線性可分概率,即擴大模式類之間的差異,在高維特征空間達到線性可聚的目的。樣本點隸屬于某一類的程度是用隸屬度來反映的,不同的樣本點以不同的隸屬度屬于每一類。
3.2 支持向量機的樣本預選取算法
通過KFCM 算法,可以得到樣本中所有類別的聚類中心V 。根據支持向量機的多類分類算法中一對一方法[9]的思路,可以把所有的C 個聚類中心任意的兩個分為一組。分別求出所有樣本點到每一組內兩個聚類中心的距離,對于任一組聚類中心有:
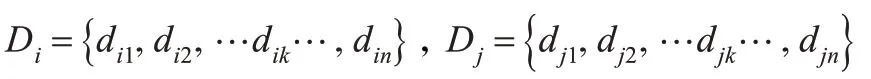
然后求出|Di-Dj|,若其中| dik-djk|<ε(ε 為一個閾值),說明該樣本點在兩個聚類中心的邊界附近,可能屬于支持向量樣本,則標記該樣本點;反之,該樣本在聚類中心點附近,則不標記該樣本點。依次重復循環,分別求出所有的聚類中心的組合中屬于兩個聚類中心之間附近的樣本點。
最后按照一個準則:分別把樣本集中屬于同一類的樣本數據取出,再把各類中的樣本點按照其出現的次數由大到小排序,然后根據各類中所取樣本的數量占該類樣本總數的比例α(0 <α <1) 來決定每類中所保留樣本的最后個數,由此得到所要選取的樣本。
算法的流程圖如圖1 所示。

圖1 KFCM 預選取算法流程圖
本文算法旨在通過聚類的方法,把訓練樣本中可能屬于支持向量的樣本點,按照前文的方法取出來。算法對訓練樣本集中的所有樣本都通過核函數把模式空間的數據非線性映射到高維特征空間中,增加了模式的線性可分概率,同時可以除去樣本集中的一些野點數據的影響,從而提高支持向量機模型的穩定性及分類性能。
4 實驗結果與分析
本實驗選取了一個小詞匯量的非特定人韓語語音庫,該語音庫在實驗室環境下由16 人分別對50 個詞進行錄音,每人每個詞發音3 次,選取其中9 人在詞匯量分別為10詞、20 詞、30 詞、40 詞、50 詞的數據為訓練樣本;同樣測試樣本為剩余7 人在各詞匯量下的數據。錄音的采樣率為11.025 kHz,然后把采樣系統得到的語音音頻文件作為實驗樣本,語音中所加的噪聲為高斯白噪聲,分別在信噪比為25 dB、0 dB 和無噪聲語音的情況下進行實驗。原始語音樣本經過MFCC(Mel 頻率倒譜系數)特征提取得到特征樣本數據,MFCC 特征提取的幀長N為256 點,幀移M為128 點。
實驗過程先用本文提出的樣本預選取算法對訓練樣本進行處理,然后再經過支持向量機進行訓練并預測識別結果。支持向量預選取的實驗參數在人工條件下,經過反復多次實驗取得一組合理的參數,取高斯核函數的參數b=91,距離差的冗余度ε=1-4。支持向量機選用Libsvm-2.9程序包,其中核函數均選RBF 核函數,懲罰參數和核參數采用網格搜索法,求得最優值為:C=32,γ=0.000 122 07。實驗環境:CPU 為Intel?CoreTM2 Duo 2.2 GHz,內存為2 GB;操作系統為Windows XP-SP2;在軟件平臺為Matlab 7.0。

表1 SNR=25 dB 時預選取的實驗結果比較
本實驗由3 部分組成:
(1)原始訓練樣本集直接用標準SVM 進行實驗;
(2)當α=0.75 時,即:選取原訓練樣本集中每一類樣本個數的75%,用本文方法進行實驗;
(3)當α=0.50 時,即:選取原訓練樣本集中每一類樣本個數的50%,用本文方法進行實驗。
在信噪比分別為25 dB、0 dB 和無噪聲語音的情況下,逐個對10 詞、20 詞、30 詞、40 詞、50 詞的訓練樣本按照上述的3 部分進行對比實驗,其中的時間是重復3 次取平均值得到的。實驗結果如表1和圖2,表2和圖3,表3和圖4所示。

