基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法
2020-10-10 01:00:08姚佳奇徐正國(guó)燕繼坤李智翔盲信號(hào)處理重點(diǎn)實(shí)驗(yàn)室成都610041
計(jì)算機(jī)工程與應(yīng)用 2020年19期
姚佳奇,徐正國(guó),燕繼坤,熊 鋼,李智翔盲信號(hào)處理重點(diǎn)實(shí)驗(yàn)室,成都610041
1 引言
多標(biāo)簽文本分類是自然語言處理的一個(gè)基礎(chǔ)問題[1-2]。傳統(tǒng)的多標(biāo)簽文本分類算法適用于標(biāo)簽閉集的問題。然而在實(shí)際應(yīng)用中,如根據(jù)郵件內(nèi)容確定接收人、新聞、商品評(píng)論的標(biāo)簽分類等問題,都會(huì)隨著時(shí)間的進(jìn)展,不斷出現(xiàn)新的標(biāo)簽,或者標(biāo)記規(guī)則發(fā)生變化導(dǎo)致標(biāo)簽的變化,本文將這些問題歸納為動(dòng)態(tài)多標(biāo)簽文本分類問題,由于標(biāo)簽隨時(shí)間發(fā)生變化,傳統(tǒng)的多標(biāo)簽文本分類算法在處理動(dòng)態(tài)多標(biāo)簽文本分類問題上出現(xiàn)了應(yīng)用瓶頸。
一種簡(jiǎn)單的方法是通過內(nèi)容相似解決動(dòng)態(tài)多標(biāo)簽文本分類問題。即通過計(jì)算待分類文本與歷史文本的內(nèi)容相似度,如計(jì)算兩個(gè)文本的TF-IDF向量的相似度,然后將與待分類文本最相似的歷史文本的標(biāo)簽分類給待預(yù)測(cè)文本。然而內(nèi)容相似度高并不意味著具有相似的標(biāo)簽。如圖1 所示,“我喜歡吃蘋果”與“我不喜歡吃蘋果”在內(nèi)容上很相似,但第一句是正向情感標(biāo)簽,而第二句是負(fù)向情感標(biāo)簽。
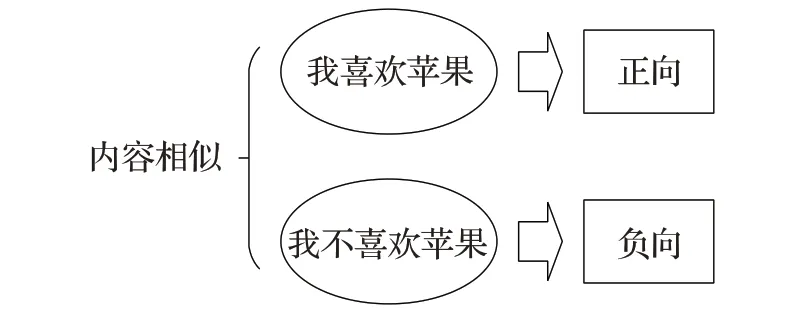
圖1 內(nèi)容相似但標(biāo)簽語義不相似的示例
因而,本文提出了一種基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法(Dynamic Multi-Label Text Classification algorithm based on Label Semantic Similarity,DMLTC-LSS)。DMLTC-LSS算法首先按照標(biāo)簽固定的方式訓(xùn)練基于卷積神經(jīng)網(wǎng)絡(luò)的多標(biāo)簽文本分類器,然后取出該網(wǎng)絡(luò)的倒數(shù)第二層的向量為文本的特征向量。由于該特征向量是在有標(biāo)簽監(jiān)督的環(huán)境下訓(xùn)練得到的,因而含有標(biāo)簽的語義信息。在測(cè)試階段,將待分類文本通過訓(xùn)練階段的多標(biāo)簽文本分類器獲取相應(yīng)的特征向量,然后采用最近鄰的算法獲取與帶分類文本特征向量最相似的訓(xùn)練集文本的標(biāo)簽,并將該標(biāo)簽分類給待預(yù)測(cè)文本。考慮到與待分類文本時(shí)間越近的文本越有可靠性,DMLTC-LSS 在標(biāo)簽語義相似的基礎(chǔ)上乘以時(shí)間衰減因子,使得時(shí)間越近的文本的相似度越高。
