地點信息在話題檢測中的應用
2012-06-01 02:55:00謝林燕戚銀城
電子科技 2012年1期
謝林燕,戚銀城,孫 卓
(華北電力大學電子與通信工程系,河北保定 071003)
隨著信息傳播手段的進步,尤其是互聯網的出現,已對信息爆炸的情況,如何快捷準確地獲取有效信息是人們關注的主要問題。由于網絡信息數量過大,與一個話題相關的信息往往孤立分散在不同地方,并出現在不同的時間,僅通過這些孤立的信息,人們對某些事件難以做到全面把握。因此人們迫切希望擁有一種工具,能夠自動把相關話題的信息匯總供人查閱。話題檢測與跟蹤(Topic Detection and Tracking,TDT[1])技術在這種情況下應運而生。話題檢測與跟蹤是一項旨在依據事件對語言文本信息流進行組織、利用的研究,也是為應對信息過載問題而提出的一項應用研究。話題檢測是TDT測評中的一項測評任務,即將新聞數據流中的報道歸入不同的話題,并在必要時建立新話題的技術。話題檢測可分為兩個階段:檢測新話題的出現和將后續報道加入相關的話題。圖1為話題檢測的基本思想。
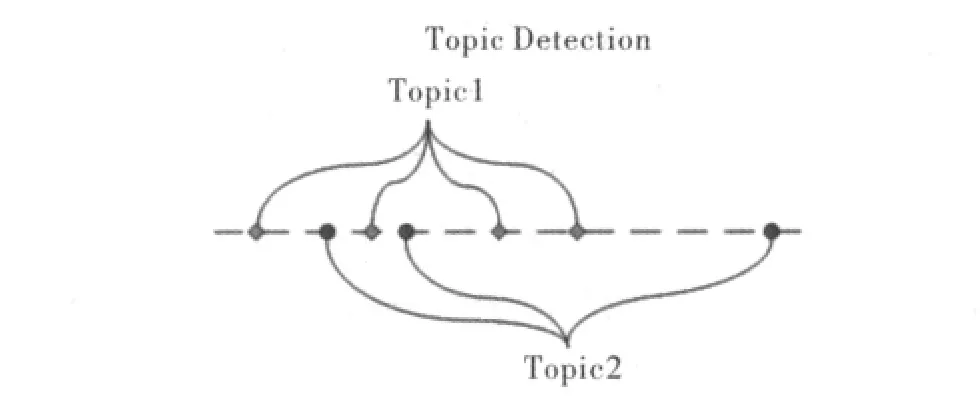
圖1 話題檢測基本思想
目前,已有多位學者針對話題檢測技術展開研究,并取得了一定的進展。文獻[2]提出了一種帶有時間窗口的單遍聚類方法,話題和報道之間的相似度計算主要采用向量夾角余弦值,但根據時間因素利用一個時間窗口作調整。UMass[3]大學系統的核心算法仍是單遍聚類算法,在質心比較策略中,設置了兩個閾值θmatch和θcertain,當前報道與某話題類的質心相似度高于θmatch時,就斷定該報道應當歸入此類,只有當它們之間相似度值高于θcertain時,才用當前報道調整該話題類的質心,即該話題類的向量表示。文獻[4]提出了基于多層聚類的有向無環圖生成算法,通過將單層文本聚類變為多層聚類,記錄各層次間結點的合并過程,得到話題層次結構。文獻[5]提出基于單遍聚類算法和改進的KNN算法相結合的方法進行話題檢測。這些方法的共同點是均采用聚類的方法來實現話題檢測,以語法信息為基礎計算話題和報道的相似度,通過改進聚類方法來提高檢測精度。然而在話題檢測研究中存在一個難題,就是難以區分相似話題[6],比如兩次不同的地震災害或者恐怖事件,因為關于這些事件的報道中所用的詞匯大部分是相同的,所以單一地依靠文本內容的相似度計算,難以將這些報道正確地進行分類。
