基于PCA和CBR的醫學診斷專家系統
2011-03-20 03:50:14侯珊珊
電子科技 2011年7期
侯珊珊
(西安電子科技大學計算機學院,陜西西安710071)
基于案例推理是人工智能領域中新崛起的一種推理技術,它克服了傳統專家系統出現的知識獲取瓶頸等問題,能夠從新案例中獲取知識,反映專家的思維過程,與醫學診斷具有較高的相似性。因此,在醫學診斷中,案例推理是一種有效的思維方式。但在實際應用中,醫學案例庫一般由大量的符號屬性構成,對所有這些屬性進行分析,會增加計算量和分析問題的復雜性,而主成份分析是一種典型的數據降維方法,文中對主成分分析和案例推理在醫學診斷中的應用進行了研究。
1 相關理論
1.1 案例推理
案例推理是基于人的認知過程的,其核心思想是:專家在進行某個問題的求解時,往往把以前使用過的與該問題類似的案例聯系起來,運用以前解決類似案例的經驗、知識和方法,來解決當前問題。其推理過程分為4部分[1]:案例檢索(Retrieve)、案例重用(Reuse)、案例修正(Revise)、案例保存(Retain),簡稱4R過程。具體步驟如下:
(1)將新問題作為目標案例,輸入新問題的特征或屬性。
(2)檢索案例庫,根據問題的要求,在案例庫中找出與目標案例最為相似的案例,其關鍵是找出對新問題的解決有最大潛在啟發價值的舊案例。
(3)判斷檢索到的案例的信息和知識是否符合需求,若符合,則復用這些信息和知識,否則根據修正規則來修改檢索到的舊案例,對新案例進行計算求解,為成功解決問題提供參考。
(4)將有利用價值的新案例存儲到案例庫中,并對案例推理系統的案例庫做相應調整,以完成案例推理的學習功能。
1.2 主成分分析
主成分分析(PrincipalComponentAnalysis,PCA),是數據降維技術的典型算法[2],它通過構造各因子的協方差矩陣,對協方差矩陣的特征進行分析,把原始數據投影到包含了大部分數據信息的線性子空間中,達到數據降維的目的,結果通常用得分矩陣和載荷矩陣表示。它的優點在于計算過程簡單、數據信息丟失少。主成分分析的得分矩陣和載荷矩陣一旦計算出來,新病人的數據就可以被映射到一個新的k維空間,然后進行推理,得出診斷結果。
1.3 RS-PCA算法
RS-PCA(Regular Simplex-PCA)算法[3]是一種無監督的通過正則單行表達式來計算文本型變量之間協方差的方法,當空間維數>2時,它是一個正三角形的延伸。簡單正則表達式中,頂點之間的距離相等,其中每個頂點是指不同屬性的文本數據,如果變量的空間維數>3,那么該規則的表示是一個四面體。
根據文獻[4]的定義,RS算法是基于數學上的正則單行概念的。一個正則單行與一個在n維空間的三角形類似,而且它各個頂點之間的距離相等。假設文本類型的變量,這個變量的取值有kj種,按照RS算法,用正則單行中的一個頂點表示變量的取值,為了表示這些頂點,定義vn(rk)作為n-1個頂點中第k個頂點的位置。
現在假設有變量x1,x2,…,xJ,對于案例a,xi有xia種取值,據此,可以用xia來代替vki(xia),xia表示實例a在變量xi上的取值,然后對每個變量都用這種方法進行處理,將這些組織起來就形成一個如式(1)所示的向量x(a)

再對每一個事例重復這個過程,就可以得到一個N×M的矩陣,其中,N是事例的個數,M是所有變量不同取值個數的總和,這個矩陣是正則單行頂點的列表(List of Regular Simplex Vertices,LRSV)。
根據已構造的LRSV矩陣,可以計算它的協方差矩陣A,協方差矩陣的計算如下

再則,計算LRSV矩陣的協方差矩陣
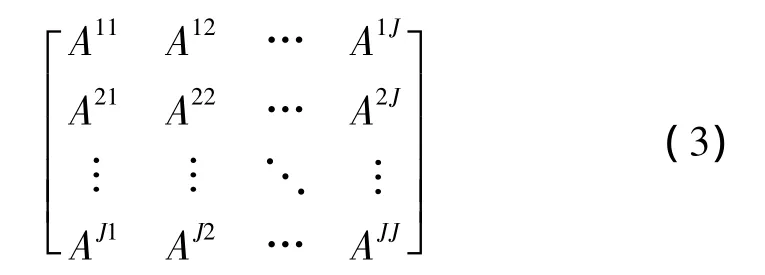
其中,Aij表示第i列和第j列的協方差。
計算出協方差矩陣,下面就可用主成分分析的方法進行下一步分析。主成分分析是將n維的數據映射到一個低維的子空間中,對數據進行降維處理,降低計算復雜度,同時也保留了原變量的絕大部分信息,并且各個主成分之間是不相關的,是一種比較可靠的數據降維方法,步驟為:
第一步,計算出整個數據集的均值向量和協方差矩陣。
第二步,計算出特征向量和特征值,然后將特征值按降序排列。
第三步,選取前k個特征值所對應的k個特征向量。選取了特征向量,就可以計算出每一個事例的得分,從而得到得分矩陣。

