基于云計算的移動商業智能系統研究*
2011-11-07 05:04:42曾蔚
長沙大學學報 2011年5期
曾 蔚
(泉州師范學院數學與計算機科學學院,福建 泉州 362000)
基于云計算的移動商業智能系統研究*
曾 蔚
(泉州師范學院數學與計算機科學學院,福建 泉州 362000)
針對傳統商業智能系統在實時性、交互性和通用性上的不足,通過借鑒云計算強大的計算和存儲能力,提出了一種Hadoop與關系數據庫相結合的高實時移動商業智能系統解決方案.系統采用Hadoop架構替代數據倉庫,實現了海量數據的分布式存儲及分析計算,將高實時及高效請求交給處理效率更高的關系數據庫,充分利用云計算的虛擬技術提升移動商業智能系統的海量數據處理能力;不僅降低了成本,更使得企業資源得到充分、靈活的應用,提高企業市場快速反應力與競爭力.
移動商業智能;云計算;Hadoop;關系數據庫;Map/Reduce
傳統的商業智能系統大多只為決策人員服務,且受到安全因素影響,分析數據更多地只能在本地用戶終端體現,而體現的方式幾乎都是普通的電腦.隨著計算技術和互聯網技術的飛速發展,銷售、市場和決策人員的流動性和活動空間越來越大,涉及決策的管理人員越來越多,信息傳遞的實時性和交互式要求越來越高,這就對商業智能提出了更高的要求.下一代商業智能的發展要求其不僅僅能為高層決策者提供戰略型決策,同時也能為企業內其他層次用戶提供戰術型決策和操作型決策[1].而企業內中層、基層管理人員及一線員工通常因外出工作而無法及時在電腦前查詢分析數據.同時,近年來發行的各種智能手機及平板電腦已經能夠存儲大量數據,提供豐富的人機交互,甚至能展現各種復雜的可視化數據,這使得將商業智能分析數據移植于移動設備成為可能.然而,目前移動設備的計算能力和存儲能力與PC機相比仍然存在很大的差距,具備強大的計算力和存儲力的云計算為實現終端的智能提供了保證,將大量的計算和存儲操作運行在廉價且高效的云中,將PC機、移動終端設備與瘦終端作為云計算的端,將商業智能分析通過用戶隨身攜帶的智能手機等移動終端將信息實時交付給企業內所有層次用戶,甚至是客戶及商業合作伙伴,這將使得企業能夠對面臨的問題做出快速反應,改善客戶服務,從而贏得競爭優勢,使企業資源得到充分、靈活的應用.
1 云計算與移動商業智能
1.1 移動商業智能
隨著移動互聯網的迅速發展,移動商業智能己成為商業智能的一個新的發展方向.基于移動互聯網應用的商業智能不僅能夠將過去局限的商業智能應用擴展到企業各層次員工,提高商業智能系統的利用率,而且還使得商業智能系統提供實時訪問分析成為可能.與傳統商業智能相比,移動商業智能具備以下幾個特點∶第一,能夠隨時隨地實時訪問企業商業智能應用,員工不再因地理位置而受訪問限制;第二,信息主動推送及個性化定制,企業可根據實際情況預先為各類員工定制按時推送信息,也可根據用戶的個性化定制進行信息推送服務;第三,實時監控預警,當突發事件出現時,系統直接將警報信息發送到用戶的移動設備,這使得員工可以及時采取措施避免損失.
1.2 云計算與移動商業智能
云計算是一種近幾年興起的一種新型技術架構,將計算任務分布在大量計算機構成的資源池上,使各種應用系統能夠根據需要獲取計算能力、存儲空間和各種軟件服務[1].云計算具有低成本、安全可靠、可擴展等突出優點,它通過虛擬機、鏡像部署執行等方法為用戶提供服務[2].云計算與商業智能的結合將進一步促進移動商業智能的應用.首先,云計算可以增強商業智能處理海量數據的能力.將運算及存儲能力通過網絡遷移到云端,能夠完成PC機無法應付的數據處理任務,用戶只需通過PC機、移動設備等終端即可完成類似以往在PC機上的各種操作.而用戶也無需為商業智能應用添置高性能移動設備,因為云計算最大程度地實現了資源共享,消除了時間和空間的限制.除此之外,傳統商業智能的海量數據處理集中于數據倉庫,近年來數據倉庫的發展己能夠大規模并行處理海量數據并對分析數據進行高效管理,而受到Map/Reduce框架強力支持的Hadoop是一種基于集群分布式架構,不論海量數據處理、成本、運算速度還是穩定性都優于數據倉庫.其次,云計算能夠提升商業智能的時效性.云計算能夠讓商業智能在更短的時間內獲取交易數據,執行更強的數據分析功能,在突發事件發生時提供及時的信息反饋,充分發揮移動商業智能的實時優勢[3].第三,云計算與商業智能的結合將降低成本.傳統基于數據倉庫的商業智能部署相當昂貴,除商業智能與數據倉庫以外還需要承擔IT成本和部署、前端商業智能展現工具的費用,在低成本地區建立大規模數據中心可以幫助企業在電力、網絡帶寬、軟件和硬件等方面降低成本.以往資金能力不足以搭建自己的商業智能平臺的中小企業無需購買任何硬件,無需安裝軟件,只需通過SaaS模式租用位于云端的移動商業智能應用.云計算與商業智能的結合可以使企業以較少的價格得到靈活且有彈性的商業智能服務.
