AI-ONETM芯片——生物啟發智能
2010-03-27 06:56:06許廷濤
電腦與電信 2010年12期
特約通訊員 許廷濤
人類本身奧妙的生物機能為新技術的開發帶來啟示。生物啟示意味著我們可以參考生物的一些功能,并將其應用到智能計算機系統中。
生物啟發智能是規則概括的基本概念,這些規則有助于提升信息處理的智能。對于智能機器來說,獲取知識和技能是智能決策的基礎,就如人類學習一樣。
生物啟發智能的開發者——semantic system ag(語義系統公司)的工程師們已經開發出第一代的能像生物大腦一樣思考的電腦芯片AI-ONE。在計算機信息處理方面,這是第一次能夠在電腦芯片中運行復雜想法與分析過程,從而得到與人類思考獲取相同的結果。全球的芯片和處理器設計專家與科學家都清楚地表明:現階段的芯片技術需要一個進化的步驟。它必須是一個真正的進化步驟,而不是僅僅逐步增加更多的內核。在未來,開發真正的智能系統需要這些新型的、增強的數據處理技術。如果我們首先解決在核心處理中神經數據的處理問題,本體、分類法、語義和符號的概念就可以突破。
我們需要更加靈活的數據處理技術,并且主要是智能數據處理技術,如邏輯運算、神經編碼、模糊邏輯等等。破解神經編碼即是我們必須理解神經細胞在生物大腦中如何發揮功能與作出反應,以及其原因。如果理解這些,我們就可以為生物啟發智能系統建立基礎。
通過開發一個神經數據處理環境,語義系統公司的工程師們已經為研發生物啟發智能計算機信息處理技術建立了基礎,這種神經數據處理環境可以在標準計算機上實施,就如運行軟件開發工具一樣。語義系統公司提供了神經數據處理環境,在這個環境中,我們可以對本體、分類、關聯或語義應用進行操作,從而獲得更好的功能。
AI-ONETM芯片
AI-ONE主要是模擬大腦復雜的圖案識別功能的能力,最真實地在計算系統中重現這種能力。基于對大腦皮層各元素的功能和途徑的理解,該芯片能夠像人類大腦一樣,處理相同復雜程度的問題和分析。
AI-ONE與傳統芯片相比的先進之處在于它解決了“過度學習”的難題。在傳統神經網絡中,若超過擬合數據的范圍,系統的概括能力將會降低。AI-ONE則集合了神經計算與常規計算的優點。它能夠識別圖案、概念、理解布爾邏輯、儲存數據。而且,AI-ONE也解決了資源與速度的難題,它可以實現集群功能,這樣就能處理大量的數據。
芯片的訓練和學習
與其它生物系統一樣,AI-ONE需要學習和訓練。因為在與用戶的交流中,AI-ONE需要學習基本的知識、常識,甚至目標。從這點上看,這不再是技術上的問題,而是如何給AI-ONE輸入正確信息的問題,讓芯片能構建必需的知識去完成所分配的任務。但是,它的訓練比人類的訓練簡單,AI-ONE可以通過計算機或自動輸送裝置進行訓練。
符號數據處理
新的芯片技術促進了全息語義環境中的數據儲存和數據處理。這樣就可以識別各種類型數據的內在信息模式。根據數據中的語法、語義和語用,它能夠識別符號關聯模式。
AI-ONE可識別各種數據的信息模式與概念,并能夠關聯與處理這些信息模式與概念。該系統自主地或根據一組規則作出決定;擁有推斷缺失信息的能力,并能完成預測、聯系、比較、評價和分析。可以說,AI-ONE是智能計算機的核心,也是使智能計算機得以發展的驅動力。
思考的過程
通過上一篇文章的介紹我們已經對“自主智能”的概念有一定的認識,AI-ONE是具有“自主智能”的芯片,基于ai-one的系統不僅能對各種查詢作出反應,而且通過先進的自組織算法,系統能夠自主作出查詢。它能夠自主、快速地在大量的數據中找到相關的信息,并且能夠根據找到的信息更改決定。例如,系統可以部署在生物統計學中,分析復雜的模式和圖像;在數據處理中,系統能夠自動識別文本的語義相關性,分配適當的進程,作出合理的決定;還能使計算機學習發言,用人類的語言與人類交流。
