基于本體的多專業領域知識語義檢索系統研究
2011-12-26 07:47:10劉紫玉楊國霞李學會
河北科技大學學報 2011年5期
劉紫玉,楊國霞,李學會
(1.河北科技大學經濟管理學院,河北石家莊 050018;2.河北科技大學信息科學與工程學院,河北石家莊 050018)
基于本體的多專業領域知識語義檢索系統研究
劉紫玉1,楊國霞2,李學會2
(1.河北科技大學經濟管理學院,河北石家莊 050018;2.河北科技大學信息科學與工程學院,河北石家莊 050018)
多專業領域是指由多個專業構成的學科領域,如高速鐵路領域由工務工程、牽引供電、動車組、運營管理等專業領域構成。對于多專業領域本體的構建,可以先構建各個專業領域本體,然后根據專業領域之間的關系進行本體集成。面向多專業領域,在本體模型的基礎上提出了多專業領域本體模型,并給出了多專業領域本體概念語義相似度計算模型,此模型可作為語義擴展的基礎。在此基礎上,設計了一個基于本體的多專業領域知識語義檢索系統,并以高速鐵路領域為背景對提出的語義檢索系統進行實驗驗證,從測試結果來看,開發的語義檢索系統可以獲取較高的準確率和召回率。
本體;多專業領域;語義檢索;高速鐵路領域
本體在知識管理、人工智能、信息檢索、Web服務發現等領域中扮演著越來越重要的角色。根據領域依賴程度,可以將本體分為通用本體、領域本體、任務本體和應用本體[1]。領域本體可以有效地組織領域中的知識,使知識更好地共享、重用。
對于多專業領域本體的構建,可以先構建各個專業領域本體,然后根據專業領域之間的關系進行本體集成。在本文中作以下定義:由多個專業領域構成的領域定義為“多專業領域”,如高速鐵路領域;基于每個專業領域構建的本體稱為“專業領域本體”,如動車組專業領域本體;由多個專業領域本體集成的統一本體稱為“多專業領域本體”,如將高速鐵路的動車組專業領域本體、牽引供電專業領域本體等集成后的本體稱為“高速鐵路多專業領域本體”。多專業領域本體構建方法本文不進行詳細說明,可以參見相關作者的文章[2]。
筆者面向多專業領域,在本體模型的基礎上提出了多專業領域本體模型,并給出了多專業領域本體概念語義相似度計算模型,此模型可作為語義擴展的基礎。在此基礎上,設計了一個基于本體的多專業領域知識語義檢索系統。最后以高速鐵路領域文獻資料知識作為實驗對象,對本文提出的語義檢索系統進行實驗分析,從測試結果來看,開發的語義檢索原型系統可以獲取較高的準確率和召回率。
1 概念語義相似度計算模型
1.1 本體模型
關于本體(Ontology)的定義有許多,目前獲得較多認同的是STUDER等的解釋[3]:“Ontology是對概念體系的明確的、形式化的、可共享的規范說明”。
