基于SVM的書目數(shù)據(jù)自動分類設(shè)計與應(yīng)用研究
2022-01-21 00:25:22柴源
黑龍江科學(xué) 2021年24期
柴 源
(西安航空學(xué)院 圖書館,西安 710077)
目前,書目數(shù)據(jù)分類標(biāo)引系統(tǒng)的算法模型主要依賴于詞表和知識庫,分類標(biāo)引準(zhǔn)確率較低[1]。圖書內(nèi)容簡介屬于文本文檔,難以通過一個線性分類器(直線、平面)來實現(xiàn)分類。書目數(shù)據(jù)自動分類是采用機(jī)器學(xué)習(xí)算法,將圖書內(nèi)容簡介經(jīng)過自然語言處理后與《中國圖書館分類法》進(jìn)行自動匹配的過程,支持向量機(jī)(Support Vector Machine,SVM)可以將低維空間數(shù)據(jù)通過核函數(shù)映射到高維空間中,獲得線性可分的特性,實現(xiàn)自動分類[2-3]。基于此,提出了一種基于SVM的書目數(shù)據(jù)分類算法模型并進(jìn)行實驗研究。
1 支持向量機(jī)
SVM (Support Vector Machine,支持向量機(jī))通過某種事先選擇的非線性映射,將輸入向量映射到一個高維空間中,構(gòu)造最優(yōu)分類超平面,將不同類別的樣本分開[4]。超平面是一個比原特征空間少一個維度的子空間,在二維情況下是一條直線,在三維情況下是一個平面[5]。研究表明,支持向量機(jī)在處理二分類任務(wù)時是非常成功的,解決實際問題時,它將多分類問題轉(zhuǎn)化為多次二分類問題,并進(jìn)行最大值或投票決策,從而實現(xiàn)多分類[6],基本原理表述如下:
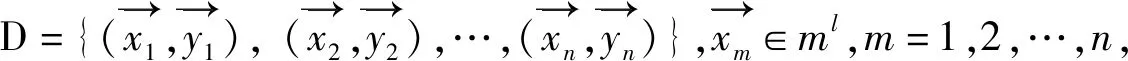
2 自動分類模型的設(shè)計
自動分類模型的設(shè)計主要包括書目數(shù)據(jù)預(yù)處理、文本特征提取、構(gòu)造分類模型、模型性能評估等階段,具體流程如圖1所示。
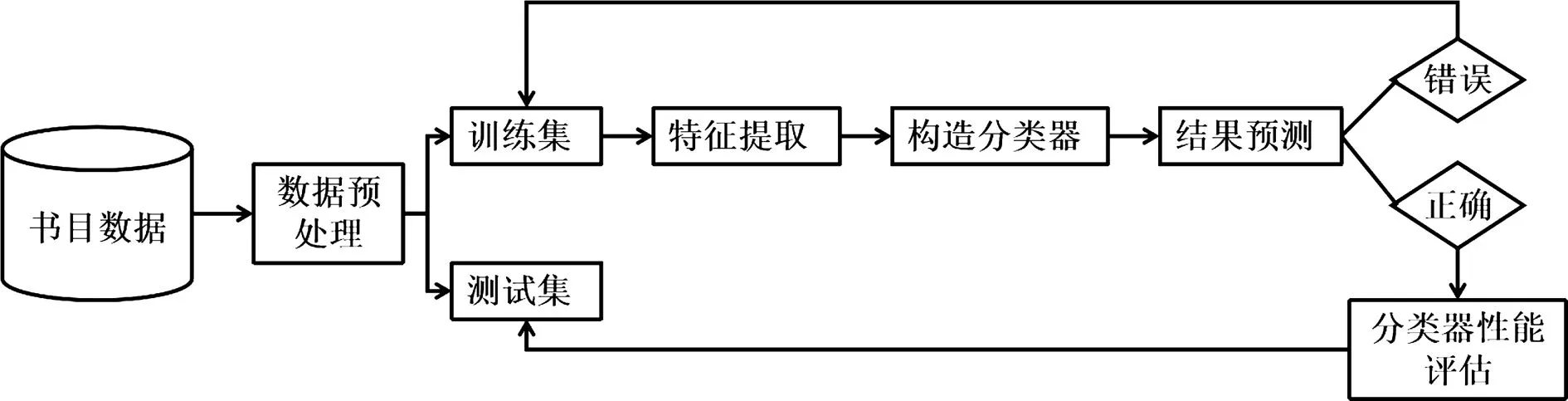
圖1 系統(tǒng)設(shè)計Fig.1 System design
2.1 數(shù)據(jù)預(yù)處理
數(shù)據(jù)清洗。去除重復(fù)的文本,過濾掉沒有研究意義的各種符號,通過小寫化、詞干提取和詞形還原等規(guī)范化處理語料里的英文詞匯。
中文分詞。為了提高計算機(jī)對文本信息的識別和理解能力,實驗整合中文停用詞表(cn_stopwords.txt)、哈工大停用詞表(hit_stopwords.txt)、百度停用詞表(baidu_stopwords.txt)、四川大學(xué)機(jī)器智能實驗室停用詞庫(scu_stopwords.txt)等,形成停用詞表;數(shù)字化《中國分類主題詞表》,形成用戶詞典,并在此基礎(chǔ)上應(yīng)用jieba工具進(jìn)行分詞。
數(shù)據(jù)編碼。原始數(shù)據(jù)中的分類是列表標(biāo)記,為了便于訓(xùn)練分類模型,將其轉(zhuǎn)化為數(shù)值編碼,即給每一個分類設(shè)定一個數(shù)值。
2.2 文本向量表示
獲取詞匯表。將數(shù)據(jù)預(yù)處理結(jié)果按照一定比例劃分為訓(xùn)練集和測試集,訓(xùn)練集用于特征提取、模型構(gòu)建和驗證,測試集用于模型性能測試。例如:[農(nóng)村,醫(yī)療保障,待遇,水平,標(biāo)準(zhǔn),統(tǒng)籌,發(fā)揮,醫(yī)療保險,大病,保險……]。
