一種改進的Max-Log-Map譯碼算法的DSP實現
2012-02-15 03:29:56李立欣蔣少豪張會生
電子設計工程 2012年13期
關鍵詞:信息
戚 楠,李立欣,范 捷,蔣少豪,張會生
(西北工業大學 電子信息學院,陜西 西安 710129)
Turbo碼很好地應用了Shannon信道編碼定理中的隨機性編/譯碼條件,采用軟輸出迭代譯碼算法來逼近最大似然譯碼算法,從而獲得了幾乎接近Shannon理論極限的譯碼性能[1-2]。但是Turbo譯碼復雜度大,譯碼延時大不能較好地滿足實時高速通信的要求,譯碼過程中變量占用的存儲空間開銷大。這些問題限制了Turbo碼的廣泛使用。而Max-Log-Map算法中分量譯碼器模塊是Turbo譯碼中的關鍵部分,其時效性和變量存儲量在很大程度上決定著Turbo碼的譯碼性能。如何減少譯碼時延以提高譯碼時效性,以及如何減少存儲開銷都是Turbo碼編譯碼應用于工程項目中的關鍵影響因素。
1 譯碼過程中的優化設計
分量譯碼器模塊是譯碼過程中的關鍵步驟,所以改善該部分的譯碼性能對整個譯碼器的作用。常規計算步驟是先進行前向遞推,計算出一幀數據所有比特的前向度量,然后再進行后向遞推,計算出一幀數據所有比特的后向度量,再算出每比特的對數似然比和外信息,經過解交織作為SISO譯碼器1的先驗信息進行下一輪迭代譯碼。其譯碼時延較大,且需要的變量存儲量大。因此,改進子譯碼器的性能是改善Turbo譯碼性能的關鍵[3]。
2 譯碼過程中的優化設計
2.1 前、后向度量的簡化
對于碼元dk的譯碼,其條件聯合概率定義為:
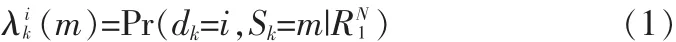
其中m是RSC分量編碼器的狀態數 (v級移位寄存器,狀態 m=0,1,…,2v-1,共 2v種狀態);i為信息碼元 dk的值;RN1是接收到的信息序列。
碼元dk的后驗概率對數似然比改寫為
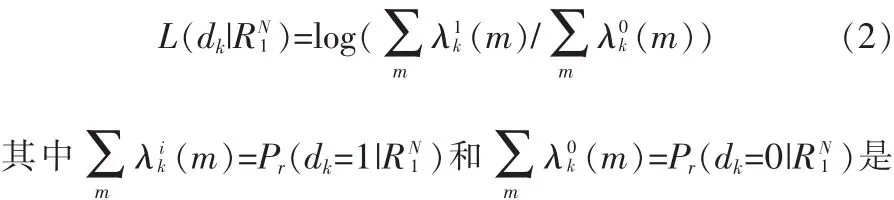
碼元dk的后驗概率。
式(1)可以寫成:

則有
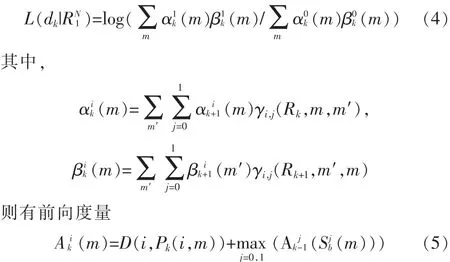
后向度量:
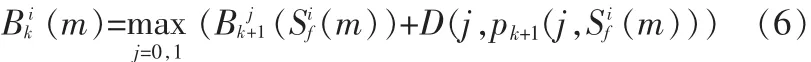
對數似然比:
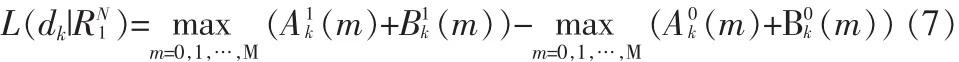
轉移度量:
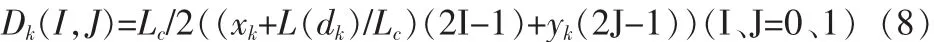
其中xk、yk為接收序列對應于i的值,Λ(dk)為先驗信息,Lc=2/δ2參數表示信道的可信度,δ2表示AWGN信道的方差。最終的譯碼器根據L(dk|RN1)作出判決。
觀察可知公式(5)、(6)可以用蝶形圖,如圖1~圖3所示。
