基于電子鼻技術的信陽毛尖茶咖啡堿檢測方法*
2011-10-19 12:47:34張紅梅余泳昌高獻坤花恒明何玉靜
傳感技術學報 2011年8期
張紅梅,王 俊,余泳昌*,高獻坤,花恒明,何玉靜
(1.河南農業大學機電工程學院,鄭州 450002;2.浙江大學生物系統工程與食品科學學院,杭州 310029)
茶葉香氣由含量少而種類繁多的揮發性物質組成,至今報道已分離鑒定的有650種[1]。這些研究雖然取得了一定成果,但從定性角度出發,這些成分分析方法的作用還是非常有限的。長期以來,茶葉科研工作者都致力于茶葉品質的量化識別研究,期望采用科學的儀器測定茶葉,用科學計量的品質指標來評價茶葉品質。水分、茶多酚、咖啡堿和氨基酸是茶葉中主要品質成分,它們影響茶色、茶香和茶味的形成。傳統的茶葉成分測定方法,比如咖啡堿含量的測定通常采用碘量法、重量法、紫外分光光度法等,茶多酚含量的測定通常采用高錳酸鉀滴定法和酒石酸鐵比色法。這些測定方法需要繁瑣的化學處理,不僅速度慢、費用高、測定結果差異大,而且易產生污染、具有破壞性。因此研究綠茶品質成分的快速準確測定方法具有重要的現實意義[2]。近年來,電子鼻技術的興起,讓我們看到了一種通過氣味來評價茶葉品質的快速無損新方法。于慧春等[3-4]采用電子鼻技術以5組不同等級的茶葉、茶水、葉底以及4個不同等級的龍井茶為研究對象,對茶葉品質進行了系統研究。Ritaban Dutta等[5]利用電子鼻技術對5種不同加工工藝的茶葉進行分析和評價,結果表明采用RBF的模式識別方法時,可以100%區分5種不同加工工藝的茶葉。Nabarum Bhattacharyya等[6]用電子鼻技術對紅茶發酵過程中的氣味進行實時監測,以便預測最佳的發酵時間,避免發酵時間不當影響成品茶葉品質。Yang Ziyin等[7]檢測日本綠茶中濃縮香豆素含量以及其獨特的香氣,結果表明電子鼻技術結合主成分分析和聚類分析方法能正確識別7個不同香豆素含量的茶葉樣本。
信陽毛尖茶是中國十大名茶之一,但有關它的品質檢測方面的研究報道并不多。郭桂義等[8-9]對信陽毛尖的滋味成分進行過系統的研究,也探討過信陽毛尖茶春季不同時期化學成分與品質的變化。霍權恭等[10]對比研究了信陽毛尖春茶和夏茶的揮發性成分的差異。筆者采用電子鼻技術,對信陽毛尖茶中咖啡堿的含量進行快速檢測,旨在探討信陽毛尖品質和成分的檢測方法,使茶葉品質評審更加科學化和定量化。
1 材料和方法
1.1 試驗材料
茶葉樣品來自河南信陽同一茶園和采用同一加工工藝的2009年明前信陽毛尖炒青茶,共有3個品質等級,分別為T1、T2和T3。T1為1級茶葉、T2為2級茶葉、T3為3級茶葉。對3個等級的信陽毛尖茶各取30個樣品,每個樣品5 g。這些子樣品分別被盛放在500 mL燒瓶內,用保鮮膜密封后,置于25±1℃的室內,60 min后進行電子鼻頂空取樣。待測茶葉樣本的揮發氣味在傳感器陣列室內與傳感器陣列反應,產生電信號,通過采集電路把數據采集到計算機進行處理。
