基于KD-Tree的KNN文本分類算法
2012-10-17 03:07:10劉忠劉洋建曉
網絡安全技術與應用 2012年5期
劉忠 劉洋 建曉
桂林理工大學信息科學與工程學院 廣西 541004
0 引言
文本分類是在預定義的分類體系下,根據文本的特征(內容或屬性),將給定文本與一個或多個類別相關聯的過程。常見的分類算法包括:樸素貝葉斯分類法、支持向量機分類法,k-最近鄰法,神經網絡法,決策樹分類法等。
KNN分類法因其思想簡單,效果較好得到了廣泛的應用。但是KNN是一種惰性學習法,模型僅對訓練樣本進行簡單的存儲或稍加處理,一直等到給定一個檢驗樣本時才進行泛化。通過給定的檢驗樣本與和它相似的訓練樣本進行比較來預測類別。然而,在文本分類中,由于訓練樣本集很大和文本特征向量的維數很高,計算訓練樣本的最近鄰樣本需要花費很多時間。
1 KNN算法的改進
針對KNN算法在文本分類上效率低下的問題,目前已經提出了很多的改進算法。歸納起來有兩種途徑:①降低文本向量的維度,采用的主要方法有:聚合文本向量中相關聯的特征詞的方法,基于隱含語義的kNN文本分類方法;②裁剪訓練集,使用小樣本代替大樣本,采用的主要方法有:基于中心向量的分類法,基于質心的文本分類算法,基于簇的K最近鄰分類算法,基于粗糙集的快速KNN文本分類算法。
本文提出的基于KD-Tree的KNN文本分類算法就是在保持原有KNN算法訓練時間為零的前提下,通過對訓練文本向量集建立KD-Tree,測試時,只需要對KD-Tree進行搜索,而不是對整個無序的訓練集進行搜索,這樣,測試時間為,遠小于原始算法的,使得總的分類時間大大減小。
2 基本概念
2.1 二叉查找樹
二叉查找樹是一種特殊的二叉樹。二叉查找樹的存儲規則是:在一棵二叉查找樹中,節點的元素可以使用一個全序語義比較,每個節點n都要遵循下面這兩個規則:
(1) n的左子樹的每個節點的元素小于等于節點n的元素。
(2) n的右子樹的每個節點的元素大于等于節點n的元素。
2.2 KD-Tree
KD-Tree指k維的二叉查找樹,在其上可實現對給定k維數據的快速最近鄰查找。與二叉查找樹不同的,KD-Tree的每個節點代表k維空間的一個點,并且樹的每一層都根據這一層的分辨器做出分枝決策。第i層的分辨器定義為:i mod k。
存儲規則為:對第 i層的任意一個節點 n,若它的左子樹非空,則其左子樹上所有節點的第i mod k維值均小于節點n的第i mod k維值;若它的右子樹非空,則其右子樹上所有節點的第i mod k維值均大于節點n的第i mod k維值;并且它的左右子樹也分別為KD-Tree。
3 基于KD-Tree的KNN文本分類算法
3.1 算法思想
傳統的knn算法認為訓練文本集是一個無序的集合,所以在測試時需要一個一個地比較訓練文本和測試文本的相似度。其實訓練文本集是一個同類文本相互聚集,不同類文本距離較大的集合。KD-Tree可以近似的描述文本集的這種關系,在KD-Tree中,某個節點的分辨器(即i mod k)都大于左子樹中所有節點的第i mod k維值,都小于右子樹中所有節點的第i mod k維值。可以KD-Tree利用這個特性,把訓練文本向量集插入一棵KD-Tree后,在KD-Tree中搜索待測文本向量時,搜索路徑所經過的節點和待測文本的相似度越來越大,而那些和待測文本相似度較小的節點則在搜索中被忽略了。這樣就能通過步得到個相似文本,再計算這個相似文本中哪個與待測文本最為相似。
文本表示通常采用向量空間模型,一個文檔看成是n維空間中的一個向量。文本向量維數一般成千上萬,因此傳統KNN算法計算開銷非常大。而改進算法通過搜索 KD-Tree大大減少了需要計算相似度的文本數量,所以雖然文本維數很高,但是改進算法效率依然很高。
3.2 算法步驟
(1) 建立一個空 KD-Tree,將訓練集文本向量依次插入KD-Tree中。
(2) 在測試集中取出一個待測文本向量,在KD-Tree中搜索這個文本向量,得到祖先節點集。
(3) 依次計算待測文本向量與祖先節點的相似度,相似度最大的文本類型就是待測文本的文本類型。
(4) 測試集文本是否計算完畢,是則結束,不是則轉到第(2)步。
4 實驗結果與分析
4.1 實驗數據來源
本文選取了復旦大學李榮陸博士的文本分類語料庫,共分為20個類別,分別是:Art,Literature,Education,Philosophy,History,Space,Energy,Electronics,Communication,Computer,Mine,Transport,Environment,Agriculture,Economy,Law,Medical,Military,Politics,Sports。原始訓練集有 9804個文本,測試集有9833個文本。去除無效文本和重復文本后,訓練集剩余8333個有效文本,測試集剩余8345個有效文本。復旦語料庫不是一個均衡的語料庫,比如:訓練集中computer,Economy,Politics,Sports類別的文本量都超過1000個,而 Energy,Electronics,Communication類別的文本量則不超過30個。
4.2 評價手段
本文使用正確率、召回率和F1測度值來評價算法的分類效果。

