移動(dòng)機(jī)器人模糊Q-學(xué)習(xí)沿墻導(dǎo)航
2010-02-10 01:29:18徐明亮柴志雷須文波
電機(jī)與控制學(xué)報(bào) 2010年6期
徐明亮, 柴志雷, 須文波
(1.無(wú)錫城市職業(yè)技術(shù)學(xué)校 電子信息系,江蘇無(wú)錫 214063;2.江南大學(xué) 信息工程學(xué)院,江蘇無(wú)錫 214122)
0 引言
導(dǎo)航是移動(dòng)機(jī)器人的一項(xiàng)重要的功能,是移動(dòng)機(jī)器人完成其他智能行為的基礎(chǔ)。沿墻導(dǎo)航控制是指機(jī)器人在和墻保持一定距離的情況下沿墻運(yùn)動(dòng),從更一般意義上來(lái)說(shuō)實(shí)際上是機(jī)器人與物體保持一定距離并沿物體輪廓運(yùn)動(dòng)[1]。因此沿墻導(dǎo)航實(shí)際上既可以使機(jī)器人實(shí)現(xiàn)障礙物的避碰[2],也可以實(shí)現(xiàn)在未知環(huán)境的導(dǎo)航[3]。
移動(dòng)機(jī)器人的反應(yīng)式導(dǎo)航是一種直接在機(jī)器人的感知和行為之間建立映射關(guān)系的導(dǎo)航方法。它具有靈活和執(zhí)行快速的特點(diǎn)而成為移動(dòng)機(jī)器人在未知和快速變化環(huán)境中導(dǎo)航的重要方法。已有許多學(xué)者提出了不同的反應(yīng)式導(dǎo)航方法,比如文獻(xiàn)[4]采用引力勢(shì)場(chǎng)法進(jìn)行導(dǎo)航。文獻(xiàn)[5]采用基于模糊規(guī)則的反應(yīng)式導(dǎo)航控制器。這些方法通常基于具體的環(huán)境模型,需要較多的先驗(yàn)知識(shí),同時(shí)對(duì)變化的環(huán)境不具有自適應(yīng)能力。
強(qiáng)化學(xué)習(xí)能夠在沒(méi)有先驗(yàn)知識(shí)的情況下通過(guò)與環(huán)境的交互獲得由狀態(tài)到動(dòng)作的策略,因此基于強(qiáng)化學(xué)習(xí)的機(jī)器人導(dǎo)航受到眾多研究者的廣泛關(guān)注。文獻(xiàn)[6]中采用Q-學(xué)習(xí)來(lái)對(duì)模糊規(guī)則進(jìn)行調(diào)整,但模糊規(guī)則則是根據(jù)機(jī)器人的系統(tǒng)特性手工建立。文獻(xiàn)[7]也采用類(lèi)似技術(shù),其特點(diǎn)是用RBF網(wǎng)絡(luò)逼近選定的若干個(gè)離散動(dòng)作的Q-值,網(wǎng)絡(luò)權(quán)值利用Q-學(xué)習(xí)來(lái)調(diào)整。而RBF網(wǎng)絡(luò)隱層節(jié)點(diǎn)的中心和寬度卻要由樣本來(lái)確定。文獻(xiàn)[8]采用CMAC神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)了Q-值函數(shù)的逼近,該方法涉及到輸入?yún)?shù)的離散化,離散化的粒度也將影響系統(tǒng)的性能。文獻(xiàn)[9]利用FNN來(lái)逼近Q-值函數(shù)和策略函數(shù),而這些函數(shù)都是建立在若干個(gè)選定的離散動(dòng)作的基礎(chǔ)之上,使得系統(tǒng)過(guò)于復(fù)雜。文獻(xiàn)[10]是用模糊推理系統(tǒng)來(lái)逼近Q-值函數(shù),每一條規(guī)則對(duì)應(yīng)一個(gè)由若干個(gè)選定的離散動(dòng)作所構(gòu)成的向量,每一個(gè)規(guī)則的輸出動(dòng)作由規(guī)則內(nèi)部的離散動(dòng)作通過(guò)競(jìng)爭(zhēng)的方法產(chǎn)生,控制器的輸出動(dòng)作由各個(gè)規(guī)則的輸出動(dòng)作根據(jù)當(dāng)前狀態(tài)在各個(gè)規(guī)則所導(dǎo)出的狀態(tài)值進(jìn)行加權(quán)。在這些方法中,導(dǎo)航控制器輸出取決于預(yù)先選定的離散動(dòng)作。這些離散動(dòng)作的選擇影響導(dǎo)航控制器的性能,而如何選擇這些種子動(dòng)作也沒(méi)有任何先驗(yàn)知識(shí)可用。另外這些方法中的Q-學(xué)習(xí)從本質(zhì)上來(lái)說(shuō)是基于 actor-critic 方法的[11]。
為避免種子動(dòng)作的選擇,我們用模糊神經(jīng)網(wǎng)絡(luò)直接對(duì)強(qiáng)化學(xué)習(xí)中的Q-值函數(shù)進(jìn)行逼近,即網(wǎng)絡(luò)的輸入為狀態(tài)動(dòng)作對(duì),而非相關(guān)文獻(xiàn)中的狀態(tài),利用函數(shù)優(yōu)化技術(shù)產(chǎn)生控制器輸出動(dòng)作。同時(shí)在學(xué)習(xí)過(guò)程中引入網(wǎng)絡(luò)節(jié)點(diǎn)自適應(yīng)構(gòu)建和參數(shù)自適應(yīng)調(diào)整方法,減少人工干預(yù)。
1 基于模糊神經(jīng)網(wǎng)絡(luò)的Q-學(xué)習(xí)
Q-學(xué)習(xí)的主要目標(biāo)是通過(guò)與環(huán)境的交互獲得表征策略的狀態(tài)動(dòng)作對(duì)的Q-值函數(shù)。Q-學(xué)習(xí)中狀態(tài)動(dòng)作對(duì)的Q值按照下式進(jìn)行更新:

