開源工具在機器學習教學中的應用
2009-03-17 09:14:32高明霞方娟毛國君
計算機教育 2009年3期
關鍵詞:機器學習
高明霞 方 娟 毛國君
文章編號:1672-5913(2009)02-0100-03
摘 要:機器學習是一門以算法和學習理論為主的計算機專業基礎課程,單純的算法分析和理論講解很難引起學生的學習興趣。為了激發學生的興趣,循序漸進的完成教學目標,本文探討了在課堂講授、課程作業和畢業設計三個基本教學環節中應用開源機器學習工具——WEKA的教學方法。
關鍵詞:機器學習;WEKA;算法
中圖分類號:G642
文獻標識碼:B
1 引言
機器學習課程是很多大學為計算機科學與技術專業的高年級學生和研究生開設的專業基礎課程。它主要講授目前機器學習中各種實用的理論和算法,包括概念學習、決策樹、神經網絡、貝葉斯學習、基于實例的學習、遺傳算法、規則學習、基于解釋的學習和增強學習等。機器學習教學的主要目標有兩個:一是掌握典型的機器學習算法并利用這些技術解決實際問題;二是根據實際應用改進現有方法,發展新的機器學習技術。目前機器學習的教學內容主要集中在典型算法和學習理論,現有教材中使用的實例和現實應用差距很大,如果教師的課堂教學中過多的采用算法分析和偽碼演示,很難激發學生的學習興趣。實際上,機器學習方法已經有了十分廣泛的應用,被成功的運用到了生物特征識別、搜索引擎、醫學診斷等各個領域。如果在教學過程中,讓同學們看到、感受到、甚至于自己參與到這些機器學習的應用實例中,必定能大大激發學生的學習興趣。
為此,我們設計了一個包括課堂講授、課程作業和畢業設計三個教學環節的教學過程,并在每個教學環節中,應用了一個開源的機器學習工具——WEKA。首先,教師利用WEKA的可視化界面在課堂教學上展示了經典算法和實例的運行效果;其次,教師應用WEKA的多種算法實現,在課程作業環節,為學生布置了一些現實應用,并要求他們借助WEKA自己解決;最后,在畢業設計環節,教師針對機器學習技術的最新發展,要求有能力、感興趣的學生自己實現某個新算法,并借助WEKA的可視化接口,和原有算法進行性能對比分析。借助WEKA,應用這種循序漸進的教學過程,可以引導學生了解機器學習課程的作用,并培養他們利用所學知識解決實際問題的動手能力和發現問題、解決問題、評估問題的研究能力。
下邊首先簡單介紹一下開源工具——WEKA。接著講述其在教學演示,課程作業和畢業設計方面的應用。最后是對本文的簡要總結。
2 WEKA簡介
WEKA[1]的全名是懷卡托智能分析環境(Waikato Environment for Knowledge Analysis),它的源代碼可通過http://www.cs.waikato.ac.nz/ml/WEKA得到。由于WEKA的主要開發者來自新西蘭,所以使用了一種新西蘭的鳥名命名這個工具。2005年8月,在第11屆ACM SIGKDD國際會議上,懷卡托大學的WEKA小組榮獲了數據挖掘和知識探索領域的最高服務獎,WEKA系統得到了廣泛的認可,成為現今較完備的數據挖掘工具之一。WEKA 3.5.8能夠提供四種操作環境:SimpleCLI、Explorer、Experimenter、knowledgeflow。四種操作環境的基本原理都大同小異,只是提供的界面不一樣。SimpleCLI適合于直接使用代碼的用戶;Knowledgeflow傾向于喜歡圖標的實驗者;explorer和experimenter通常更適用于功能形控制。WEKA作為一個開源的數據挖掘工作平臺,集合了大量能承擔數據挖掘任務的機器學習算法,包括對數據進行預處理、分類、回歸、聚類、關聯規則以及在新的交互式界面上的可視化。WEKA提供了通用的接口文檔和插件模式的系統結構,供機器學習研究人員方便的實現自己的算法并集成到WEKA環境中進行深入研究。
3 WEKA在教學演示方面的應用
講解某個機器學習算法時,除了從理論上進行闡述外,使用一個真實問題,借助WEKA為學生演示該算法解決這個真實問題的整個步驟,并根據算法特點和知識點,在演示過程中設置問題和學生交互更能激發學生的興趣,加深他們對算法的認識。下邊是針對教材中通用的天氣(weather)數據集(5個屬性,14個樣例)講解決策樹算法ID3時WEKA—Explorer在教學演示方面的應用。
