關聯規則挖掘在教師成長中的應用
2011-06-12 08:55:32高曉紅柴銀平
網絡安全技術與應用 2011年6期
高曉紅 柴銀平
楚雄師范學院 云南 675000
0 引言
隨著現在信息技術與科技的發展,現代高校在引進許多新技術和設備的同時也積累了許多教師的數據。并形成了具有一定規模的教師信息數據庫。然而面對眾多的數據,高校管理層如何利用,如何從中發現對高校教師隊伍建設有實際指導意義的規律,特別是如何才能將人才的引進及培養與社會的需求正確結合?關聯規則挖掘是數據挖掘的一個重要的研究分支,其主要的研究目的是從大型數據集中發現隱藏的、有價值的屬性間存在的規律。本文用關聯規則挖掘技術在這方面做了一定的探索和研究,期望能得到一些有益的啟示。
1 相關概念
1.1 關聯規則
定義:設I= {i1,i2, . ..,in}是項的集合。包含K個項的項集稱作K項集。設D是數據庫記錄的集合,其中每個事務T是項的集合,且T?I。設X是一個項集,事務T包含X當且僅當X?T。
關聯規則是形如X?Y 的蘊涵式,這里X?I,Y?I,且X∩Y=Φ。X稱為規則的左部或規則的前提(LHS),Y稱為規則的右部或結論(RHS)。
度量規則的參數是支持度與置信度。支持度是指數據集中的實例同時包含條件屬性與決策屬性的共同概率,支持度揭示了規則的重要性。置信度表示實例在包含條件屬性的前提下,也包含決策屬性的條件概率,它揭示了規則的可信度。在粗糙集理論中支持度與置信度可以表示為:support(x?y) =p(x∪y)
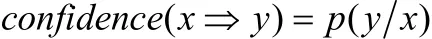
其中P(X)表示X在數據D中出現的概率,其余相似。support(x?y)指X、Y在D中同時出現的概率;confidence(x?y)表示在X出現的前提下Y出現的條件概率。若得到的規則同時滿足支持度不小于支持度閾值和置信度不小于置信度閾值,則該規則有意義。
1.2 決策表的屬性約簡
在決策表中,不同的屬性可能具有不同的重要性。要找出某些屬性的重要性,就要從表中去掉一些屬性,再來考察沒有該屬性后分類會有怎樣的變化,若去掉該屬性后分類變化較大,則說明該屬性強度較大,重要性高,反之,則說明該屬性重要性低。決策表的一般屬性約簡的具體步驟:
(1) 求多個條件屬性C1,C2,C3,…,Cn的等價類;
(2) 計算從C中分別去掉C1,C2,C3和Cn后所有屬性集下的等價類;
