基于內容管理技術的檔案網站信息資源整合
2011-12-27 09:20:42岳修志趙建建
中原工學院學報 2011年1期
岳修志,趙建建
(中原工學院,鄭州 450007)
基于內容管理技術的檔案網站信息資源整合
岳修志,趙建建
(中原工學院,鄭州 450007)
基于內容管理技術,分析了檔案網站信息資源整合的現狀,總結出了元數據模型信息提取和存儲的方法.
檔案網站;內容管理;信息資源整合;元數據
隨著信息技術的發展,目前大多數檔案館都實現了在B/S模式下的網上辦公,通過網絡環境將“有形”的紙制檔案轉化成網上無紙辦公.檔案網站提供的信息資源越來越多,種類也越來越豐富.縱觀各個檔案館,電子檔案往往只是紙質檔案的數字化,各個檔案館只是一個信息孤島,缺少資源共享.用戶面對眾多分散的網站檔案信息往往無所是從,因此迫切需要整合各個網站的檔案信息,以提高用戶檢索效率.內容管理是信息資源管理的核心部分,目前的數據庫技術主要是解決結構化的信息資源的管理,而內容管理技術是解決非結構化信息資源管理的有效方法.對檔案資源整合而言,內容管理技術是提高信息資源管理效率的關鍵環節[1].
1 內容管理技術
內容管理(Content M anagement,CM)是指對組織機構內部多種格式和媒體類型的信息資源的組織、分類、管理等有序化的過程[2].其基本思想是分離內容的管理和設計,頁面美工的設計存儲在模板里,而內容存儲在數據庫或者獨立的文件中[3].內容管理能夠使網站使用通用的設計元素和模板,以確保整個網站的協調.
一個內容管理系統至少要包含以下4個子系統[4]:
(1)內容收集系統:進行內容的收集、獲取、分發、編輯、整合及轉換等工作,并可加入元數據以支持對內容組件的定義及搜尋.
(2)管理系統:負責組件、內容及發布模板的存取管理,并可記錄內容的版本、工作流程的狀態、權限的設定及更新處理等.
(3)發布系統:負責將內容快速且自動地按照所建立的發布模板送至瀏覽器端.
(4)工作流系統:負責整個內容的收集、儲存和發布.
檔案網站內容管理系統屬于資源型網站,其結構比較復雜,主要包含以文章發布為中心的文檔資源類欄目以及圖片資源、視頻類、光盤類資源的發布等.
2 檔案網站的信息資源整合
2.1 檔案網站信息資源整合的涵義及現狀分析
檔案網站信息資源整合是指根據檔案用戶的利用需求,結合檔案網站信息資源整合的特點,利用先進的技術,按照一定的原則、規范及標準,實現一定范圍內的檔案網站信息資源的抓取與優化,并組織成一個集關聯性、動態性和實用性于一體的有機整體或者統一的利用平臺[5].
目前,我國檔案網站已經初具規模,但隨著檔案網站的增多,檔案網站信息資源的充分整合是目前我們必須要解決的問題.檔案網站在信息資源整合方面主要存在以下不足[6].
(1)整合層次較低.資源建設主要以館藏為主,從而形成一個個“信息孤島”,用戶面對零落的、離散的資源,不知道如何尋找自己需要的信息.
(2)資源整合缺乏規范性.網站類目組織的一致性、檢索平臺的統一性需要加以規范.
(3)重資源建設,輕資源利用.在資源整合技術的選擇上,只是針對資源的特點來進行堆積,片面重視資源數量,而不是從用戶利用的角度來合理整合資源,缺乏導航服務和個性化服務等.
2.2 內容管理技術在信息資源整合中的優勢
(1)統一了管理標準.網站內的內容格式和處理方式標準化,統一了頁面的現實風格,增強了網站的擴展能力.
(2)統一了訪問接口.利用XML技術能夠描述各種不規則的數據,因此可以將文檔等半結構化的數據納入到同一個XML文件并傳送到客戶端[7].
(3)相對傳統的Web網站,負載能力強.
(4)內容管理系統提供強大的二次開發平臺,降低了開發難度.
(5)網頁呈現和內核技術、日常發布和系統維護等完全分離,使得日常操作非常簡單,降低了維護成本[8].
2.3 內容管理技術在檔案網站信息資源整合中的應用
內容管理系統主要是支持異構平臺上的各種類型信息的管理和訪問,而信息包含結構化形式和非結構化形式的信息,如何管理這些信息成為檔案網站信息資源整合的關鍵.結構化信息可以直接存儲到關系數據庫中;而對于非結構化信息如何處理,成為檔案網站信息資源整合的關鍵.
非結構化信息一般采用元數據模型進行描述.元數據是描述一個具體的資源對象,能對這個對象進行定位、管理,并有助于資源的發現與數據的獲取,是關于數據的數據[9].下面介紹內容管理的2個主要方面:元數據的提取和元數據模型的存儲.
