基于訓(xùn)練集的自動(dòng)文摘方法的研究
2011-12-27 08:54:22程傳鵬
中原工學(xué)院學(xué)報(bào) 2011年1期
關(guān)鍵詞:方法
程傳鵬
(中原工學(xué)院,鄭州 450007)
基于訓(xùn)練集的自動(dòng)文摘方法的研究
程傳鵬
(中原工學(xué)院,鄭州 450007)
提出了一種基于訓(xùn)練集的自動(dòng)文摘方法.依據(jù)訓(xùn)練集所產(chǎn)生的主題詞,設(shè)計(jì)出一種新的段落加權(quán)公式和一種新的句子重要性加權(quán)公式,將生成的主題句消除冗余后得到文摘.測(cè)試結(jié)果表明,該方法具有一定的實(shí)用性.
訓(xùn)練集;主題詞;主題句;自動(dòng)文摘
自動(dòng)文摘就是利用計(jì)算機(jī)從文檔中提取盡可能少的句子,要求這些句子語意連貫,并且能夠最大限度地體現(xiàn)原文檔所要表達(dá)的中心思想.隨著Internet的迅猛發(fā)展以及無紙化辦公的普及,各種格式的電子文件大量涌現(xiàn).從這些電子文檔中迅速、準(zhǔn)確地進(jìn)行自動(dòng)文摘,已經(jīng)成為一項(xiàng)重要的研究課題.目前,自動(dòng)文摘的方法大體上可以分為2類:基于統(tǒng)計(jì)的機(jī)械文摘方法和基于理解的文摘方法[1].前者主要是簡(jiǎn)單的對(duì)詞頻(詞條在全文中所出現(xiàn)的次數(shù))進(jìn)行統(tǒng)計(jì),依照詞頻來確定主題詞,主題句的產(chǎn)生也只是依賴所包含主題詞的數(shù)量的多少.它的優(yōu)點(diǎn)是實(shí)現(xiàn)簡(jiǎn)單,文摘效率較高,但得到的文摘往往不能很好地體現(xiàn)原始文檔的中心思想.后者則是利用人工智能技術(shù),特別是自然語言理解技術(shù)為核心,在對(duì)文本進(jìn)行語法結(jié)構(gòu)分析的同時(shí),利用領(lǐng)域知識(shí)對(duì)文本的語義進(jìn)行分析,通過判斷推理,得出文摘句的語義描述,根據(jù)語義描述自動(dòng)生成摘要.這種方法雖然一定程度上彌補(bǔ)了機(jī)械文摘的不足,提高了文摘的質(zhì)量,但需要構(gòu)建復(fù)雜的推理規(guī)則,文摘生成過程所耗時(shí)間長(zhǎng),實(shí)時(shí)性能低劣.
文摘的質(zhì)量固然重要,但低劣的實(shí)時(shí)性也是不能接受的.基于此,本文提出了一種基于訓(xùn)練集的自動(dòng)文摘方法,首先對(duì)自動(dòng)文摘中主題詞的選擇、主題句的產(chǎn)生、文摘的生成等關(guān)鍵技術(shù)進(jìn)行了研究與分析.在此基礎(chǔ)上,設(shè)計(jì)出了一個(gè)自動(dòng)文摘原型系統(tǒng),最后對(duì)該方法進(jìn)行了實(shí)驗(yàn)和評(píng)價(jià).
1 關(guān)鍵技術(shù)分析
自動(dòng)文摘從原始文檔中提取最精簡(jiǎn)、最能體現(xiàn)原始文檔意思的語句,文摘的優(yōu)劣跟主題詞的選擇、主題句的選擇以及自動(dòng)文摘息息相關(guān).下面對(duì)這些關(guān)鍵技術(shù)進(jìn)行介紹.
1.1 主題詞的選擇
本文中,主題詞的界定參照了文檔分類中特征提取的方法,通過分詞后的文檔詞匯,數(shù)量是相當(dāng)大的,原始的特征空間可能由出現(xiàn)在文章中的全部詞條構(gòu)成.而中文的詞條總數(shù)有二十多萬條,這樣高維的特征空間對(duì)于幾乎所有的分類算法來說都偏大[2].為了提高分類的效率和精度,在分類之前必須進(jìn)行特征抽取來剔除那些表現(xiàn)力不強(qiáng)的詞匯.在主題詞的選擇過程中,給出如下的定義:
定義1訓(xùn)練集:由專家系統(tǒng)篩選出來的,具有某相近主題的文檔集合.本文用S來表示訓(xùn)練集.
