一種基于GPU的主動聲納寬帶信號處理實時系統*
2011-10-19 12:47:48李曉敏侯朝煥鄢社鋒
傳感技術學報 2011年9期
李曉敏,侯朝煥,鄢社鋒
(中國科學院聲學研究所聲學智能制導實驗室,北京 100190)
傳統意義上的GPU主要針對圖形圖像處理和游戲加速,其功能受到一定限制。NVIDIA公司于2007年發布了CUDA以及相應的GPU版本。這類GPU內核有很多流處理器,每個流處理器內包含相當多數量的并行執行單元,可以高效執行各種模型的大規模科學計算,因此受到學術界和產業界的追捧,被廣泛應用于金融、石油、天文學、流體力學、信號處理、電磁仿真、模式識別、圖像處理和視頻壓縮等眾多領域[1-7]。然而,目前國內外將GPU通用計算應用到聲納信號處理的案例還很少。
聲納信號處理的手段主要分為兩類。一類為以CPU為代表的處理平臺,另一類為基于FPGA和DSP等大規模集成電路芯片的陣列信號處理平臺。前者耗時嚴重,實時性差;后者雖然能夠完成實時信號處理,但也具有開發周期長、板卡眾多和成本高等眾多缺點。
基于以上因素,本文采用基于CUDA編程架構的GPU,實現了LFM及CW信號的幾種經典波束形成和匹配濾波過程,該系統具有實時性、開發周期短、性價比高和使用靈活等眾多優點。
1 基于CUDA的GPU通用編程
CUDA是一種將GPU作為數據并行計算設備的軟硬件體系,采用了比較容易掌握的類C語言進行開發。它是一個SIMD(Single Instruction Multiple Data)系統,即一個程序編譯一次以后,CUDA將計算任務映射為大量的可以并行執行的線程,并由擁有大量內核的硬件動態調度和執行這些線程,從而顯著提高運算速度。如圖1所示,將一個可以并行化執行的任務首先分配給若干個線程網格(Grid),其次將每個Grid內的任務分配給若干個線程塊(Block),最后再將每個Block內的任務細分給若干個線程(Thread)。Grid中的所有Blocks并行執行,Block中的所有Threads并行執行,這種兩層并行模型是 CUDA 最重要的創新之一[8-9]。

圖1 GPU內線程結構
2 主動聲納寬帶信號處理的GPU實現
圖2是一個簡單的主動聲納信號處理過程框圖。

圖2 主動聲納信號處理基本框圖
接收基陣接收到M路回波信號,通過波束形成實現DOA估計,并將波束匯聚后送入匹配處理器,最終得到目標距離和速度。
2.1 經典窄帶波束形成的實現
2.1.1 自適應 MVDR 波束形成器[10-11]
MVDR波束形成器的加權向量為

其中,as(θ)為θ方向上的導向向量。
方位譜為

其中,對Rx進行特征分解為Rx=UΓUH,M為基陣陣元數

圖3為在GPU上實現MVDR波束形成器的任務分配圖。其中,s為掃描角度數目,一般取掃描范圍為[0:1:180]°,則s=181。

圖3 MVDR波束形成器GPU內部kernel任務分配圖
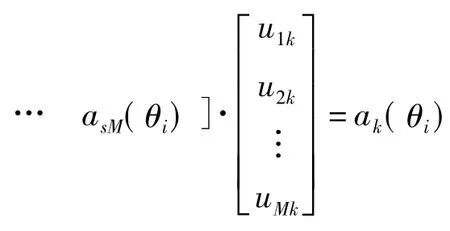
2.1.2 LSMI波束形成器[10-11]
LSMI波束形成器的加權向量為

其中λ為對角加載量,經驗值為10。
方位譜為

的第k個元素;B為對角陣,Bk為B的第k個元素。圖4為在GPU上實現LSMI波束形成器的任務分配圖。

圖4 LSMI波束形成器GPU內部kernel任務分配圖

2.1.3 RCB 波束形成器[10-11]
RCB波束形成器的加權向量為

方位譜為

其中,B為對角陣,λλk為B的第k個元素。令ε0為一個趨近于0的正小數,則λ可通過(8)求解

圖5為在GPU上實現RCB波束形成器的任務分配圖。
對于RCB波束形成器,仍然使用s個Blocks,每個Block內包含M個并行處理Threads。

圖5 RCB波束形成器GPU內部kernel任務分配圖

2.2 寬帶波束形成的實現
寬帶波束形成器的實現包括頻域FFT實現和時域FIR實現兩種方式。本文采用頻域FFT實現方法,首先使用離散傅里葉變換將陣列數據分解為若干頻帶上的子窄帶,然后針對每個子帶進行[0:1:180]°掃描窄帶波束形成,最后將各子帶方位譜累加從而估計出目標方位[11],實現流程如圖6所示。

