網頁去重的改進算法
2011-02-28 05:10:32劉觀寧張鈺輝
網絡安全與數據管理 2011年12期
王 靜 ,劉觀寧 ,張鈺輝
(1.西安電子科技大學 計算機學院,陜西 西安 710071;2.安徽省技術創新服務中心,安徽 合肥 230001)
隨著互聯網的高速發展,Web已經成為最大的信息來源。但是如何獲取這些Web信息為我所用則是大家面臨的共同問題。網頁去重是Web網頁信息處理的重要環節,只有在對網頁的去重基礎上才可以準確處理網頁中的信息。本文介紹網頁的去重算法。
提取出來的網頁,有些內容可能很相似,對于這些內容相似的網頁沒必要保存。針對系統中的人才招聘網頁更是必要:一個公司的招聘信息很可能會在數十家招聘網站以及自己公司主頁同時發布,所以有必要對這些網頁去重。
1 網頁的特征表示
詞、詞組和短語是組成文檔的基本元素,在不同內容的文檔中各詞條出現頻率有一定的規律性,不同的特征詞條可以區分不同內容的文本。因此可以抽取一些特征詞條構成特征矢量,在VSM[1]模型中把 t1,t2,…,tn看成一個N維的坐標系 w1(d),w2(d),…,wn(d)為相應的坐標值,因而文本d被看成是N維空間中的一個規范化特征矢量:V(d)=(t1,w1(d);…;ti,wi(d);…;tn,wn(d);)
對于網頁,ti就表示特征詞條,wi(d)就是文本d中ti的權值。用這個特征矢量來表示網頁文本。在網頁表示中,對任一特征而言有兩個因素影響特征的權值。一是詞在HTML文檔中出現的詞頻,另一個是該詞在該文檔中出現的位置。詞頻指的是某一詞條在文檔中出現的頻率,頻率越高 (當然不包括那些停用詞)則說明該詞越重要,越能代表該網頁的內容。對于網頁的主題包含在之間的詞組比在之間的詞組更具有代表性。因此本文提出了一種把該詞出現的頻率以及該詞出現的位置相結合的權重計算方法,能夠更有效地表示網頁。公式如下:


這里α=2,α=3,α=4和α=6都是經過實驗得到的。實驗結果也證明了此改進算法對網頁分類正確率的有效性。
2 網頁的特征提取
使用VSM模型表示法時,表示文檔的特征向量的維數會達到成百上千。同時,具有代表性的特征以及詞匯特征也會很大,并且是冗余的。這種未經處理的文本矢量會給后繼的處理工作帶來巨大的計算開銷。特征提取主要用于排除那些被認為無關或關聯性不大的特征。基于VSM常用的特征項提取算法有:詞頻、信息增益、互信息量[2]及X2統計量[3]等。在中文文本分類中使用較多的是互信息量和X2統計量。
(1)互信息量
互信息是信息論中的概念,它用于度量一個消息中兩個信號之間的相互依賴程度。在特征選擇領域中人們經常利用它來計算特征t與類別c之間的依賴程度,將特征t與各個類的互信息融合起來作為特征的權重。特征t與第i類的互信息計算公式如下(兩個公式等價):

其中:tk表示任意特征項 (特征詞);ci表示任意類別;g為訓練集中所有文本數;P(tk,ci)為tk和ci同時出現的概率(即對于任意一篇文章X,含有特征項tk且文章X屬于類別 ci的概率);P(tk)為文章中出現特征項 tk的概率;P(ci)為文章屬于類別ci的概率,類似地不難理解
(3)聯合特征提取方法
雖然X2統計量法是目前常用的特征提取方法之一,但該方法仍存在一些缺點,如它提高了在指定類中出現少而在其他類中出現較高的特征的權重以及降低了低頻詞的權重等。根據公式(3)~(5),對于指定類中出現頻率低而其他類中出現頻率高的詞語,當P(t,ci)→0,而 P(t)和 P(ci)均不趨向于零,則 P(t,ci)/(P(t)P(ci))→0,于是I(t,c)將趨向于負無窮,故這些詞語會被過濾掉。根據式(6),對于有相同 logPr(t|c)的詞語來說,低頻詞的權重將更高,即在多類中普遍出現的高頻詞的權重將比只在特定類中出現的低頻詞的權重低。這樣就很好地解決了上述問題,所以本文提出一種聯合特征提取的方法,該方法綜合了X2統計量法和互信息量法,可以獲得較好的結果。該方法可以描述為:

其中E1(t,c)是使用X2統計量法得到的特征權重;E2(t,c)為使用互信息量法得到的特征權重。
3 SOM神經網絡算法
3.1 向量歸一化
向量的歸一化是對輸入向量進行預處理的第一步。其目的是把所有不同長短和方向的向量變成方向不變、長度為1的單位向量。設:
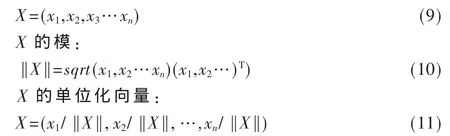
在網絡訓練過程開始時,定義獲勝節點的鄰域節點是為了能使二維輸出平面上相鄰輸出節點對相近的輸入模式類做出特別反應。假設本次獲勝節點為Nj,它在t時刻的鄰域節點用 NEj表示,NEj(t)是包含以 Nj中心而距離不超過某一半徑的所有節點。隨著訓練過程的進行,NEj(t)的半徑逐漸減小,最后只包含獲勝節點 Nj本身,也就是說在訓練的起始階段不僅對獲勝節點做權值調整,而且也對其較大范圍內的幾何鄰節點做相應的調整,隨著訓練過程的繼續進行,與輸出節點相連的權向量也越來越接近其代表的模式類。這時,在對獲勝節點的權值進行比較細微的調整時,只對其幾何鄰節點比較近的節點進行相應的調整,直到最后只對獲勝節點本身做細微的調整。在訓練過程結束后,幾何上相近的輸出節點所連接的權向量既有聯系又有區別,這樣,保證了對某一類輸入模式獲勝節點能夠做出最大“響應”,而相鄰節點做出“較大”響應。幾何上相鄰節點代表特征上相近的模式類別。
自組織特征映射學習過程包括描述最佳匹配神經元的選擇和描述權矢量的自適應變化過程兩部分。SOM輸出層通常由兩維m×m的網格節點組成,從輸入向量到網絡輸出層的每個節點j的權值向量定義為w,w和xi的維數是相同的,設為d,影射節點的數量從數十個到數千個決定SOM正確性和概化能力。
3.2 Kohonen網絡訓練算法[4~5]
其算法步聚如下:
(1)權連接初始化:初始化輸出層節點j的權值矢量wij時可選隨機值,初始值通常要選擇小一點。初始化學習率和領域函數時要盡量大一些,對連接輸入神經元和輸出神經元之間的權系數設定為小的隨機數a,一般有0 (2)網絡輸入模式為: (3)在SOM迭代訓練的每一步,從輸入數據集中隨機地選擇文本向量xi屬于實數集,計算xi和som輸出層所有節點j的權值向量wij的距離,最匹配的點用d表示,權值向量用wij表示,它是輸出層節點中最接近xi的。 (5)在每一步學習中CN的神經元自適應變化而CN外的神經元保持不變,調整輸出節點所連接的權值以及幾何鄰域內節點所連權值為: 式中 η(t)為標量自適應增益,0<η(t)<1,η(t)是單調降函數,它可以是線性指數的或者是與其成反比的形式等,通常選擇η(t)=0.9(1-t/1 000),它與 N(t)都是經驗函數。 (6)若還有輸入樣本數據則t=t+1轉到步驟(2)。 網絡輸出與權值調整競爭學習算法規定,獲勝神經元輸出為1,其余輸出為零。只有獲勝神經元才有權調整其權向量j×w,調整后權向量為: 其中,α∈(0,1]為學習率,一般其值隨著學習的進展而減小。可以看出,當 j≠j*時,對應神經元的權值得不到調整,其實質是“勝者”對它們進行了抑制,不允許它們興奮。另外,調整后得到的新向量不再是單位向量,因此需要對調整后的向量重新歸一化。步驟(3)完成后回到步驟(1)繼續訓練,直到學習率α衰減到0。 采用以上介紹的算法,對一批數量在50~100之間的網頁集合進行去重處理,集合中包含了一與此內容完全相同或部分相同的網頁,將實驗結果與人工判別的結果進了比較,發現重復網頁的正確率達到95%以上,出現錯誤的判斷的是由于網頁轉載時出現錯碼等現象,有的是兩個重復網頁的段落排列差異太大。測試結果如圖1所示。 本文將SOM的思想和方法引入中文Web文檔的聚類問題.探索向用戶提供高質量的網頁信息具有很強的理論意義和實際價值。但是,這種方法的不足之處是當網絡的連接過多、節點數目龐大時其計算量大,需要較長的學習時間。所以對于上述問題,筆者正在研究通過網絡剪枝技術,在不增加聚類錯誤的前提下,剪去多余的連接和節點,降低特征向量空間的維數從而減少計算工作量。 [1]LINSKER R.An application of the principle of maximum information preservation to linear systems[Z].Adv.Neural Inform.Process Systems,1989,1. [2]JUTTEN C,HERAULT J.Blind separation of sources,Part 1:An adaptive algorithm based on neuromimetic architecture[J].Signal Processing,1991,24:10. [3]COMMON P.Independent component analysis,a new concept[J].Signal Processing,1994,36:287-314. [4]TONAZZINI A,BEDINI L,KURUOGLU E E.Blind separation of auto-correlated images from noisy images using mrf models,.in 4th Int.Symp.on ICA and Blind Source Separation,Nara,Japan,2003. [5]SHULMAN D,HERVE J Y.Regularization of discontinuous flow fields.in Proc.Workshop on Visual Motion,1989:81.86. [6]BOUMAN C,SAUER K.A generalised gaussian image model for edge-preserving MAP estimation,.IEEE Trans.Image Processing,vol.2,pp.296-310,1993.2704.


4 實驗結果

猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
甘肅教育(2020年8期)2020-06-11 06:10:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