本文分別測(cè)試了基于卷積神經(jīng)網(wǎng)絡(luò)、循環(huán)神經(jīng)網(wǎng)絡(luò)和BERT 的算法以及基于內(nèi)容相似的算法在處理動(dòng)態(tài)多標(biāo)簽文本分類問題上的性能。然后在基于卷積神經(jīng)網(wǎng)絡(luò)的多標(biāo)簽文本分類器的基礎(chǔ)上,構(gòu)建了DMLTCLSS 算法。實(shí)驗(yàn)結(jié)果表明,本文提出的DMLTC-LSS 算法具有較優(yōu)的性能。
2 相關(guān)工作
2.1 文本特征
文本特征可以按照詞的表示方法分成兩類:一類將詞表示成獨(dú)熱向量(One-Hot),即獨(dú)熱模型;一類將詞表示成固定長(zhǎng)度的連續(xù)向量,即詞嵌入模型(word embedding)[3]。基于獨(dú)熱向量的文本特征,如TF-IDF 無法表示詞的語義信息,導(dǎo)致了建立在該文本特征上的機(jī)器學(xué)習(xí)模型的性能受限。然而在大規(guī)模語料集上訓(xùn)練得到的詞嵌入模型利用了詞的共現(xiàn)信息,從而一定程度上捕獲了詞的語義信息。CBOW和Skipgram是兩種經(jīng)典的訓(xùn)練詞嵌入模型的算法[4-6]。由于詞嵌入上述優(yōu)勢(shì),研究者提出了許多基于詞嵌入的文本分類模型[7]。這些模型可以根據(jù)采用的神經(jīng)網(wǎng)絡(luò)架構(gòu)劃分為基于卷積神經(jīng)網(wǎng)絡(luò)[8-9]和基于循環(huán)神經(jīng)網(wǎng)絡(luò)兩大類[10-11]。
最近,一些研究者提出一個(gè)詞在不同的上下文中具有不同的語義,應(yīng)當(dāng)具有不同的向量表示[12]。因而,研究者提出了具有上下文背景的詞嵌入模型,如ELMo[12]、GPT[13]和BERT[14]等。這些模型首先根據(jù)某些訓(xùn)練目標(biāo)(如預(yù)測(cè)下一個(gè)詞)訓(xùn)練得到語言模型,然后再根據(jù)下游任務(wù)微調(diào)語言模型。實(shí)驗(yàn)結(jié)果顯示具有上下文背景的詞嵌入模型在多項(xiàng)自然語言處理任務(wù)中取得了最優(yōu)的性能。
2.2 多標(biāo)簽分類
多標(biāo)簽分類任務(wù)是賦予一個(gè)樣本多個(gè)相關(guān)的標(biāo)簽。多標(biāo)簽分類算法大體上可以分成兩類:?jiǎn)栴}適應(yīng)類和算法適應(yīng)類。
(1)問題適應(yīng)類:即將多標(biāo)簽分類問題轉(zhuǎn)換成其他學(xué)習(xí)問題。典型算法包括BR(Binary Relevance)[15]、
Classifier Chains(CC)[16]、Calibrated Label Ranking(CLR)[17]
和Label Power(LP)[18]等。BR 將多標(biāo)簽分類轉(zhuǎn)換成了多個(gè)二分類問題,因此,BR算法未能夠利用標(biāo)簽之間的關(guān)聯(lián)。CC 算法則構(gòu)造了鏈條式的二分類器,鏈條上后一個(gè)二分類器將前一個(gè)二分類器的輸出作為輸入。CLR算法則在兩兩標(biāo)簽之間構(gòu)造二分類器。LP直接將多標(biāo)簽分類轉(zhuǎn)換成了多類別分類問題。
(2)算法適應(yīng)類:即修改分類算法適應(yīng)多標(biāo)簽分類問題。典型算法有基于KNN 算法的ML-KNN[19]、基于決策樹算法的ML-DT[20]、基于SVM算法的Rank-SVM[21],以及利用二值交叉熵?fù)p失函數(shù)(Binary Cross-Entropy,BCE)代替交叉熵?fù)p失函數(shù)的神經(jīng)網(wǎng)絡(luò)類算法[1]。
