肺癌家系腫瘤風險度病例對照研究與預測模型
2011-09-11 08:35:24林歡鐘文昭楊學寧嚴紅虹吳一龍
中國肺癌雜志 2011年7期
林歡 鐘文昭 楊學寧 嚴紅虹 吳一龍
大多數人類腫瘤和環境因素相關,但同樣暴露于特定致癌物,卻僅部分人群發病。另外,某些腫瘤也有明顯的家族聚集現象。可見,除環境因素外,遺傳背景尤其是基因的多態性差異也是重要的決定因素。來自冰島等地的研究揭示,家族聚集可表現為不同類型腫瘤的聚集,提示存在共同的遺傳因素。例如,雌激素相關基因可能和經產婦患乳腺癌與肺癌風險性增加存在交叉聯系[1-4]。瑞典的研究[5]揭示,吸煙可能導致胰腺癌與肺癌的家族聚集,而胰腺癌與乳腺癌的家族聚集可能與BRCA2的遺傳變異有關。本文通過對單位時間內的肺癌患者連續性收集調查資料,進行大樣本量遺傳流行病學調查,對肺癌患者的腫瘤家族聚集性進行研究,并建立肺癌風險度預測模型,期望有助于高危人群的篩選和早期發現。
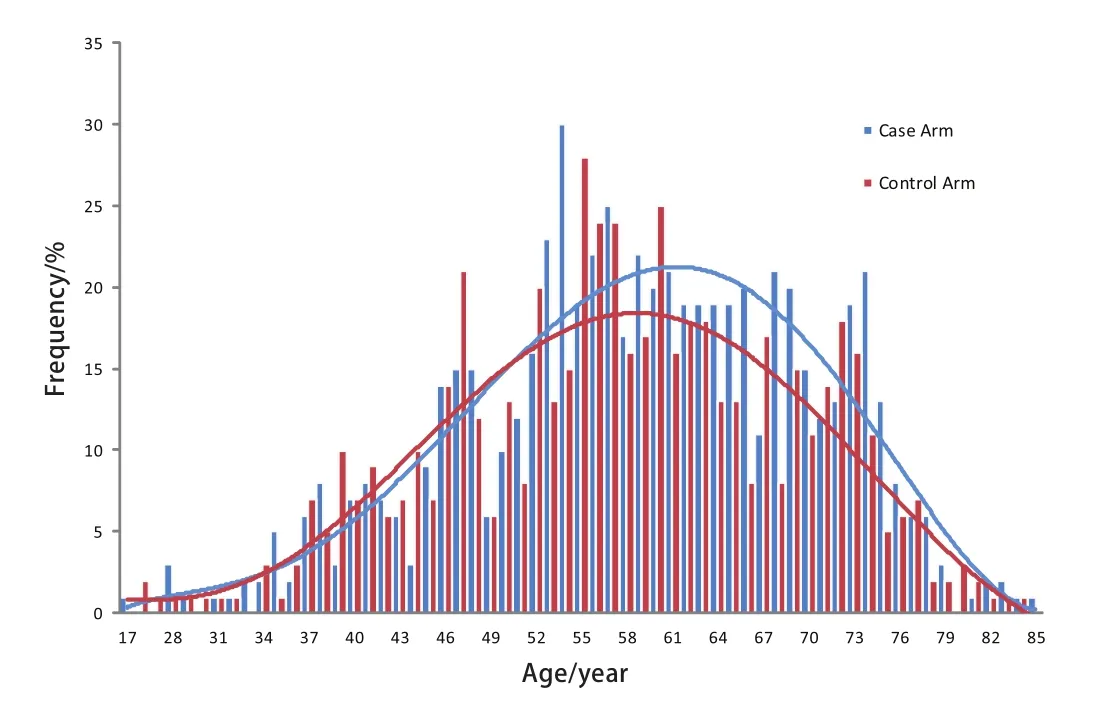
圖 1 病例組和對照組年齡分布圖Fig 1 The distribution of age in case arm and control arm
1 材料與方法
1.1 病例選擇 連續性收集2009年10月-2010年12月于廣東省肺癌研究所病理學確診的肺癌患者,并以其作為先證者,其所在家系確定為先證者家系,其一級親屬(被調查者的父母、子女及同胞)為家系成員。因肺癌先證者的子女發病率極低,與大部分年齡未到發病高峰期有關,且絕大部分子女為先證者和配偶對照組的共同子女,因此統計時將子女從一級親屬范圍剔除。
