基于支持向量機的MEMS陀螺儀隨機漂移補償*
2012-06-10 08:08:56李澤民段鳳陽馬佳智
傳感技術學報 2012年8期
關鍵詞:模型
李澤民,段鳳陽,馬佳智
(空軍航空大學航空控制工程系,長春130022)
隨著微電子技術和集成電路技術的發展,采用微機電系統(MEMS)技術的慣性傳感器以其體積小、質量輕、成本低、產品可靠性高等優異特性,被廣泛應用于汽車、航空、航天和武器制導等軍民領域[1]。由于受自身結構缺陷和加工工藝的限制,MEMS陀螺儀存在較大的漂移,尤其是其中的隨機漂移,具有隨機性、非線性、非平穩和弱時變特性,已成為制約MEMS陀螺儀向高精度領域應用的主要因素,必須建立有效的誤差模型對其進行預測和補償[2]。
目前常用的陀螺儀隨機漂移預測方法主要有兩類:一類是以傳統時間序列分析法為代表的統計建模方法,如將AR模型或者ARMA模型與Kalman濾波器相結合[3-4]。這類方法要求時間序列具有平穩性、正態性和獨立性特征,極大的限制了模型的使用范圍和預測精度。另一類是以神經網絡為代表的人工智能算法[5]。神經網絡具有很好的非線性逼近能力,但神經網絡訓練過程遵循的是經驗風險最小化準則,存在著過擬合現象,導致算法的泛化性能差,并且訓練過程受局部極小點的困擾。基于統計學習理論[6]的支持向量機SVM(Support Vector Machine)方法,其訓練過程遵循的是結構風險最小化原則,不易發生局部最優及過擬合現象,能夠很好的克服神經網絡的上述缺陷,非常適合非線性的隨機序列動態建模[7]。
本文通過對隨機漂移序列進行相空間重構,將回歸支持向量機用于陀螺儀隨機漂移的預測和補償,以探索新的更加有效的隨機漂移補償方法。
1 支持向量機預測模型
支持向量機是建立在統計學習理論的VC維理論和結構風險最小化準則的基礎上,根據有限樣本信息在模型的復雜度和學習能力之間尋求最佳折衷,以期望獲得最好的泛化能力[8]。其基本思想是對于非線性問題,利用非線性變換將其映射到一個高維的特征空間中,并在此空間進行線性分析,即將低維空間的非線性問題轉化為高維特征空間中的線性問題來解決。通常引入一個核函數以代替高維空間中的內積運算,從而巧妙的避免了復雜的計算,并且有效地克服了維數災難和局部極值問題。
對于給定的容量為N的隨機漂移樣本集T={xk,yk}(k=1,2,…,N;xk∈Rn,yk∈R),其中 xk為輸入變量,yk為相應的目標值。根據支持向量機的基本思想,首先通過非線性變換將輸入空間映射到一個高維特征空間,在此特征空間中的SVM預測模型為:
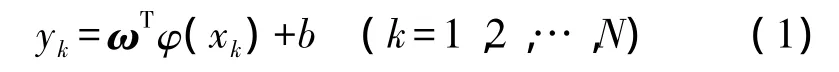
式中,ω、b和φ(xk)分別為權值向量、閾值和進行空間映射的非線性變換。依據結構最小化準則,并考慮偏離點的影響,引入非負的松弛因子,問題轉變為有約束最優問題:
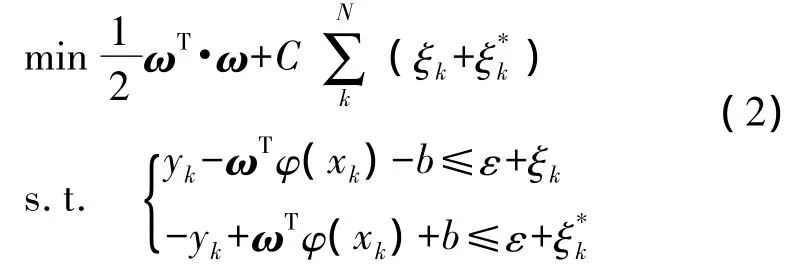
對于此約束二次規劃問題,依據KKT條件,通過引入非負的拉格朗日乘子α,α*,將問題轉化為二次規劃的對偶問題:
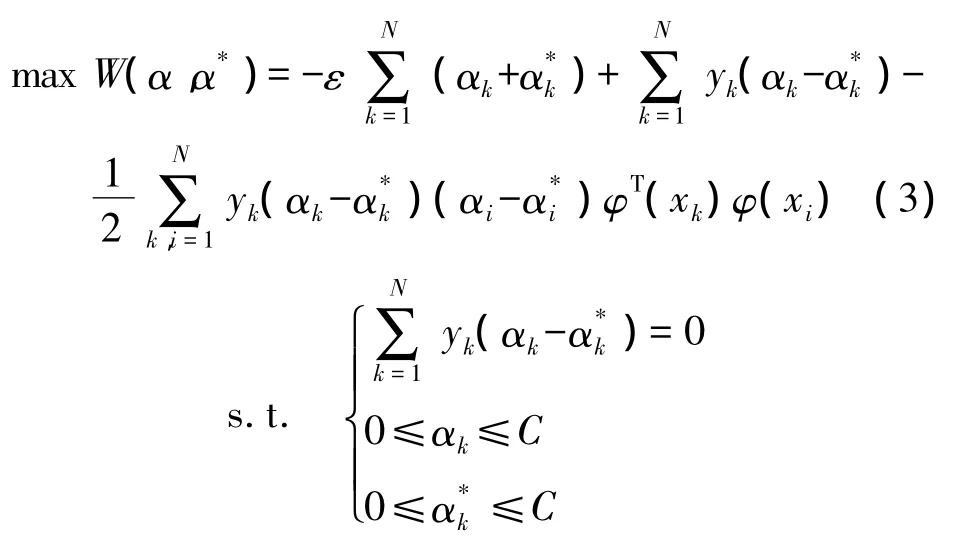
求解上式可得到所求的預測模型:

上式需要計算高維空間的內積,當維數很高時計算量巨大,造成所謂的維數災難。引入核函數K(xk,x)來代替內積的計算,即
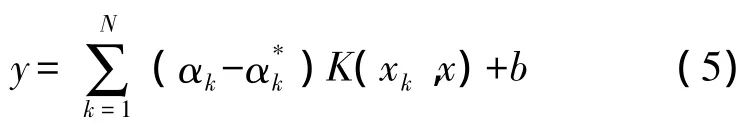
核函數接受低維的輸入而計算高維的內積,可以有效的避免維數災難。根據泛函理論,滿足Mercer條件的函數都可以作為核函數。很多研究和實驗表明:當缺少過程的先驗知識情況下,選擇徑向基核函數比選擇其他核函數預測性能好。在對各種常用核函數預測效果對比的基礎上,本文選擇了徑向基核函數 K(x,xi)=exp(-‖x-xi‖2/σ2)。
2 支持向量機預測模型的建立
2.1 相空間重構
陀螺的隨機漂移是一維的標量時間序列,需要通過相空間重構,把標量時間序列嵌入到一個輔助的相空間中,以得到滿足支持向量機要求的訓練和測試序列。
由Takens嵌入定理[9]可知:如果嵌入維的維數m≥2D2+1,D2是系統的維數,則通過相空間重構的得到的系統與原始系統是等價的。對于標量時間序列:{x(i)},i=1,2,…N,由延遲坐標相空間重構法得到的重構序列為:
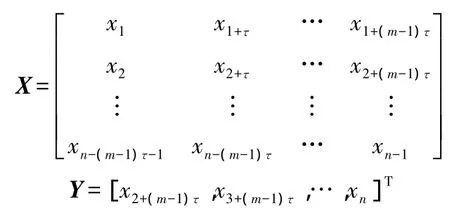
其中m和τ分別為嵌入維數和延遲時間,對一個序列進行相空間重構關鍵是要確定這兩個參數。嵌入維數m表征吸引子的空間間隔和幾何不變量;延遲時間τ反映了任意兩個相鄰延遲坐標點的相關程度。m和τ的不恰當配對將影響重構后的相空間結構與原空間的等價關系。本文使用的C-C法是通過引入嵌入窗寬τw=(m-1)τ將m和τ統一起來的。C-C法基于大量的統計結果產生,計算量少、計算速度快,計算結果理想,并且魯棒性能和抗噪聲性能尤其突出,是最為廣泛使用的計算時間窗的方法。
2.2 核函數參數和SVM參數的選擇
支持向量機模型中,待確定的參數為不敏感系數ε、懲罰系數C和徑向基核函數中的參數σ,這幾個參數在模型的訓練過程中都是定值,需要訓練前事先確定。常用的方法有交叉驗證法、基于VC維的誤差估計和LOO誤差估計[10-11]。本文使用的k-折交叉驗證法,對于中等規模的問題而言,是最為可靠的參數選擇方式。
統計學習理論中,通過比較算法的泛化能力來評價支持向量機的好壞,即檢驗模型對測試集的預測精度來衡量該模型的優劣。本文使用的誤差指標為均方根誤差:
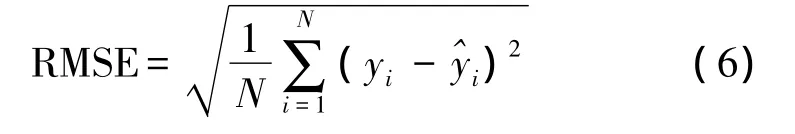
即所有格點中,均方根誤差最小的格點處對應的參數為所尋找的最優參數組合。
3 支持向量機預測模型的實驗驗證
3.1 實驗方法和步驟
采集一組MEMS陀螺儀STIM202的靜態數據,經過確定性誤差補償和小波閾值去噪,得到表征陀螺儀隨機漂移的時間序列。當樣本容量大于3 000時,C-C法尋找最優相空間重構參數的效果較好,因此取該時間序列中長度為3 500的一段序列作為實驗數據。以前500個樣本點為訓練集訓練模型,用后2 000個樣本點做測試。實驗步驟如下:
(1)相空間重構
首先對此標量時間序列進行相空間重構,得到符合要求的訓練集和測試集。利用C-C法求解最優的嵌入維數m和延遲時間τ。得到時間窗τw=13,延遲時間τ=4,計算可得嵌入維數m=4。
(2)樣本歸一化
支持向量機對零均值方差為1的數值最敏感,為了減小模型訓練誤差,對重構后的訓練集和測試集進行歸一化處理:
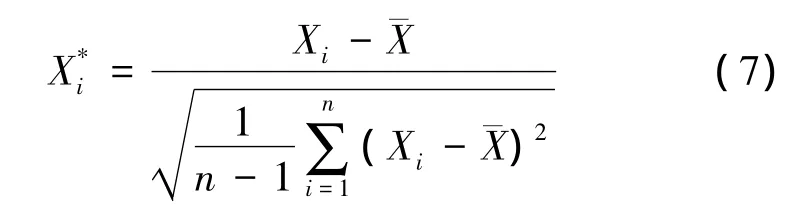
(3)核函數參數和SVM參數的選擇
使用k-折交叉驗法尋找最優參數,k取5,誤差評價指標為均方根誤差RMSE,得到的最優參數組合為(C,σ,ε)=(0.329 88,21.112 1,0.094 6)。
(4)模型的訓練和測試
利用上步得到的最優參數組合,通過SMO[12]算法訓練SVM模型,并對訓練得到的模型進行測試。為了說明SVM模型的有效性,還分別使用了最大Lyapunov指數法、一階加權局域法和RBF神經網絡法對重構樣本做了訓練和預測。
3.2 實驗結果及分析
圖1為最大Lyapunov指數法和一階加權局域法的預測結果。由于這兩種方法預測速度很慢,所以只用來預測了50步。從圖中可以看出,但這兩種方法對陀螺隨機漂移的預測都不太理想。
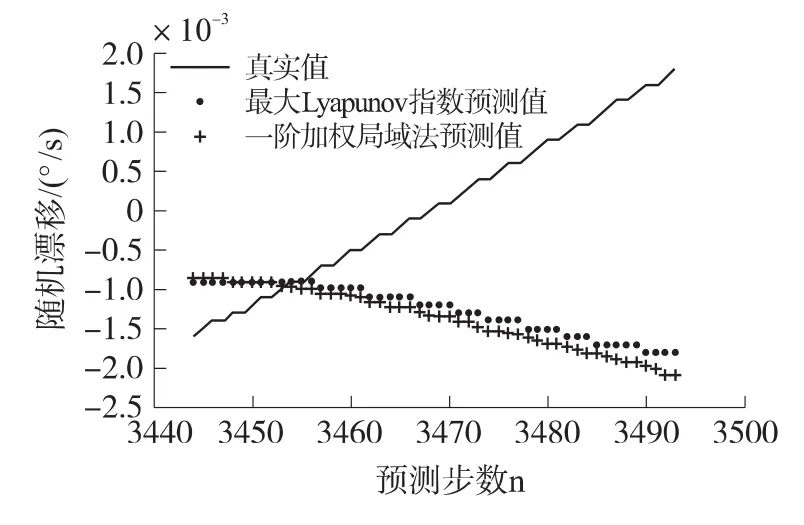
圖1 最大Lyapunov指數法和一階加權局域法的預測結果
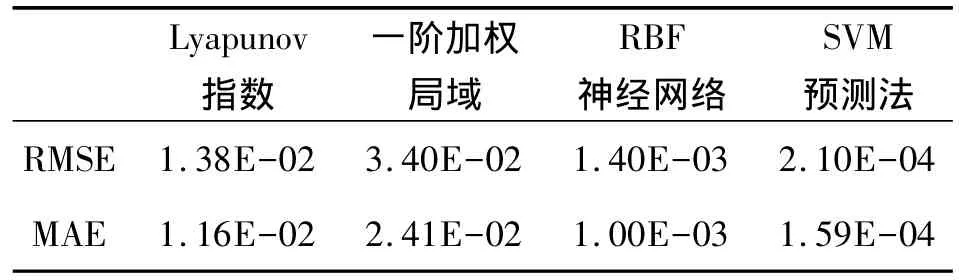
表1 幾種方法對測試集的預測結果
圖2和圖3所示分別為RBF神經網絡方法與SVM法對訓練集的預測絕對誤差和對測試集的預測效果,表1記錄了4種方法對測試集預測的均方根誤差RMSE和平均絕對誤差MAE。從以上圖表可得到結論:
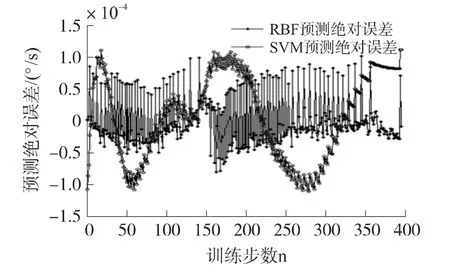
圖2 RBF法和SVM法對訓練集的預測絕對誤差
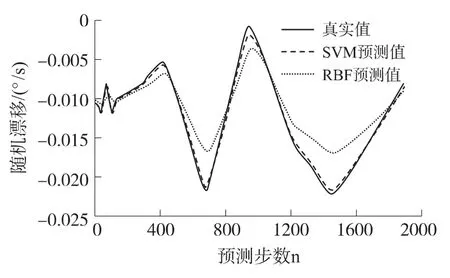
圖3 RBF法和SVM法對測試集的預測結果
(1)對于相同的訓練集,RBF神經網絡法和SVM法相比,具有更高的訓練精度。
(2)對于相同的測試集,SVM法比RBF神經網絡法的預測效果要好,能夠更好的預測出陀螺隨機漂移的變化趨勢。
(3)SVM法的預測誤差隨著預測步數的增加而不斷增大。
造成以上結果的原因是:RBF神經網絡法是一種基于風險經驗最小化準則的學習算法,它的訓練過程力求對訓練集做到最好的擬合,而忽視了模型結構固有的置信風險,因此預測效果受到模型自身缺陷的限制。SVM法以結構風險最小為學習準則,既兼顧訓練集的擬合精度,又重視置信風險的減小,因而具有較好的泛化能力,能取得更好的預測效果。
由于陀螺隨機漂移時間序列的非線性和弱時變特征,造成訓練模型的預測精度隨預測步數的增加而增大,訓練得到的模型只能做短時預測。為了提高全程的預測精度,每隔一定時間以新加入的樣本為訓練集,而對于器件的同一次工作,可以保持模型的各個參數不變,重新訓練預測模型。3個軸向的模型訓練可以間隔進行,模型的訓練耗時很少,對系統的正常工作的實時性影響不大。