定義2主題詞:最能代表訓(xùn)練集的一些詞條.本文用T來表示主題詞.
定義3主題詞權(quán)重:主題詞Ti在文檔中的重要程度.本文用TWi來表示第i個(gè)主題詞權(quán)重.
符號(hào)定義:
A:包含詞條t且屬于類別c的文檔頻數(shù).
B:包含t但是不屬于c的文檔頻數(shù).
C:屬于c但是不包含t的文檔頻數(shù).
N:語料中文檔總數(shù).
有了上面的定義后,主題詞的選擇步驟如下:
(1)對(duì)訓(xùn)練集中所有的文檔進(jìn)行分詞,分詞后得到的詞條,都作為候選主題詞.
(2)采用互信息的方法選取主題詞.互信息是信息論中的概念,它用于度量一個(gè)消息中2個(gè)信號(hào)之間的相互依賴程度[3].對(duì)于每個(gè)候選主題詞,計(jì)算候選主題詞t和訓(xùn)練集類c的互信息量:
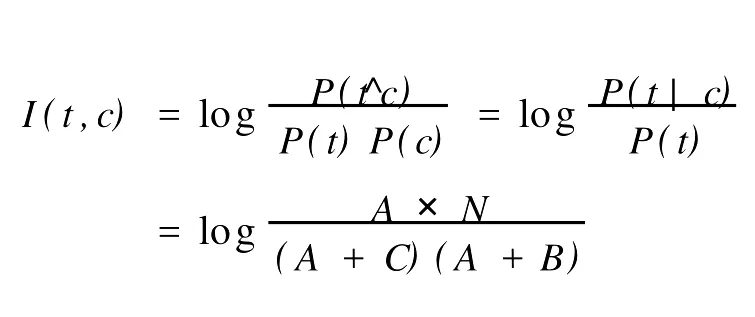
式中:I(t,c)表示候選主題詞和類別c之間的互信息量;P(t^c)表示候選主題詞t和類別c同時(shí)出現(xiàn)的概率;p(t)表示候選主題詞t出現(xiàn)的概率;p(c)表示類別c出現(xiàn)的概率;p(t|c)表示類別c里出現(xiàn)候選主題詞的概率.
(3)對(duì)訓(xùn)練集中的所有候選主題詞,依據(jù)上面計(jì)算的互信息量進(jìn)行排序.
(4)依據(jù)詞的互信息量大小,抽取一定數(shù)量的詞作為主題詞.
1.2 段落權(quán)重計(jì)算以及主題句選擇
同一篇文章中,不同的段落,具有不同的重要程度,段落中所包含的主題詞數(shù)量、段落的長(zhǎng)度,都決定著段落在整篇文檔中的重要性.此外,經(jīng)過對(duì)大量文檔的觀察,我們發(fā)現(xiàn),一個(gè)句子是否能夠成為主題句,不僅與句子所在的段落的重要性有關(guān),而且和句子的長(zhǎng)度(SL)、句子在段落中的位置(SP)以及句子中所包含的主題詞個(gè)數(shù)(f)有著密切的聯(lián)系.
在主題句的選擇過程中給出如下的定義:
定義4段落:是按照中文習(xí)慣所形成的語言段落.本文用P來表示段落.
定義5段落權(quán)重:一個(gè)段落在整篇文檔中的重要程度.本文用PW來表示段落權(quán)重.
定義6句子:按照中文標(biāo)點(diǎn)符號(hào)分割成的,由字、詞、詞組所組成的語言單位.本文用S來表示句子.
定義7句子權(quán)重:句子在整篇文檔中的重要程度.本文用SW來表示句子權(quán)重.
主題句產(chǎn)生的步驟如下:
(1)對(duì)用戶提交的待摘要文檔進(jìn)行段落劃分,形成段落集{P1,P2,P3…Pi…Pn}.
(2)對(duì)段落Pi進(jìn)行中文分詞,計(jì)算每個(gè)段落的權(quán)重.計(jì)算公式如下:

式中:WTi為段落中出現(xiàn)的主題詞的權(quán)重;fi為該主題詞在段落中出現(xiàn)的頻率;PLi為段落的長(zhǎng)度;DL為整篇文檔的長(zhǎng)度.