1.2 對照選擇 對照組為肺癌先證者的配偶家系,納入研究的配偶無腫瘤史,與肺癌家系成員之間不存在任何血緣關系。由同一調查員采用相應調查表記錄對照家系成員的一般情況及家系資料,另一調查員進行復核。
1.3 材料收集 由調查員對初治的肺癌患者進行面訪,在先證者本人或其親屬簽定知情同意書后,應用統一的調查表,對肺癌先證者及其配偶進行調查。調查表內容包括性別、年齡分組、吸煙指數、肺部既往疾病史、居住環境、職業接觸、一級親屬腫瘤家族史和親屬的情況等。由最了解情況者作為問訊對象,提高可靠性。為了減少回憶偏倚,我們盡可能增加了樣本量,同時又讓調查對象對一些不確定情況通過電話咨詢的方式進行證實。
1.4 統計分析 用EpiData 3.1軟件建立數據庫,應用SPSS 17.0對先證者及其家系資料和對照資料進行統計學分析。分類資料的比較采用卡方檢驗,如不滿足卡方檢驗條件者采用Fisher Exact檢驗;計量資料的比較采用兩獨立樣本t檢驗。所有統計均采用雙側檢驗,檢驗水準為0.05。Crude OR通過卡方檢驗計算得出,Adjusted OR通過Logistic回歸分析得到。Logistic逐步回歸模型對因素的篩選條件為進入標準P<0.05,剔除標準為P>0.10。
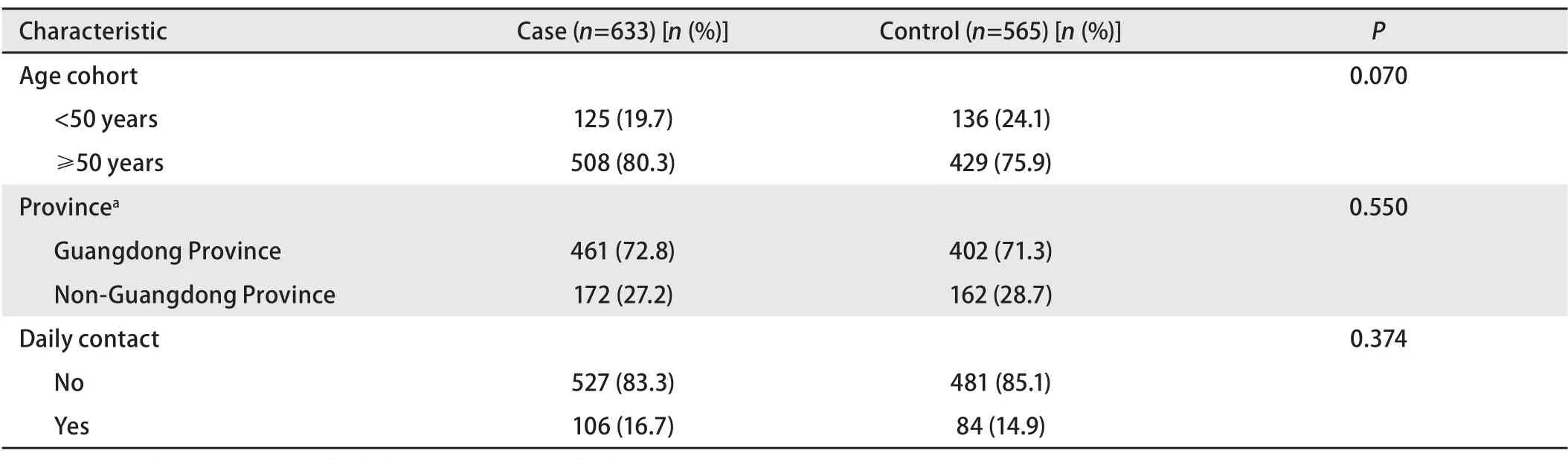
表 1 臨床流行病學資料比較Tab 1 Comparison of epidemiology data
2 結果
2.1 均衡性檢驗 先證者及對照組的籍貫屬于中國東部沿海的25個省或直轄市,廣東省內患者來自廣東省21個地級市。兩者家系在年齡、地區、居住環境和一級親屬人數的比較,無統計學差異(表1)。先證者的肺癌分期采用UICC的TNM2009分期,其中I期患者96例,II期患者63例,III期患者157例,IV期患者317例。