其中:st為當(dāng)前狀態(tài);at為當(dāng)前狀態(tài)下選擇執(zhí)行的動(dòng)

其中:γ為折扣因子,rt+1為學(xué)習(xí)agent在狀態(tài)st執(zhí)行動(dòng)作at后轉(zhuǎn)移到狀態(tài)st+1時(shí)所獲得的立即獎(jiǎng)賞。經(jīng)典的Q-學(xué)習(xí)是以查找表來(lái)描述離散空間狀態(tài)動(dòng)作對(duì)的值函數(shù)。對(duì)于連續(xù)空間下的Q學(xué)習(xí),直接的方法是將連續(xù)空間進(jìn)行離散化處理。而對(duì)于離散的粒度選擇,往往沒(méi)有任何先驗(yàn)知識(shí)可用。離散粒度過(guò)大將會(huì)導(dǎo)致系統(tǒng)性能下降,甚至學(xué)習(xí)不成功;過(guò)小也會(huì)使學(xué)習(xí)速度下降。為克服離散化所產(chǎn)生的弊端,研究者普遍采用具有泛化功能的神經(jīng)網(wǎng)絡(luò)或模糊推理系統(tǒng)來(lái)逼近Q值函數(shù)。
模糊神經(jīng)網(wǎng)絡(luò)是模糊推理系統(tǒng)和神經(jīng)網(wǎng)絡(luò)相結(jié)合的產(chǎn)物,它既擁有模糊推理系統(tǒng)便于知識(shí)的表達(dá)和便于在系統(tǒng)中嵌入已有知識(shí)的優(yōu)點(diǎn),也擁有神經(jīng)網(wǎng)絡(luò)的自學(xué)習(xí)自組織的特點(diǎn),因此在函數(shù)逼近中得到廣泛應(yīng)用。因此我們采用模糊神經(jīng)網(wǎng)絡(luò)來(lái)逼近Q值函數(shù)。
1.1 網(wǎng)絡(luò)結(jié)構(gòu)
用于對(duì)Q值函數(shù)進(jìn)行直接逼近的模糊神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示。第一層為輸入層,它將由狀態(tài)s和動(dòng)作a構(gòu)成的向量x=(s1,…,sm,a)T直接傳送到下一層。狀態(tài)空間s為m維,記向量x維數(shù)為n,則n=m+1。第二層為模糊化層,其中每個(gè)節(jié)點(diǎn)代表一個(gè)語(yǔ)言變量。該層的作用是計(jì)算各個(gè)分量在不同語(yǔ)言變量中的隸屬度。各個(gè)語(yǔ)言變量的隸屬度函數(shù)采用高斯函數(shù)。輸入向量第i個(gè)分量的第j個(gè)語(yǔ)言變量的隸屬度函數(shù)為作;α 為學(xué)習(xí)率;δTD為時(shí)間差分(temporal difference,TD)。一步時(shí)間差分δTD計(jì)算式為其中:μij和σij分別為該隸屬度函數(shù)的中心和寬度;J為該分量的語(yǔ)言變量的個(gè)數(shù)。