定義1 一個完整的本體應由概念、關系、函數、公理和實例等5類基本元素構成。本體可以表示為
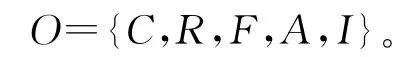
其中:C為概念,概念是指客觀世界中任何事物的抽象描述,在本體中通常按照一定的關系形成一個層次結構;
R?2C×C,概念之間的關系,如“subclass-of”關系、“part-of”關系等;
F?Rn是一種特殊的關系,其中第n個元素cn相對于前面n-1個元素是唯一確定的,函數F可以表示為c1×c2×…×cn-1→cn;
A為概念或者概念之間的關系所滿足的公理,是一些永真式;
I為領域內概念實例的集合。
1.2 領域本體模型
在實際的領域本體中,由于概念之間不僅僅存在著上下位關系,概念之間還通過其他各種關系可以連接,尤其在多專業構成的領域本體中還有許多自定義的關系,這使得概念的組織形式并不完全是一個樹型結構,而是一個網狀結構。因此,根據多專業領域本體的特點,在本體模型的基礎上重新構建了領域本體模型。
定義2 領域本體模型是一個八元組:DO={C,P,Hc,Rs,Rud,I,F,A}。其中:DO 表示領域本體;C 表示概念(或稱為類);P表示領域本體中Datatype類型屬性;Hc表示類間的上下位(subclass-of)二元關系;Rs表示類間的同義(synonymy)關系;Rud表示類間的用戶自定義(user-defined)關系(包括part-of關系也用自定義關系來描述),也就是類的ObjectProperty;I表示領域內概念實例的集合;F表示概念間一種特殊的關系,可以表示為c1×c2×…×cn-1→cn;A表示領域本體中概念或者概念之間的關系所滿足的公理,是一些永真式。
定義3 概念C 的模型是一個九元組:C={P,Csc,Cuc,Cs,Cr,Hc,Rs,Rud,Ic}。其中:P 表示概念C 的Datatype類型屬性;Csc表示概念C的子概念(subclass);Cuc表示概念C的父概念(upperclass);Cs表示概念C的同義概念(equivalentclass);Cr表示與概念C有關系的概念;這里主要指通過用戶自定義關系聯系起來的概念;Hc表示概念C的上下位關系;Rs表示概念C的同義(synonymy)關系;Rud表示概念C的用戶自定義(user-defined)關系;Ic描述概念C 的實例。
概念之間的關系主要分為3類:1)上下位關系,用Csc,Cuc和Hc表示;2)同義關系,用Cs和Rs表示;3)用戶自定義關系,用Rud表示。
1.3 概念語義相似度計算模型
1.3.1 模型組成描述
