Hadoop中任務調度算法的改進
2012-09-26 02:28:06蘇小會何婧媛
電子設計工程 2012年22期
蘇小會,何婧媛
(西安工業大學 計算機科學與工程學院,陜西 西安 710032)
云計算技術發展到現在,已經出現了很多云計算的軟件平臺,但是功能強、性能穩定的基本都是商業軟件,目前只有Hadoop是可實現大規模分布式計算的開源軟件平臺[1],因此對于Hadoop的應用和研究也最多。
Hadoop旨在構建一個具有高可靠性和良好擴展性的分布式系統,在很多大型網站上都已經得到了應用,可以說是目前最為廣泛應用的開源云計算軟件平臺[1]。Hadoop有以下優點:擴容能力強、成本低廉、效率高、高可靠性、免費開源及良好的可移植性。
Hadoop0.20.0中的任務調度算法包括FIFO調度算法(First In First Out)、公平調度算法(Fair Scheduler)和計算能力調度算法(Capacity Scheduler)。FIFO算法的整體性能和系統資源的利用率不高;公平調度算法負載不均衡,系統的響應時間長,配置文件的好壞影響整個系統的性能;計算能力調度算法中隊列設置和隊列組無法自動進行從而影響系統整體性能的提高。因此對于Hadoop中任務調度算法的改進和優化一直就沒有停息,文中根據對任務執行過程的實時監控,依據任務執行結果放的反饋,動態調整后續任務的分配和執行,在現有任務調度算法的基礎上提出一種基于改進遺傳算法(IGA)的任務調度算法,該算法最大特點是利用遺傳算法的群體搜索技術使得群體進化到包含或接近最優解,從而解決現有任務調度算法收斂速度慢、任務完成時間長、負載不均、資源利用率低、系統整體性能低等缺點。
1 問題分析
任務調度算法作為Hadoop平臺的核心技術之一,直接關系到Hadoop平臺的整體性能和對系統資源的利用,本文的研究目標是改進和完善任務調度算法以提高平臺的整體性能和系統資源使用率。
1.1 Hadoop中的任務調度算法
Hadoop的MapReduce任務調度[2]是一個主動請求的任務,其任務請求調度過程如圖1所示。slave的SubTaskTracker主動向master的TaskTracker請求任務,當SubTaskTracker接到任務后,通過自身調度在本slave建立起SubTask,執行任務。
這個過程可以簡單地概括為以下4個步驟:
1)TaskClient提交任務;
2)TaskTracker接收任務生成子任務;
3)SubTaskTracker申請子任務;
4)TaskTracker分配并監控子任務。
對Hadoop中調度算法的改進也已經有很多研究,文獻[3]中作者提出了一種基于樸素貝葉斯分類的作業調度算法。改進遺傳算法的并行任務調度[4]中提出了一種基于改進遺傳算法的并行任務調度算法。文獻 [5]中HP實驗室開發的Dynamic Priority schedule調度,允許用戶不斷地增加或更改他們的隊列優先順序來滿足當前負載的需要。文獻[6]中介紹了延遲調度并提出了一種基于特征加權的樸素貝葉斯分類器算法來解決公平調度算法中需要對隊列和資源池進行資源配置的問題,