圖1 網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 The architecture of network
第三層為T(mén)-norm運(yùn)算層,該層計(jì)算每個(gè)規(guī)則的發(fā)射強(qiáng)度。第k條規(guī)則的發(fā)射強(qiáng)度為

第四層為歸一化層,對(duì)每一條規(guī)則的發(fā)射強(qiáng)度進(jìn)行歸一化處理。第k條規(guī)則的歸一化后的發(fā)射強(qiáng)度為
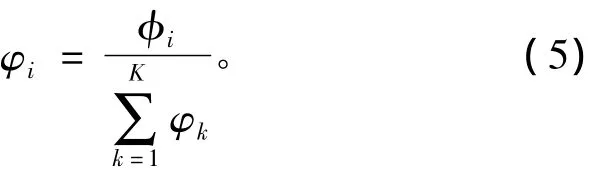

wk是第k條規(guī)則的后件。
1.2 結(jié)構(gòu)與參數(shù)學(xué)習(xí)
模糊規(guī)則可以根據(jù)樣本的ε完整性[12]來(lái)建立,但ε完整性不能充分體現(xiàn)每個(gè)分量對(duì)系統(tǒng)性能有不同影響。在文獻(xiàn)[13]中,RBF網(wǎng)絡(luò)隱層節(jié)點(diǎn)根據(jù)當(dāng)前樣本與隱層節(jié)點(diǎn)中心最小距離和誤差進(jìn)行自適應(yīng)添加。在這些方法中沒(méi)有考慮系統(tǒng)性能對(duì)輸入向量中的不同分量有不同的敏感程度。如果對(duì)這些分量不加區(qū)別,為保證系統(tǒng)性能,就要照顧到對(duì)系統(tǒng)性能敏感的分量,因此必須采用較細(xì)的分辨率,這樣將導(dǎo)致規(guī)則數(shù)或隱層節(jié)點(diǎn)數(shù)目過(guò)多。對(duì)系統(tǒng)性能敏感的分量應(yīng)采用較細(xì)的分辨率,而對(duì)系統(tǒng)性能不敏感的分量應(yīng)采用較粗的分辨率。這樣可以減少節(jié)點(diǎn)數(shù)目,減小系統(tǒng)計(jì)算量,加快學(xué)習(xí)速度。因此考慮不同分量具有不同分辨率的模糊規(guī)則構(gòu)造的條件為

第五層為解模糊層即輸出層,采用重心法進(jìn)行解模糊,輸出為輸入狀態(tài)動(dòng)作對(duì)的Q值,即
式中:ρi為第i個(gè)分量的分辨率;eT為T(mén)D誤差閾值;di為輸入狀態(tài)動(dòng)作對(duì)的第i個(gè)分量和該分量全部語(yǔ)言變量的隸屬度函數(shù)中心的最小距離,即