2.2 先證者與配偶年齡分布 由圖1可見,先證者由52歲開始迅速上升,56歲左右達高峰,至80歲后迅速下降,大致呈單峰分布。而配偶的年齡分布大致與之匹配。
2.3 一級親屬患癌風險 由表2、表3可見,肺癌患者一級親屬的患癌風險性明顯高于對照組。家系患癌個數分別為0、1和≥2三組,有統計學差異,發病年齡分層分析顯示晚發肺癌差異較早發肺癌明顯,但早發肺癌樣本量相對較少。
2.4 肺癌風險度的判別預測模型 為控制混雜因素,提高預測準確率,建立以性別(女、男)[6]、吸煙指數(0、<400和≥400)[7]、肺部既往疾病史(無、有)[8]、生活接觸史(無、有)[9]、職業接觸史(無、有)[10]等公認的危險因素和本研究證實的一級親屬患癌個數(0、1、≥2),年齡分組(<50歲、≥50歲)[11]等肺癌風險度影響因素為自變量(各變量的取值以第一種情況為0,余各情況依次遞增),是否為先證者為因變量建立二分類Logistic前進法逐步回歸模型。最終保留在模型中的自變量為性別、吸煙指數、肺部既往疾病史、職業接觸史和一級親屬患癌個數(表4)。
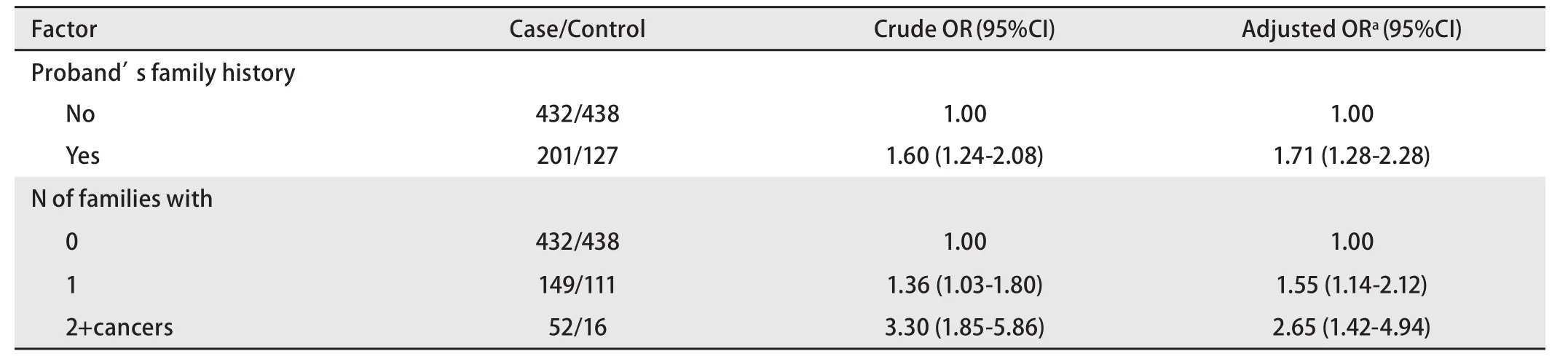
表 2 先證者一級親屬患癌風險性Tab 2 Risk of cancer in first-degree relatives of proband
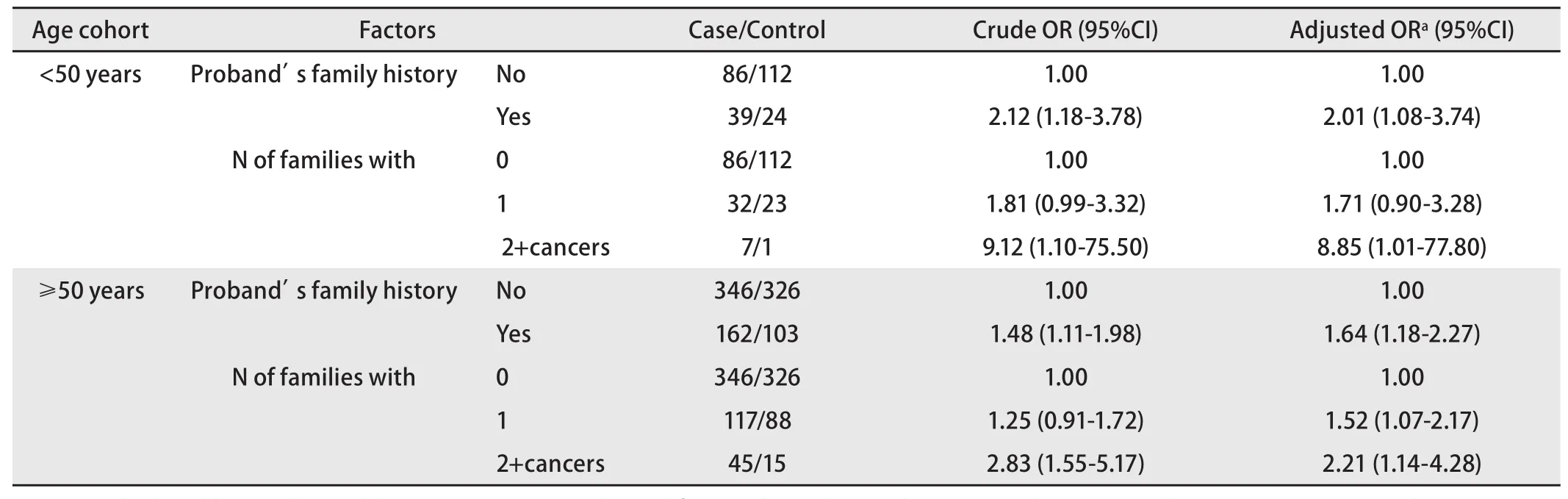
表 3 先證者的一級親屬患癌風險性(以年齡分層)Tab 3 Risk of cancer in first-degree relatives of Proband stratified by age