3 基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法
本文提出了一種基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法DMLTC-LSS。DMLTC-LSS 算法的整體流程如圖2所示。
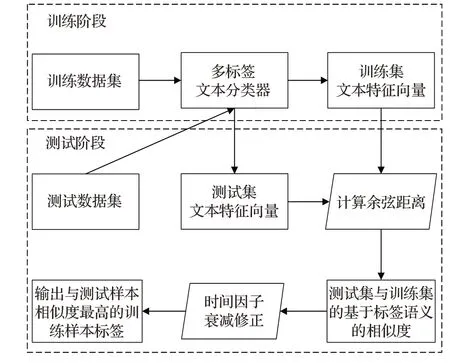
圖2 DMLTC-LSS算法流程


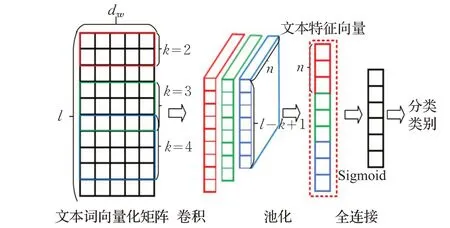
圖3 基于卷積神經(jīng)網(wǎng)絡(luò)的多標(biāo)簽文本分類器示意圖

加上時(shí)間衰減因子修正的相似度函數(shù)為(*表示逐元素相乘):

4 實(shí)驗(yàn)結(jié)果與分析
4.1 實(shí)驗(yàn)數(shù)據(jù)集
(1)Reuters-21578新聞數(shù)據(jù)集
本文使用Reuters-21578 新聞數(shù)據(jù)集構(gòu)造了用戶感興趣主題隨時(shí)間變化的數(shù)據(jù)集。具體構(gòu)造方式為:首先篩選出樣本數(shù)目最多的10 個(gè)標(biāo)簽,并按照時(shí)間順序排序;然后創(chuàng)建了5 個(gè)用戶(A~E),3 種感興趣主題關(guān)系,分別是{A:labels[0:3],B:labels[1:4],C:labels[2:5],D:
labels[3:6],E:labels[7:9]},A:labels[0:2],B:labels[3:3],C:labels[2:4],D:labels[3:5],E:labels[6:9]},{A:labels[2:4],B:labels[4:5],C:labels[5:6],D:labels[4:7],E:labels[5:9]},其中A:labels[0:3]表示用戶A感興趣0,1,2,3主題,其余類似;最后按照時(shí)間順序每2 000個(gè)樣本改變一次感興趣主題關(guān)系,3種感興趣主題關(guān)系循環(huán)使用。本文按照文獻(xiàn)[22]的方式劃分了訓(xùn)練集和測(cè)試集,并從訓(xùn)練集中選取按照時(shí)間排序的后10%的樣本作為驗(yàn)證集。此外,本文公將在Reuters-21578數(shù)據(jù)集上的實(shí)驗(yàn)代碼公布在了Github上(https://github.com/JiaqiYao/dynamic_multi_label)。
(2)中文郵件數(shù)據(jù)集
本文采集了某公司內(nèi)部1年的74 000份郵件,抽取郵件中的郵件內(nèi)容(content)、接收人列表(receivers)和發(fā)送時(shí)間(post_time)要素,構(gòu)造成(content,receivers,post_time)三元組,并按照發(fā)送時(shí)間順序排序,選取1~60 000 份郵件為訓(xùn)練集,60 001~67 000 份郵件為驗(yàn)證集,67 001~74 000 份郵件為測(cè)試集。不同的收件人的總數(shù)為232個(gè)。
4.2 對(duì)比模型與實(shí)驗(yàn)配置