圖2 SNR=25 dB 時表1 中的訓練時間比較
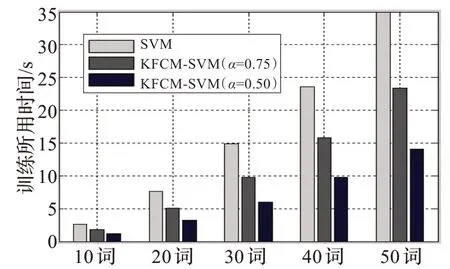
圖3 SNR=0 dB 時表2 中的訓練時間比較
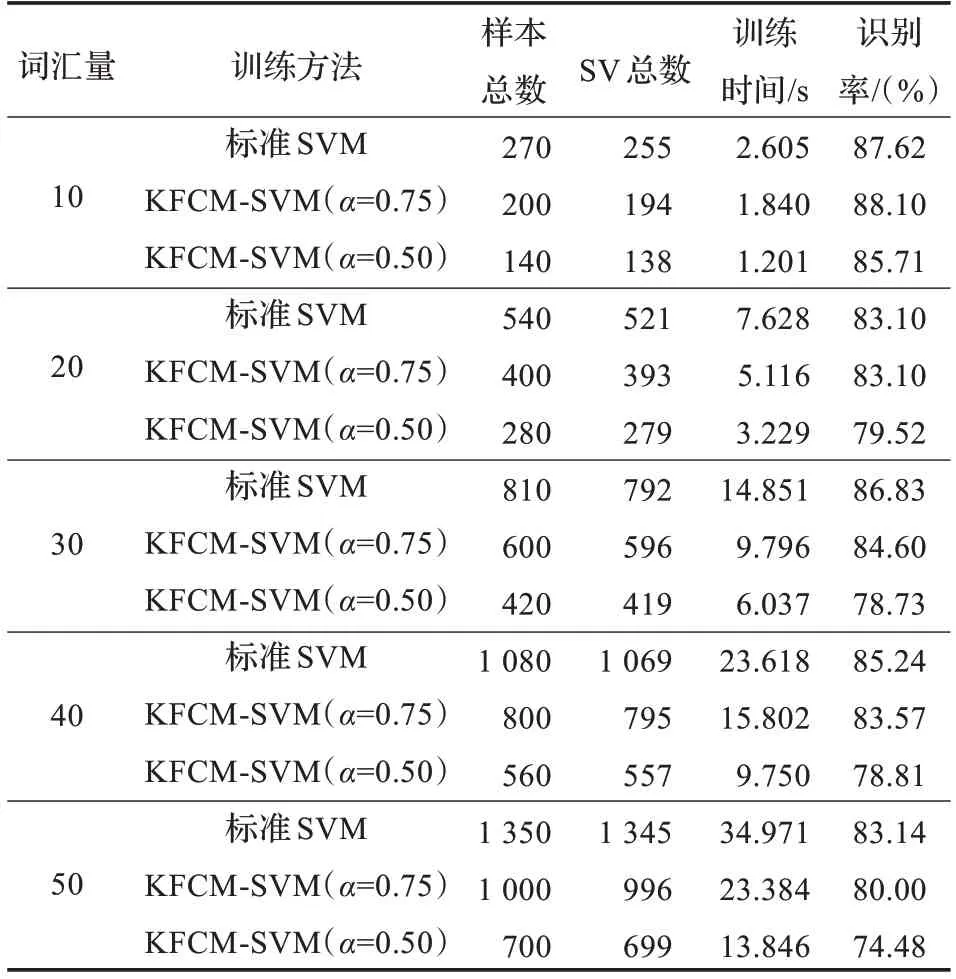
表2 SNR=0 dB 時預選取的實驗結果比較

