基于Web的智能信息檢索方法研究*
2011-09-03 10:50:26李春生楊冬黎
黑龍江科學 2011年5期
高 玲, 李春生, 楊冬黎
(1.大慶油田圖書館,黑龍江大慶163300;2.東北石油大學,黑龍江大慶,163318)
Web為用戶提供海量信息的同時,也帶來了大量的噪聲,用戶對大量的無關信息淹沒對自己有價值的信息已經無法忍受[1]。所以即時的處理大量信息,提高信息檢索系統的準確率,使用戶可以快速找到自己所需要的信息已經變得勢在必行,Web信息檢索受到越來越多的重視[2]。Web信息檢索與傳統信息檢索有所不同:一是信息資源海量,用戶對查全率的追求降低,查準率要求越來越高;二是文檔之間的超鏈接結構是Web信息檢索和傳統信息檢索的又一區別[3],鏈接描述文檔對網頁主題的概括有高度的精確性,由此產生了基于超鏈接結構的檢索技術;三是Web上的文本數據大部分用HTML書寫,使用HTML標簽對網頁的修飾作用進行信息檢索。
本文以石油安全信息檢索為例,應用分類算法和中文分詞的關鍵技術,研究了信息檢索模型及其實現。具體包括:⑴以石油安全生產方面的Web頁為例,將大量分散無序的Web頁信息集中起來,經過加工整理,使之形成有序化、系統化的語料庫;⑵結合信息檢索模型的相關理論、關鍵技術,選擇在檢索模型中應用概率的計算方法[4];⑶通過運用統計的學習方法,實現模型對檢索結果的優化與完善。用已知的石油安全生產方面的文檔,對模型的檢索結果不斷地進行訓練,從而使模型在多次交互操作之后,得到的檢索結果逐步接近用戶提問的理想命中結果。
1 基于Web的信息檢索模型設計
建立信息檢索模型是實現檢索系統的基礎,基本設計要求如下:⑴語料庫足夠大,檢索到的數據能滿足一般用戶需求;⑵用戶操作界面簡單,用戶可以很方便地輸入檢索請求;⑶檢索出的信息能夠達到用戶的要求,并能按照合理的順序顯式給用戶,并且可以對顯示的信息進行分類處理。
1.1 模型結構設計
信息檢索是利用一定的檢索算法,借助于特定的檢索工具,針對用戶的檢索需求,從結構化或非結構化的數據中獲取有用信息的過程。把整個信息檢索過程刻畫為三個方面:信息的存儲與組織,信息的檢索,信息的展示[5]。圖1給出了信息檢索過程的框架結構。