圖6 寬帶波束形成算法實現流程圖
其中,M為陣元數,fftnum為采樣數據長度,ST為分解后的特征值,UT為分解后的特征向量,angledis為波束掃描間隔角度。在寬帶波束形成器的實現過程中,只需要針對每個子窄帶使用2.1節介紹的過程即可。
2.3 匹配處理的實現
匹配濾波常用來檢測淹沒在加性高斯白噪聲中的信號,它是一種使輸出峰值信噪比最大的最優濾波技術。在主動聲納系統中,匹配濾波接收輸出波束的時間序列,并將處理后的結果直接作為檢測器的輸入,與門限進行比較,進而判定目標是否存在[12]。
由于匹配濾波器對頻移信號沒有適應性,因此需要產生發射信號的多種頻率版本,以匹配由多普勒頻移造成的接收信號頻率與發射信號頻率不一致,這個過程通常被稱為拷貝相關。圖7展示了采用匹配濾波的過程。

圖7 匹配濾波示意圖
上圖中,每個陰影區域即代表某頻移點上的拷貝相關。考慮到信號點數length(length=快拍數snapnum*FFT點數 fftnum)遠大于 GPU內每個Block擁有的最大線程數512,無法將每個陰影區的執行單獨分配給1個Block。因此,將各個陰影區域之間串行執行,而每個陰影區域內部并行執行。并行任務分配給snapnum個Blocks,每個Block內有fftnum個Threads,所有的Threads均完成一次點乘。
3 實驗結果
3.1 硬件平臺

表1 硬件平臺
3.2 系統輸入輸出界面
本文采用諾基亞公司開發的跨平臺C++圖形用戶界面應用程序框架Qt實現系統輸入輸出界面,圖8所示為系統主界面。

圖8 系統主界面
右側藍色方框內為目標參數輸入區和系統參數輸入區,左側紫色方框內為信號處理結果顯示區。
假設目標在[40~140]°之間以5°間隔來回運動,設置完成各項參數后,點擊“開始”按鈕,輸出方位譜圖將會顯示每個時刻的方位譜,輸出方位歷程圖將會記錄下所有時刻目標的方位情況,并一幀一幀刷新。點擊方位歷程圖上任意一點,將會在輸出頻譜圖上顯示相應時間和方位上的輸出信號頻譜。
同時,每個時刻目標方位、目標距離和目標速度都以文字形式顯示在主界面最左側。由于該系統具備實時性,處理時間始終小于采樣時間。
點擊主界面上“顯示換能器通道數據”按鈕將彈出一個新界面,如圖9所示。通過下拉框選擇想查看的通道,點擊“確定”按鈕,該界面將與主界面同步顯示當前時刻某換能器通道輸入信號波形及其頻譜。
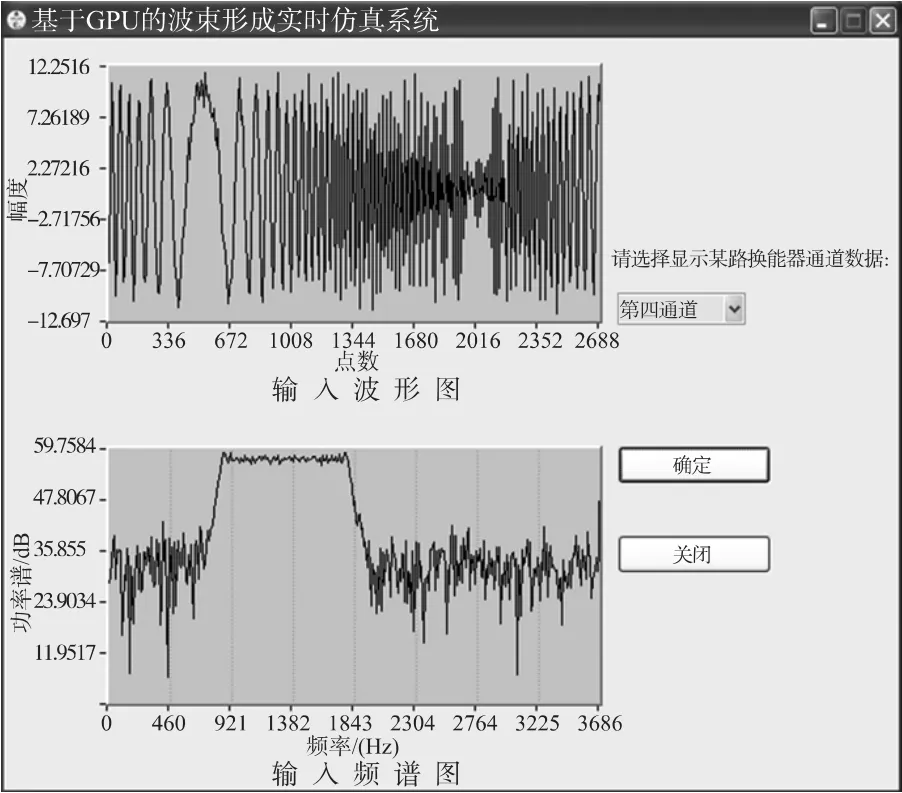
圖9 顯示換能器通道數據界面
3.3 運行時間及加速比
在圖8中所示參數的基礎上,增大陣元數為32,增大子帶數為21,減小掃描間隔為1°,從而增大掃描角度次數。表2展示了Matlab、CPU和GPU三種平臺在此參數條件下采用不同的算法執行處理過程的時間以及加速比。
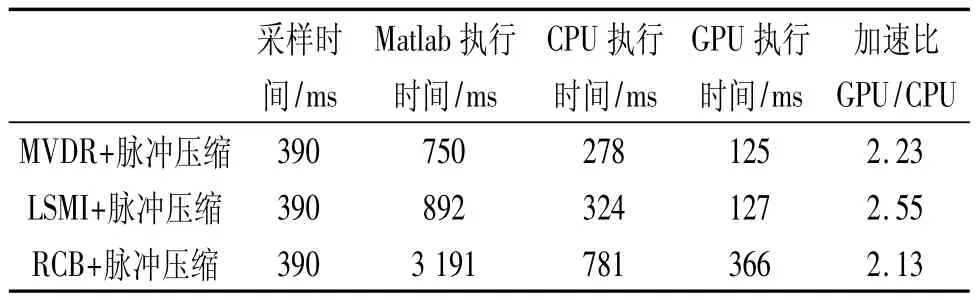
表2 各種平臺執行時間及加速比
表2中所示的4種處理算法,從上到下運算量依次增大。從表2可以看出,處理同樣的數據,GPU相比于CPU要快兩倍多。當數據量增大到一定程度時,Matlab和CPU已經無法在采樣一幀數據的時間內完成對上一幀數據的處理,而GPU卻仍然可以滿足處理的實時性。
在不考慮實時性的前提下,繼續增大運算量,上面四個表格中的加速比會越來越大,GPU的加速優勢會越來越明顯。圖10和圖11分別展示了在表2所示參數基礎上,CPU和GPU這兩種平臺執行“LSMI+匹配處理”的時間隨著陣元數和子帶數增加的變化趨勢。