傳統本體概念間相似度計算的不足在于其語義關系只考慮了層次語義關系,沒有考慮語義關系中非層次關系的影響,同時對象實例對于概念的影響也沒有考慮。筆者在定義3的基礎上,提出了計算概念之間相似度的模型,該模型全面考慮了本體概念模型中各種元素對相似度的影響,考慮的元素主要包括屬性(Datatype類型屬性)、上下位語義關系、其他語義關系(自定義關系)和實例特征。
1.3.2 MD4模型概念語義相似度算法
在同一本體中,概念相似度計算首先需要檢查2個概念是否同義。如果2個概念同義,那么2個概念是完全相似的,其相似度為1。
1)上下位關系語義相似度計算
在領域本體中,只考慮上下位關系時的本體模型為樹型結構。計算上下位關系語義相似度時采用基于距離的概念相似度計算方法。筆者參考陳杰等人的算法,綜合考慮概念距離和層次對概念相似度的影響[4],算法公式如下:
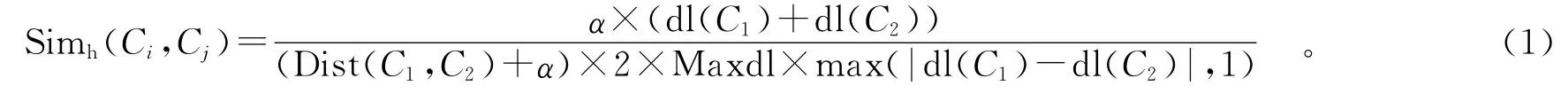
式中dl(C1)和dl(C2)分別是C1和C2所處的層次;Dist(C1,C2)是概念C1和C2之間的本體樹中的最短路徑;Max樣dl是指本體樹的最大深度,在這里除以該參數是便于計算結果的歸一化處理;α是一個可調節參數,一般α≥0。
2)自定義關系語義相似度計算
假設有2個非同義概念Ci和Cj,根據定義3中的概念模型表示方法,可得到概念Ci對應的p個自定義關系集Rudi和p個自定義關系對應的m個概念集Cri,概念Cj對應的q個自定義關系集Rudj和q個自定義關系對應的n個概念集Crj。這里,每個集合中不存在相同的元素。
當2個自定義關系進行比較時,如果2個關系是相同的,那么相似度為1,否則相似度為0。
自定義關系相似度計算公式如下:
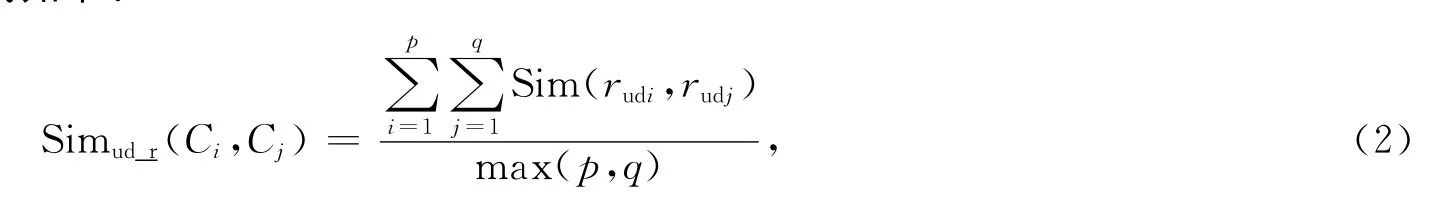
其中p和q分別是概念Ci和Cj對應的自定義關系的個數。
自定義關系對應的概念之間的相似度計算使用式(1),綜合相似度計算公式為
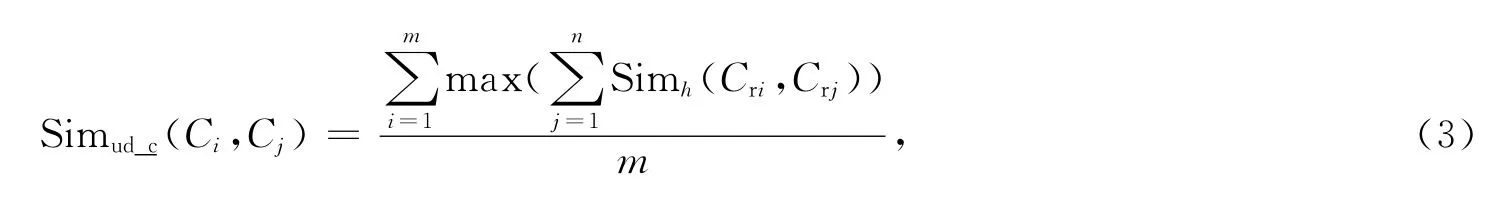
其中m是Ci的p個自定義關系對應的概念個數,n是Cj的q個自定義關系對應的概念個數。
在領域本體中,Ci和Cj通過自定義關系體現出的相似度Simud(Ci,Cj)為
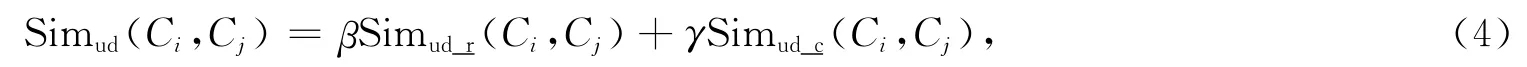
其中β,γ分別表示2種相似度的權重(可簡單設定β=γ=0.5),0≤β≤1,0≤γ≤1,β+γ=1。
3)概念Datatype類型屬性相似度計算