(3) 求決策屬性D與條件屬性C的依賴度;
(4) 檢查從C中去掉C1,C2,C3或Cn時分類的變化情況,若分類發生較大變化,說明該屬性不可去,否則可去。
2 關聯規則挖掘模型
在大量實踐的基礎上,總結出了一個相對成熟的基于粗糙集的關聯規則挖掘模型,其基本思想和步驟如下。本文應用基于粗糙集的關聯規則的挖掘過程分為三步:數據預處理,屬性約簡與關聯規則的挖掘,見圖1。
(1) 數據預處理:通過對高校人事數據的初始信息進行數據清洗,缺失值處理,轉換及數據選擇,獲取初始信息表,且初始表轉換為決策表形式,并明確條件屬性集和決策屬性;
(2) 屬性約簡:對條件屬性進行約簡,刪除多余屬性,在此基礎上利用文獻[1]中的算法進行屬性約簡并生成約簡屬性集;
(3) 關聯規則挖掘:輸入支持度閾值和置信度閾值,根據數據約簡結果,利用粗糙集理論文獻中的算法,進行關聯規則的挖掘。
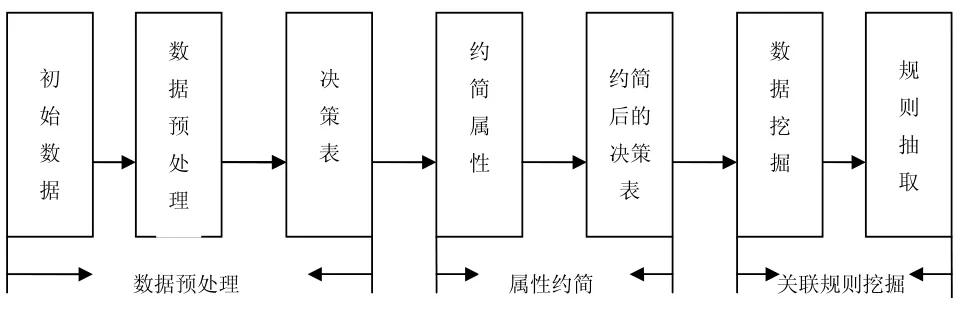
圖1 基于粗糙集的關聯規則模型
3 關聯規則挖掘技術在教師成長中的應用
下面以高校教師成長信息為例(本文以職稱為教授和講師作為高校人才成長的標志,根據參加工作時間的長短和目前職稱來判斷教師成長的快慢),說明基于粗糙集的關聯規則挖掘算法的實施過程。
根據上述構建的數據挖掘模型,利用屬性約簡算法對高校教師數據進行約簡。首先進行數據預處理,其次求出約簡,并在此基礎上根據值約簡等減少屬性和個體數目,最后提取規則應用于新對象的分析和預測。
3.1 數據預處理
本文以本人所在高校教師數據為例,采用關系數據庫模型,經關系數據庫的導入及連接并進行抽象、離散化等預處理。將影響教師成長的因素:性別、政治面貌、學歷、畢業學校、年齡、學歷變動、現聘職稱、教齡、教學能力和科研能力作為系統的條件屬性C,而將教師的成長速度作為決策屬性D。
對于具體的數據處理時可先將其抽象、離散化、使后續的表格簡潔明了。性別(1:男2:女),年齡(1:25—30 2:30—35 3:36—40 4:40—45 5:45以上),教齡(1:1—5 2:10—15 3:16—20 4:21—25 5:25 以上),政治面貌(1:黨員 2:其他),畢業院校(1:重點高校 2:普通高校),學歷(1:學士 2:碩士),現聘職稱(1:教授 2:副教授3:講師 4:助教),評定年齡(1: 25—30歲, 2: 31—35歲, 3:35—40歲, 4: 40歲以上),學歷是否變動(1:是 2:否),教學能力,科研能力(1:高 2:中 3:一般)和成長(1:快 2:中 3:慢)。