其中:xti為在時(shí)間t的狀態(tài)動(dòng)作對(duì)的第i個(gè)分量。
如果當(dāng)前狀態(tài)動(dòng)作對(duì)滿足式(7)的條件,系統(tǒng)就構(gòu)造一個(gè)新的模糊規(guī)則。為描述方便,記


式中參數(shù)τ為重疊系數(shù)。ηi為第i個(gè)分量的分辨率。新規(guī)則的后件wnew為

該規(guī)則第i個(gè)分量的隸屬度函數(shù)的寬度為
在學(xué)習(xí)的初始階段,系統(tǒng)沒(méi)有任何規(guī)則,可以以第一個(gè)狀態(tài)動(dòng)作對(duì)作為隸屬度函數(shù)中心建立第一個(gè)規(guī)則,規(guī)則的寬度設(shè)為[τρ1,…,τρn]。對(duì)于后續(xù)的狀態(tài)動(dòng)作對(duì)則根據(jù)式(7)來(lái)判斷是否創(chuàng)建新的規(guī)則。
當(dāng)無(wú)需增加新規(guī)則時(shí),即狀態(tài)動(dòng)作對(duì)不滿足規(guī)則構(gòu)建的條件時(shí),可以采用梯度下降法對(duì)規(guī)則的前件和后件中的相關(guān)參數(shù)進(jìn)行調(diào)整。但由于梯度下降法容易陷入局部最優(yōu),因此采用卡爾曼濾波法對(duì)相關(guān)參數(shù)進(jìn)行調(diào)整[14]。
令規(guī)則中全部可調(diào)參數(shù)構(gòu)成的向量為v=[w1,μT1,σT1,…,wK,μTK,σTK]T,根據(jù)卡爾曼濾波方法其更新式為

其中Γh為各個(gè)參數(shù)的梯度向量,由式(3),(4),(5),(6)可以推導(dǎo)出

其中Rh為測(cè)量噪聲方差,Ph為協(xié)方差矩陣,其更新式為

其中U是一個(gè)標(biāo)量,表示在梯度方向上的隨機(jī)步長(zhǎng),I為單位矩陣。如果參數(shù)v的長(zhǎng)度為N,Ph是一個(gè)N×N正定對(duì)稱(chēng)矩陣,當(dāng)新增一個(gè)規(guī)則時(shí),可調(diào)參數(shù)也將增加,矩陣Ph的維數(shù)按下式增加,即

其中P0為新增規(guī)則的初始化參數(shù)。
1.3 動(dòng)作輸出與搜索和利用平衡
為獲得最大的累積報(bào)酬,學(xué)習(xí)主體在任何狀態(tài)下總是選擇具有最大Q值的動(dòng)作,即貪婪動(dòng)作:

其中b為可選動(dòng)作。該貪婪動(dòng)作的求解實(shí)際上是一個(gè)優(yōu)化問(wèn)題,即
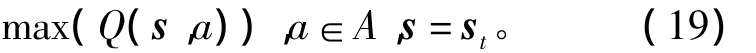
式中A為動(dòng)作定義域。將當(dāng)前狀態(tài)st代入上式有的障礙物與機(jī)器人之間的距離。


圖2 KheperaⅡ機(jī)器人傳感器及其布置[10]Fig.2 The displace of the sensor of the robot KheperaⅡ
上述優(yōu)化問(wèn)題可以用PSO或GA算法或最簡(jiǎn)單的格點(diǎn)法進(jìn)行求解。
為平衡強(qiáng)化學(xué)習(xí)中特有的搜索和利用兩難問(wèn)題,貪婪動(dòng)作并不直接作用于環(huán)境,而是在其上疊加一個(gè)干擾動(dòng)作ad[15],即執(zhí)行動(dòng)作aexe為

而干擾動(dòng)作ad服從如下的正態(tài)分布:

式中

λ為比列因子。
2 沿墻導(dǎo)航
和文獻(xiàn)[10]一樣,用 Khepera 2[16]機(jī)器人仿真器進(jìn)行實(shí)驗(yàn),該機(jī)器人的結(jié)構(gòu)如圖2所示,該機(jī)器人有6對(duì)紅外傳感發(fā)射、接收器,用于測(cè)量相應(yīng)方向上
實(shí)驗(yàn)?zāi)康氖窍M麢C(jī)器人在沒(méi)有任何先驗(yàn)知識(shí)的情況下通過(guò)強(qiáng)化學(xué)習(xí)獲得一個(gè)能控制機(jī)器人按順時(shí)針?lè)较蜓貕@行的控制器,因此只需考慮s0,s1,s2,s3這四個(gè)傳感器的輸出作為機(jī)器人狀態(tài)。機(jī)器人的動(dòng)作為轉(zhuǎn)角。將距離進(jìn)行歸一化處理后,機(jī)器人離墻的最小距離為0.15 m,最大距離為0.85 m。以傳感器s0的測(cè)量值為機(jī)器人與墻的距離。
仿真實(shí)驗(yàn)環(huán)境如圖3所示。在這個(gè)環(huán)境中,有三個(gè)90°拐角,一個(gè)270°拐角,一個(gè) 116.57°鈍角拐角,一個(gè)63.43°銳角拐角,可見(jiàn)該環(huán)境比文獻(xiàn)[10]要復(fù)雜。實(shí)驗(yàn)中4個(gè)傳感器的最大分辨率為1 m,最小分辨率為0.5 m。輸出轉(zhuǎn)角在-30°和30°之間,其最大分辨率為60°,最小分辨率為30°。所有分辨率衰減因子均為0.82。TD誤差閾值eT為0.01,TD誤差計(jì)算式(2)中的折扣因子γ=0.48,Q值更新式(1)中學(xué)習(xí)因子α=1。重疊因子τ=0.82。卡爾曼濾波器參數(shù)P0=R0=1.0,Q0=0.000 5。式(23)中λ=0.4。機(jī)器人速度為0.2 m/s。機(jī)器人決策時(shí)間間隔為200 ms。為簡(jiǎn)單起見(jiàn),貪婪動(dòng)作及最大Q值的計(jì)算采用格點(diǎn)法,即按ai=-30°+i+f(i=0°,1°…,60°,f是一個(gè)在區(qū)間[-0.5,0.5]上服從均勻分布的隨機(jī)數(shù)。如果ai大于30°,取ai為30°,如果ai小于 -30°,取ai為 -30°)。比較60 個(gè)輸出動(dòng)作的Q值,取Q值最大的動(dòng)作為貪婪動(dòng)作。
強(qiáng)化信號(hào)定義為


圖3 仿真環(huán)境Fig.3 The enviroment of simulation
為加快學(xué)習(xí)速度同時(shí)減小計(jì)算量,采用經(jīng)驗(yàn)重放的方法[17]進(jìn)行學(xué)習(xí)。
一次運(yùn)行中最大嘗試次數(shù)為500,當(dāng)機(jī)器人能繞墻成功行走1 200步(1 200步能確保機(jī)器人繞墻至少一周)就視為學(xué)習(xí)成功。每次嘗試時(shí)機(jī)器人的初始位姿為(0.5,0.5,90°)。
在25次運(yùn)行中,每次機(jī)器人都能經(jīng)過(guò)不到500次嘗試就能完成繞墻至少一周的任務(wù)。平均嘗試次數(shù)為67.6,最大嘗試次數(shù)為480,最小嘗試次數(shù)為5。控制器平均規(guī)則數(shù)為14,最大為40,最小為8。性能優(yōu)于文獻(xiàn)[10]的DFQL方法。如果直接采用文獻(xiàn)[13]中的方法進(jìn)行規(guī)則增加,即取總的最大分辨率為1,最小分辨率為0.5,在500次嘗試中并不能次次成功,同時(shí)由于規(guī)則數(shù)過(guò)多,計(jì)算量大。
圖4給出了在學(xué)習(xí)成功后繞墻行走的軌跡,該軌跡起點(diǎn)為(0.5,0.5)出發(fā),繞墻一周后終點(diǎn)為(2.66,4.42)。在這次運(yùn)行中,控制器經(jīng)過(guò)9次嘗試后就能成功地控制仿真機(jī)器人實(shí)現(xiàn)沿墻行走。