2.3.1 元數據的提取
根據元數據標準和國內圖書情報領域的相關成果,依據都柏林核心元素規范,總結出檔案網站元數據,如表1所示.
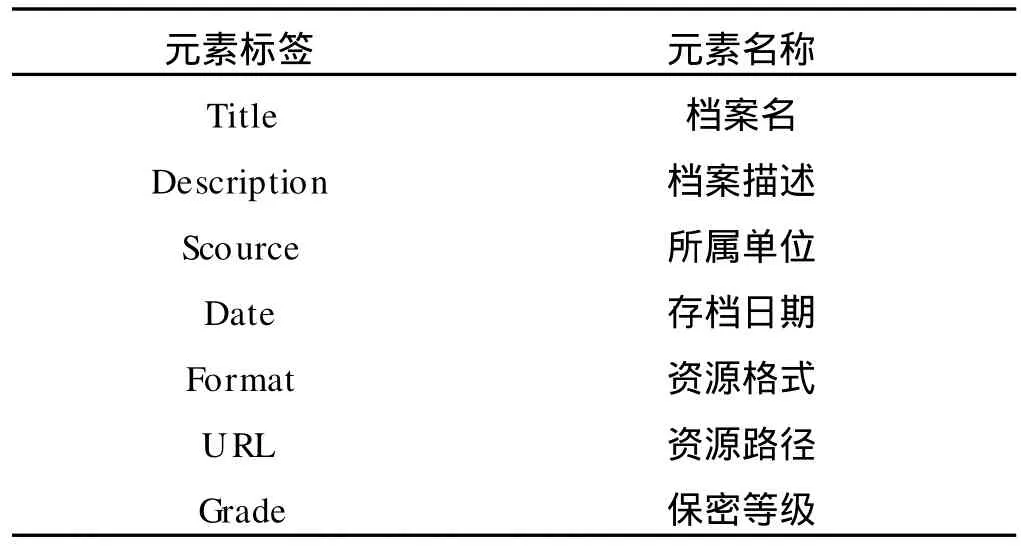
表1 檔案網站內容管理元數據表
Web頁面以 Html形式存在,我們為了收集內容,必須將Htm l源文件的 Html標記和文本區分開來,從而將文本形成2個Stream:Htm l標記Stream和文本Stream.這樣Web網頁內容就轉換成容易處理的形式.
目前,從Web頁面中提取所需要的元數據信息的方法主要有[10]:利用包裝器 W rapper技術,基于層次結構的信息抽取及基于概念模型的多記錄信息提取;以W 3C的文檔對象模型DOM為基礎,把提取的信息以DOM層次結構中的路徑表達式來表示,通過歸納學習來獲得所需信息的路徑表達式,達到提取信息的目的.利用包裝器W raaper技術工作量大,而且不便于推廣.本文主要介紹以DOM為基礎的元數據提取.其過程描述如下:
(1)利用DOM 提供的API分析文本信息,生成每個頁面對應的DOM樹型結構;
(2)提供檔案網站內容管理元數據表;
(3)以元數據表和DOM樹為輸入,學習生成提取規則;
(4)使用提取規則提取數據,完成信息的提取.
2.3.2 元數據模型的存儲
XML(Extensible Markup Language,可擴展標記語言)是由W 3C組織于1998年2月發布的一種標準.XML是自描述的、半結構化的和可擴展的標記語言.由于XML非常適合描述非結構化數據,一般元數據模型的存儲都采用XML技術.
目前,XML數據管理的方式主要有文件系統方式、Native XML存儲方式、關系數據庫存儲方式和面向對象XML數據存儲方式.在內容管理系統應用上,上述4種方式各有特點,對XML的存儲一般采用關系數據庫存儲方式.
要想將XML文檔存儲到關系數據庫中,需要建立從XML到關系數據庫的映射關系.目前,映射方法主要有3種:
(1)直接將整個XML文檔數據作為關系數據庫表的一個屬性進行存儲;
(2)基于XML結構樹,將結構樹中具有相同語義的父子節點用嚴格的二元聯系模式來表示,這樣能充分利用語義的直觀性,確保查詢的效率;
(3)假設每個XML文檔都有相應的DTD與之對應,然后對D TD進行簡化、分解等預處理,將D TD中的元素、屬性映射成關系模式.這樣,XML可以最大限度地利用底層RDBM S提供的查詢處理和優化技術[11].
建立映射機制后,下一步就要完成XML到關系數據庫的存儲.XML標準提供了標準接口DOM、DSO來存取數據.DOM可以為不同的開發平臺和開發語言提供一致的API.XML文檔是按照層次結構組織起來的樹形結構,所以DOM可以把XM L文件看成樹形結構,文件中的每一部分數據信息相當于樹節點.采用樹形結構,方便了 XML文檔的增加、刪除、修改、查詢等操作.DSO技術可以完成H tm l標記同XM L節點數據的綁定,以方便從XML文檔中讀取或者寫入數據.XML數據存取機制如圖1所示.