圖10 各平臺執行時間隨陣元數M的變化

圖11 個平臺執行時間隨子帶數subband的變化
可以看出,當數據量增大時,GPU相較于CPU的執行速度優勢更加明顯,這正應證了GPU處理大數據量的優良性能。
4 結論
本文設計了一種主動聲納信號處理系統,采用具有眾多并行內核的GPU實現其實時性。該系統相較于CPU有約一個數量級的加速,相較于同樣處理速度的DSP平臺,則體現了開發周期短、成本低和操作簡單等優點。隨著聲納信號處理數據量的日益增大,將GPU強大的通用計算能力應用到聲納領域的各個環節,是一個值得繼續深入研究的課題。
[1]杜歆,顏瑞,劉加海.監控攝像機視頻去隔行和CUDA加速[J].傳感技術學報,2010,23(3):393-398.
[2]趙欣,李鳳霞,戰守義,等.基于粒子系統實現船舶航跡仿真的加速方法[J].大連海事大學學報,2008,34(1):54-57.
[3]程廣斌,馬承華,郝立巍.基于圖形處理器加速的醫學圖像分割算法研究[J].醫療衛生裝備,2008,29(2):6-8.
[4]李蔚清,吳慧中.一種基于GPU的雷達探測區域快速可視化方法[J].系統仿真學報,2008,(20):323-327.
[5]Balz T,Stilla U.Hybrid GPU-Based Single-and Double-Bounce SAR Simulation[J].IEEE Transactions on Geoscience and Remote Sensing,2009,47(10):3519-3529.
[6]柳彬,王開志,劉興釗,等.利用CUDA實現的基于GPU的SAR成像算法[J].信息技術,2009,11:62-67.
[7]Yubo Tao,Hai Lin,Hujun Bao.GPU-Based Shooting and Bouncing Ray Method for Fast RCS Prediction[J].IEEE Transactions on Antennas and Propagation,2010,58(2):494-502.
[8]Garland M,Le Grand S,Nickolls J,et al.Parallel Computing Experiences with CUDA[J].Micro,IEEE,2008,28(4):13-27.
[9]張舒,諸艷麗,趙開勇,等.GPU高性能運算之CUDA[M].北京:中國水利水電出版社,2009:1-100.
[10]朱埜.主動聲納檢測信息原理[M].北京:海洋出版社,1990:32-50.
[11]鄢社鋒,馬遠良.傳感器陣列波束優化設計及應用[M].北京:科學出版社,2009:48-93.
[12]豐平.基于VPX規范的新型陣列信號處理機系統設計[D].北京:中科院,2010:18-19.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
鴨綠江(2021年35期)2021-04-19 12:24:18
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
當代陜西(2020年13期)2020-08-24 08:22:02
電子制作(2018年11期)2018-08-04 03:25:42
制造技術與機床(2017年5期)2018-01-19 02:49:17
家庭影院技術(2017年9期)2017-09-26 03:41:45
濰坊學院學報(2016年2期)2016-12-01 13:00:11