圖4 機(jī)器人繞墻行軌跡Fig.4 The tragectory of the robot
圖5給出了機(jī)器人方向角的變化情況,圖6給出了控制器在1 200步的沿墻運(yùn)動(dòng)中輸出的控制量變化。圖7所示為每個(gè)傳感器在沿墻行走過(guò)程中的測(cè)量值。圖8給出了在學(xué)習(xí)后自動(dòng)建立的9條規(guī)則中每個(gè)輸入變量隸屬度函數(shù)。

圖5 機(jī)器人方向角變化曲線Fig.5 The azimuth of the robot

圖6 控制器輸出控制量Fig.6 The output of the controller

圖7 各傳感器測(cè)量值變化Fig.7 The sensors value during moving

圖8 各輸入變量的隸屬度函數(shù)曲線Fig.8 Member function of ench variable
在25次運(yùn)行過(guò)程中,一旦控制器通過(guò)學(xué)習(xí)能控制機(jī)器人過(guò)90°拐角和270°拐角后,就可以直接過(guò)116.57°鈍角拐角,這說(shuō)明該學(xué)習(xí)系統(tǒng)具有較強(qiáng)的泛化性能。對(duì)于63.43°銳角拐角有時(shí)還需要進(jìn)行學(xué)習(xí)。同時(shí)控制器在學(xué)習(xí)通過(guò)拐角的過(guò)程中,對(duì)沿直線墻行走控制一般沒(méi)有影響,這源于FRBF網(wǎng)絡(luò)具有局部逼近的特性。
從圖5的機(jī)器人方位角變化情況來(lái)看,機(jī)器人在直線段行走過(guò)程中,方向角總的來(lái)說(shuō)是以墻的方向角為基準(zhǔn)波動(dòng),這種波動(dòng)一是由于強(qiáng)化學(xué)習(xí)中已有知識(shí)的應(yīng)用和新知識(shí)的探索之間的平衡所致。為能搜索到更好的策略,學(xué)習(xí)主體每次執(zhí)行的動(dòng)作并非是最優(yōu)動(dòng)作(已有知識(shí)的利用),通過(guò)選擇貪婪動(dòng)作之外的動(dòng)作來(lái)發(fā)現(xiàn)更好的動(dòng)作(搜索),但這將會(huì)導(dǎo)致系統(tǒng)性能下降。二是由于傳感器s0的測(cè)量值并非是機(jī)器人和墻之間的距離,傳感器的測(cè)量值對(duì)機(jī)器人的姿態(tài)非常敏感,姿態(tài)的細(xì)微變化會(huì)導(dǎo)致測(cè)量值的巨大波動(dòng),為克服這種測(cè)量波動(dòng),機(jī)器人基本上是以一種之字形的路線沿墻行走,以保持其不出“軌道”。這一點(diǎn)從圖6控制器輸出控制量變化情況也可以看出。盡管傳感器s0的測(cè)量值不是機(jī)器人與墻的真正距離,用本文所提的方法仍然能獲得一個(gè)可以控制該機(jī)器人實(shí)現(xiàn)沿墻行走的控制器。
圖7和圖8分別給出機(jī)器人在1 200步的運(yùn)行過(guò)程中四個(gè)傳感器輸出的測(cè)量數(shù)值和狀態(tài)動(dòng)作對(duì)的五個(gè)分量的八個(gè)語(yǔ)言變量的隸屬度函數(shù)。
在前面所述文獻(xiàn)中,如文獻(xiàn)[10],控制器的輸出動(dòng)作總的來(lái)說(shuō)是基于預(yù)先選定的若干個(gè)離散的加權(quán)構(gòu)成,假設(shè)離散種子動(dòng)作集合B={a1,a2,…,am},規(guī)則數(shù)為n,則控制器輸出動(dòng)作為

