基于MogoDB數據庫的臨床醫療大數據挖掘案例分析
2021-07-28 05:30:35胡皓皓胡昌盛
科技創新導報 2021年3期
胡皓皓 胡昌盛


DOI:10.16660/j.cnki.1674-098X.2011-5640-8970
摘? 要:隨著醫療大數據時代的到來,從大量原始數據中挖掘出相關有用的信息,對治病防病及醫療決策進行有效輔助,起到非常好的作用。本文基于MongoDB數據庫,利用Python編程語言,編寫數據處理程序,通過將原始的多個數據表入庫轉換,找出已治愈患者,在此基礎上找出復燃、復發患者并篩選出沒有重復的數據;通過多進程提高處理速度。最后結果達到了預期,為相關醫務人員提供了診斷及決策依據。
關鍵詞:Python? MongoDB數據庫? 大數據? 數據挖掘
中圖分類號:TP311? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼:A? ? ? ? ? ? ? ? ? ? 文章編號:1674-098X(2021)01(c)-0108-03
A Case Study of Clinical Medical Big Data Mining Based on MongoDB Database
HU Haohao1? HU Changsheng2*
(1.South China Institute of Software Engineering, Guangzhou University, Guangzhou, Guangdong? Province, 510990 China; 2.Guangzhou University of Chinese Medicine, Guangzhou, Guangdong? ?Province, 510006 China)
Abstract: With the advent of the era of medical big data, mining relevant useful information from a large number of original data plays a very good role in effectively assisting the treatment and prevention of diseases and medical decision-making. In this paper, based on MongoDB database, using Python programming language, we write a data processing program. Through putting the original data tables into the database and transforming, we find out the cured patients. On this basis, we find out the recurrent patients, and screen out the data without duplication. We improve the processing speed through multi-processing. Finally, the results achieved the expected results, and provided the basis for diagnosis and decision-making for relevant medical staff.
Key Words: Python; MongoDB database; Big data; Data mining