根據表4得到回歸函數logit(P)=-0.867+0.464*性別+0.135*吸煙指數1+1.545*吸煙指數2+1.689*肺部既往疾病史+0.470*職業接觸+0.436*一級親屬患癌個數1+0.957*一級親屬患癌個數2。
①模型用于預測:由于病例對照研究的非條件Logistic回歸得不到常數項a′的估計值,不能直接用于預測,需要對常數項進行校正,即:
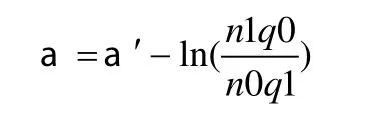
其中n1和n0分別為病例和對照的樣本含量,q1和q0為特定人群中發病和不發病的先驗概率。以《中國腫瘤登記地區2006年腫瘤發病和死亡資料分析》中肺癌發病率49.7/10萬用于常數項的校正[12],然后再用調整后的α作為Logistic回歸方程的常數項計算預測的肺癌發病概率(表5)。
由表5可見,模型將本研究的病例組和對照組分為58個亞組,并列出與普通人群肺癌發病率比較得到的相對風險度。根據第四版流行病學教科書關于暴露與疾病聯系強度的描述,RR在1.0-1.1為無聯系,RR在1.2-1.4代表聯系強度為弱,RR為1.5-2.9代表聯系強度為中等,RR為3.0-9.0代表聯系強度為強,RR≥10代表聯系強度為很強。表5中風險度為普通人群10倍以上的群體共13個亞組,該人群主要為重度吸煙的吸煙人群,在性別、肺部既往疾病史、職業接觸史和一級親屬腫瘤家族史中具備至少兩個以上陽性。
②模型用于判別以驗證正確率(表6):根據估計概率進行判別歸類,第一類為非肺癌(對照),第二類為肺癌(病例)。如果估計概率<0.5,則將其判定為第一類;如果估計概率>0.5,則將其判定為第二類;如果=0.5,暫不歸類。最后將結果與實際情況對照,得到模型的正確率。