當2個Datatype型的屬性進行比較時,如果2個屬性是相同的,那么相似度為1,否則相似度為0。首先確定Ci和Cj的屬性集Pi和Pj,概念Ci和Cj分別對應m和n個Datatype類型的屬性(DatatypeProperty),然后對屬性集合Pi和Pj進行笛卡爾乘積Pi×Pj,得到配對集,再計算Ci和Cj的屬性相似度Simp,得到Ci和Cj的屬性相似度計算公式為
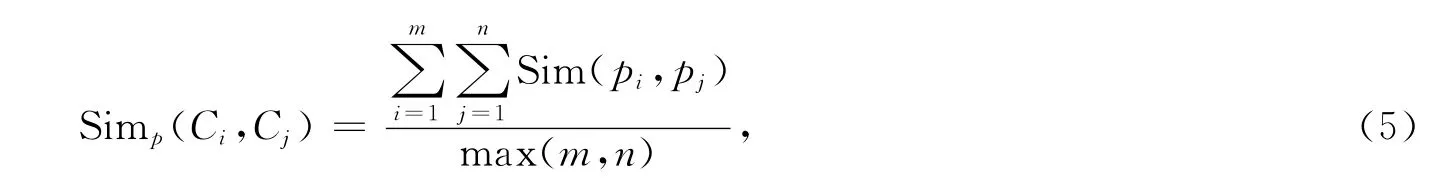
其中,m和n分別是概念Ci和Cj的Datatype類型屬性的個數。
4)實例語義相似度計算
實例語義相似度的計算采用和概念Datatype類型屬性相似度計算相同的算法。Ci和Cj的實例語義相似度計算公式為
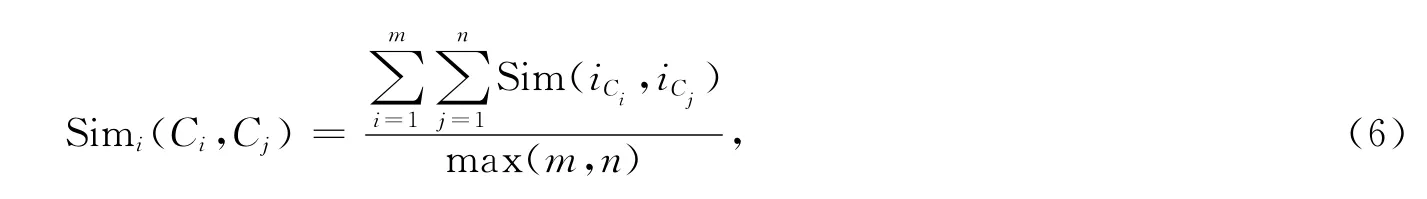
式中:m和n分別是概念Ci和Cj的實例的個數;iCi和iCj表示概念Ci和Cj的某個實例。
5)領域本體中非同義概念實際相似度計算
將上述4種相似度加權綜合,得到非同義概念Ci和Cj的實際相似度計算公式為
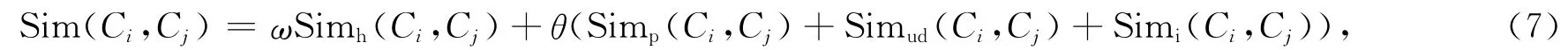
其中ω,θ分別表示權重,0<ω<1,0<θ<1,ω+θ=1,一般ω較大。
2 語義檢索系統結構
本文設計的語義檢索系統[5]分為4個大的功能模塊:本體查詢、文獻語義預處理與概念語義相似度預計算、語義擴展檢索和推理檢索,具體結構如圖1所示。
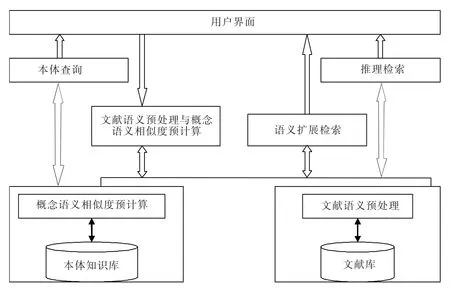
圖1 系統結構圖Fig.1 Architecture of semantic retrieval system
用戶界面主要和用戶進行交互,系統提供4種功能:第1種是本體查詢,可以查詢所建本體的概念、概念屬性、概念實例等;第2種是語義擴展檢索,用戶以關鍵字形式表達查詢意圖;第3種是推理檢索,使用本體規則和公理進行推理檢索;第4種是系統給用戶提供對文獻語義預處理與概念語義相似度預計算進行操作的界面。
本體知識庫以OWL文件的形式存儲領域本體知識,文獻庫存儲進行語義標注過的領域文獻知識。
2.1 本體查詢
這一模塊的主要功能是使用戶可以方便查詢本體知識庫中所建本體的概念、概念屬性、概念實例等。
2.2 文獻語義預處理與概念語義相似度預計算
文獻語義預處理與概念語義相似度預計算的主要結構如圖2所示。該模塊主要包括2個部分:文獻語義預處理和概念語義相似度預計算。文獻語義預處理主要是對文獻事先進行語義標注,按照用本體庫中定義好的概念對文獻進行標引。語義相似度預計算事先對本體庫中的概念進行語義相似度計算,根據本文的式(7)進行相似度值的計算,并在本體庫中保留相似度值,方便語義擴展檢索模塊進行查詢關鍵字的擴展。