醫療機構作為醫療行業的重要載體,保存大量的患者的原始數據。早期,大部分醫院原始數據的記錄大都保存在Excel電子表格中,表格多,數據量大,少則十多萬條,多則幾百萬條。單獨通過電子表格進行數據統計功能非常有限,而且處理速度慢,對深度數據挖掘沒有什么作用。本文筆者通過Python編寫語言,結合MongoDB數據庫編寫程序,把原始數據中的多表進行關聯并進行條件篩選,通過多次優化進程,挖掘出相應結果。具體編程處理流程分多步進行。
1? 設計具體流程
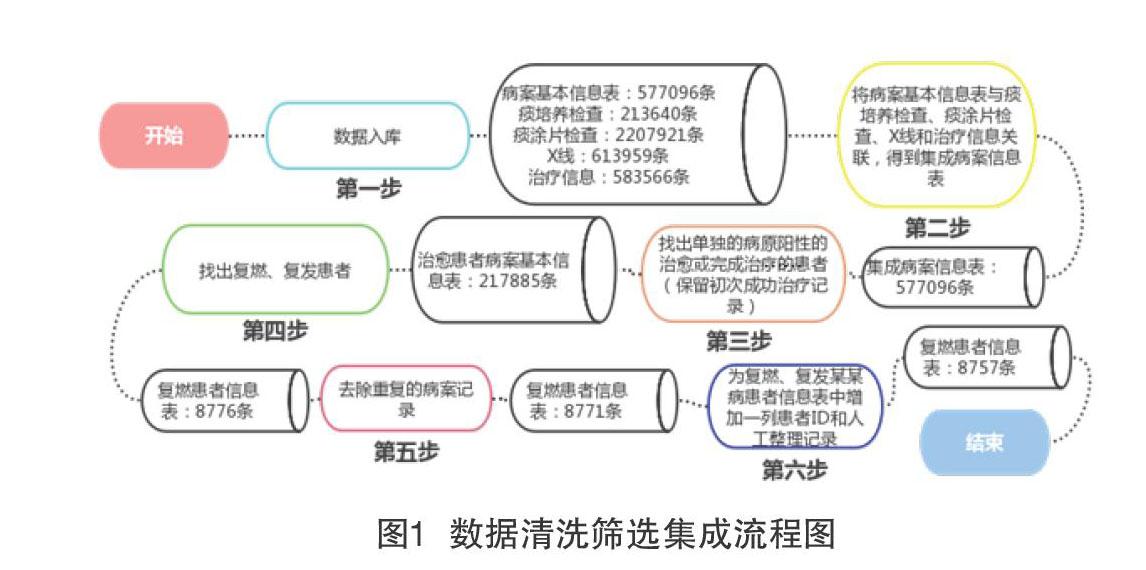
設計具體流程如圖1所示。
2? 數據轉換及導入
MongoDB是一種NoSQL數據庫,MongoDB可以實現多類數據的一體化存儲、統一規則訪問及多樣性查詢、關聯檢索等功能。將xls格式的2011~2019年某省某某病患者數據文件全部導入到MongoDB中。通過將病案基本信息表關聯其他四個表(痰涂片檢查、痰培養檢查、X線和治療信息)的信息,匹配的條件是病案ID和登記號,得到集成病案信息表。
這一步獲得五個大表和一個總表,如表1。
3? 找出已治愈的患者
從第一步得到的病案基本信息表里面篩選出已治愈的患者記錄(包含221357條記錄)并導入治愈患者信息表,其中主要偽代碼如下:
輸入:病案基本信息表
輸出:治愈患者信息表
對病案基本信息表的每條記錄R:{
如果 (R[“診斷結果”]∈[“涂片陽性”,“僅陪陽”,“僅分子生物學陽性”] 或
R[“分子檢出結果”]==“檢出”) 且 R[“停止原因”]∈[“完成療程”,“治愈”]:{
將R加入治愈患者信息表}}
篩選條件是:“診斷結果”是“涂片陽性”、“僅陪陽”或者是“僅分子生物學陽性”,或者“分子檢出結果”是“檢出”。除此之外,“停止原因”是“完成療程”或“治愈”。
然后再進行去重(即找出不重復的患者)并輸出一個csv格式的文件。去重的條件是有相同的患者姓名、出生日期和性別,或者有相同的身份證號,或者有相同的患者姓名、出生日期和患者聯系電話。去重去掉的是治愈患者第一次治愈記錄之后的全部治愈記錄。去重之后治愈患者信息表中還有217885條記錄。
4? 找出復燃、得發患者
遍歷上一步得到的治愈患者信息表csv文件,在病案基本信息表中找出復燃、復發患者的所有初次治愈(包含初次治愈記錄)后的記錄:
對csv中的每一條記錄:果身份證號不為空,用身份證號查詢病案,看看是否有出現在該記錄“停止時間”相同或之后的病原學陽性發病記錄:
輸入:治愈患者信息表csv
對治愈患者信息表csv的每條記錄R:{
獨特病案ID序列:=[]
獨特病案記錄序列:=[]
如果 R[“身份證號”] ≠ ””:{
身份證號查詢結果 := 查詢集成病案信息表 ((記錄[“診斷結果”]∈[“涂片陽性”,“僅陪陽”,“僅分子生物學陽性”] 或 記錄[“分子檢出結果”]==“檢出”) 且 (記錄[“停止時間”] ≥R[“停止時間”] 且 記錄[“停止原因”] ≠“診斷變更” 且 記錄[“身份證號”] ==R[“身份證號”])
如果 身份證號查詢結果記錄的數目>1:{
對身份證號查詢結果的每條記錄D:{
如果 D[“病案ID”]獨特病案ID序列:{
往 獨特病案ID序列 加入D[“病案ID”]
往 獨特病案記錄序列 加入D
往 復發患者信息表-身份證號匹配 加入D? ?}} }}
姓名出生日期查詢結果 := 查詢集成病案信息表 ((記錄[“診斷結果”]∈[“涂片陽性”,“僅陪陽”,“僅分子生物學陽性”] 或 記錄[“分子檢出結果”]==“檢出”) 且 (記錄[“停止時間”] ≥R[“停止時間”] 且 記錄[“停止原因”]≠“診斷變更” 且 記錄[“患者姓名”] ==R[“患者姓名”]且 記錄[“出生日期”] ==R[“出生日期”])
如果 姓名出生日期查詢結果記錄的數目>1:{
對姓名出生日期查詢結果的每條記錄D:{