4.3 結果及分析
實驗分詞使用的是開源分詞程序IKAnalyzer3.2.8,然后去除停用詞,用信息增益法選取前 1000個貢獻最大的詞為特征詞集。使用TF-IDF作為計算文本向量特征的權重函數。結果如表1、表2、表3。
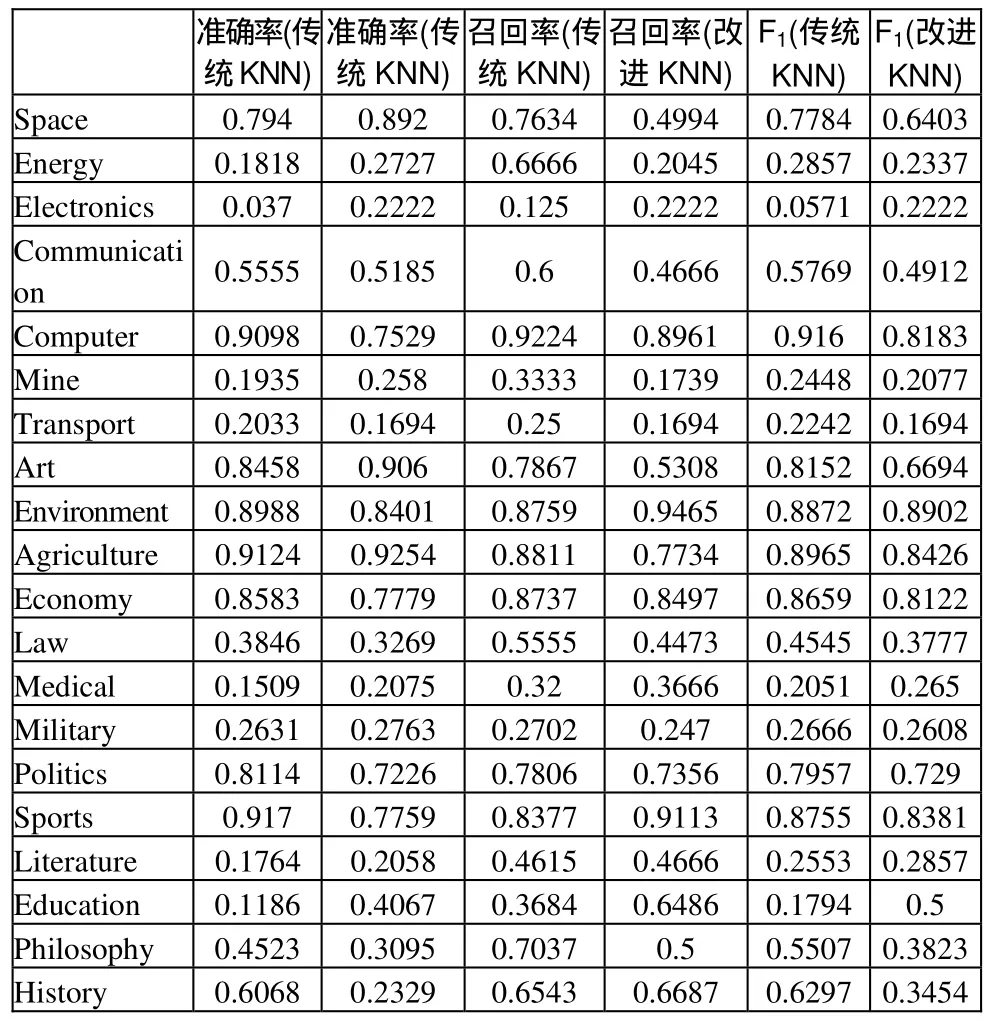
表1 算法分類精度比較

表2 算法平均準確率比較

表3 算法分類時間比較
從準確率和召回率來看,對于語料庫中文本數量相對較多的類別,傳統KNN和改進KNN都具有較好的分類效果,文本數量相對較少的類別,分類效果則較差。但因為語料庫分布不均衡,貧樣本類別的文本總量占語料庫文本總數比例過少,所以平均準確率還是很高的。
從分類時間上來看,改進的KNN的效率是極高的,提高了近 60倍。這是由于 KD-Tree的時間復雜度僅有的緣故。
5 結論
針對傳統KNN文本分類算法的缺點,本文提出一種基于KD-Tree的KNN文本分類算法。實驗表明,改進的KNN算法的效率是非常高效的,并且隨著文本數目的增加,效率也不會顯著變慢。比如,假設訓練集有一百萬個文本,log106≈20,即比較20個文本即可計算出待測樣本的類別,所以該算法有一定的Web海量文本分類和挖掘的潛力。并且該算法只需額外建立一個 KD-Tree,所以非常容易集成到已有的分類系統中,另外結合其他算法的話,比如基于語義等方法,效率和準確度會更高。
今后的工作是在改進算法的基礎上,繼續尋找提升準確度的更好的方法,并且進一步提升算法的效率和精度。
[1]李瑩,張曉輝,王華勇.一種應用向量聚合技術的 KNN 中文文本分類方法[J].小型微型計算機系統.2004.
[2]李永平,程莉,葉衛國.基于隱含語義的 kNN 文本分類研究.計算機工程與應用.2004.
[3]魯婷,王浩,姚宏亮.一種基于中心文檔的 KNN 中文文本分類算法.計算機工程與應用.2011.
[4]柴玉梅.基于質心的文本分類算法.計算機工程.2009.
[5]潘麗芳,楊炳儒.基于簇的K最近鄰(KNN)分類算法研究.計算機工程與設計.2009.
[6]孫榮宗.基于粗糙集的快速KNN文本分類算法.計算機工程.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