文獻語義標引的最終目的是獲得文檔的語義向量,對本體解析后可以遍歷本體中的概念對一篇文檔進行標引,關鍵是如何確定標引概念對應的權重,即這個概念相對于這篇文檔的重要性。過去的研究表明,詞頻和位置在反映標引詞和文獻主題的關系上起著重要的作用,筆者采用山西大學鄭家恒等人提出的非線性函數和“成對比較法”相結合的方法,綜合考慮位置和詞頻2個因素[6],最終給出標引概念的權重。對于標引文檔的概念和其對應權重,采用一維向量的形式來表示,文獻的語義特征向量就由這2個一維向量來表現。
文檔語義表示之后的概念向量和權重向量如下:

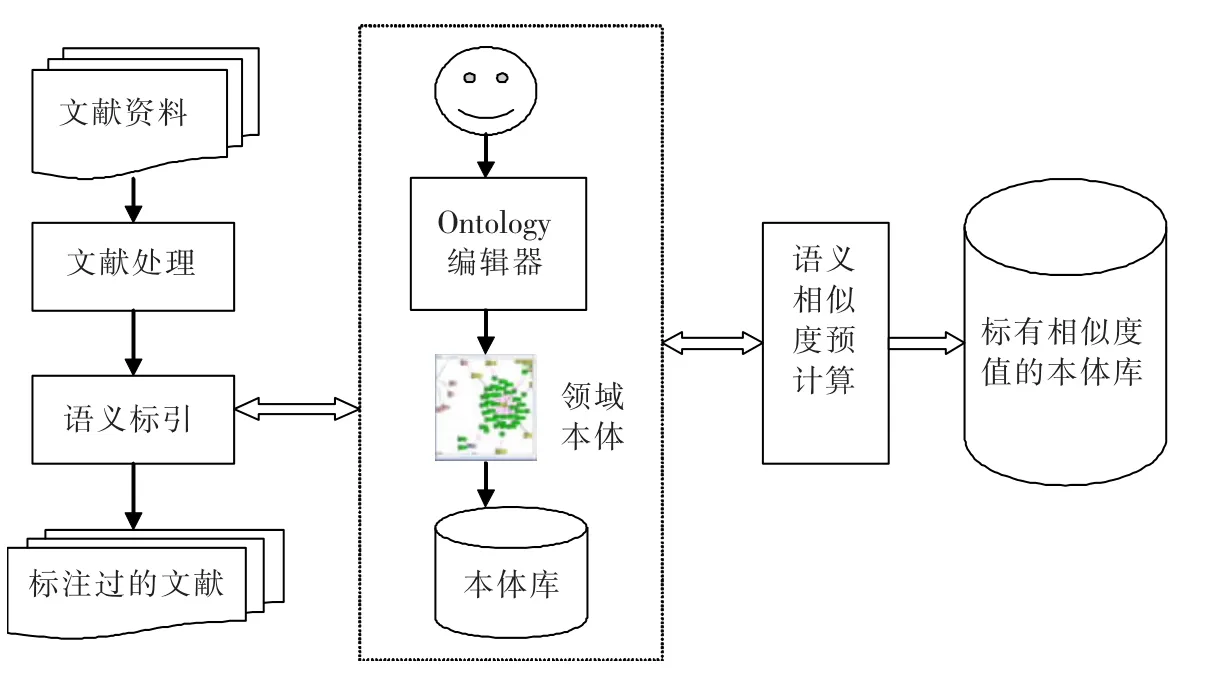
圖2 文獻語義預處理與概念語義相似度預計算結構圖Fig.2 Process structure of semantic precomputation for document and the concept similarity
2.3 語義擴展檢索
語義擴展檢索模塊的主要功能是把用戶輸入的查詢詞進行語義擴展,然后把語義擴展向量和從文獻語義預處理模塊中取出的標引向量進行相似度計算,計算后得到的相似度與用戶設立的閾值進行比較,如果大于閾值則文獻與查詢相關,返回該文檔查詢結果,并按照相似度大小將排序后的文獻列表返回給用戶界面。
用戶查詢詞經過概念語義相似度計算擴展以后,語義擴展向量可以用擴展后的概念向量(包括用戶輸入的查詢概念詞)和對應的權重向量來表現,這2個向量用一維向量的形式表示。

計算文檔語義特征向量和用戶查詢語義擴展向量的語義相似度,本文借鑒的方法,首先計算兩兩概念之間的語義相似度,然后計算2個向量之間的語義相似度[7]。
對于文檔語義特征向量Document(1)中的概念c1i,其對應的權重為w1i,用戶查詢語義擴展向量Document(2)中的概念c2j,其對應的權重為w2j。那么,對于這2個概念(c1i,c2j),其相似度計算公式如下:
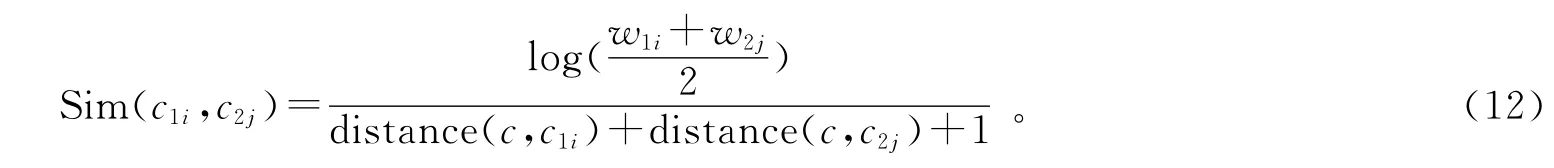
其中distance(c1,c2)是c1和c2之間最短路徑所包含的邊的條數,用于計算c1和c2之間的距離。
最終計算2個一維向量的相似度,可以用以下的方法得到:
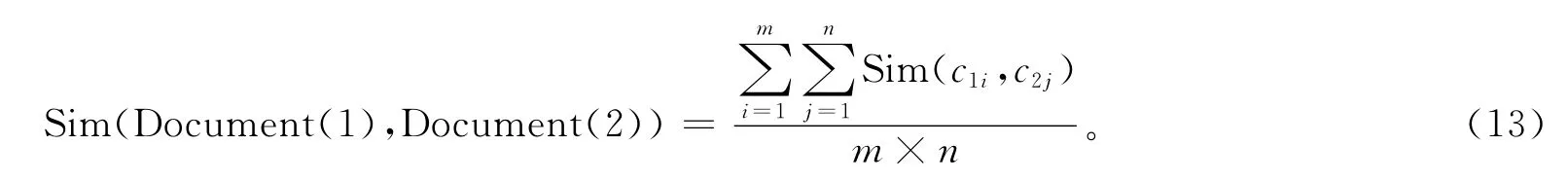
其中,m是文獻語義特征向量的概念向量中概念的個數,n是用戶查詢語義擴展向量的概念向量中概念的個數。
2.4 推理檢索
本體推理檢索是在構建的本體的基礎上,獲得本體中隱含的知識或推理出需要的知識。推理檢索的目的是回答用戶問題,并檢索出相關文獻,按文獻語義標注時的相似度排序后提交給用戶[8]。推理檢索模塊直接使用本體中的規則和公理的語義關系進行推理檢索,如利用本體中的子類公理(subClassOf)、同義(equivalentClass)等,實現了實例推理查詢、實例所屬類推理查詢和三元組推理查詢。