如果 D[“病案ID”]獨特病案ID序列:{
往 獨特病案ID序列 加入D[“病案ID”]
往 獨特病案記錄序列 加入D? }} }}
“停止原因”不能是“診斷變更”,因為“診斷變更”意味著并沒有發病,診斷有誤。
如果查詢出來的記錄數大于一,再對查詢到的記錄根據“病案ID”去重(每個病案ID對應一次發病記錄),再將去重后的記錄加入臨時獨特的記錄序列和用身份證號匹配的復發患者信息表(中間結果),其“病案ID”加入臨時獨特的病案ID序列。
用姓名、出生日期查詢病案,看看是否有出現在該記錄“停止時間”相同或之后的發病記錄:
如果查詢出來的記錄數大于1,再對查詢到的記錄根據“病案ID”去重,再將去重后的記錄加入臨時獨特的記錄序列,其“病案ID”加入臨時獨特的病案ID序列。去重后的記錄如果不符合其他匹配條件就加入用患者姓名和出生日期匹配的復發患者信息表(中間結果),如果性別相同就加入用患者姓名、性別和出生日期匹配的復發患者信息表(中間結果),如果性別相同、戶籍地址相同就加入用患者姓名、性別、出生日期和戶籍地址匹配的復發患者信息表(中間結果),如果性別相同、現地址相同就加入用患者姓名、性別、出生日期和現地址匹配的復發患者信息表(中間結果),代碼如圖2所示。
如果上一步得到的臨時獨特的病案ID序列的元素個數大于1,將臨時獨特的記錄序列中的記錄按停止時間排序(升序)。然后對序列中的記錄增加一個“第幾次發病”字段值,再存入復發患者信息表。
5? 去除復燃、復發某某病患者信息表中含有重復的病案ID的記錄
由于第二步得到的去重之后的治愈患者信息表中仍然有可能有重復的患者,最后根據病案ID把重復的記錄刪去。患者ID是每個患者唯一的,可以通過患者ID找到某患者的全部發病記錄。經過整理(包括合并同一個患者的兩個患者ID的記錄和刪除不合適的數據),表中還剩下8757條記錄。部分代碼片段如圖3。
圖3? 部分代碼片段
第四步完成后,刪去的重復記錄是5條,得到的復發患者信息表有8757條記錄。
6? 結語
醫療系統包括各種各樣的醫療信息,其中早期使用最廣泛的數據表格主要是電子表格Excel,如何把相關表格導入到結構化數據庫中,表之間的關系如何,在用戶調研過程中要清楚,編程人員要找出表之間的關系,根據用戶需求,通過選擇不同的編程語言及數據庫,同時優化數據庫服務器,提高數據運行處理速度。還要注意算法的優化,比如在這個項目中同時用到了多個數據庫查詢,利用查詢之間的關系優化算法,使得多條查詢可以簡化為一條查詢。
參考文獻
[1] 周羿陽. 基于Hadoop的醫療輔助診斷系統的設計與實現[D].上海:東華大學,2016.
[2] 梁曉杰. 基于Hana的醫療大數據多維度挖掘[D].上海:東華大學,2016.
[3] 王培勛,李沖,劉曉歡.基于醫院信息數據挖掘的信息化臨床路徑在臨床醫療費用監控中的應用[J].中國醫學裝備,2019,16(4):110-113.
[4] 梁小玲.探討醫療大數據環境背景下健康信息的分析方法[J].信息技術與信息化,2018(6):87-88,91.
[5] 李偉,劉光明,張真發.基于MongoDB數據庫的臨床醫療大數據存儲方案設計與優化[J].工業控制計算機,2016,29(1):121-123.
[6] 阮彤,高炬,馮東雷,等.基于電子病歷的臨床醫療大數據挖掘流程與方法[J].大數據,2017,3(5):83-98.
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
電力與能源(2017年6期)2017-05-14 06:19:37
科技視界(2016年20期)2016-09-29 10:53:22
信息通信技術(2015年6期)2015-12-26 01:16:46
電子設計工程(2014年18期)2014-02-27 12:00:13