③風險度為普通人群10倍以上的群體預測正確率(表7,表8) 由表7和表8可見,在該群體應用本預測模型的正確率達到了88.1%,有良好的應用價值。
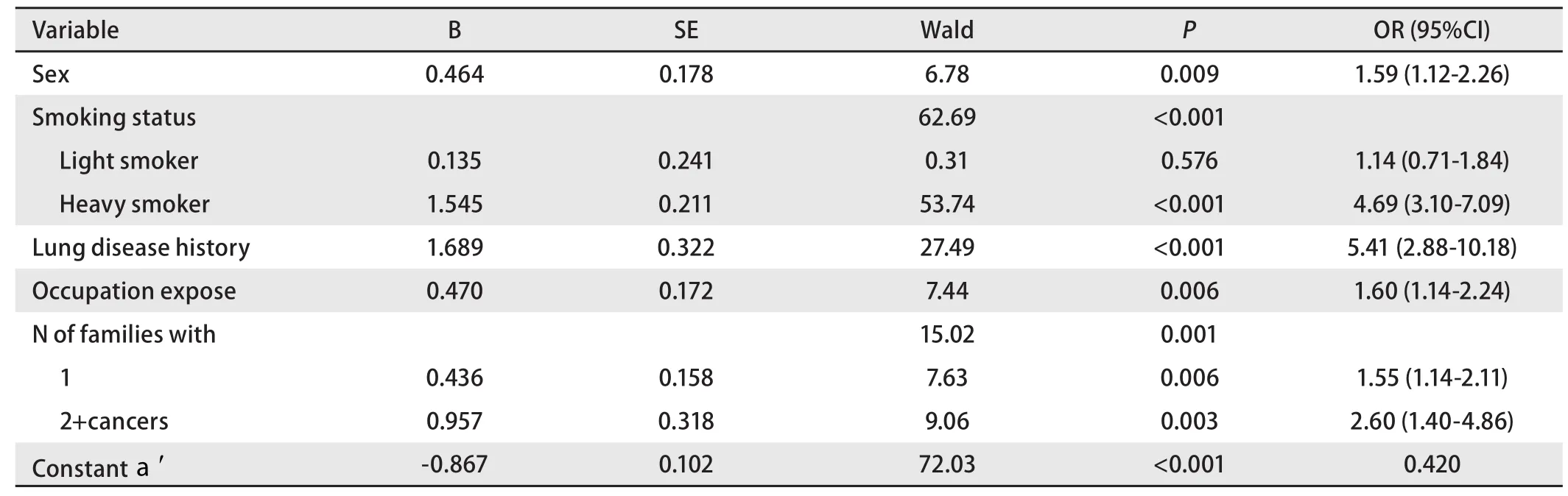
表 4 預測模型的二分類Logistic回歸分析模型Tab 4 A binary Logistic regression analysis of forecasting model
3 討論
吸煙是目前肺癌最重要的危險因素。其它的危險因素包括二手煙、生活接觸、職業暴露、HPV等病毒感染、空氣污染和結核等。基因易感性在年輕肺癌中起到尤其重要的意義。
腫瘤二次打擊學說主要適用于有遺傳傾向的腫瘤,如視網膜母細胞瘤等,對應的臨床特點為:早年發病、病灶雙側或多發和家族聚集傾向,其中家族史是最明顯的臨床特征。Xu等[13]收集了1,561例肺癌先證者的12,817例一級親屬的資料進行分析,提示孟德爾衰減模型和共顯性模型均能容納肺癌的病因解釋,而當把發病年齡分布納入模型時,則發現多基因和環境因子的交互作用模型更符合總體人群的肺癌發病分布。
本研究為單位時間內連續收集病例的大樣本量病例對照研究,地域分布均衡,具有人群普遍性。Ziogas等[14]研究表明,以人口登記為基礎的研究其家族史假陽性率較高,以臨床患者為基礎的研究比較可靠。本研究的調查對象為臨床患者,風險比為控制性別、年齡分組、肺部既往疾病史、吸煙指數、居住環境、職業接觸得到的調整OR,因此,與以人群為基礎的研究比較可信度較高。