其中bi為第i條規(guī)則輸出動(dòng)作,βi為第i條規(guī)則后件。將上式進(jìn)行如下處理并按ai進(jìn)行同類(lèi)項(xiàng)合并,即有:

由上式可見(jiàn),由離散種子動(dòng)作加權(quán)獲得輸出動(dòng)作本質(zhì)上是由種子動(dòng)作構(gòu)成的向量和由規(guī)則后件構(gòu)成的向量的內(nèi)積,后者需要通過(guò)學(xué)習(xí)來(lái)確定,其參數(shù)空間的維數(shù)為m-1。為獲得連續(xù)的動(dòng)作,離散動(dòng)作數(shù)m一般都取得較大,如在文獻(xiàn)[10]中,m為13,這樣參數(shù)空間維數(shù)比原來(lái)動(dòng)作空間維數(shù)要大,因此學(xué)習(xí)速度慢,且同一規(guī)則內(nèi)的離散動(dòng)作之間沒(méi)有泛化能力。
3 結(jié)論
本文提出了一種基于模糊Q-學(xué)習(xí)導(dǎo)航控制方法,與已有的連續(xù)空間中的Q學(xué)習(xí)方法相比,其特點(diǎn)之一是以模糊神經(jīng)網(wǎng)絡(luò)對(duì)Q值函數(shù)進(jìn)行直接逼近,通過(guò)函數(shù)優(yōu)化的方法獲得輸出動(dòng)作,這就克服了相關(guān)文獻(xiàn)中種子動(dòng)作的選擇問(wèn)題,實(shí)現(xiàn)了強(qiáng)化學(xué)習(xí)和函數(shù)優(yōu)化技術(shù)的結(jié)合。特點(diǎn)之二是提出了一種新的模糊規(guī)則自適應(yīng)構(gòu)造方法,實(shí)現(xiàn)了在學(xué)習(xí)過(guò)程中模糊規(guī)則的自動(dòng)構(gòu)建和相關(guān)參數(shù)的自適應(yīng)調(diào)整,避免了模糊規(guī)則手工建立的困難。此外學(xué)習(xí)經(jīng)驗(yàn)不但能在鄰近的狀態(tài)中可以進(jìn)行泛化,還可以在相鄰的動(dòng)作之間進(jìn)行泛化,因此學(xué)習(xí)速度也得到提高。實(shí)驗(yàn)結(jié)果表明該方法可以成功實(shí)現(xiàn)機(jī)器人沿墻行走的導(dǎo)航控制。
今后還將該方法應(yīng)用到其他控制問(wèn)題,此外本文所提的模糊規(guī)則自適應(yīng)方法還可以應(yīng)用到監(jiān)督學(xué)習(xí)等方面,這都是今后的研究?jī)?nèi)容。
[1] TURENNOUT P,HONDERD G,SCHELVEN L J.Wall-following control of a mobile robot[C]//Proceedings of the1992IEEE International Conference on Robotics and Automation,May 12 - 14,1992,Nice,F(xiàn)rance.1992:280-285.
[2] BORENSTEIN J,KERON Y.The vector filed histogram fast obstacle avoidance for mobile robots[J].IEEE Transactions on Robotics and Automation,1991,7(3):278-288.
[3] 彭一準(zhǔn),原魁,劉俊承,等.室內(nèi)移動(dòng)機(jī)器人的三層規(guī)劃導(dǎo)航策略[J].電機(jī)與控制學(xué)報(bào),2006,10(4):380-384.
PENT Yizhun,YUAN Kui,LIU Juncheng,et al.A three-layer planning navigation method for indoor mobile robot[J].Electric Machines and Control,2006,10(4):380 -384.
[4] KHATIB O.Real-time obstacle avoidance for manipulator and mobile robots[J].International Journal of Robotic Research,1986,5(1):90-98.
[5] Lee P S,Wang L L.Collision avoidance by fuzzy logic control for automated guided vehicle navigation[J].Journal of Robotic Systems,1994,11(8):743 -760.
[6] ZHANG Wenzhi,LU Tiansheng.Reactive fuzzy controller design byQ-learning for mobile robot navigation[J].Journal of Harbin Institute of Technology,2005,12(3):319 -324.
[7] 吳洪巖,劉淑華,張崳.基于RBFNN的強(qiáng)化學(xué)習(xí)在機(jī)器人導(dǎo)航中的應(yīng)用[J].吉林大學(xué)學(xué)報(bào):信息科學(xué)版,2009,27(2):185-190.