(3)計(jì)算句子SWi的權(quán)重.計(jì)算公式如下:
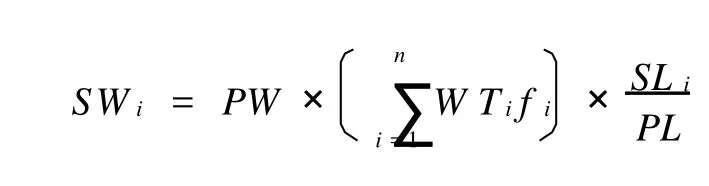
式中:PW為主題詞所在段落的權(quán)重;fi為該主題詞在段落中出現(xiàn)的頻率;SL為段落的長(zhǎng)度;PL為主題詞所在段落的長(zhǎng)度.
(4)對(duì)所有句子,依照權(quán)重大小進(jìn)行排序,選擇權(quán)重最大的N個(gè)句子作為主題句.N的大小跟生成的文摘長(zhǎng)度有關(guān).
1.3 文摘的生成
自動(dòng)文摘應(yīng)該以盡可能少的文字,最大程度地體現(xiàn)原文所表達(dá)的意思.通過以上2個(gè)步驟所得到的主題句,并不能完全作為文摘提交給用戶.因?yàn)榻?jīng)過系統(tǒng)初步篩選出的主題句,往往具有較多的冗余信息.常見的冗余信息有以下3種:
(1)語意相似.比如下面2個(gè)語意相似的句子:①吳文俊老師在拓?fù)鋵W(xué)領(lǐng)域取得了豐碩的成果;②吳文俊老師在拓?fù)鋵W(xué)方面獲得了驕人的成就.(2)同一主語.除了語意相似產(chǎn)生的信息冗余外,相鄰主題句如果主語相同,也會(huì)產(chǎn)生文摘的信息冗余.比如下面2個(gè)句子:
①吳文俊是著名的數(shù)學(xué)家,他的研究工作涉及到數(shù)學(xué)的諸多領(lǐng)域;
②吳文俊的主要成就表現(xiàn)在拓?fù)鋵W(xué)和數(shù)學(xué)機(jī)械化2個(gè)領(lǐng)域.
(3)過渡性詞語.在主題句里,有時(shí)會(huì)出現(xiàn)一些承上啟下的連詞或者轉(zhuǎn)折詞,這些詞條對(duì)文摘沒有任何意義,只是在原文中起到一種過渡的作用.比如:“因?yàn)椤?“也就是說”,“對(duì)我來說”.
基于以上原因,我們還要對(duì)主題句經(jīng)過相似度比較并且對(duì)主題句進(jìn)行壓縮,對(duì)于語意相似的句子,進(jìn)行刪減;對(duì)于主語相同的相鄰主題句,保留一個(gè)主語;對(duì)于過渡性詞語,在分詞時(shí)利用停止詞表進(jìn)行剔除.對(duì)主題句經(jīng)過上面步驟處理后,按照主題句在原文中的順序進(jìn)行輸出,最終產(chǎn)生較為理想的文摘.
2 系統(tǒng)實(shí)現(xiàn)
在上述分析的基礎(chǔ)上,我們采用VC++6.0開發(fā)平臺(tái),設(shè)計(jì)出了一個(gè)自動(dòng)文摘系統(tǒng)原型.本系統(tǒng)包含主題詞生成模塊、文摘生成模塊、用戶接口模塊.系統(tǒng)結(jié)構(gòu)圖如圖1所示.
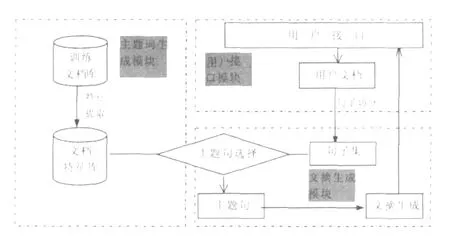
圖1 自動(dòng)文摘系統(tǒng)模型
下面對(duì)系統(tǒng)中各模塊作簡(jiǎn)要介紹:
(1)主題詞生成模塊.從詞典數(shù)據(jù)庫(kù)里讀出詞條,按照漢字的 GBK編碼在機(jī)器內(nèi)存中建立詞典.從網(wǎng)頁(yè)庫(kù)里依次讀出所有的主題網(wǎng)頁(yè),按照最大匹配法的分詞方法(未登錄詞的識(shí)別按照統(tǒng)計(jì)的方法)對(duì)網(wǎng)頁(yè)進(jìn)行分詞.對(duì)分詞得到的所有詞條去掉停止詞后,進(jìn)行特征提取,提取出最能表現(xiàn)該領(lǐng)域主題的特征詞,即主題詞.