美國肺癌遺傳流行病學聯盟2004年首次定位了和肺癌家系關聯的區域——染色體6q23-25,并發現隨著家系中癌癥成員的增加,易感基因與6號染色體上的遺傳標記的連鎖相關性也增強[15]。本文發現在調整性別、年齡分組、肺部既往疾病史、吸煙指數、生活接觸和職業接觸后,肺癌患者一級親屬的患癌風險性明顯高于對照組,且家系患癌個數為1和≥2的兩個亞組均有統計學差異(OR=1.55, P=0.005; OR=2.65, P=0.002),結論與前述類似。這提示隨著家系中腫瘤患者的增加,體現的腫瘤遺傳易感性強度有增加的趨勢,這也是將家系中一級親屬患癌個數列為腫瘤風險度因素之一的依據。另外,發病年齡分層分析顯示晚發肺癌差異較早發肺癌明顯,除早發肺癌例數相對較少的因素外,也可能與肺癌由低腫瘤易感性的遺傳多態性決定有關。

表 5 研究對象的肺癌發病概率預測及相對風險度Tab 5 Prediction of lung cancer morbidity and relative risk in the study objects
日本有一項大規模的前瞻性隊列研究JPHC研究[16]表明所有癌癥家族史與肺癌發病風險增加無關。作為前瞻性研究,其與本研究肺癌先證者一級親屬患癌風險性有高度統計學意義的結論相反。從肺癌與其它腫瘤的家族聚集現象證明有共同遺傳因素影響的眾多研究,以及肺癌發病的理論推斷,肺癌先證者的腫瘤家族史對肺癌風險性的提高應有影響,但影響低于肺癌家族史。分析該研究的隨訪,發現該隊列研究入組132,972受試者,年齡40歲-69歲,隨訪102,255例,隨訪13年發現791例新發肺癌。在基線記錄資料后,追蹤新發肺癌患者資料而未更新腫瘤家族史資料。而本研究以臨床患者為目標人群,即時記錄對應的腫瘤家族史,目的性和時效性強。因此,JPHC研究的樣本量基數大,腫瘤家族史資料未更新,可能導致關聯關系被掩蓋。