智能系統的關鍵
原則上,任何種類數據的處理,如圖像、文本、數據值等靜態或動態的數據,可以分為以下三步:
1.獲取數據——掃描,記錄,輸入(識別與輸入)
2.分析/理解——決策與分類的智能
3.匹配/處理——匹配,后期處理
第一步與第三步已基本解決。主要的難題的是第二步。第一步和第三步是數據獲取和數據匹配,不少系統已經能夠在不同條件下,獲取不同來源的數據并且匹配這些數據。當然,這些系統仍然需要改善。然而,對第一步和第三步的改善并不能使其成為一個智能系統。
第二步是構建智能系統的關鍵,它只能通過擁有強大思考能力的軟件來完成。這是一種創造性地分析和改進自身性能的能力,朝著更加優化的方向去完成自己的目標。第二步也有眾多的解決方案可以使用。然而,這些解決方案仍然需要根據每個特定的任務而被訓練。此外,這些系統需要復雜的和廣泛的環境模型(本體,分類,模式標本等)。因此,這些解決方案不能實現普及化,不能通用于各種任務。
AI-ONE的智能體現主要是基于生物啟發智能與機器認知這個基本概念的。這個概念能促進計算機系統的總體智能的發展。基于AI-ONE的計算機系統無需編寫程序去完成新任務,它僅僅是接受人類的指令,通過自學和訓練,以廣義和抽象的形式去吸收知識,使系統能夠解決類似的任務。該系統利用相關的背景知識,因應各種情況而作出相應的調整。而且,AI-ONE芯片能夠安排何時完成學習并中止學習,這樣就解決了過度學習和過度適應的問題。
圖像識別實例
以下通過一組例子來分析AI-ONE芯片的學習過程。圖1中是一組鞋印的圖像。其清晰程度有很大差異,但其形狀的整體分布仍然是保持穩定的。
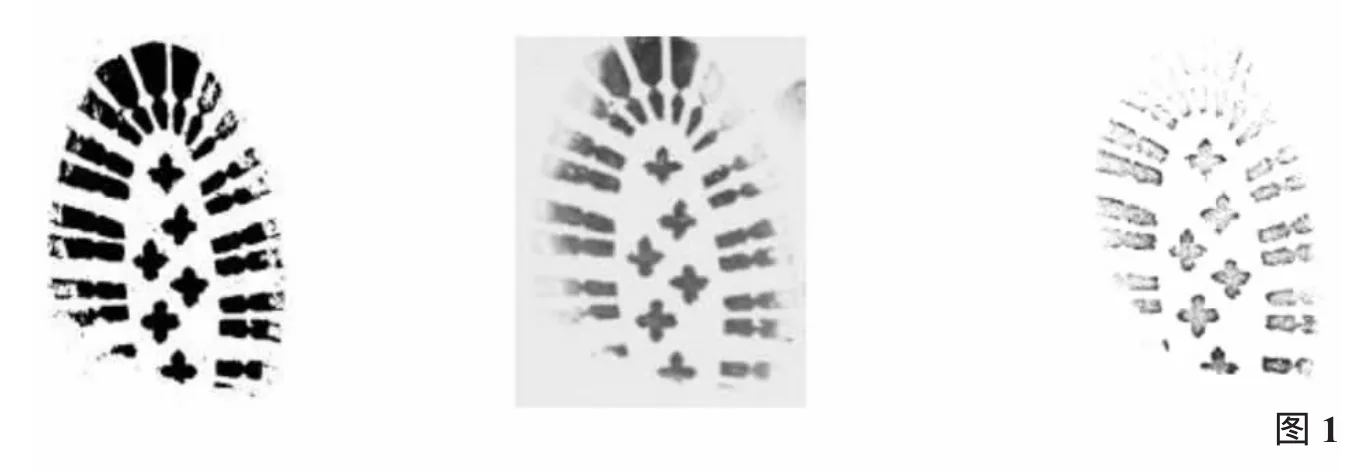

1.對單一形狀概念的理解
以上的鞋圖案的具體形狀的編碼揭示了一個問題:由于原始圖像的不清晰,數字視網膜會把這種形狀編碼成不同的物體。很多情況下,原始圖像甚至只留下部分形狀的痕跡。AI-ONE能夠自發地學習形狀的概念,并在概念方面進行訓練,試圖通過還原形狀以進行匹對。在匹配形狀時,它以降序形式呈現各種可能的配對。
2.理解形狀之間的關系與關聯的概念
對于圖像匹配來說,識別和理解各種形狀,甚至各組形狀之間的關系以及關聯的概念是不可缺少的。如以上所展示的圖像,形狀可能有所不同,但是,各種形狀之間的關系與它們的總體分布是保持穩定的。通過遞歸地比較每個形狀與每組形狀,系統可以找到匹配的圖像。如圖2所示。
理解各種尺寸的形狀的概念,然后適當地推廣這方面的知識是生物智能的關鍵。根據一個特定的知識基礎,基于這種技術的計算機系統可以自主地作出決策。當然,管理者可以設定規則和限制,使計算機只能在一個確定的權限與責任框架內作出決定。
除了單一形狀,AI-ONE還擁有對多組形狀進行學習的能力來進行圖像匹配。除此以外,按照類似的學習過程,AI-ONE還可用于分析各種語言文字,理解詞語、句子、段落、頁面以及詞語與句子之間的關系。
參考資料:www.semantic.ch
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
現代語文(2016年21期)2016-05-25 13:13:44
中國慣性技術學報(2015年1期)2015-12-19 13:12:17
大連民族大學學報(2015年2期)2015-02-27 08:28:11