1.2 化學成分測定
咖啡堿的測定采用GB8312—87《茶 咖啡堿測定》,紫外分光光度法(UV-2501紫外分光光度儀)。
1.3 電子鼻
試驗是用德國Airsense公司的PEN2電子鼻,該電子鼻包含有l0個金屬氧化物傳感器組成的陣列。10個傳感器名稱分別為 W1C、W5S、W3C、W6S、W5C、W1S、W1W、W2S、W2W 和 W3S。傳感器對不同的化學成分有不同的響應值。響應信號為傳感器接觸到樣品揮發物后的電導率G與傳感器在經過標準活性碳過濾氣體的電導率G0的比值。測量時記錄10個不同選擇性傳感器的G/G0比值,作為進一步統計分析的數據。每次測量前后,傳感器都進行清洗,這有效地保證了電子鼻測量數據的穩定性和精確度。結合電子鼻自帶WinMuster軟件對數據進行采集、測量和分析。儀器組成主要包含:傳感器通道、采樣通道、計算機。該電子鼻具有自動調整、自動校準及系統自動富集的功能。本試驗研究中,檢測時間設定為60 s,清洗時間設置為90 s,可以基本使傳感器響應恢復到初始狀態。
2 結果和討論
2.1 咖啡堿檢測結果
咖啡堿是構成茶湯滋味的重要物質,也是茶葉中主要的藥理活性成分。雖然其本身味苦,但是與多酚類及其氧化產物形成絡合物以后便具有一種鮮爽滋味。因此,茶葉咖啡堿含量與品質之間呈正相關,咖啡堿含量高,茶葉品質好[11]。圖1所示是三個等級的信陽毛尖茶咖啡堿含量平均值,從圖1中可以看出,茶葉等級越高,咖啡堿含量越高。試驗結果與前人研究結果吻合。
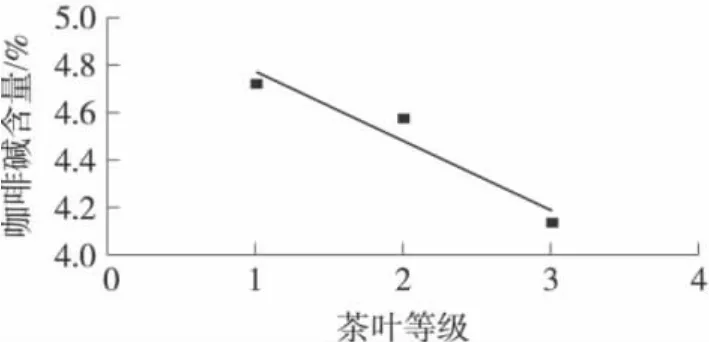
圖1 不同信陽毛尖茶葉等級的咖啡堿含量
2.2 氣敏傳感器陣列對不同品質茶葉氣味的響應
圖2所示是3個等級信陽毛尖茶氣味的傳感器陣列響應平均值的變化。圖2可以看出傳感器S2對茶葉氣味反應比較大,響應值也比較大。傳感器S5正向略偏離1,響應值有所增強。傳感器S6和S8負向偏離1,信號有所變化。傳感器S1、S3、S4、S7、S9 和S10響應值變化不大。從S2的響應值看,傳感器對1級茶葉響應較大,對3級茶葉響應較小。
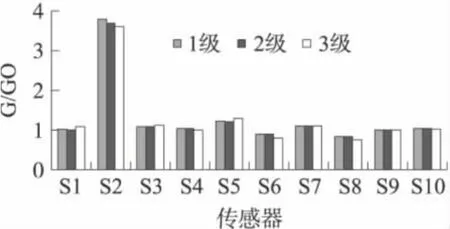
圖2 三個等級信陽毛尖茶傳感器響應值變化
2.3 傳感器陣列的優化
對傳感器陣列所得的原始數據進行標準化處理后再進行傳感器陣列的優化。Loading分析用于反應因子與各個變量間的密切程度,常應用于指標(變量)分類。在電子鼻應用中把各個傳感器當成變量,通過Loading分析可以直觀的對傳感器進行分類,為傳感器取舍提供一種依據[12]。Loading分析結果如圖3所示。圖3顯示出了,傳感器S7、S5各為為一類,在第二主軸上比重較大;S4和S10為一類,S1、S3、S2、S6、S8 和 S9 為一類在第一主軸的比重較大。下面再通過相關分析,分析一下各個傳感器之間的相關程度。