文中將地點信息運用到話題檢測中,將報道與話題語料用向量空間模型表示。改進基于Baseline模型中的文本內容相似度計算方法,將新聞報道中涉及的地點因素應用到相似度計算中,并與文本內容相似度相結合,兩者的加權和作為最終的新聞報道與話題的相似度,由此來克服相似話題的難以區分問題。實驗證明,該方法提高了檢測精度。
1 建立報道與話題模型
1.1 預處理與報道模型
對收集到的報道語料進行分詞,分詞結果中含有大量的冠詞、介詞、連詞等出現頻率較高的詞匯,其對文本表達的意思基本沒有任何貢獻,更多的作用在于語法上,即稱為停用詞。為去除噪聲,降低后續處理流程的復雜度,減輕整個算法的計算開銷,提高檢測精度,首先要去除停用詞。
采用VSM模型表示報道和話題。基本思想是:它把文本表示成為一個空間向量,向量的每一維代表該文本的一個特征(Term),假設F為經過預處理的報道,term1,term2,…,termm是報道S中的m個不同的詞,那么S可以表示為:S=(term1,ω1;term2,ω2;…;termm,ωm),ωi是 termi在報道S中的權值,文中采用TF - IDF[7]公式來計算特征項權值
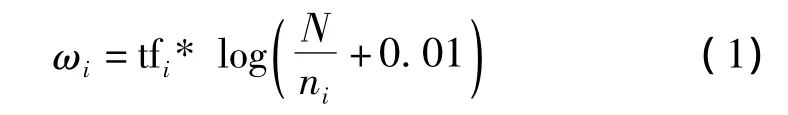
其中,tfi是termi在報道S中的詞頻;N是所有已輸入報道的總數;ni是N篇報道中含有termi報道的數量。
1.2 話題模型
話題是用質心來表示,質心是用向量空間模型表示。為了將話題表示成質心,需經過抽取特征項和計算特征項權值兩步。實驗過程中,從收集到的相關語料中隨機抽取4篇作為訓練語料形成相應話題。首先對訓練語料進行預處理,然后分別計算每篇訓練語料的特征項權重。最后進行話題特征項的權重計算。文中通過式(2)計算話題特征項權重。
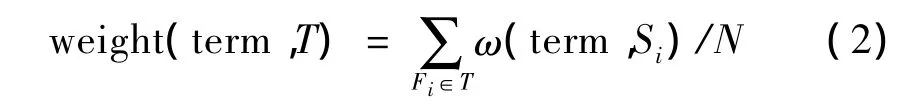
其中,weight(term,T)表示特征項term在話題T中的權重;Si是話題T中包含的新聞報道;N為話題T包含新聞報道的總數量;ω(term,Si)是特征項term在Si中的權重值。
2 報道與話題相似度計算
2.1 基于Baseline模型的報道與話題相似度計算
在基于Baseline模型的報道與話題的相似度計算中,選用向量夾角余弦函數作為相似度計算方法。假設報道S與話題T的向量空間模型分別為S=(ws1,ws2,…,wsn)和T=(wt1,wt2,…,wtn),那么報道S與話題T基于夾角余弦函數的相似度如式(3)所示。
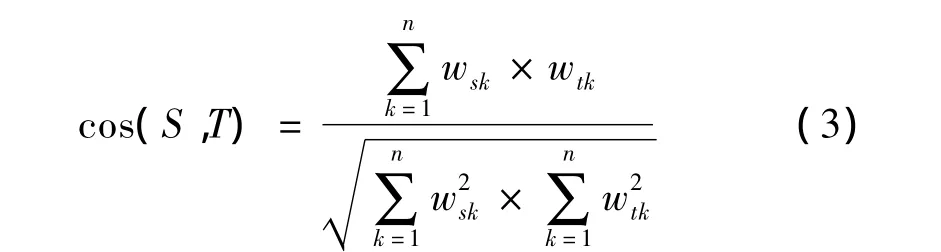
2.2 地點信息報道與話題相似度計算