圖1 Hadoop的任務請求調度過程示意圖Fig.1 Process schematic diagram of the task request scheduling in hadoop
1.2 問題分析
Hadoop0.20.0中公平調度算法和計算能力調度算法都需要在分配任務資源之前進行一些配置工作,比如管理員需要對SubTaskTracker上可以同時運行的最大子任務數進行正確設置。但要準確設置最大子任務數,需要管理員深入掌握Hadoop平臺上運行的MapReduce任務和SubTaskTracker兩者各自資源使用特點。公平調度算法和計算能力調度算法雖然比FIFO調度算法有很大程度上的提高,但仍然需要預先設置任務池和用戶池的容量或是權重,實際操作中遇到多用戶、多任務情況下預先設置任務池和用戶池的容量或是權重難度很大。
文中研究不預先設置最大子任務數以及任務池和用戶池的容量或是權重,而對任務執行過程進行實時監控,根據任務執行結果的反饋,對后續任務進行動態調度,在現有任務調度算法的基礎上對最大子任務數以及任務池和用戶池的容量或是權重的取值使用遺傳算法進行動態計算,得到最佳取值后再應用公平調度算法或者計算能力調度算法進行調度。IGA任務調度算法試圖做出以下一些改進:
1)對遺傳算法的初始種群生成方式進行改進,以達到減少迭代次數,并提高運行速度的目的;
2)用兩個適應度來選擇種群,以便達到總任務的完成時間和任務平均所用時間都較短的目的;
3)在選擇、交叉、變異等遺傳操作過程中,有可能會破壞當前種群中適應度最高的個體,加入最優保留策略來更好的對種群進行優勝劣汰以提高算法的收斂精度;
4)采用規則約束的交叉和變異操作以提高個體質量;
5)引入加速進化策略以避免早熟而使得算法停滯的問題。
2 基于改進遺傳算法的設計
2.1 初始種群生成
基于均勻分布策略的初始種群生成方式可以保證隨機產生的個體間有明顯的差異,使它們比較均勻地分布在解空間上,保證初始種群有較豐富的模式,從而提高搜索收斂于全局最優解的可能,再進行幾代進化,使得種群中解的質量逐漸提高,然后通過尋找提交給遺傳算法的任務間的相似性,重復使用先前相似任務的解決方案作為當前任務的種群染色體個體,以此來形成當前任務的初始種群,從總體上減少總的進化次數。IGA的初始種群采用基于均勻分布策略通過隨機方式產生整個算法的第一代種群,以保證有足夠的個體差異性。
為實現改進遺傳算法的初始種群選擇性建立問題,本文引入一個歷史表用來存儲對任務的描述和對應的調度方案。
定義1:任務的描述是任務在資源上執行時間的矩陣ETC[i,j],ETC矩陣表示各個子任務在每個資源上執行時間,ETC[i,j]表示第i個子任務在第j個資源上執行完成所需要的時間。
定義2:不同樣本之間的相似性度量(Similarity Measurement)通常采用計算樣本間“距離”(Distance) 的方法,任務的相似性判斷可以通過輸入任務的期望執行時間矩陣ETC與表中存儲的歷史任務執行時間矩陣計算得到,兩個含有k個元素的向量 a(x11,x12,…,x1k)與 b(x21,x22,…,x2k),則兩向量的相似性可由下式得出:

2.2 最優保留策略
最優保留策略,即在群體交叉、變異之前,先選出本代適應度最高的兩個個體進行保留,不參加選擇、交叉、變異等遺傳操作。而等本代個體完成遺傳操作之后,用先前保留的兩個個體與完成遺傳操作的種群中適應度最小的兩個個體進行替換,這使得種群更好的進化,提高了優勝劣汰的質量。
2.3 規則約束的交叉和變異操作
交叉將選中個體的基因進行交叉,從而生成包含更優良結構的新個體。交叉操作在解空間中進行有效的搜索,同時降低對有效模式的破壞概率。變異隨機地改變選中個體串結構數據中某個串的值來產生新個體,以改善算法的局部搜索能力并維持種群多樣性。由于目前云計算中任務調度的特點,傳統的單點、多點和順序等交叉變異方法不再適用,所以本文采用規則約束的交叉和變異操作。
假設a和b是進行交叉操作的兩個個體,則根據以下規則進行交叉:任意將a和b中的一個或者多個串值進行對換,且對換的串值最好是不同的。
變異操作針對選中個體的串結構數據,任意選擇n個串中的一個或者多個根據以下規則進行變異:
1)將該串值變異為串結構數據中任意的一個值;
2)將任意串移動到距其所在串結構的前一不同串值的任意位置。
2.4 加速進化策略
算法后期的種群中容易導致早熟局部收斂,為了避免早熟而使得算法停滯的問題,本文引入了加速進化策略,即在檢測到算法的早熟指標Dp≤$后,則將交叉和變異的概率均臨時性的提高k倍,文中將k取值為10,以保證在加速進化后的交叉和變異概率達到100%;當早熟指標Dp>$后,又將交叉和變異的概率恢復正常。其中$為早熟判斷門限值,其值由求解中某代個體平均適應度的量級確定,即1×10x。若50個任務,由平均適應度的量級確定x=-2,則$=0.01。

其中,fmax表示本代個體最大適應度值,fmin表示本代個體最小適應度值,favg表示本代個體平均適應度值。
3 基于改進遺傳算法的實現
3.1 算法流程
根據第2節的描述,算法的求解過程如下:
1)初始化控制參數;
2)對基因進行編碼,并隨機產生初始種群;
3)評價群體中每個個體的適應度函數值;
4)選出適應度最高的個體進行保留;
5)根據定義的遺傳算子,分別對種群進行選擇、交叉、變異操作,產生下一代子群;
6)將保留的個體與新種群中適應度最小的個體進行替換;
7)根據加速進化策略對種群進行進化;
8)若滿足收斂條件,返回最優解,結束算法;否則,返回到步驟 3)。
根據上述描述,可以得到基于IGA的任務調度算法流程圖如圖2所示。
3.2 算法實現
根據3.1節給出的算法流程圖,將基于IGA的任務調度算法的過程概括如下:
1)客戶端提交MapReduee任務;
2)初始化任務,創建運行子任務列表;