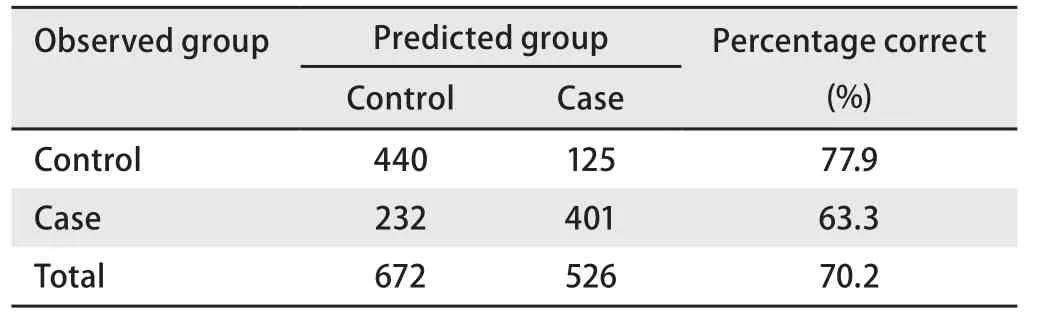
表 6 預測模型效果檢驗Tab 6 Classification tablea of forecasting model
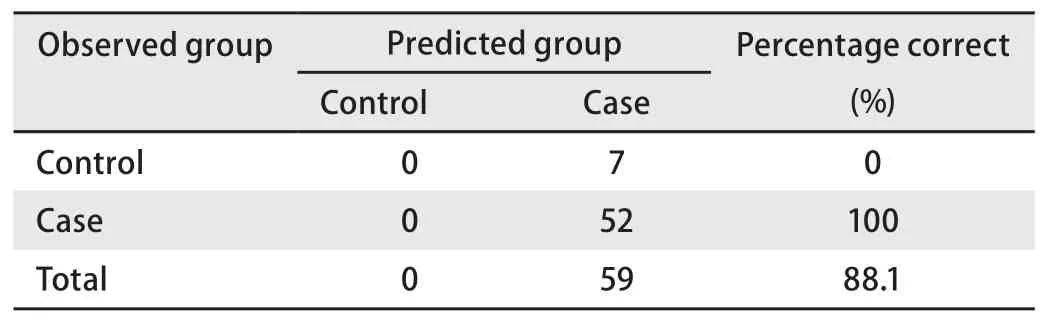
表 8 預測模型中風險度為普通人群十倍以上的群體效果檢測Tab 8 Classification tablea of people whose degree of risk are more than ten times to the Chinese population in the forecasting model
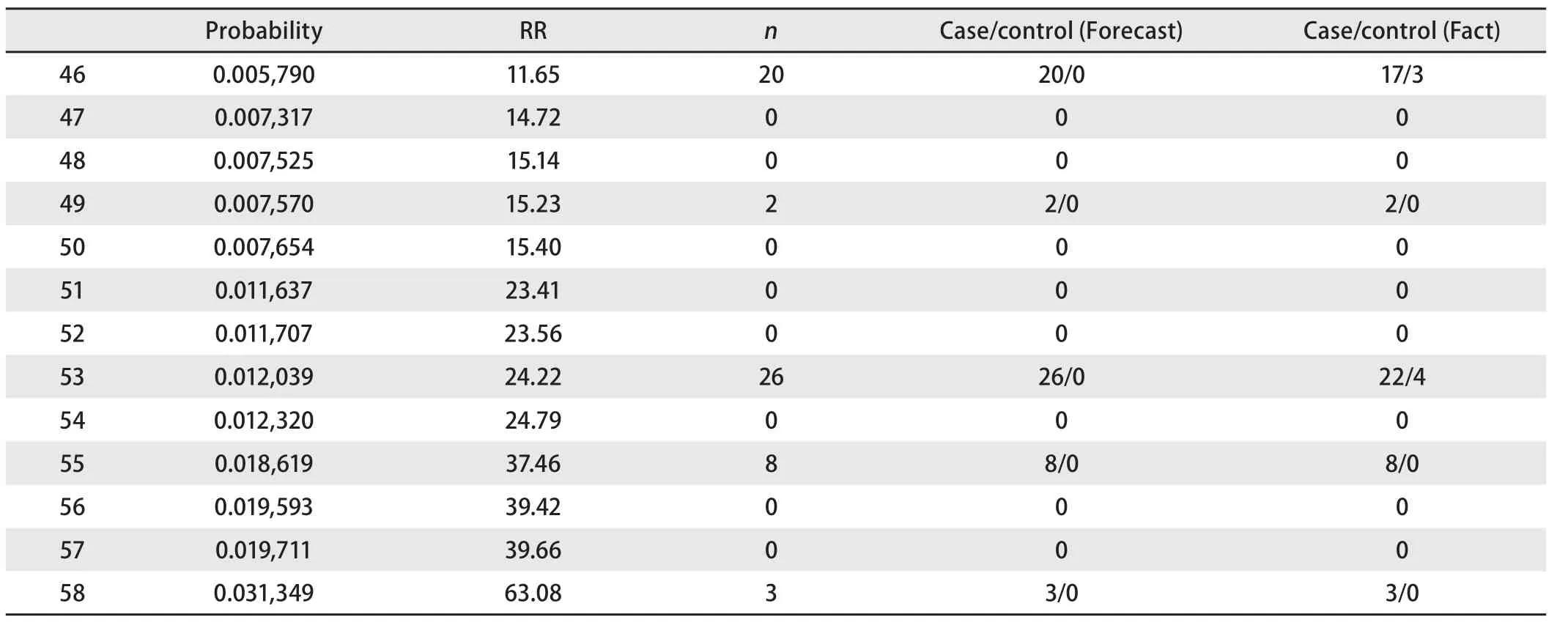
表 7 風險度為普通人群十倍以上的群體預測情況Tab 7 Prediction of people whose degree of risk are more than ten times to the Chinese population
早期肺癌篩查國際行動計劃(International Early Lung Cancer Action Program, I-ELCAP)此前的研究數據[17]表明,每年進行低劑量CT篩查可檢查出I期肺癌,I期肺癌患者若立即進行手術切除腫瘤,其10年生存率可達92%,而所有未治療的I期患者將在5年內死亡。該研究表明低劑量CT篩查可增加早期肺癌的診斷率,從而使患者獲得較好的生存結果。但該篩查的假陽性率一直被詬病。