圖1 基于Web的信息檢索框架結構Fig.1 Web-based framework for information retrieval
根據圖1的框架結構,可以設計基于Web的信息檢索模型,對Web頁的分類處理分兩個階段完成。第一階段是利用自動搜索程序,通過輸入一個短查詢式的問題,進行初始檢索,然后將檢索出的Web頁面經過頁面清洗,去掉噪聲,最后以文本文檔的形式存入專門設計的后臺數據庫(包含檢索出的題目、上傳時間、內容等)。所謂Web頁面清洗,是從Web頁面中劃分出精確的信息單位,并根據Web頁面信息加工的后續應用的需求,將頁面中不需要的部分去除,將需要的部分提取出來。噪聲是指Web頁中大量的諸如導航條、廣告鏈接、版本信息、更新日期等。本文采用一種新的“HTML頁面清洗壓縮算法”,該方法是把頁面對應的HTML文檔,轉化成對應的HTML樹,然后再對樹進行頁面清洗。經過清洗后,Web頁面在結構和語義上都被劃分成細粒度的信息塊,為后續的信息加工工作順利進行提供了方便。由于在初始檢索結果中會得到數目相當龐大的結果,包含的信息質量也會良莠不齊,大量的與用戶意圖不相關的文檔也混雜在其中,這樣就造成檢索結果不夠準確。因此需要對這些文檔再進行第二次檢索,即進入檢索的第二階段。第二階段主要任務是對文本文檔加以歸類,利用文本分類方法來組織信息,最終實現按類顯示用戶查找信息的要求。
第二階段信息檢索模型分成前臺用戶查詢處理和后臺文檔信息處理兩大部分,結構如圖2所示。
前臺部分:給用戶提供查詢界面,用戶在該界面輸入查詢請求后,調用后臺信息,界面中會顯示查詢結果。用戶點擊查詢到的文檔標題后,又彈出一個界面。界面的上方顯示這篇文檔屬于第幾類,界面的下方會顯示這篇文章的詳細內容。
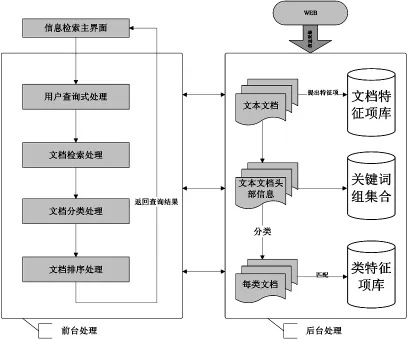
圖2 模型的組織結構Fig.2 Structure of the model
后臺部分:利用第一階段從Web上收集來的用戶初次查詢請求資料,將其轉化為統一格式的文本文檔。然后對所有文檔采用停用詞處理,也就是刪掉沒有意義的代詞、助詞、副詞。再采用信息檢索模型對所有文檔進行檢索,先提取特征項。我們選取能正確反映文檔重要內容的文檔標題、摘要部分進行關鍵詞及詞組提取,然后這些詞形成了文檔的關鍵詞組集合。再計算每篇文檔中關鍵詞出現的頻數,將詞頻數高的關鍵詞也存儲到文檔特征項庫中去。將查詢式詞組、特征項及已知的數據字典中的類特征項進行匹配,使用分類算法公式計算概率值,依據數值進行歸類處理。
1.2 分類算法設計
為了對模型進行訓練,將文本集分為兩個部分:訓練集和測試集。所謂訓練集是由一組已經分好類(即已給定類別標號)的文本組成,用于歸納出各個類別的特性以構造分類器。測試集是用于測試分類效果的文檔的集合。其中每個文本都通過分類器分類,然后與正確決策的分類結果相對比,從而得到對分類器效果的評價,其中,測試集不參與分類器的訓練。
本文采用貝葉斯分類方法對文檔進行分類。由于真實文本的一個屬性對給定類的影響獨立于其他屬性的假設并非總是成立,我們選取了貝葉斯網絡分類器。這種模型考慮到了屬性之間的依賴關系,更能反映文本的真實情況。但代價是計算復雜度比樸素貝葉斯高。貝葉斯分類算法的基本思路是計算文本屬于類別的概率,文本屬于類別的概率等于文本中每個特征項屬于類別的概率的綜合表達式。其具體算法步驟如下:輸入訓練集文本文檔,每個文檔都包含特定的特征的詞。
第一步:先對訓練集中的每個文本文檔進行分詞處理,提取關鍵詞。依次計算出每個關鍵詞在這個文檔di中出現的次數ni和頻度fi。頻度:

其中N為每個關鍵詞在文檔di中出現的次數的和。頻度高的這些關鍵詞放到文本特征項庫中。
第二步:用下列公式計算特征項庫中每個特征詞屬于每個類別的概率。

其中:
P(Wk|Cj)為特征詞 Wk在類 Cj中出現的比重,|DJ|為該類的訓練文本數,N(Wk,di)為特征詞Wk在文檔di中的詞頻,|V|為特征文檔庫中的總詞數(Wx,di)為該類所有詞的詞頻和。
第三步:文本到達時,根據特征詞,按下面的公式計算該文本di屬于類Cj的概率:

P為類的總數,N(Wk,di)為Wk在di中的詞頻,n為特征詞總數。
第四步:比較測試文檔屬于所有類的概率,將文本分到概率最大的那個類中。
第五步:確定閾值。根據訓練集中文檔的概率和頻率,算出每一類的閾值。
第六步:當有新文檔出現時,只需要用它第二步計算出P(Wk|Cj)和每一類的閾值進行比較,大于閾值的認為是相關文檔,把它歸入該類中。省去第三步到第五步的計算過程,節約了時間也減少了計算工作量。
2 模型在石油安全領域的應用
在基于中文分詞和文本分類算法相結合的信息檢索模型的基礎上,針對石油安全領域的Web信息檢索設計了一個智能信息檢索系統,該系統在查找準確率、文檔分類方面均取得了較好的結果。
2.1 實驗數據
本文利用網絡蜘蛛自動搜索程序從百度網上采集了與石油相關的Web頁400個。其中200個作為訓練集,剩下的200個作為測試集。為了保證訓練數據的正確性,訓練集里的Web頁是由人工提取的。
2.2 數據處理
數據處理基于語料庫。語料庫主要由文檔特征項庫、類特征項庫、關鍵詞組集合三大部分組成。文檔特征項庫是從由特征提取中詞頻高的關鍵詞組成的(可以選擇字、詞或詞組來作為特征項,但是根據做實驗顯示的結果來看,選取“詞”作為特征項要優于字和詞組,所以文檔特征庫是由詞構成的);關鍵詞組集合是從每篇文本文檔的標題、摘要、關鍵詞信息中獲取的;類特征項庫是利用數據字典中的數據獲得的。
數據處理的目的是讓系統最終實現智能分類,要分類就得先分詞。對于一篇經過預處理后的文本文檔,根據它出現的標點符號位置,先將它切分成句子。遇到逗號、問號、感嘆號、分號、冒號、省略號和回車換行符,就認為是一個句子的結束標志。另外,如果句子中存在括號,被一對括號括起的部分認為是一個獨立的句子。然后對句子再進行切分,得到詞。這主要是因為考慮到自然語言處理技術的影響,選擇詞作為文本組成的特征,更符合人們的思維習慣。因此本文中文檔特征項庫中的關鍵詞、關鍵詞組集合中的特征項都是用文本分詞的方法獲得的。本文采用的中文分詞算法是基于分詞詞典(常用詞詞典)的字符串匹配算法,其分詞過程如3所示。