其中,X為LRSV矩陣;P為特征向量組成的矩陣,也稱為載荷矩陣。
2 醫學專家系統設計
醫學案例庫一般由大量屬性構成,這些屬性大部分是文本型數據,為便于數據的分析和處理,需要對其進行數字化處理,對所有的這些屬性進行分析會增大計算量和分析問題的復雜性,因此,需要找到一種不丟失信息的屬性約簡方法來減少工作量。
專家系統首先對醫學案例庫的符號屬性進行數字化轉換,然后利用主成分分析進行特征提取,將案例庫映射到特征空間,再根據案例推理的方法進行輔助診斷。針對RS的數字化轉換方法沒有考慮各屬性特征的重要性不同,提出了基于權重的WRS數值化方法,提高了系統的準確度;并對案例檢索中常用的最近鄰策略進行了改進,提出了基于最相似匹配原理的最近鄰比值檢索方法,提高檢索效率,降低計算復雜度。
2.1 基于權重WRS數值化方法
基于權重WRS數值化方法,考慮到每個屬性的值對結果的影響不同,根據其貢獻大小,賦予不同的數值,對貢獻大的值賦一個較大的數,貢獻小的就賦一個較小的數值,而不是簡單的賦值0或1,使得結果更加準確可靠。如何計算每個屬性的不同取值對結果貢獻的大小,可以由專家根據經驗人為確定,也可以由專家系統自動學習得到。前者易于實現且方便,但不可避免地要受專家主觀意識的影響。為使權值更加客觀地反映屬性值對診斷結果的影響,采用一種基于概率統計的權值計算方法,從案例庫中學習得到權值。根據概率統計理論的觀點,如果屬性值s在所有結果是A的數據集U中出現的頻率高,那么屬性值s的出現對確定結果是A就重要,否則,如果頻率低的話,則屬性值s對確定結果是A的貢獻就小。計算出了權值,就可以根據權值的大小,在編碼過程中賦予不同的數值,但是這些不同的數值如何選取,采用的方法是看該屬性有多少個不同的取值,最大的取值就是這個值,其他的按權值的大小依次減少。根據WRS方法得到編碼,再按照PCA的步驟進行數據降維。
2.2 最近鄰比值檢索方法
為加快檢索速度,提出基于最相似匹配原理的最近鄰比值檢索方法。首先對屬性的權重進行排序,根據目標案例的屬性中權重最大的屬性,從數據庫中取出一批合格的記錄放到數據存儲中,然后根據目標案例屬性中權重次大的屬性,對上述數據存儲進行一次過濾,最后對目標案例和數據存儲中的記錄計算相似度,這樣就不用計算目標案例和案例庫中每個案例的相似度,只對一些接近的記錄進行相似度計算。文中提出利用比值法進行相似度計算,即通過計算新案例和源案例之間的比值來選取最相似的案例。

比值越接近1,說明新案例與該案例的相似度越大。通過使用這種檢索方法,大大提高了案例的檢索效率,降低了計算復雜度。
3 系統測試
為驗證系統的有效性,需要進行測試。測試數據[5],從案例庫中隨機抽取10個不同的案例作為測試案例,對這些案例的測試如下:(1)第一個案例開始測試。(2)首先將這個案例從案例庫中刪除,作為要診斷的新案例。(3)在剩余的案例庫中進行檢索。(4)重復步驟(2)和(3),直到10個測試案例都被測試完。

表1 測試結果
測試證明,本系統具有較好的可靠性。
4 結束語
將PCA和CB R結合構造了一個醫學輔助專家系統,對RS的數值轉換方法和最近鄰檢索策略進行了改進,提高了系統的準確度和檢索效率。實驗證明,該系統的推理機能夠有效模擬醫生的診斷思維,可以作為醫生診斷疾病的一種輔助工具。
[1] 章曙光,錢權,方瑾.范例推理中基于時序的范例匹配方法模型[J].小型微型計算機系統,2003,24(4):640-642.
[2] YAN LI,SIMON C K,SANKAR K PAL.Combining feature reduction and case selection in building CBR classifiers[C].IEEE Transactions Knowledge and Data Engineering,2006:415-428.
[3] CARLES P,DANI C,BEATRIZ L.Diagnosing patients with a combination of principal component analysis and case-based reasoning[J].International Journal of Hybrid Intelligent Systems,2009,6(2):111-122.
[4] NIITSUMA H,OKADA T.Covariance and PCA for categorical variables[C].Hanoi,Vietnam:Proceedings of the 9th Pacific-Asia Conference,PAKDD 2005,Advances in Knowledge DiscoveryandDataMining,LNAI,3518,Spring-Verlag,2005:523-528.
[5] 聶艷召.基于案例推理的羊病診斷專家系統研究與實現[D].西安:西北農林科技大學,2007.
猜你喜歡
少先隊活動(2021年2期)2021-03-29 05:40:48
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
電子制作(2018年18期)2018-11-14 01:48:24
中國公路(2017年7期)2017-07-24 13:56:38
山東工業技術(2016年15期)2016-12-01 05:31:22
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛生(2015年4期)2015-11-08 11:16:06
Coco薇(2015年1期)2015-08-13 02:47:34