本文選取了基于卷積神經(jīng)網(wǎng)絡(luò)的XML-CNN[9]、基于循環(huán)神經(jīng)網(wǎng)絡(luò)的HAN[10],并改造BERT[14]使其適用于多標(biāo)簽文本分類。同時(shí),本文構(gòu)造了基于TF-IDF 特征向量的最近鄰算法,用以驗(yàn)證基于內(nèi)容相似的算法的性能。下面分別介紹上述各個(gè)算法以及本文提出的DMLTC-LSS算法的詳細(xì)實(shí)驗(yàn)配置。
對(duì)于Reuters-21578 數(shù)據(jù)集,本文使用Google 預(yù)訓(xùn)練的詞向量[6]。而采集的中文郵件數(shù)據(jù)集,本文首先應(yīng)用jieba將采集到的郵件內(nèi)容分詞,然后采用word2vec[4-6]的Skip-gram 模型預(yù)訓(xùn)練詞嵌入模型WE∈RNw×dw,Nw為語料集的詞的個(gè)數(shù),dw為詞嵌入向量的維度,本文設(shè)定為300。此外,本文所有基于神經(jīng)網(wǎng)絡(luò)模型的損失函數(shù)均為二值交叉熵(Binary Cross Entropy,BCE)損失函數(shù),并采用Adam[23]優(yōu)化算法,學(xué)習(xí)速率通過驗(yàn)證集上的性能確定。
(1)基于卷積神經(jīng)網(wǎng)絡(luò)的XML-CNN
XML-CNN 采用卷積神經(jīng)網(wǎng)絡(luò)作為基本架構(gòu)。本文采用了尺寸為3×300、4×300、5×300的卷積核,每個(gè)卷積核的個(gè)數(shù)為256,激勵(lì)函數(shù)未Relu 函數(shù),應(yīng)用最大池化函數(shù),在倒數(shù)第二層加入了隨機(jī)失活層(Dropout)減少模型的過擬合,提高模型的性能,隨機(jī)失活率為0.5。
(2)基于循環(huán)神經(jīng)網(wǎng)絡(luò)的HAN
HAN(Hierarchical Attention Network)模型為層次注意力模型,分別在詞級(jí)(word-level)和句子級(jí)(sentencelevel)應(yīng)用自注意力機(jī)制。本文僅應(yīng)用了詞級(jí)的自注意力機(jī)制,采用GRU 的循環(huán)神經(jīng)網(wǎng)絡(luò)模型,每個(gè)GRU 中含有128個(gè)單位,激勵(lì)函數(shù)為雙曲正切函數(shù)(tanh),在循環(huán)神經(jīng)網(wǎng)絡(luò)層之后加入隨機(jī)失活層,隨機(jī)失活率為0.5。
(3)BERT模型
本文使用了預(yù)訓(xùn)練的BERT 模型,英文模型為uncased_L-12_H-768_A-12,中文模型為chinese_L-12_H-768_A-12[14]。這兩個(gè)模型均由12層Transformer模塊構(gòu)成,每個(gè)Transformer 模塊由768 個(gè)隱層單元和12 個(gè)多線頭(multi-heads)組成,總共約110M個(gè)參數(shù)。
(4)基于TF-IDF的最近鄰算法
首先在jieba 分詞的基礎(chǔ)上構(gòu)建文本的TF-IDF 特征,本文沒有使用停用詞表,而是將文檔頻率超過0.9的詞濾除掉,然后基于向量的余弦相似度應(yīng)用最近鄰算法分類待分類的文檔。
(5)DMLTC-LSS