特定話題中涉及到的地點信息在解決相似話題難以區分的問題中起著不可忽視的作用。由于相似話題通常采用相同的詞語進行描述,如兩次不同的交通事故或恐怖事件,僅采用基于Baseline模型的相似度計算方法很難將相似話題正確區分。文中提出結合地點信息的話題檢測方法,通過構造地點相似度計算函數,獲得地點相似度,并將其計算結果應用于話題檢測中。實驗結果證明,提出的結合地點相似度的話題檢測方法能很好地改進系統性能指標。
提取報道的地點信息形成地點向量,并與相應話題的地點向量進行相似度計算,計算公式如式(4)所示。
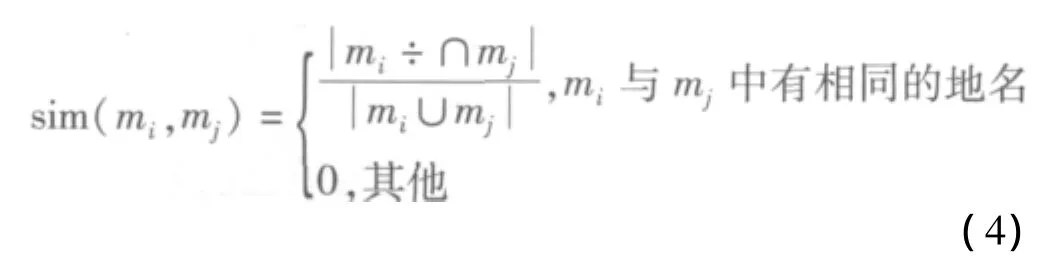

將基于Baseline模型的相似度和地點相似度分別計算,通過兩類相似度計算結果線性組合的方式得到最終的相似度
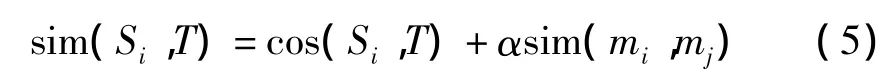
其中,α為設定的參數,實驗中α=0.4。
3 話題檢測算法
文中以Single-Pass聚類策略為基礎實現話題檢測算法,該算法按新聞報道輸入的先后順序依次處理信息流中的報道,直到所有的報道處理完畢,具體過程如下:
(1)對新聞報道進行預處理,然后利用上述的特征權重計算方法計算報道和話題中各個特征詞的權值,分別建立報道模型和話題模型。
(2)計算新聞報道與話題的相似度,與預設的閾值進行比較,報道與話題的相似度高于閾值,則判定該報道與話題相關,否則判定該報道與話題不相關。
(3)重復上述過程直到信息流中的所有報道都處理完畢。
4 實驗結果與分析
4.1 評價指標
文中實驗采用的性能指標為正確率(Precision)、召回率(Recall)和F1指數,其定義如表1所示。
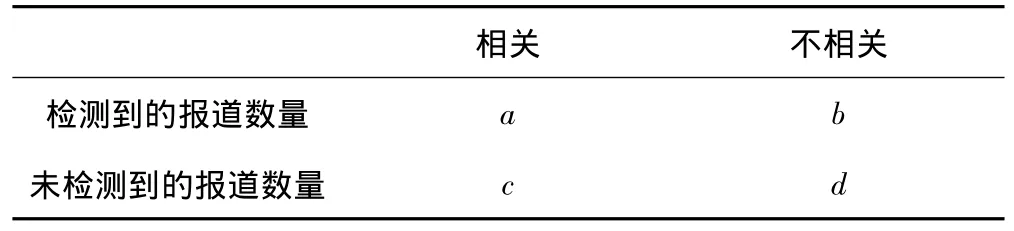
表1 評價指標
其中,收集到的測試新聞語料中與話題相關的報道數目為a+c,不相關的報道數目為b+d。檢測結果中,判定與話題相關的報道數目為a+b,不相關的報道數目為c+d。正確率、召回率和F1指數計算方法如下所示。

4.2 實驗結果與分析
實驗采用從互聯網收集到的新聞報道作為評測語料,該語料包含725篇中文報道,定義了10個話題,表2為話題事件與相關新聞報道數目。
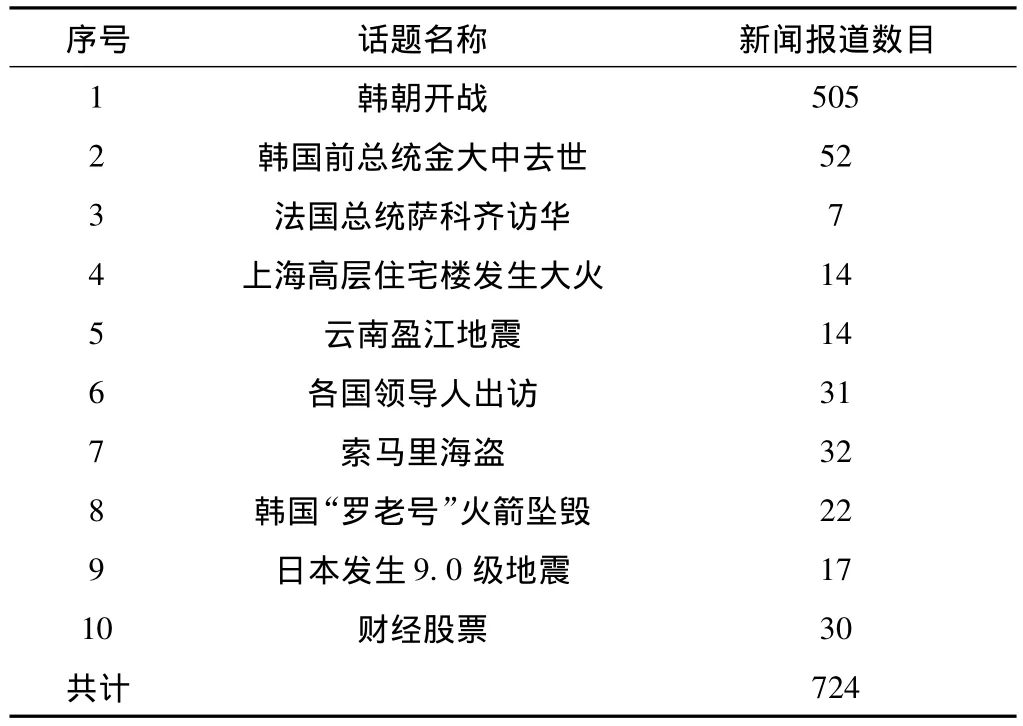
表2 話題事件與相關新聞報道數
隨機選取4篇與韓朝開戰相關的新聞報道作為訓練語料,構建話題模型,剩余720篇新聞報道作為測試語料,其中選取韓朝開戰事件作為本次實驗的相關話題,其余話題作為與該話題不相關的反例話題,共計219篇。分別對基于Baseline模型和結合地點信息兩種方法進行實驗對比,實驗結果如表3所示。