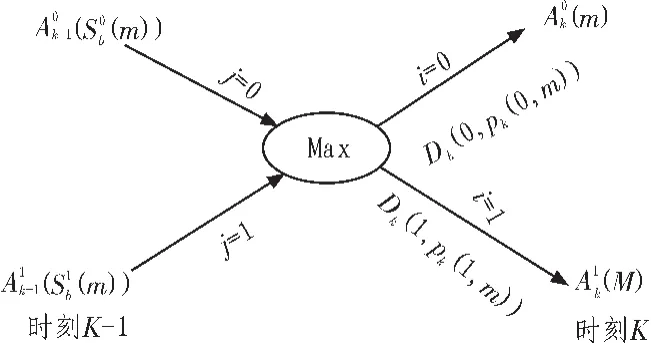
圖1 Aik(m)的迭代計算蝶形圖Fig.1 Papilionaceous drawing of Aik(m)
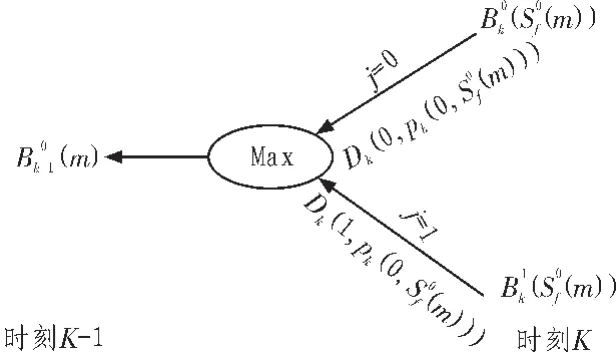
圖 2 B0k-1(m)的迭代計算蝶形圖Fig.2 Papilionaceous drawing of B0k-1(m)
這種改進的數據計算采用蝶形結構,其最大優點是易于工程實現,在DSP芯片中可以直接調用CSSU(比較、選擇、存儲單元),一次性并行計算出(m)等,從而減小Turbo碼的譯碼延時,提高譯碼效率[4]。
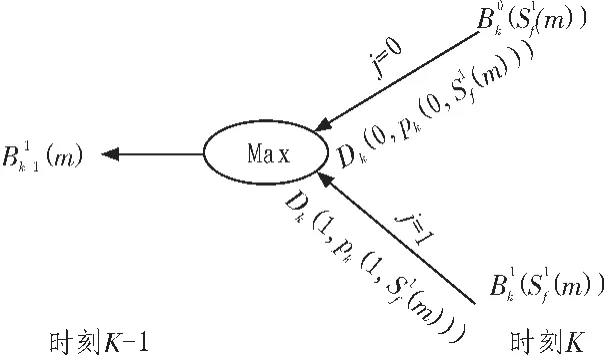
圖 3 (m)的迭代計算蝶形圖Fig.3 Papilionaceous drawing of(m)
2.2 數據溢出保護
在譯碼過程中,前向累計度量Ak和后向累計度量Bk會隨著迭代不斷增大。當交織長度達到一定程度時,定點DSP在遞推計算前、后項度量時就會發生溢出現象,從而導致整個譯碼器性能的惡化。所以必須考慮溢出處理。分析對數似然比公式(7)可知,當減號兩邊同時減去任一常數時,并不影響正確結果,而且前向累積度量和后向累積度量雖然不斷增大,但對于任一比特的前向累積度量或后向累積度量之間的差值的動態范圍并不大。考慮到程序運行耗時及程序執行的方便處理可以每次度量結果后減去一個設定的數。本文設定為。每次執行后的結果進行下次迭代前初始化為(0) ,因此第二次以后的迭代譯碼前、后向度量的相對值,由于相對值很小,這樣就能有效防止溢出。
2.3 分塊并行設計
在譯碼過程中,用于存儲中間結果的數據空間需求正比于交織長度,當交織長度較大時,傳統的譯碼算法需要大量的存儲空間保存變量值,這加大了計算時間和存儲開銷。為減少譯碼計算延時,將整個幀長分割成若干個子塊,各個子塊進行并行Max-Log-Map譯碼。設信息幀長為L,各個子塊的長為K,則所分子塊的塊數N=L/K,并行譯碼結構圖如圖4所示。

圖4 分塊并行Max-Log-Map譯碼算法示意圖Fig.4 Flow chart of the Max-Log-Map algorithm
譯碼器的結構與原譯碼器結構基本相同,每個子塊都執行碼元子序列的前向度量、后向度量、轉移度量計算。其中,前一碼元的前向度量將作為后一碼元的前向度量Aik(m)初始值,后一碼元的后向度量Bik(m)將作為前一碼元后向計算的初值,由前向度量及傳遞過來的后向度量計算出其余變量值。
區別于傳統的譯碼算法的是:分量譯碼器改為由N個分量譯碼器子塊并行調用,每一子塊進行相同的初始化,這些模塊同時工作,并行執行各個分塊的信息子序列譯碼,最終對結果拼接輸出,因此該設計方案可以很大程度上減少譯碼延時。