以上劃分等級的標準是根據以往實際經驗和具體的數據而確定,按以上的規則概化和離散化原始數據,根據以往的經驗和實際的情況可判斷性別,年齡,政治面貌,學歷變動為冗余屬性。刪除其中的冗余屬性得到預處理后的數據表如表1所示。
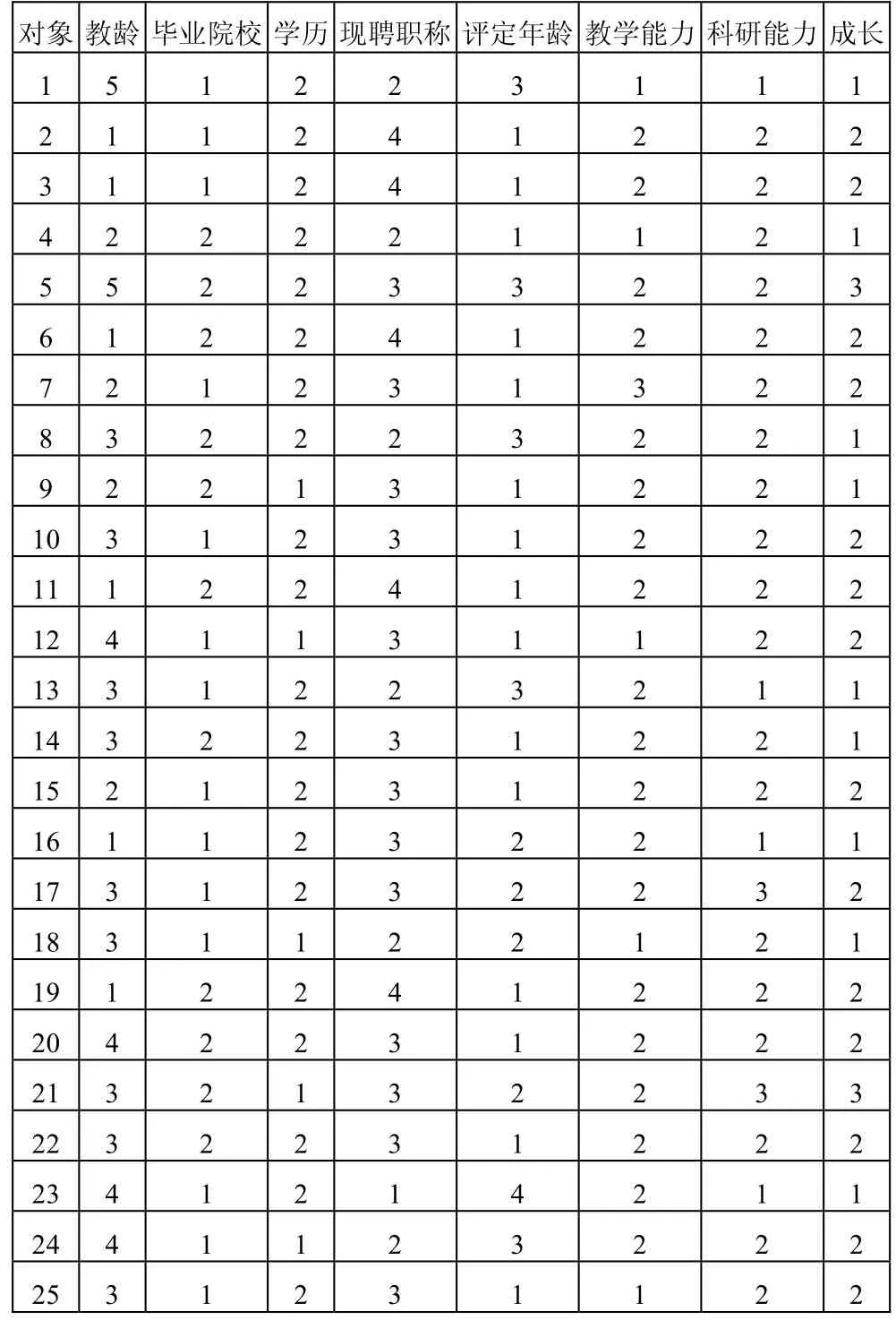
表1 預處理后的教師數據
3.2 屬性約簡
表1中的數據只是對初級數據的簡單分類和離散化,首先刪除表1中的冗余對象,然后對其進行屬性約簡,通過計算可得 U 的屬性約簡集為{C4,C5,C6,C7} 。此時對屬性約簡后對應的表再次刪除冗余對象,得到最終屬性約簡后的數據如表2所示。為了計算方便將條件屬性在表中以C1,C2,…,C7來表示,其中C1 = 教齡,C2=畢業院校,C3=學歷,C4=現聘職稱,C5=評定年齡,C6=教學能力,C7=科研能力,D=成長。
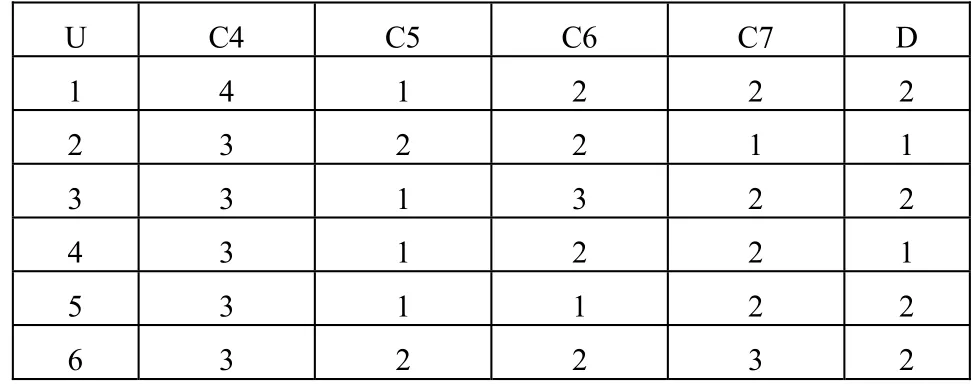
表2 約簡后的數據表
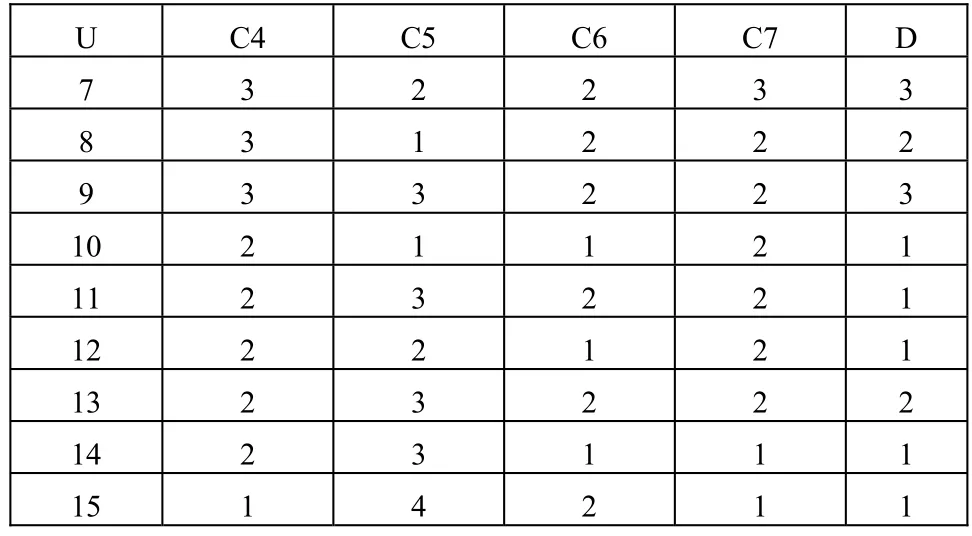
續表
3.3 關聯規則挖掘
根據上面得到的約簡,通過屬性之間的隱含關系來挖掘關聯規則,給定支持度閾值 5%,置信度閾值 80%,可得到同時滿足支持度閾值和置信度閾值的項目集生成的關聯規則有:
Rule 1(現聘職稱=4)&(評定年齡=1)&(教學能力=2)&(科研能力=2)=>(成長速度=2);
Rule 2(現聘職稱=3)&(評定年齡=1)=>(成長速度=2);
Rule 3(現聘職稱=3)&(評定年齡=3)=>(成長速度=3);
Rule 4(現聘職稱=2)&(評定年齡=1)=>(成長速度=1);
Rule 5(現聘職稱=2)&(教學能力=1)&(科研能力=1)=>(成長速度=1);
Rule 6(現聘職稱=1)&(評定年齡=4)=>(成長速度=1)。