?
由上述實驗可知,通過設定不同的相似度閾值發現,隨著該值的增大,正確率提高,召回率下降;結合地點信息的話題檢測方法的召回率在同等條件下,高于基于Baseline模型的檢測結果,同時,F1測試值較Baseline模型改進了7.306%,說明結合地點信息的話題檢測系統的檢測性能優于基于Baseline模型的話題檢測系統。綜上所述,將地點信息應用到話題檢測是一種行之有效的方法。
5 結束語
針對話題檢測方法進行了初步研究,通過分析新聞報道語料的特點,將新聞報道中的地點信息融入報道與話題的相似度計算中,即構建地點相似度計算公式,并結合基于Baseline模型的相似度計算結果,將兩類相似度的計算結果進行線性組合,從而得到報道和話題的相似度計算結果,完成話題檢測任務。實驗結果表明,將地點信息應用于話題檢測能夠提高性能指標。
[1]李保利,俞士汶.話題識別與跟蹤研究[J].計算機工程與應用,2003,39(17):7 -10.
[2]YANG Y,CARBONELL J,BROWN R,et al.Multi- strategy learning for topic detection and tracking[C].Proc.of the TDT2002 Workshop,2002:85 -114.
[3]KUPIEC J,PEDERSEN J.A trainable document summarizer[C].Seattle,Washington,USA:Proceedings of the 18th Annual Int'l ACM SIGIR Conf on Research and Development in Information Retrieval(SIGIR'95),1995:68 -73.
[4]于滿泉,駱衛華,許洪波,等.話題識別與跟蹤中的層次化話題識別技術研究[J].計算機研究與發展,2006,43(3):489-495.
[5]李保利.漢語新聞報道中的話題跟蹤與識別研究[D].北京:北京大學,2003.
[6]洪宇,張宇,劉挺,等.話題檢測與跟蹤的評測及研究綜述[J].中文信息學報,2007,21(6):71 -87.
[7]劉海峰,王元元,劉守生.一種組合型中文分類特征選擇方法[J].廣西師范大學學報:自然科學版,2007,25(4):208-211.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