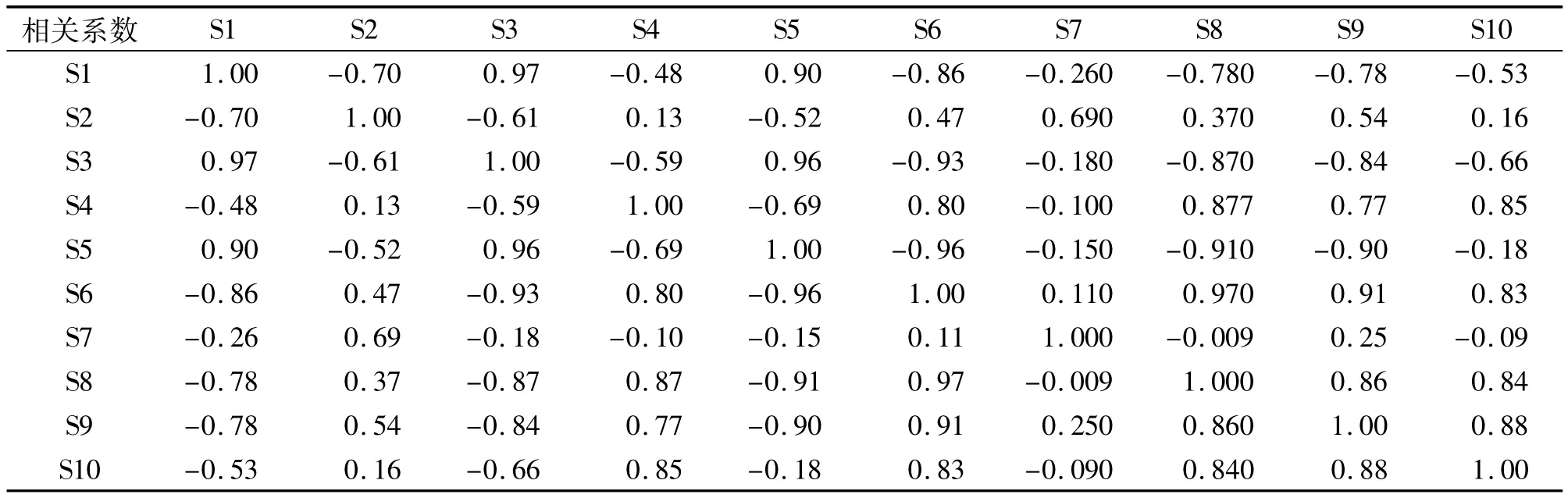
表1 各傳感器之間的相關系數
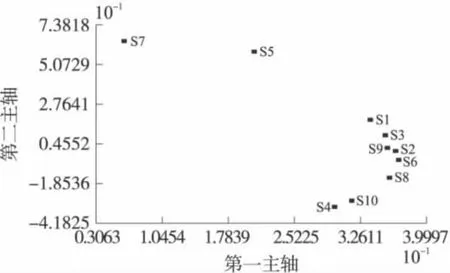
圖3 Loading分析圖
相關分析主要用來分析傳感器之間的相關程度,如果兩個傳感器測試結果的相關程度大,說明兩個傳感器包含相似的信息。傳感器之間的相關程度用相關系數來表示,相關系數越大,說明傳感器之間的相似程度越大,包含越多的冗余信息,可考慮去除。相關系數越小,傳感器之間的相似度越低,傳感器之間包含的冗余信息越少,應優先考慮[12]。通過相關分析10個傳感器之間的相關系數如表1所示。通過Loading分析,傳感器S5和S7各為一類,通過計算S5和S7的相關系數為-0.15,說明二者相似程度較少,可以優先考慮采用。S4和S10為一類,二者相關系數為0.85,相關系數較大,說明二者之間的相似程度很大,考慮去除 S4。S1、S2、S3、S6、S8和S9為一類,綜合考慮與其他傳感器之間的相關系數以及傳感器對茶葉響應值的大小,在這一類中選擇S2。S2、S7、S10和S5為最終的新傳感器陣列,用于信陽毛尖茶的品質識別。
2.4 PCA 分析
對傳感器陣列對信陽毛尖茶葉響應值的數據矩陣進行主成分分析,圖4是前兩個主成分PC1和PC2組成的二維圖,前兩個主成分的貢獻率分別為72.89%和17.63%,累計貢獻率為90.52%。因為PCA只對原始數據分析,不考慮分類情況,其區分情況與品質實際情況一致。按照1級、2級、3級茶葉的情況,可以將不同等級的茶葉完全區分開,而且效果比較好。說明電子鼻可以檢測到不同品質信陽毛尖茶的氣味差異。
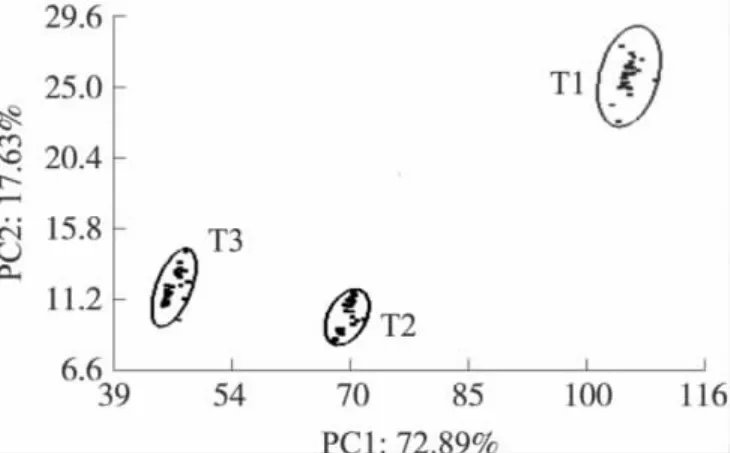
圖4 不同品質茶葉的PCA分析圖
2.5 基于氣敏傳感器陣列的咖啡堿預測模型
提取優化后的氣敏傳感器陣列 S2、S5、S7和S10四個傳感器對信陽毛尖1級、2級、3級茶葉樣品的穩態信號即45s時刻的響應信號進行分析,所提取的數據矩陣為90行4列。每個等級茶葉樣品試驗時測試了30個子樣品,3個等級共90個試驗數據;從每個等級茶葉30個子樣本中隨機抽取27個,共81個作為訓練集,剩余9個作為測試集。將4個傳感器對信陽毛尖茶的響應信號作為自變量,3個等級的茶葉咖啡堿含量作為因變量。利用主成分回歸(PCR)、多元線性回歸(MLR)和二次多項式逐步回歸(QPSR)方法分別建立信陽毛尖茶基于氣敏傳感器陣列的咖啡堿預測模型。