2 基于云計算的移動商業智能架構
系統利用云計算的虛擬化技術建立了基礎設施層、平臺層、支撐層和應用層,其架構如圖1所示.
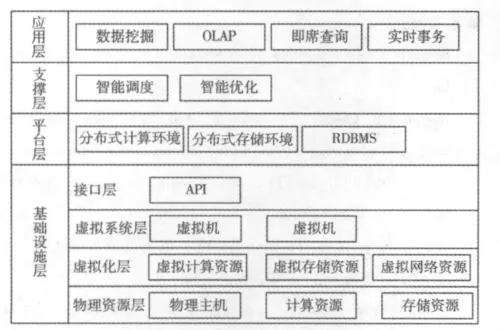
圖1 基于云計算的移動商業智能系統架構
應用層提供了各種商業智能應用,如數據挖掘、OLAP、即席查詢及實時事務處理.PC機及瘦客戶端用戶可以通過瀏覽器或者特定的客戶端訪問和使用這些服務,持有移動設備用戶可使用各類移動終端通過移動通信網或無線網連接平臺使用服務,系統將為持有不同類型設備的用戶提供不同的界面及功能.
支撐層負責處理應用層中的應用請求,對其業務處理邏輯進行智能調度.商業智能系統面臨的是巨量且不同存儲和計算的請求,可分為海量數據處理請求、日常信息處理請求、高性能計算請求等.智能調度根據請求類型進行判斷,若該請求對計算需求很小可以在關系數據庫中找到則直接訪問關系數據庫;若請求需要較大的計算量和存儲量則需要提交云計算平臺執行并行計算.由于用戶的移動設備可能是平板電腦等高性能智能設備,也可能是較為普通的低性能手機,智能優化識別各種移動設備不同的存儲和計算能力并依據用戶請求內容進行度量,為不同類型移動設備提供最適合其存儲和計算能力的瀏覽結果.
平臺層采用了分布式存儲環境與關系數據庫相結合的模式.企業各類網站產生的數據通過數據分析及抽取,將高實時性數據及低實時性數據分別抽取到關系數據庫與分布式存儲環境中,部分被頻繁請求的分析數據也在分布式計算環境完成后同時導入到關系型數據庫和分布式存儲環境中,進一步提高移動商業智能系統的訪問速度.分布式計算平臺將用戶請求分解為多個并行的子任務,充分利用環境中的多個計算資源節點,加速分析計算處理的過程.
基礎設施層分為接口層、虛擬系統層、虛擬化層和物理資源層這四個子層.物理資源層將服務器、存儲和網絡等資源組織為資源池的方式進行統一管理,以獲得最大資源利用率.虛擬化層利用虛擬化技術將硬件資源劃分為“虛擬硬件”,從而提供虛擬CPU、存儲、虛擬網絡等更細粒度的資源.虛擬系統層打破了操作系統與物理資源之間的約束,該層中的虛擬機只能看到虛擬化層提供的虛擬硬件,不必考慮物理服務器的情況,從而提供更高的資源利用率和靈活性.接口層將基礎設施的服務通過API的方式提供給上層.
3 Hadoop與關系型數據庫相結合的海量數據實時計算
Hadoop是一個能夠對大量數據進行分布式處理的框架,實現了 Google的 Map/Reduce應用[4].Hadoop是一種典型的主從式結構,其基本結構如圖2所示,上層是主從式的Map/Reduce處理,下層是主從式的HDFS文件系統.HDFS集群包括一個NameNode和若干DataNode,NameNode負責管理各個DataNode和維護系統的元數據,DataNode用于實際對數據的存放,與用戶直接建立數據通信.NamedNode作為文件系統負責運行在Master上,而DataNode運行在每個機器上.Hadoop實現了 Google的 Map/Reduce,JobTracker負責整個Map/Reduce的控制工作運行在Master上,TaskTracker則運行在每個機器上執行Task.對于一個大文件,Hadoop把它切割成一個個大小為16MB~64MB的塊.這些塊是以普通文件的形式分布存儲在各個節點上的.通過此種方式,來達到數據的安全和可靠.