1) 數據預處理:Explorer的選項卡“Preprocess”提供了對樣例數據的多角度觀察和大數據集的屬性實例過濾操作等數據預處理方法。在這個過程中,以可視的形式給學生展示了數據預處理,數據格式等和算法相關的知識。由于ID3算法只能處理離散值屬性,原始實例中的兩個屬性(temperature和humidity)值范圍是實數,為了滿足ID3算法,需要對這些屬性值進行各種離散化處理。借助這一選項卡對各種離散化方法進行展示,并比較結果和使用范圍。
2) 屬性選擇方法:Explorer的選項卡“Select attributes”提供了多種方法用于選擇分類屬性,例如信息增益(information gain),信息增益比(gain ratio)等。通過多種屬性選擇方法對天氣數據集中的五個屬性進行實時處理和可視化結果對比,為學生展示了屬性選擇對ID3算法的重要性。
3) 樹模型形成:Explorer的選項卡“Classify”提供了各種測試形式用于形成樹模型,包括帶訓練集(use training set)、交叉驗證(cross-validation)、比例分割(percentage split)等測試形式。通過自由選擇可以實時演示不同測試形式的模型學習結果和詳細評估指標,通過對比可以了解不同測試形式的優缺點以及適用范圍。特別是帶源碼的模型結果輸出,除了形象的展示了形成的模型樹外,還以面向對象編程的思想展示了ID3算法的JAVA語言實現,這些真實程序和偽代碼結合講解,可以培養學生的實際動手能力和算法抽象能力。
4) 結果指標的圖形化演示和處理:除了選項卡“Classify”提供的分類器輸出(Classifier Output)用于顯示結果指標,WEKA對結果的一些特殊指標提供了圖形化演示和文件導出的靈活功能,可以通過右鍵獲得。
4 WEKA在課程作業方面的應用
上節借助WEKA演示機器學習算法的過程可以幫助學生掌握典型的機器學習方法,本節結合教學過程中的課程作業布置重點闡述借助WEKA培養學生利用所學機器學習方法解決實際問題的能力。
由于機器學習方法在實際領域中得到了廣泛的應用,我們可以將這些領域中的現實問題提出作為課程作業布置給學生,要求他們利用所學的機器學習方法來解決。如果沒有WEKA對經典算法的實現,就需要學生自己花費大量時間完成算法實現、輸入數據標準化和輸出格式圖形化這些復雜、繁瑣的編程工作。這將大大降低學生學習機器學習方法和利用這些方法解決現實問題的興趣。WEKA作為一個數據分析平臺,提供了大量經典機器學習算法的實現,并提供了方便的數據輸入、結果輸出和可視化功能,它能簡化利用機器學習技術解決現實問題的過程。使得學生集中關注有助于提高他們解決問題能力的如下問題點:現實問題到機器學習實例的形式化,所用機器學習算法的優缺點和數據要求,那些算法適用這一現實領域等。
下邊以自然語言處理領域中一個識別自然語言問題所處領域的現實需求為例,說明利用WEKA解決這一現實問題的簡化過程。問題領域識別是問題分類[2]的一種,可以看作是典型的文本分類問題,通常需要特征提取,模型訓練,和新問題預測三個階段。課程作業所用樣本問題搜集于MadSci Circumnavigator站點1996至2005年間用戶提交的真實問題,包括計算機領域的709個問題和醫療領域的2142個問題,糾正了原始問題中包含的語法和拼寫錯誤,分別得到570個計算機類和1928個醫療類問題。
特征提取可以參考文本分類[3]中所用特征向量,將同領域中的所有樣本問題包含的核心詞作為特征,并以要分類問題中是否出現這些核心詞為這些特征定義兩個取值{0,1},分別表示不出現和出現。這一階段主要完成現實問題到機器學習問題的形式化,所用技術和自然語言處理領域密切相關,和WEKA關系不大。
定義了特征后,模型訓練和新問題領域預測兩個階段可完全借助WEKA—Explorer實現。模型訓練需要選擇合適的問題作為正負樣例,并根據特征取值和所屬領域將他們轉換為特征向量,表示成WEKA可識別的數據格式,用WEKA提供的各種分類器訓練模型。要完成這一步驟,需要了解WEKA使用的數據格式。WEKA存儲數據的格式是一種ASCII文本文件ARFF(Attribute-Relation File Format)。表1中的ARFF文件就是部分計算機領域的WEKA數據樣例集。以“%”開始的行是注釋行,處理過程中被忽略。除去注釋后,整個ARFF文件可以分為頭信息和數據信息兩個部分。頭信息(Head information),包括對關系和屬性的聲明。數據信息(Data information),即數據集中的實際樣例,從“@data”標記開始。將要處理的數據表示成WEKA的存儲格式后,就可以利用Explorer 的選項卡“Classify”提供的不同分類器和訓練方式來訓練模型。該選項卡的作用很清晰,面板上的操作類型也很明確,我們可以按照要求選擇并完成模型訓練,右邊的分類器輸出(Classifier Output)對該模型的具體情況做了詳細說明。表2是選擇WEKA中提供的NaiveBayes、RBFNetwork、VotedPerceptron、SMO四種分類算法和它們的默認參數,對訓練樣本集進行了4-fold的交叉驗證后得到的模型精度結果。