在對S2、S5、S7和S10四個傳感器對信陽毛尖1級、2級、3級茶葉樣品的穩態信號即45 s時刻的響應信號進行主成分分析過程發現,第一主成分與第二主成分的貢獻率分別為64.27%和27.93%,累積貢獻率達92.2%,說明前兩個主成分可以解釋所有變量的信息。所以選擇第一和第二主成分建立回歸模型如下所示。
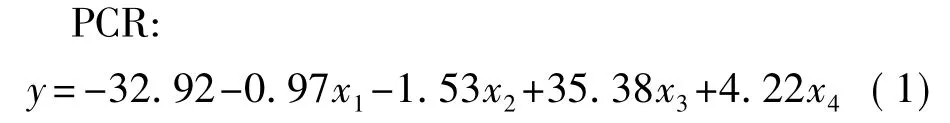
式(1)中y表示咖啡堿的含量;x1到x4分別表示傳感器S2、S5、S7和S10對茶葉的響應信號。
模型(1)訓練集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.75、0.17和3.08%。測試集預測值與實測值的關系如圖5所示。預測集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差誤差百分比分別為:0.66、0.32 和 3.42%。
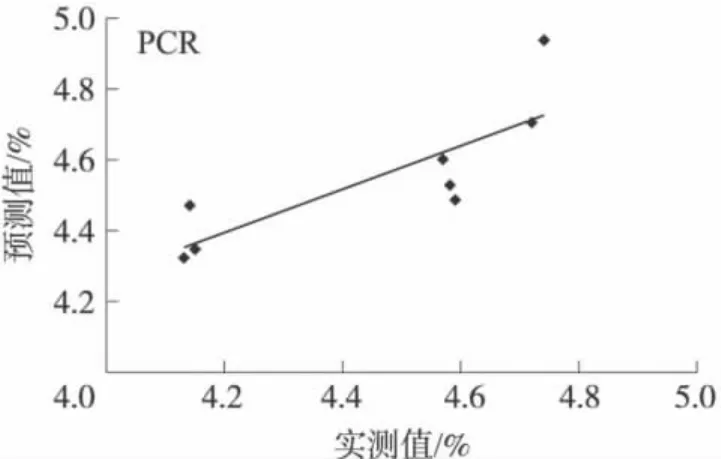
圖5 PCR模型對測試集預測值與實測值的擬合圖
多元線性逐步回歸(MLR)利用4個傳感器對茶葉的響應信號建立與茶葉咖啡堿含量之間的多元線性關系。MLR回歸模型如下:
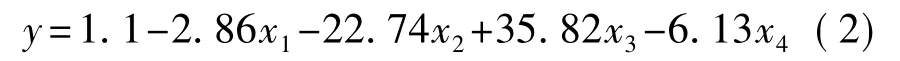
式(2)中自變量的含義與式(1)相同。
式(2)訓練集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.89、0.12和1.92%。測試集預測值與實測值的關系如圖6所示。預測集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差誤差百分比分別為:0.80、0.19 和 2.8%。
前兩種建模都是線性方法,本文采用二次多項式逐步回歸方法建立傳感器信號與茶葉咖啡堿含量之間的非線性關系。即把正交實驗和回歸分析有機結合起來,在正交實驗的基礎上利用回歸分析,在給出的因素和指標之間,找到一個明確的函數表達式。回歸模型如下:
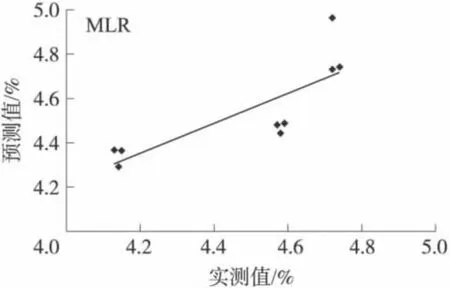
圖6 MLR模型對測試集預測值與實測值的擬合圖
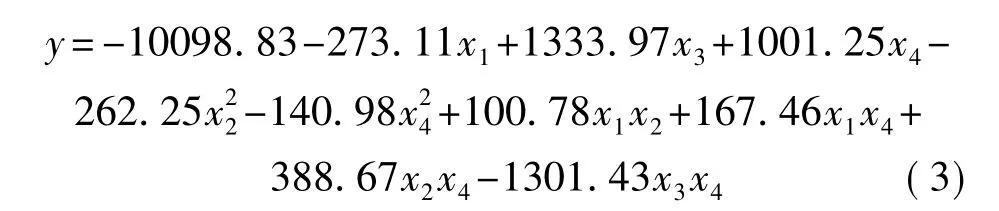
式(3)中自變量的含義與式(1)相同。
式(3)訓練集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.96、0.06和1.08%。試集預測值與實測值的關系如圖7所示。預測集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.94、0.19 和 2.3%。