2.4 子塊內進一步優化設計
在每一子塊的譯碼過程可以進一步優化來節省存儲空間和譯碼延時。流程圖如圖5所示。
1)簡化轉移度量的計算。每比特的狀態轉移度量的計算只需要4次加法,而不需要乘法、加法的混合運算,在譯碼運算過程中,完全可以結合到計算前向累計度量Ak和后向累積度量Bk的遞推過程中,從而節省了狀態轉移度量的存取操作,大大減少了計算量,提高了算法的執行速度,節省了4L(設交織長度為L)存儲空間。
2)外信息的計算和前向度量并行進行,可省略對前向度量的存儲,節省了8L存儲空間,直接由硬判決單元根據外信息恢復出對數似然比,可以節省對似然比的存儲,節省約1L的存儲空間,同時減少了存儲操作,提高了程序效率。
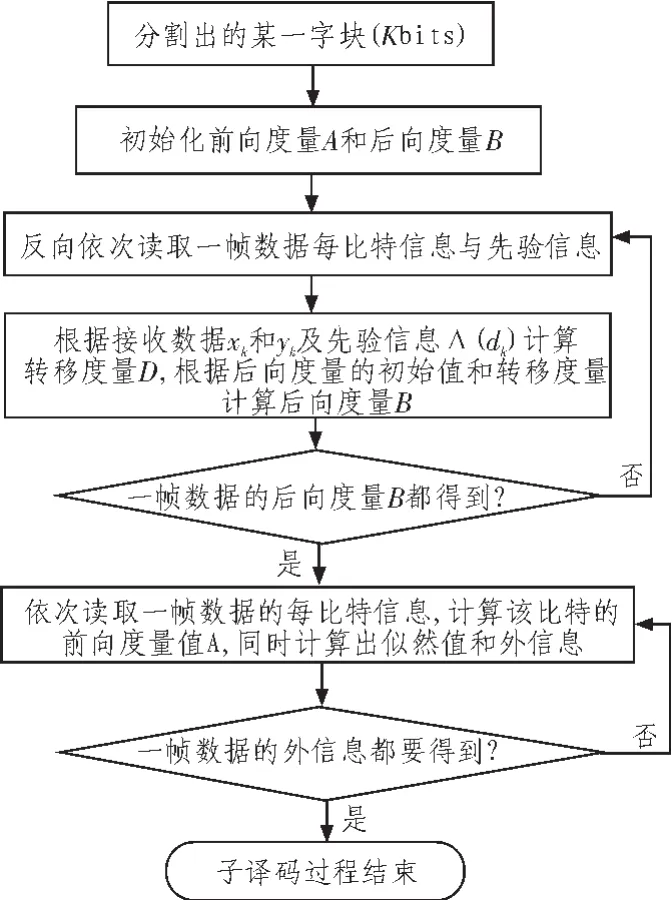
圖5 Turbo子譯碼器流程圖Fig.5 Flow chart of the Turbo sub-decoder algorithm
此種設計的優勢分析如下:
①提高時效性
圖6是經典的譯碼算法和改進的子譯碼算法對應的時序圖(一個周期為T)。

圖6 傳統算法和改進后的算法時序比較圖Fig.6 Comparison between the traditional algorithm and improved one
從圖6中可以看出,優化后的方案減少了約3/5的譯碼時延,在很大程度上縮減了譯碼耗時。
②節約存儲開銷
本算法設計共節約了13L存儲空間資源。優化后的算法的存儲空間如表1所示。

表1 主要占用的存儲空間分配Tab.1 Principal storage cost
3 DSP實現結果及性能分析
TMS320C6000系列是TI公司推出的高性能DSP系列。采用TI專利技術VeloiTI和新的超長指令字結構,使該系列DSP的性能達到很高的水平。DSPC6416每時鐘周期同時執行8條指令,運算能力可達到 4 800MIPS(每秒百萬條指令)[5-6]。
3.1 仿真分析
模擬傳送400幀的隨機數據作為信源信息序列,每幀256 bit。 系統編碼率定為 1/2。 Turbo 碼采用(7,5)碼,其中交織器采用偽隨機交織映射,信息長256 bit,均分為4段并行運算,采用五次迭代的改進Max-Log-Map譯碼算法,BPSK調制解調。在DSPC6416軟件平臺進行仿真。
1)改進前后的BER(誤比特率)系統性能分析
圖7中橫坐標表示信道的信噪比。由圖可知,改進前后的仿真結果相近,這從一定程度上說明了改進后算法的合理性和可靠性。但觀察知改進后的算法誤比特率稍高于改進前的譯碼誤比特率。這是因為一幀數據中,校驗數據之間存在聯系,而采用并行譯碼將割裂整幀數據間的聯系,必然會帶來誤碼率的惡化。
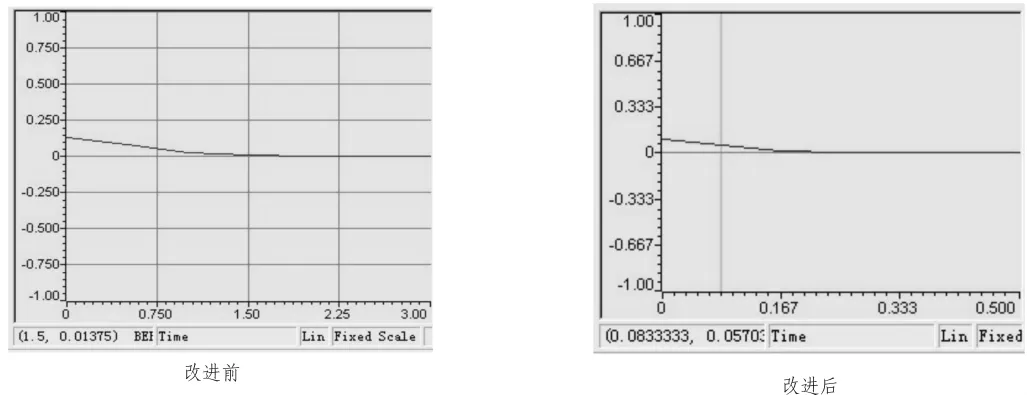