以上規則的含義如下:由第一條規則可知現聘職稱為助教,評定年齡在25到30,教學和科研能力中等,則可以斷定教師的成長速度中等;由第二條規則可知:現聘職稱為講師,評定年齡在25到30,可以斷定該教師的成長速度中等;第三條規則說明如果現聘職稱是講師,評定年齡在35到40,斷定教師的成長速度慢;第四條規則說明職稱是副教授,評定年齡在25到30,可以斷定該教師的成長速度快;第五條規則說明職稱是副教授,教學和科研能力高的教師成長速度快;第六條規則說明職稱是教授,評定年齡是 40以上的教師成長速度快。
由以上規則可以得出:現聘職稱,評定年齡,教學能力和科研能力對教師成長的快慢有顯著影響。現聘職稱是助教,教學和科研能力都中等的教師,屬于成長速度中等的類型;而在 30歲前評為副教授的教師,成長速度快;職稱是副教授,教學和科研能力較強的教師的成長速度也是快速型的。因此,如果高校希望教師能夠快速成長,則在人才引進時就要多考慮教師的教學和科研能力,在人才的考核方面提出新的機制來改變傳統的只看學歷和畢業院校等情況。
4 結論
本文在對數據挖掘相關技術、關聯規則挖掘算法進行深入研究的基礎上,歸納總結了基于粗糙集理論的關聯規則挖掘模型和屬性約簡算法,利用某高校教師的成長數據,進行了關聯規則的挖掘實驗,將其應用于高校教師的成長中,并對關聯規則產生的結果進行了解釋。
[1]孟慶文,徐文龍.粗糙集合在中醫診斷中的應用研究.安徽大學學報[J].2006.
[2]白秀玲,崔林,王向陽.一種基于關聯規則挖掘的粗糙集約簡算法[J].計算機工程與應用.2003.
[3]曾黃麟.基于粗集方法的智能專家系統[J].中國工程科學.2001.
[4]馮少榮,肖文俊.數據挖掘技術在試題質量評價中的應用[J].東北師大學報(自然科學版).2008.
[5]張瑤,陳高云,王鵬.數據挖掘技術在試卷分析中的應用.西南民族大學學報(自然科學版).2008.
[6]王艷春,郭小利,陳鴻等.基于數據挖掘算法的教學測評系統研究[J].長春理工大學學報.2006.
[7]蔡偉杰,張曉輝,朱建秋.關聯規則挖掘綜述[J].計算機科學.2005.
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
快樂語文(2021年27期)2021-11-24 01:29:04
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
甘肅教育(2020年22期)2020-04-13 08:11:16
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