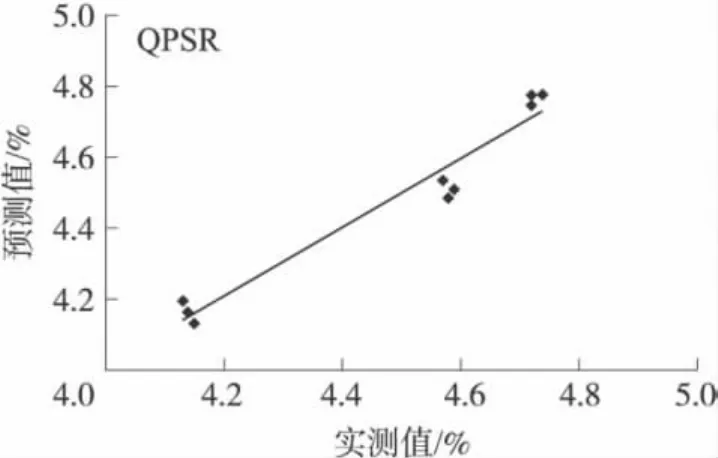
圖7 二次多項式逐步回歸模型對測試集預測值與實測值的擬合圖
2.6 PCR、MLR和QPSR模型比較
分別采用PCR、MLR和QPSR三種建模方法建立了基于氣敏傳感器信號的信陽毛尖茶咖啡堿含量預測模型。表2列出了三種模型對預測集的預測結果。由表2可知,QPSR模型的預測效果最好,具有最大的相關系數和最小的相對誤差百分比。說明采用非線性方法來建立因素與指標之間的關系,能夠反映二者之間復雜的非線性關系以及因素之間的交互作用。MLR模型的預測結果優于PCR模型的預測結果,說明前兩個主成分的累積貢獻率雖然達到92.2%,但是還有一些重要信息丟失,不能完全解釋4個氣敏傳感器信息。表中數據顯示為:3種模型中二次多項式逐步回歸(QPSR)相關系數最大,預測標準差最小,相對誤差百分比最小,由此可以確定,對于本研究中信陽毛尖茶品質的電子鼻分析中,最優模型為二次多項式逐步回歸。
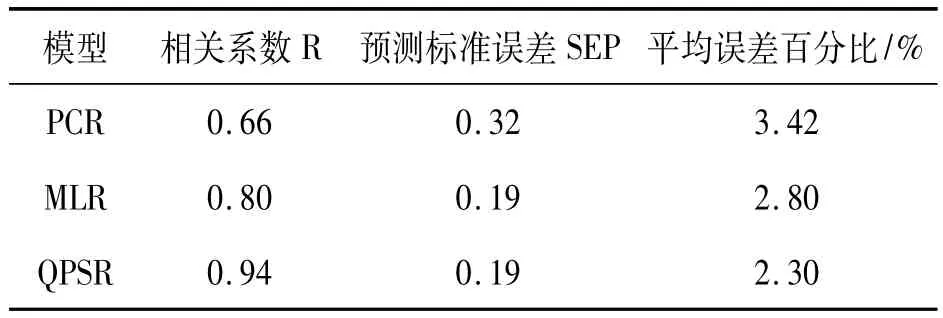
表2 不同模型預測結果比較
3 結論
(1)對三個等級信陽毛尖茶的咖啡堿含量檢測結果表明茶葉等級越高,咖啡堿含量越高。說明咖啡堿含量對信陽毛尖茶品質有很大的影響。
(2)分析3個等級信陽毛尖茶氣味的傳感器陣列響應值變化發現,傳感器S2對茶葉氣味反應比較大,響應值也比較大,有些傳感器信號或正向或負向偏離1,而有些傳感器信號變化微小。
(3)采用Loading分析和相關分析對傳感器陣列進行優化。Loading分析根據各個傳感器間的密切程度,把10個傳感器分成四類。結合各傳感器之間的相關系數,以及傳感器對茶葉的響應值的大小,選擇S2、S7、S10和S5為最終的新傳感器陣列,用于信陽毛尖茶的品質識別。
(4)對傳感器陣列對信陽毛尖茶葉響應值的數據矩陣進行主成分分析,結果顯示可以將不同等級的茶葉完全區分開,而且效果比較好。說明電子鼻可以檢測到不同品質信陽毛尖茶的氣味差異。
(5)利用PCR、MLR和QPSR方法分別建立信陽毛尖茶基于氣敏傳感器陣列的咖啡堿預測模型。MLR對預測集的預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.80、0.19和2.8%。PCR對預測集的測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.66、0.32 和3.42%。QPSR 對預測集預測值與實測值之間的相關系數,預測標準誤差SEP,平均誤差百分比分別為:0.94、0.19 和2.3%。