3 實驗和結果
高速鐵路領域由工務工程、牽引供電、動車組、運營管理等不同的專業領域構成,它是多專業領域的一個代表。在集成后的高速鐵路多專業領域本體的基礎上,以筆者提出的語義檢索系統結構,開發了一個面向高速鐵路文檔知識的語義檢索和推理系統,并對其進行了實驗分析。
2個最常用的基于相關性的語義檢索系統評價指標分別是準確率(precision)和召回率(recall),為了考察語義擴展檢索方法的有效性,采用準確率和召回率作為評測標準。
實驗目的:比較語義擴展檢索方法(expand)和傳統的關鍵字檢索方法(non_expand)。
實驗方法:分別用語義擴展檢索方法和傳統的關鍵字檢索方法,進行10次檢索,比較這2種方法的結果。結果如表1所示。
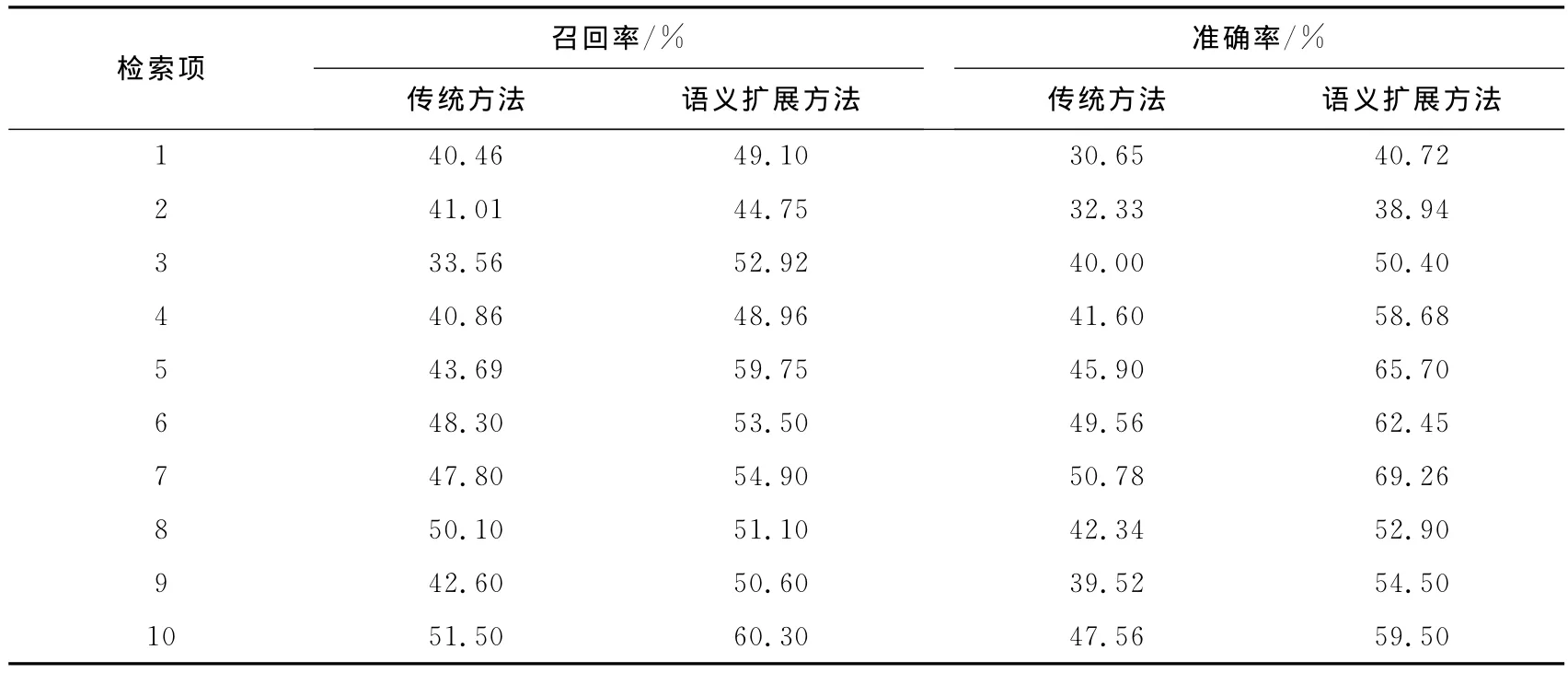
表1 不同方法的召回率和準確率Tab.1 Recall and precision of different methods
通過實驗,可以看出語義擴展檢索方法在準確率和召回率上要明顯優于傳統的關鍵字檢索方法。所以這在一定程度上證明了語義擴展檢索方法的有效性。雖然人工選擇的相關集有一定的不確定性,但這個不確定性也是人機交互系統所不可完全避免的一個問題。
4 結 語
以本體為基石的語義網的出現,克服了傳統檢索方法的不足,為實現信息檢索提供了一種全新的方法,能夠大大提高檢索的效率和精確度。面向多專業領域,在本體模型的基礎上提出了多專業領域本體模型,并給出了多專業領域本體概念語義相似度計算模型,此方法作為語義擴展的基礎。在此基礎上設計了一個基于本體的多專業領域知識語義檢索系統,該系統包括4部分:本體查詢、語義擴展檢索、推理檢索和用戶界面。最后以高速鐵路領域文獻資料知識作為實驗對象,對本文提出的語義檢索系統進行實驗分析,從測試結果來看,開發的語義檢索原型系統可以獲取較高的準確率和召回率。
[1] 金 芝.知識工程中的本體論研究[A].世紀之交的知識工程與知識科學[C].北京:清華大學出版社,2001.447-465.
[2] 劉紫玉,黃 磊.高速鐵路領域本體構建方法研究[J].情報學報(Journal of the China Society for Scientific and Technical Information),2009,28(2):195-200.