系統必須滿足實時查詢和數據挖掘,傳統做法是讓實時性查詢由關系數據庫承擔,而數據倉庫負責低實時的數據挖掘與分析,但是一旦數據量龐大時使用數據倉庫將直接導致數據檢索速度急劇下降,因此平臺采用hadoop來替代數據倉庫實現低實時的數據挖掘.但并不是使用Hadoop替換關系數據庫與數據倉庫,Hadoop的數據裝載開銷比關系數據庫小,但效率卻依然不如關系數據庫[5],因此為同時滿足用戶高實時請求及高計算和存儲能力請求,將關系型數據庫與Hadoop相結合實現海量數據實時計算,其架構如圖2所示.
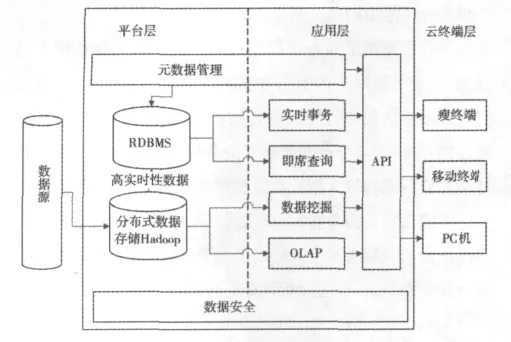
圖2 Hadoop與關系型數據庫相結合的海量數據實時計算架構
Hadoop的Map/Reduce架構可以快速地裝載并處理大規模數據,因此由Hadoop負責從數據源抽取數據并對其進行解析,將一些要求高響應速度的數據或計算需求小的數據裝載到關系數據庫中實時響應用戶請求,而對于某些請求頻率較高的低實時數據則在Hadoop中進行預處理,待Map/Reduce完成分布式計算后將結果也存入關系數據庫.
Hadoop中只有一個NameNode節點,當處理某些大型作業時可能需要運行數小時甚至是數天才能完成,作業運行時間偏長的缺點是NameNode一旦失敗將丟失所有己經完成的中間結果,因此考慮對大型作業在其運行過程中定時保存中間結果,若NameNode失敗還可以從磁盤中繼續讀入己完成中間結果繼續處理.因此不論在Map還是Reduce部分均根據作業大小為其分配一定大小的內存來保存中間結果,待對應的內存寫滿才寫入磁盤空間,且寫入磁盤前還應對中間結果進行壓縮來加快數據在內存與磁盤之間的傳輸速度.Hadoop為每個大型作業均分配一定大小的緩存,并定時將己完成的中間結果寫入到緩存中,當緩存寫滿時則將中間結果進行壓縮存入磁盤.若作業失敗則可從己保存在磁盤中的中間結果繼續計算,而不是重頭開始計算.當作業完成時還必須有一個合并過程將所有的中間結果并行合并.當作業的第一個中間結果結束后,所有的Reduce均從己完成的中間結果并行下載該Reduce所需的數據塊.同樣地,為了提高IO讀寫效率,每個Reduce也將下載的中間結果緩存在一定大小的內存中,待對應內存寫滿時進行壓縮并寫入磁盤.當Reduce將所有的中間結果上對應的數據塊全部下載完成后,再將數據塊合并接著進行計算.
4 結論
鑒于傳統的商業智能系統在實時性及利用率過低等方面的不足,結合云計算提出了一種具有高實時性的移動商業智能系統解決方案,給出了系統體系結構,結合Hadoop與關系數據庫兩者的優勢,利用Hadoop從數據源中實時將數據載入關系數據庫,提出了一種海量數據實時處理方式.基于云計算的移動商業智能系統具備靈活性、實時性等特點,較之傳統的商業智能系統不僅降低了成本,還能夠更快速地應對市場動態發展所帶來的挑戰.
[1]Hayes B.Cloud computing[J].Commun ACM,2008,51(7):9-11.
[2]Rajkumar B,Chee S Y,Srikumar V,et al.Cloud computing and emerging IT platforms:Vision,hype,and reality for delivering computing as the 5thutility[J].Future Generation Computer Systems,2009,25(6):599-616.
[3]穆向陽,繆寧,陳明,等.云計算環境下BI對企業核心競爭力的影響[J].情報雜志,2010,29(6):52.
[4]王鵬.云計算的關鍵技術與應用實例[M].北京:人民郵電出版社,2010.
[5]Pavlo A,Paulson E,Rasin A,et al.A comparison of approaches to large-scale data analysis[A].Proceedings of the 35thSIGMOD International Conference on Management of Data[C].New York:SIGMOD,2009.
(責任編校:晴川)
TP399
A
1008-4681(2011)05-0048-03
2011-07-11
曾蔚(1982-),女,福建泉州人,泉州師范學院數學與計算機科學學院助教,碩士.研究方向∶數據庫技術、云計算.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