(6)對比三種模型的性能發現:3種模型中二次多項式逐步回歸(QPSR)相關系數最大,預測標準差最小,相對誤差百分比最小,由此可以確定,對于本研究中信陽毛尖茶品質的電子鼻分析中,最優模型為二次多項式逐步回歸。
[1]趙菁.綠茶特征香氣成分及與品質的關系研究[D].浙江大學,碩士學位論文,2002.
[2]林新,牛智有,劉梅英,等.近紅外光譜法快速測定綠茶的4種主要成分[J].華中農業大學學報,2009,28(4):487-490.
[3]于慧春,王俊.電子鼻技術在茶葉品質檢測中的應用研究[J].傳感技術學報,2008,21(5):748-752.
[4]于慧春,王俊,張紅梅,等.龍井茶葉品質的電子鼻檢測方法[J].農業機械學報,2007,38(7):103-106.
[5]Dutta Ritaban,Hines E L,Gardner J W,et al.Tea Quality Prediction Using a Tin Oxide-Based Electronic Nose:an Artificial Intelligence Approach[J].Sensors and Actuators B,2003,94:228-237.
[6]Nabarun Bhattacharya,Bipan Tudu,Arun Jana,et al.Preemptive I-dentification of Optimum Fermentation Time for Black Tea Using E-lectronic Nose[J].Sensors and Actuators B,2008,131:110-116.
[7]Yang Ziyin,Dong Fang,Shimizu Kazuo,et al.Identification of Coumarin-Enriched Japanese Green Teas and Their Particular Flavor Using Electronic Nose[J].Journal of Food Engineering,2009,92:312-316.
[8]郭桂義,胡強,劉黎,等.信陽毛尖茶春季不同時期化學成分與品質的變化[J].河南農業科學,2007,(12):48-50.
[9]郭桂義.信陽毛尖茶化學成分與品質關系初探[J].茶葉,2000,26(4):228-233.
[10]霍權恭,楊京,劉鐘棟,等.信陽毛尖茶葉揮發性成分GC/MS分析[J].中國農學通報,2005,21(7):108-110.
[11]郭桂義,胡孔鋒,袁丁.信陽毛尖茶的化學成分研究[J].食品工業科技,2006,27(12):162-167.
[12]周海濤,殷勇,于慧春.勁酒電子鼻鑒別分析中傳感器陣列優化方法研究[J].傳感技術學報,2009,22(2):175-178.