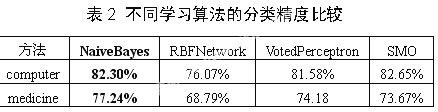
由于目前的應用實例只考慮了兩個領域,所以新問題預測只能預測該問題是否屬于某個(計算機或醫療)領域。例如要預測問題“should I gargle salty water against mouth infection?”是否屬于醫療領域。只需要將新問題根據醫療領域的特征字典和取值表示成特征向量,并將最后一個屬性值result置空,使其成為一個要預測問題的ARFF文件(medicine-new.arff)。從表2可知要選擇第一個分類器(Na?ve Bayes)和醫療訓練數據形成的學習模型預測,在這個模型結果列表上重新選擇測試形式(Test options)為 “Supplied test set”,并且“Set”成你得到的要預測問題的數據集,這里是“medicine-new.arff”文件。現在,右鍵點擊選擇的模型,選擇“Re-evaluate model on current test set”進行預測。并通過點擊右鍵菜單中的“Visualize classifier errors”,將彈出的一些有關預測誤差的散點圖保存成一個Arff文件。打開這個文件可以看到在倒數第二個位置多了一個屬性(predictedpep),這個屬性上的值就是模型對新問題領域的預測值。
5 WEKA在實踐環節的應用
不同的機器學習算法有不同的特點和應用領域,隨著大量新問題和新領域的出現,研究人員在不斷的開發新的算法和改進已有算法的應用范圍。對于那些對機器學習技術有興趣,想深入學習的學生,為他們提供機器學習領域內合適的畢業設計題目可以鍛煉他們的實踐能力和科研能力。例如讓他們實現一個新的機器學習算法并通過實驗分析比較它的性能和優缺點。WEKA提供了插件體系模式和通用接口,供研究人員方便的集成自己的算法到他的環境中。所以,學生可以借助WEKA的這些功能,實現這一算法并集成在WEKA的環境中,利用WEKA平臺方便快捷的分析、比較新算法和已有典型算法的各種性能。
6 結論
為了更好的達到機器學習教學的兩個目標,激發出學生學習機器學習課程的興趣,我們在機器學習的教學過程中應用了一個開源工具——WEKA,并借助它的可視化環境、典型算法實現和通用接口說明,在課堂上為學生演示實際問題解決過程,在課程作業布置上有意識的選擇特定領域得真實問題并要求學生應用WEKA和所學知識解決這些問題,在課程設計上鼓勵學生以WEKA提供的通用接口實現新算法和改進現有算法并集成到它的環境中。通過這些教學步驟,讓學生循序漸進的做到了解機器學習方法,掌握典型算法,利用機器學習方法解決問題,提出、實現新的機器學習方法,并最終實現機器學習教學的兩個目標。
參考文獻:
[1] I. Witten, E. Frank. WEKA Machine Learning Algorithms in Java[D]. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations, Morgan Kaufmann Publishers, 2000.
[2] J. Pomerantz. A Linguistic Analysis of Question Taxonomies[J]. Journal of the American Society for Information Science and Technology, 2005,56(7).
[3] C. Zhalaing, P. L. Khanh, M. Ashesh, et al. Feature Extraction for Learning to Classify Questions[J]. AI 2004, 2004, LNAI 3339.
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