圖3 中文分詞流程Fig.3 Flow chart of Chinese Word Segmentation
現以石油安全生產領域的一篇名叫《石油庫帶掩體油罐防護安全距離的確定》的文檔D1和《加油站與加氣站安全距離要求》的文檔D2為例,說明對文檔的智能分類過程。

表1 D1和D2關鍵詞統計Table 1 Keywords statistics of Documents D1 and D2
石油庫帶掩體油罐防護安全距離的確定。摘要:油庫安全距離有兩個不同的概念,一個是防火安全距離;另一個是防護安全距離。針對如何科學地確定油庫防護安全距離這一問題,對炸彈的破壞因素和建筑物的破壞等級進行了分析與劃分,從而根據建筑物的重要性和抗沖擊波破壞能力,確定其允許破壞的等級,再由投彈的裝藥量計算出沖擊波的設防安全距離。對于帶有掩體的油罐,其防護安全距離的確定應根據允許破壞等級、爆炸位置以及有掩體的兩油罐間防護安全距離的計算來確定。關鍵詞:油庫,油罐,安全,距離。
加油站與加氣站安全距離要求。根據《汽車加油站、加氣站設計與施工規范》,加氣機與加油站、加氣站房的最小防火距離為5米。
從文檔D1和D2的標題、摘要(或者主要敘述內容)、關鍵詞信息中我們取出相對重要的詞放到關鍵詞組集合中,如表1所示。
由于“安全”和“距離”這兩個詞在文檔D1和D2中全出現了,所以這連個詞的NDocuments=2,其余詞的NDocuments=1。如下圖4所示。

圖4 “距離”關鍵詞統計Fig.4 Statistics of the keyword“Distance”
從圖4可知,關鍵詞“距離”出現在D1與D2兩篇文檔中,“距離”在文檔D1中一共出現了9次,第一次出現的位置為29,第二次出現的位置離第一次出現位置的相對的位移為26(這里采用的是一個漢字占2個字符的算法來計算詞在文檔中的位置的)。“距離”在文檔D2中僅出現了2次。從圖4顯示的內容來看,關鍵詞“距離”這個詞在文檔D1中的出現的頻率是很高的,所以把它存入到文檔特征項庫中。類特征項庫的數據是從已知的石油安全數據字典中獲得的。
2.3 檢索結果
在面向用戶的信息檢索系統的檢索詞提交框中,用戶輸入想查詢的關鍵詞,或者在下拉列表框中選擇已知的類別中的某一類,點擊“搜索”按鈕提交給系統。經過計算處理后,查到的與用戶輸入相關的文檔結果會按相關度展示給用戶。通過對系統測試,文檔對應分類的查準率穩定在62%到71%之間。如圖5所示。

圖5 不同類別查準率的比較Fig.5 Comparison of accuracy of different categories
3 結 論
提出了分階段對Web頁的檢索方法。第一階段,通過在Web站點上安裝程序獲取Web頁,應用頁面清洗技術,使之變成文本文檔,實現了模型中數據導入前的預處理;第二階段,把分類算法運用到信息檢索模型中,在計算文檔與用戶需求相關度的同時,對文檔進行了分類。通過概率模型實現了文檔的分類,并且把這種方法應用到了石油安全生產領域,取得了良好的分類效果。
[1]WANGNENGBIN.Databasesystemtutorial[M].Beijing:Publishing houseof Electronics Industry,2004.
[2]張德海,沙月林.基于本體與工作流的知識服務系統[J].計算機工 程,2009,35(19):75~77,80.
[3]MENGXIAO-FENG,ZHOULONG-XIANG,WANGSHAN.Stateof theart and trends in databaseresearch[J].Journal of software,2004,15(12):1822~I836.
[4]杜小勇,李曼,王珊.本體學習研究綜述[J].北京軟件學報,2006,17(9):l837~1847.
[5]王珊,薩師煊.數據庫系統概論[M].北京:高等教育出版社,2005.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
新聞傳播(2016年18期)2016-07-19 10:12:06
現代計算機(2016年11期)2016-02-28 18:35:15
河南科技(2014年23期)2014-02-27 14:19:15