圖7 改進前后的譯碼BER對比圖Fig.7 BER comparison between the original algorithm and the improved one
2)改進前后仿真信息傳輸速率分析
由于對Max-Log-Map譯碼算法的計算流程進行了改進,大大減少了指令對DSP芯片CPU的資源占用,信息處理速率得到大幅度提高。經CCS軟件自帶的代碼執行時間統計模塊里的Incl.Total顯示代碼段消耗的所有時鐘周期及相應的信息傳輸速率如表2所示 (本例中C6416DSP芯片時鐘周期為 1/600M)。
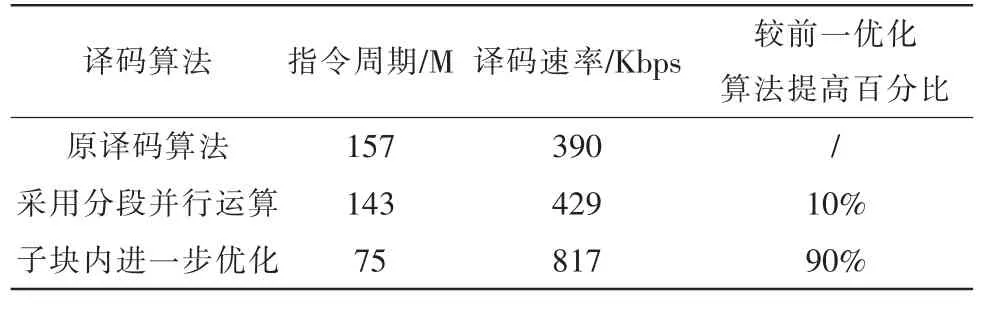
表2 改進前后消耗周期數及信息傳輸速率比較Tab.2 Transmission rate and consumed cycle time comparison
4 結 論
文中對Turbo碼Max-Log-Map譯碼算法進行了改進。理論分析看到,改進后的算法在很大程度上減少了譯碼延時,節約了13倍交織長度的存儲空間資源。同時,性能仿真結果表明,在譯碼BER性能相當的情況下,改進的Turbo碼譯碼速率提高至原來的2倍,驗證了優化后的算法的合理性和可靠性。因此該優化方案具有一定的實際參考與應用價值。
[1]劉東華.Turbo碼原理與應用技術[M].北京:電子工業出版社,2004.
[2]Berrou C,Glvaieux A.Near shannon limit error-correcting coding and decoding:turbo-codes[J].ICC,Geneva, Switztlnad,1993(2):1064-1074.
[3]尹成群,謝小軍,宋文妙.Turbo碼譯碼器的DSP實現[J].電子測量與儀器學報,2005,19(5):72-76.YIN Cheng-qun,Xie Xiao-jun,SONG Wen-miao,et al.Research and Realization on DSP of Turbo decoder[J].Journal of Electronic Measurement and Instrument,2005,19(5):72-76.
[4]王強.Turbo碼在COFDM中的應用研究[D].南京:南京理工大學,2003.
[5]李方慧,王飛,何佩現.TMS320C6000系列DSPs原理與應用[M].北京:電子工業出版社,2002.
[6]豈興明,胡小冬,周火金.DSP嵌入式開發入門與典型實例[M].北京:人民郵電出版社,2011.
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