(2)文摘生成模塊.其功能是將對(duì)用戶提交的文檔進(jìn)行段落劃分,計(jì)算段落的權(quán)重,依照詞條的權(quán)重以及主題詞所在段落的權(quán)重,確定一個(gè)句子是否能成為主題句.對(duì)主題句進(jìn)行冗余信息消除后,生成文摘.
(3)用戶接口模塊.該模塊為用戶提供可視化的查詢輸入和結(jié)果輸出界面.在輸入界面中,用戶可以提交待摘取的文檔.在輸出界面中,系統(tǒng)提交給用戶較為理想的文摘.
3 實(shí)驗(yàn)結(jié)果及分析
目前,還沒有一種很好的自動(dòng)文摘的評(píng)價(jià)方法,我們采用了文獻(xiàn)[4]所提到的一種評(píng)價(jià)指標(biāo):主題覆蓋度,即原文中的主題內(nèi)容被文摘句所覆蓋的百分比.主題覆蓋度的值可通過多個(gè)人工專家分別打分,所取得分的平均值來確定.這里假設(shè)人工專家主題覆蓋度為100%,經(jīng)過實(shí)驗(yàn)形成如表1所示的數(shù)據(jù).

表1 實(shí)驗(yàn)結(jié)果
從表1可以看出,本文中的方法在時(shí)間性能上要優(yōu)于基于理解的方法,而在主題覆蓋度上又優(yōu)于機(jī)械統(tǒng)計(jì)的方法.因此,本文中所提出的方法,在提高了文摘主題覆蓋度的同時(shí),又兼顧了時(shí)間性能,具有一定的實(shí)用性.
4 結(jié) 語
隨著互聯(lián)網(wǎng)的迅猛發(fā)展以及無紙化辦公的普及,會(huì)涌現(xiàn)出大量的電子文檔,如何快速準(zhǔn)確地從繁多的文檔中提取“主題思想”,已經(jīng)成為自動(dòng)文摘需要迫切解決的一個(gè)課題.本文提出了一種基于訓(xùn)練集的文摘自動(dòng)生成方法,實(shí)驗(yàn)結(jié)果表明,該方法所產(chǎn)生的主題句能夠較好地體現(xiàn)原始文檔的中心思想,能較全面地表達(dá)原文檔的內(nèi)容.該系統(tǒng)生成的文摘,比較適合一些對(duì)文摘實(shí)時(shí)性要求較高,但對(duì)文摘質(zhì)量不是過于苛刻的場(chǎng)合.
[1]傅間蓮,陳群秀.基于規(guī)則和統(tǒng)計(jì)的中文自動(dòng)文摘系統(tǒng)[J].中文信息學(xué)報(bào),2006,20(5):10-16.
[2]代六玲.中文文本分類中特征抽取方法的比較研究[J].中文信息學(xué)報(bào),2004,24(1):26-32.
[3]李粵,李星,劉輝,等.一種改進(jìn)的文本網(wǎng)頁(yè)分類特征選擇方法[J].計(jì)算機(jī)應(yīng)用,2004,24(7):119-121.
[4]胡拍,何婷婷,姬東鴻.基于主題區(qū)域發(fā)現(xiàn)的中文自動(dòng)文摘研[J].計(jì)算機(jī)應(yīng)用,2005,32(1):177-181.
Research of Automatic Abstraction Method Based on Training Set
This paper p roposes a method of automatic abstraction based on training set.Keyword is p roduced acco rding to training set,and a new paragraph w eighting fo rmula and a new sentence impo rtance w eight formula are designed.Abstraction obtained through the elimination of redundant topic sentence.Experiments show that the system has a certain utility.
training set;topic words;topic sentence;automatic abstraction
CHENG Chuan-peng
(Zhongyuan University of Technology,Zhengzhou 450007,China)
TP391.1
A
10.3969/j.issn.1671-6906.2011.01.017
1671-6906(2011)01-0062-04
2011-01-03
程傳鵬(1977-),男,河南鄭州人,講師,碩士.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(bào)(2021年2期)2021-05-25 02:07:46
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56