美國國立衛生研究院(National Institutes of Health,NIH)一項大樣本、長期隨機臨床研究[18]表明,對高危人群(吸煙或曾經吸煙達每年30包以上,年齡55歲-74歲)進行低劑量CT掃描篩查肺癌的假陽性率較高,常常因“錯誤預警”導致不必要的檢查、活檢和手術。因此,建立肺癌風險度模型,綜合評估肺癌發病的各個危險因素,找到真正的肺癌高危人群,是性價比最高的途徑。
本文針對吸煙指數、性別、年齡分組、一級親屬患癌個數、肺部既往疾病史、生活接觸史和職業接觸史,建立回歸模型,賦值后得到各亞組肺癌發病概率與人群相比的風險度在0.38-63.08的結論,準確率為70.2%。這可能是因為在低風險的群體,暴露因素和疾病聯系的強度不大從而影響了預測效率。而在聯系強度為很強、風險度為普通人群10倍以上的群體,應用本模型的預測準確率為88.1%。特點為:有肺部既往疾病史的重度吸煙人群,加上男性、職業暴露和一級親屬腫瘤家族史三項中的任一項;有肺部既往疾病史或重度吸煙的人群中,有職業暴露的男性且一級親屬有不少于兩位腫瘤患者。因此,建議風險度為人群10倍以上的高危人群可每年進行低劑量CT篩查,可望提高篩查效能。但因病例組和對照組為配偶關系,生活環境基本相同,所以生活接觸史未保留在模型中,應用時應結合本因素綜合考慮。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫苑(2023年2期)2023-03-15 09:03:04
中國臨床醫學影像雜志(2022年2期)2022-05-25 13:24:34
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