圖2 基于IGA的任務調度算法流程圖Fig.2 Flow chart of the task scheduling algorithm based on IGA
3)SubTaskTraeker空閑時, 主動發出心跳請求TaskTraeker分配任務;
4)TaskTracker采用基于IGA的任務調度算法選擇一個最優的任務;
5)選擇該任務的一個子任務分配給發送心跳請求的SubTaskTracker;
6)SubTaskTracker被分配了子任務后開始運行子任務,子任務完成時告知TaskTracker;
7)TaskTracker在接到子任務完成的通知后,把任務的狀態設置為“成功”,并顯示一條消息告訴用戶。
3.3 實驗驗證
由于實驗條件有限,本實驗平臺是由3臺機器構成的集群,其中一臺作為 Master,負責 NameNode和 TaskTracker的工作,另兩臺作為Slave,負責DataNode和SubTaskTracker的工作。每臺實驗機器上均運行Ubuntu 10.10系統,java版本1.6,Hadoop版本0.20.2。實驗中的三臺機器分別設置主機名為 hadoop1、hadoop2、hadoop3,其中 hadoop1 為 Master,其他為Slave,圖3為Hadoop平臺結構示意圖,具體配置過程簡單概括為以下3步:

圖3 Hadoop平臺結構示意圖Fig.3 Schematic diagram of the Hadoop platform
1)下載 Linux環境下的 JDK安裝包 jdk-6u27-linuxi586.bin進行安裝,并配置環境變量。
2)配置SSH及無密碼登陸本機
3)安裝并配置Hadoop:
使用前面搭建的Hadoop集群來評估算法的性能。將本文提出的IGA任務調度算法與Hadoop平臺現有的3種算法進行性能比較實驗,選取同一個任務,每次用不同的算法運行這個任務,總共運行10次,記錄每次算法運行的時間。初始條件:任務數量為50;收斂條件:1)達到最大進化代數MaxGen(這里取 MaxGen=100);2)如果連續 50代總任務完成時間和任務平均完成時間都沒有變化,認為算法基本收斂,終止算法。在生成初始種群時若相似度Simlarity(a,b)的取值大于或等于0.75就認為任務a和b相似。實驗參數如表1所示。

表1 實驗主要參數Tab.1 Test main parameters of experiment
要將調度算法從Hadoop平臺現有的調度算法配置為本文IGA任務調度算法,需要將已經編寫好的IGA任務調度程序拷貝到Hadoop_Home/lib下,然后在Hadoop中修改配置文件并加入IGA任務調度模塊,最后檢查調度算法是否運行。對實驗結果進行分析后得到圖4。
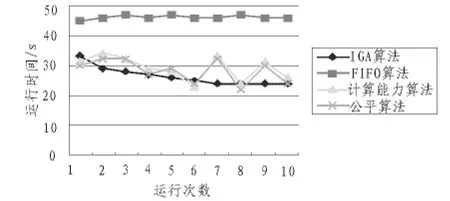
圖4 性能比較實驗Fig.4 Performance comparison test
由上圖可知,FIFO算法的運行時間最長,且效率低,但是運行時間比較穩定。公平算法和計算能力算法隨著SubTaskTracker上最多可同時運行的子任務數以及任務池或者任務隊列的設置不同而存在較大的波動。總的來說公平調度算法和計算能力調度算法的運行時間是低于IGA算法的。本文提出的IGA算法雖存在波動,但是運行幾次后算法開始收斂并趨于穩定。
4 結 論
文中通過對Hadoop現有調度算法和IGA任務調度算法的性能比較實驗可知,IGA任務調度算法的性能比FIFO算法要高的多,相對公平算法和計算能力算法存在著優勢,不僅提供非常不錯的性能同時減輕了管理員和用戶的負擔、提高了管理效率。通過仿真實驗也表明IGA算法可以對Hadoop下編程模式實現較為理想的任務調度,滿足了實際操作中多用戶、多任務的需求動態變化,解決了公平調度算法和計算能力調度算法中預先設置困難的問題,使得改進的任務調度算法迭代次數少、收斂速度快、任務完成時間少、負載均衡、資源利用率高、系統整體性能高,是一種有效的任務調度算法。
[1]Hadoop[EB/OL].(2011-04-16)http://www.Hadoop.org.
[2]宋坤芳.基于蟻群算法的云計算資源調度策略研究[D].武漢:武漢紡織大學,2011.
[3]夏袆.Hadoop平臺下的作業調度算法研究與改進 [D].廣州:華南理工大學,2010.
[4]袁雪莉,鐘明洋.改進遺傳算法的并行任務調度[J].計算機工程與應用,2011,47(10) :56-59.
YUAN Xue-li,ZHONG Ming-yang.Parallel task scheduling algorithm using improved genetic algorithm[J].Computer Engineering and Applications,2011,47(10):56-59.
[5]Sandholm T,Lai K.Dynamic proportional share scheduling in Hadoop[J].In:Springer:2010:110-131.
[6]余正祥.基于hadoop平臺作業調度算法研究[D].昆明:云南大學,2011.