4 總結
本文將基于機器學習理論的支持向量機法,用于MEMS陀螺儀隨機漂移的建模和補償。通過相空間重構將問題轉換為支持向量機所需要的形式,利用最優化算法求得了相空間重構、核函數和預測模型的各項參數。仿真結果表明,該方法克服了傳統方法的不足,能夠很好的預測陀螺的隨機漂移,可以用于實際工程中MEMS陀螺儀隨機漂移的補償。
[1]張英,戚紅向.航天慣導產品及技術發展簡介[J].航天標準,2010(3):40-43.
[2]陳殿生,邵志浩,雷旭升.MEMS陀螺儀隨機誤差濾波[J].北京航空航天大學學報,2009,35(2):246-250.
[3]方靜,尚捷,顧啟泰.光纖陀螺隨機誤差建模的實驗研究[J].傳感技術學報,2008,21(9):1514-1517.
[4]李杰,張文棟,劉俊.基于時間序列分析的Kalman濾波方法在MEMS陀螺儀隨機漂移誤差補償中的應用研究[J].傳感技術學報,2006,19(5):2215-2219.
[5]盧海曦,夏敦柱,周百令.基于遺傳小波神經網絡的MEMS陀螺誤差建模[J].中國慣性技術學報,2008,16(2):216-219.
[6]Vapnik V N.The Nature of Statistical Learning Theory[M].New York:Springer-Verlag,1995:35-46.
[7]趙志宏,楊紹普.基于SVM的混沌時間序列分析[J].動力學與控制學報,2009,7(1):5-8.
[8]Smola A J,Schoelkopf B.A Tutorial on Support Vector Regression[J].Statistics and Computing,2004(14):199-222.
[9]呂金虎.混沌時間序列分析及其應用[M].武漢:武漢大學出版社,2002:66-71.
[10]Ito K,Nakano R.Optimizing Support Vector Regression Hyper-Parameters Based on Cross Validation[J].Proceedings of the International Joint Conference on Neural Networks,2003(7):2077-2082.
[11]王曉蘭,康蕾.在線模糊最小二乘支持向量機的時間序列預測[J].計算機工程與應用,2010,46(9):215-240.
[12]Keerthi S,Shevade S K.SMO Algorithm for Least-Squares SVM Formulation[J].Neural Computation,2003,15(2):487-507.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