WU Hongyan,LIU Shuhua,ZHANGYu.Application of reinforcement learning based on radial basis function neural networks in robot navigation[J].Journal of Jilin University:Information Science Edition,2009,7(2):185-190.
[8] 陸軍,徐莉,周小平.強(qiáng)化學(xué)習(xí)方法在移動(dòng)機(jī)器人導(dǎo)航中的應(yīng)用[J].哈爾濱工程大學(xué)學(xué)報(bào),2004,25(2):176-179.
LU Jun,XU Li,ZHOU Xiaoping.Research on reinforcement learning and its application to mobile robot[J].Journal of Harbin Engineering University,2004,25(2):176-179.
[9] 段勇,徐心和.基于模糊神經(jīng)網(wǎng)絡(luò)的強(qiáng)化學(xué)習(xí)及其在機(jī)器人導(dǎo)航中的應(yīng)用[J].控制與決策,2007,22(5):525-534.
DUAN Yong,XU Xinhe.Reinforcement learning based on FNN and its application in robot navigation[J].Control and Decision,2007,22(5):525-534.
[10] ER M J,DENG C.Online tuning of fuzzy inference systems using dynamic fuzzyQ-learning[J].IEEE Transactions on Systems,Man and Cybernetics Part B:Cybernetics,2004,34(3):1478-1489.
[11] BARTO A G,SUTTON R S,ANDERSON C W.Neuron like adaptive elements that can solve difficult learning control problems[J].IEEE Transactions on Systems,Man,and Cybernetics,1983,13(5):834-846.
[12] LEE C C.Fuzzy logic in control systems:fuzzy logic controller-Part I and II[J].IEEE Transactions on Systems,Man and Cybernetics,1990,20(2):404 -435.
[13] PLATT J.A resource allocating network for function interpolation[J].Neural Computation,1991,3(2):213 -225.
[14] SINGHAL S,WU L.Training multilayer perceptrons with the extended Kalman algorithm[C]//Advances in Neural Processing Systems,December 12 -14,1988,San Mateo,CA.1988:133-140.
[15]KONDO T,ITO K.A reinforcement learning with evolutionary state recruitment strategy for autonomous mobile robots control[J].Robotics and Autonomous Systems,2004,46(2):111-124.
[16] KTEAM S A.Khepera 2 User Manual[R].Switzerland,2002.
[17] LIN L J.Self-improving reactive agents based on reinforcement learning,planning and teaching[J].Maching Learning,1992,8(3-4):293-321.
(編輯:劉素菊)
猜你喜歡
小獼猴智力畫(huà)刊(2022年3期)2022-03-29 01:09:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:26:14
小學(xué)生作文(低年級(jí)適用)(2018年3期)2018-04-17 00:58:35
Coco薇(2017年11期)2018-01-03 20:59:57
少年博覽·小學(xué)低年級(jí)(2017年4期)2017-06-09 16:22:28
作文評(píng)點(diǎn)報(bào)·低幼版(2017年7期)2017-03-11 20:49:41
暨南學(xué)報(bào)(哲學(xué)社會(huì)科學(xué)版)(2016年9期)2017-01-15 13:52:02
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 20:56:37