[3] STUDER R,BENJAMINS V R,FENSEL D.Knowledge engineering:Principles and methods[J].Data and Knowledge Engineering,1998,25(1/2):161-197.
[4] 陳 杰,蔣祖華.領域本體的概念相似度計算[J].計算機工程與應用(Computer Engineering and Applications),2006,42(33):163-166.
[5] 孔田野,李萬龍,張海鷗.基于藥品本體的信息檢索系統研究[J].河北科技大學學報(Journal of Hebei University of Science and Technology),2008,29(3):223-226.
[6] 鄭家恒,盧嬌麗.關鍵詞抽取方法的研究[J].計算機工程(Computer Engineering),2005,31(18):194-196.
[7] WU Jiang-ning,YANG Guang-fei.An ontology-based method for project and domain expert matching[A].FSKD(2)[C].[S.l.]:[s.n.],2005.176-185.
[8] 董 慧,余傳明,徐國虎,等.基于本體的數字圖書館檢索模型研究——歷史領域知識推理機制[J].情報學報(Journal of the China Society for Scientific and Technical Information),2006,25(6):666-678.
Research in semantic retrieval system for knowledge of multiple majors domain based on ontology
LIU Zi-yu1,YANG Guo-xia2,LI Xue-hui2
(1.College of Economics and Management,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China;2.College of Information Science and Engineering,Hebei University of Science and Technology,Shijiazhuang Hebei 050018,China)
In this paper a domain including different major fields is called multiple majors domain.For example,the high-speed railway domain consists of maintenance engineering,traction power supply,EMU and operation management,etc.Ontologies of the major fields are built based on thesaurus and thematic words,and these ontologies are integreted into a unified ontology for the multiple majors domain.Oriented to the domain that consisting of several major fields,this paper gives the ontology model for multiple majors domain,and also builds the model to compute semantic similarity between concepts for multiple major domain.Then,this paper puts out a semantic retrieval system for the knowledge of multiple major domain based on ontology and verifies it.The experimental results show that the developed semantic retrieval system can reach satisfying recall and precision.
ontology;multiple majors domain;semantic retrieval;high-speed railwaydomain
TP311
A
1008-1542(2011)05-0471-06
2011-03-05;
2011-09-12;責任編輯:李 穆
河北省科技支撐計劃項目(11213504D);河北省教育廳科學技術研究項目(Z2011275);河北科技大學博士科研基金資助項目(QD201017)
劉紫玉(1975-),女,河北趙縣人,講師,博士,主要從事知識管理、本體等方面的研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代裝飾(2022年1期)2022-04-19 13:47:32
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