表3 無噪聲語音時預選取的實驗結果比較

圖4 無噪聲語音時表3 中的訓練時間比較
從以上實驗結果可以得到,經過預選取的訓練樣本的支持向量總數明顯減少,在不同信噪比的情況下,隨著詞匯量的增加,支持向量機的訓練時間隨之增加,同時預測樣本的識別率有所減小,在信噪比為0 dB 時,由于噪聲較強,故識別率受到一定的影響但均保持在較高的水平。運用本文的算法進行訓練,當α=0.75 時,在各個信噪比下識別率保持不變或隨詞匯量增加識別率略受影響,而訓練時間明顯減少,說明此時所選的支持向量數對分類機的性能影響并不大,識別率仍然很接近;當α=0.50 時,訓練樣本集的識別率隨著詞匯量越大和信噪比的減小有所降低,但是從圖2、圖3、圖4 可以很直觀地看出,預選取后的訓練時間大大減少,其中最大的減少了原時間的60.40%,取得了較為滿意的實驗結果。
5 總結
本文基于核模糊C均值聚類提出了一種樣本預選取算法,并且在語音識別上進行了應用。該算法目的是把支持向量機訓練過程中對計算構建最優分類超平面貢獻大的樣本點篩選出來,然后把這些樣本數據組成一個新的訓練樣本集,這樣刪減了冗余的樣本點,從而使得訓練時間得以減少,提高了效率。從實驗結果可以看出,隨著信噪比的減小和詞匯量的增加,訓練時間逐漸變長,識別率幾乎保持穩定,實驗的效果在某種程度上受到了所選參數的制約,通過參數的優化將會提高算法的性能;另外,當訓練樣本中的冗余樣本點較多時,本文方法的效果將會更加顯著。運用本文方法進行樣本預選取后的訓練樣本集在保證分類精度的前提下,訓練時間明顯減少,從而得到了較為理想的支持向量樣本預選取效果。
[1] Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995:77-79.
[2] 張學工.關于統計學習理論與支持向量機[J].自動化學報,2000,26(1):32-42.
[3] 韓德強,韓崇昭,楊藝.基于k-最近鄰的支持向量預選取方法[J].控制與決策,2009,24(4):494-498.
[4] 鄧乃揚,田英杰.支持向量機——理論、算法與拓展[M].北京:科學出版社,2009:97-101.
[5] Zhang D Q,Chen S C.Kernel-based fuzzy clustering incorporating spatial constraints for image segmentation[C]//Proceedings of the 2nd International Conference on Machine Learning and Cybernetics,2003.
[6] Du C,Sun D,Jachman P,et al.Development of a hybrid image processing algorithm for automatic evaluation of intramuscular fat in beef M longissimus dorsi[J].Meat Science,2008,80(4):1231-1237.
[7] 唐成龍,王石剛,徐威.基于數據加權策略的模糊聚類改進算法[J].電子與信息學報,2010,32(6):1277-1283.
[8] 伍學千,廖宜濤,樊玉霞,等.基于KFCM 和改進分水嶺算法的豬肉背最長肌分割技術[J].農業機械學報,2010,41(1):172-176.
[9] Knerr S,Personnaz L,Dreyfus G.Single-layer learning revisited:a stepwise procedure for building and training a neural network[M]//Neurocomputing:Algorithms Architectures and Applications.New York:Springer Verlag,1990:236-241.
猜你喜歡
作文·小學低年級(2025年2期)2025-02-13 00:00:00
小雪花·小學生快樂作文(2024年11期)2024-12-31 00:00:00
作文·小學低年級(2024年2期)2024-04-29 00:00:00
作文·小學低年級(2023年3期)2023-04-29 00:00:00
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
小主人報(2022年4期)2022-08-09 08:52:06
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