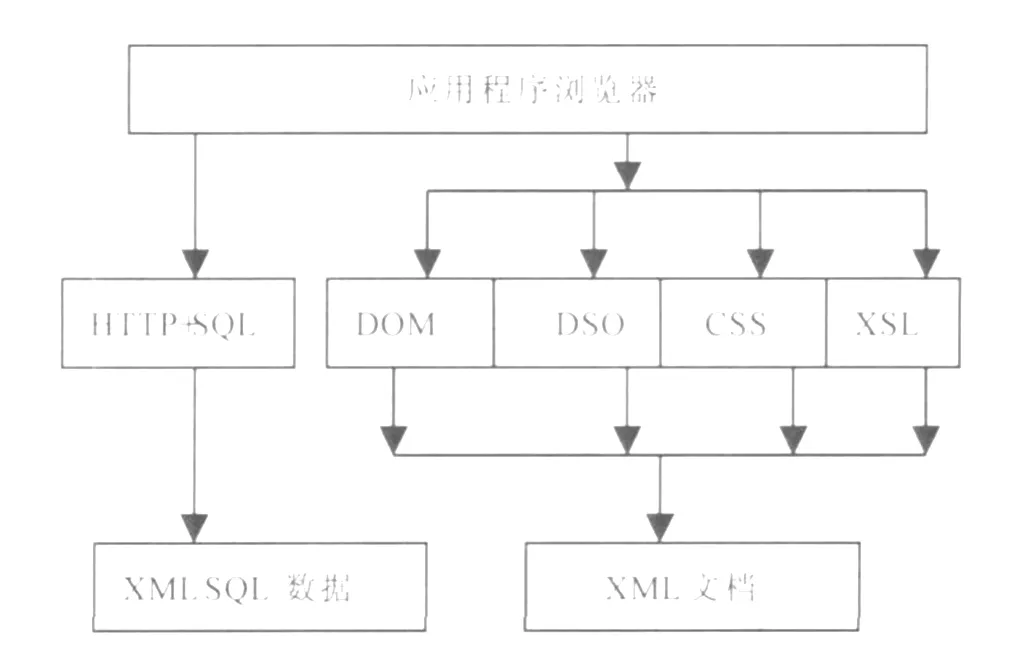
圖1 XML數據存取機制
3 結 語
檔案網站信息資源整合的難點是異構平臺及非結構化數據的整合問題,整合的目的就是將各種不同類型的信息資源,利用內容管理技術,通過元數據模型或者提供中間件的方式整合成相聯系的統一平臺,便于用戶檢索,提高檔案網站的交互性,更好地滿足用戶的需求.
[1]王芳,郭英.電子政務內容管理及其應用分析[J].理論與探索,2009(6):47-50.
[2]孔佳.內容管理系統的產生與發展[J].農業網絡信息,2008(3):89-92.
[3]宮生文,穆江波.基于ASP.NET 2.0的內容管理系統的設計與實現[J].科技信息,2009(1):487-488.
[4]徐小靜.基于XML的內容管理與內容發布技術系統的研究[D].武漢:武漢理工大學,2005:22-23.
[5]吳建華,方燕平.檔案網站信息資源及其整合概念的界定——“檔案網站信息資源普查與整合研究”系列論文之一[J].檔案學通訊,2009(5):52-55.
[6]杭珊,吳建華.檔案網站信息資源整合現狀及分析[J].學術園地,2009(9):15-19.
[7]向培素,黃勤珍.內容管理系統中統一訪問接口的實現[J].中國測試技術,2003,9(5):61-63.
[8]陳曉慧.基于內容管理的網站自動化生成系統的開發與實現[J].計算機科學,2005,2(32):106-108
[9]姜波.基于XML的企業內容管理系統的研究[D].武漢:武漢理工大學,2009:24-26.
[10]劉政怡.基于DOM和元數據的Web信息提取[J].計算機與現代化,2003(10):106-108.
[11]崔清華.XML文檔在關系數據庫中的存儲研究[J].微計算機信息,2007,4(23):184-186.
Information Resources Integration of ArchivesWeb Site Based on Content Management Technology
YUE Xiu-zhi,ZHAO Jian-jian
(Zhongyuan University of Technology,Zhengzhou 450007,China)
Information resources integration is the core issue of archives Web site information.Based on content management technology,the statusof information resources integration are analyzed,and information extraction and storage methods of metadata model are summed up.
archives Web site;content management;integration of information resources;metadata
G270.7
A
10.3969/j.issn.1671-6906.2011.01.010
1671-6906(2011)01-0039-03
2011-01-08
河南省檔案局科技項目(2010-X-43)
岳修志(1972-),男,河南獲嘉人,副研究館員.
猜你喜歡
科學大眾(2022年11期)2022-06-21 09:20:52
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
臺聲(2016年2期)2016-09-16 01:06:53
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