DMLTC-LSS 算法建立在XML-CNN 模型的基礎(chǔ)上,在訓(xùn)練好XML-CNN 模型后,按照第3 章的描述運(yùn)行DMLTC-LSS算法。DMLTC-LSS算法的超參數(shù)衰減因子η的具體數(shù)值通過驗(yàn)證集上的性能確定。同時(shí),本文對(duì)比了基于HAN 和BERT 的最近鄰算法,其中HAN也取倒數(shù)第二層為文本的特征向量,BERT 則取原模型中的[CLS]對(duì)應(yīng)的向量。
4.3 結(jié)果與分析
本文采用基于樣本平均的精確率(Precision)、召回率(Recall)和F1指標(biāo)度量算法的性能。令yi表示一個(gè)樣本xi的標(biāo)簽集合,f(xi)表示分類器預(yù)測(cè)的標(biāo)簽集合,N表示總共的樣本個(gè)數(shù)。
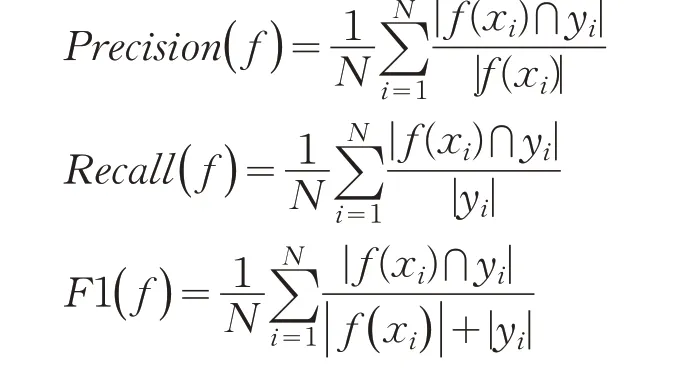
實(shí)驗(yàn)結(jié)果如表1和表2所示(其中*表示采用了時(shí)間衰減因子,HAN#*和BERT#*分別表示基于HAN 和BERT的最近鄰算法)。
從實(shí)驗(yàn)結(jié)果中可以看出:
(1)基于TF-IDF 的最近鄰算法是一種基于內(nèi)容相似的算法,在精確率、召回率和F1 性能指標(biāo)上表現(xiàn)均不好。
(2)DMLTC-LSS*算法,即基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法在兩個(gè)數(shù)據(jù)集上均取得了最優(yōu)的結(jié)果,充分說明了本文提出的算法的有效性。
(3)DMLTC-LSS*相較于DMLTC-LSS 的性能更優(yōu),表明加入時(shí)間衰減因子使得較新的樣本具有相對(duì)更近的距離,對(duì)動(dòng)態(tài)多標(biāo)簽文本分類的必要性。
(4)本文對(duì)比了基于HAN 和BERT 的最近鄰算法,并且也加上了時(shí)間衰減因子,實(shí)驗(yàn)結(jié)果表明相對(duì)于原始的HAN 和BERT 而言,性能有所提升,但是沒有超過DMLTC-LSS*算法。動(dòng)態(tài)多標(biāo)簽文本分類數(shù)據(jù)集的概率分布p(x,y)隨著時(shí)間發(fā)生變化,因而對(duì)于HAN 和BERT 等具有較大模型容納能力的模型而言,容易過擬合,從而影響其倒數(shù)第二層提取含有標(biāo)簽語義信息的特征能力。
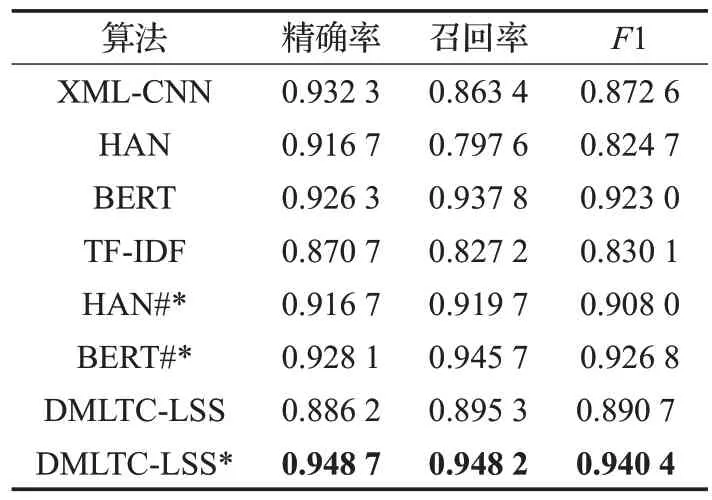
表1 Reuters-21578實(shí)驗(yàn)結(jié)果
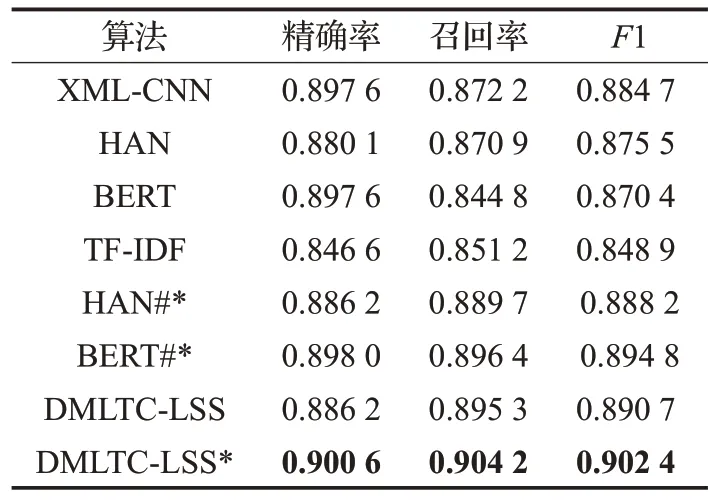
表2 中文郵件實(shí)驗(yàn)結(jié)果
5 結(jié)束語
本文提出了一種基于標(biāo)簽語義相似的動(dòng)態(tài)多標(biāo)簽文本分類算法(DMLTC-LSS),主要用于解決標(biāo)簽隨著時(shí)間的進(jìn)展不斷發(fā)生變化的多標(biāo)簽文本分類問題。DMLTC-LSS算法利用傳統(tǒng)多標(biāo)簽文本分類提取文本的特征向量,該特征向量是在標(biāo)簽監(jiān)督下訓(xùn)練得到,因而內(nèi)涵標(biāo)簽語義信息,從而使得基于該特征向量的相似度反映了標(biāo)簽語義的相似度。在標(biāo)簽語義相似度的基礎(chǔ)上,本文加上了時(shí)間衰減因子的修正,進(jìn)一步提升了算法的性能。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