計算每個詞的TF-IDF值。TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆文檔頻度)是一種用于信息檢索與文本挖掘的常用加權(quán)技術(shù)[7],如果某個詞在一篇文章中出現(xiàn)的頻率TF高,且在其他文章中很少出現(xiàn),則認(rèn)為此詞具有很好的類別區(qū)分能力,適合用來分類。文本中每個詞的TF值是每個詞的詞頻/總詞頻,例如:人工智能的詞頻是1,總詞頻是9,所以“人工智能”的TF值是1/9;“人工智能”這個詞的IDF=log(2/(2+0.001))=-0.0005。
使用TF-IDF表示一個文本。將訓(xùn)練集中每一個文本中的每一個詞對應(yīng)詞匯表的索引進(jìn)行填值,詞匯表中有的索引就用TF-IDF值填充,沒有的就用0填充。
2.3 卡方檢驗
文本向量表示后,所含的特征維度非常高,需要進(jìn)行特征降維,去除一些與分類關(guān)系不大的無關(guān)特征,獲取更有價值的信息,降低算法的復(fù)雜度。
卡方檢驗(chi-square distribution,CHI)是一種統(tǒng)計學(xué)的工具,用來檢驗數(shù)據(jù)的擬合度和關(guān)聯(lián)度,是特征降維有效的方法[8]。假設(shè)特征項t和類別ci之間符合一階自由度的χ2分布,特征項t對于類別ci的χ2統(tǒng)計值越高,特征項t和類別ci的相關(guān)性越強(qiáng),類別區(qū)分度越大,反之,類別區(qū)分度越小。計算公式如下:
式中,A為包含特征項t且屬于類別ci的文本數(shù)目,B為包含特征項t且不屬于類別ci的文本數(shù)目,C為不包含特征項t且屬于類別ci的文本數(shù)目,D為不包含特征項t且不屬于類別ci的文本數(shù)目。將每個特征項t的χ2統(tǒng)計值從大到小排序,選取前若干個作為特征項集合。
2.4 訓(xùn)練分類器
scikit-learn是一個功能強(qiáng)大的通用機(jī)器學(xué)習(xí)庫,封裝了大量常用的機(jī)器學(xué)習(xí)算法,包括各種分類算法。設(shè)計采用scikit-learn的支持向量機(jī)模型訓(xùn)練分類器,主要是將卡方檢驗后的特征向量輸入,使用支持向量機(jī)模型訓(xùn)練分類器,并用訓(xùn)練集數(shù)據(jù)驗證分類器的準(zhǔn)確性。
2.5 分類器的性能評估
準(zhǔn)確率(accuracy)、精確率(precision)、召回率(recall)、f1分?jǐn)?shù)(f1-score)是分類器性能評估的重要指標(biāo)。準(zhǔn)確率是針對所有樣本而言的,表示所有樣本有多少被準(zhǔn)確預(yù)測了,即:
精確率是針對預(yù)測結(jié)果而言的,表示預(yù)測為正的樣本中有多少是真正的正樣本,一種是把正類預(yù)測為正類(TP),另一種是把負(fù)類預(yù)測為正類(FP),即:
召回率是針對正樣本而言的,它表示正例樣本中有多少被預(yù)測正確了。一種是把原來的正類預(yù)測成正類(TP),另一種是把原來的正類預(yù)測為負(fù)類(FN),即:
f1分?jǐn)?shù)(f1-score)是精確率和召回率的調(diào)和平均數(shù),最大為1,最小為0,值越大意味著模型越好,即:
3 實驗結(jié)果與分析
實驗系統(tǒng)環(huán)境為Windows10,語言環(huán)境為Python,調(diào)用Python的第三方機(jī)器學(xué)習(xí)庫Scikit-learn來實現(xiàn)SVM的分類方法。
3.1 實驗數(shù)據(jù)
以西安航空學(xué)院2018-2020年的中文圖書書目數(shù)據(jù)為語料,共計36 046條。由于研究是通過圖書內(nèi)容判別分類號的,所以刪除題名、ISBN、責(zé)任者、主題詞等字段,保留內(nèi)容簡介和分類號。預(yù)處理后的數(shù)據(jù)如圖2所示。
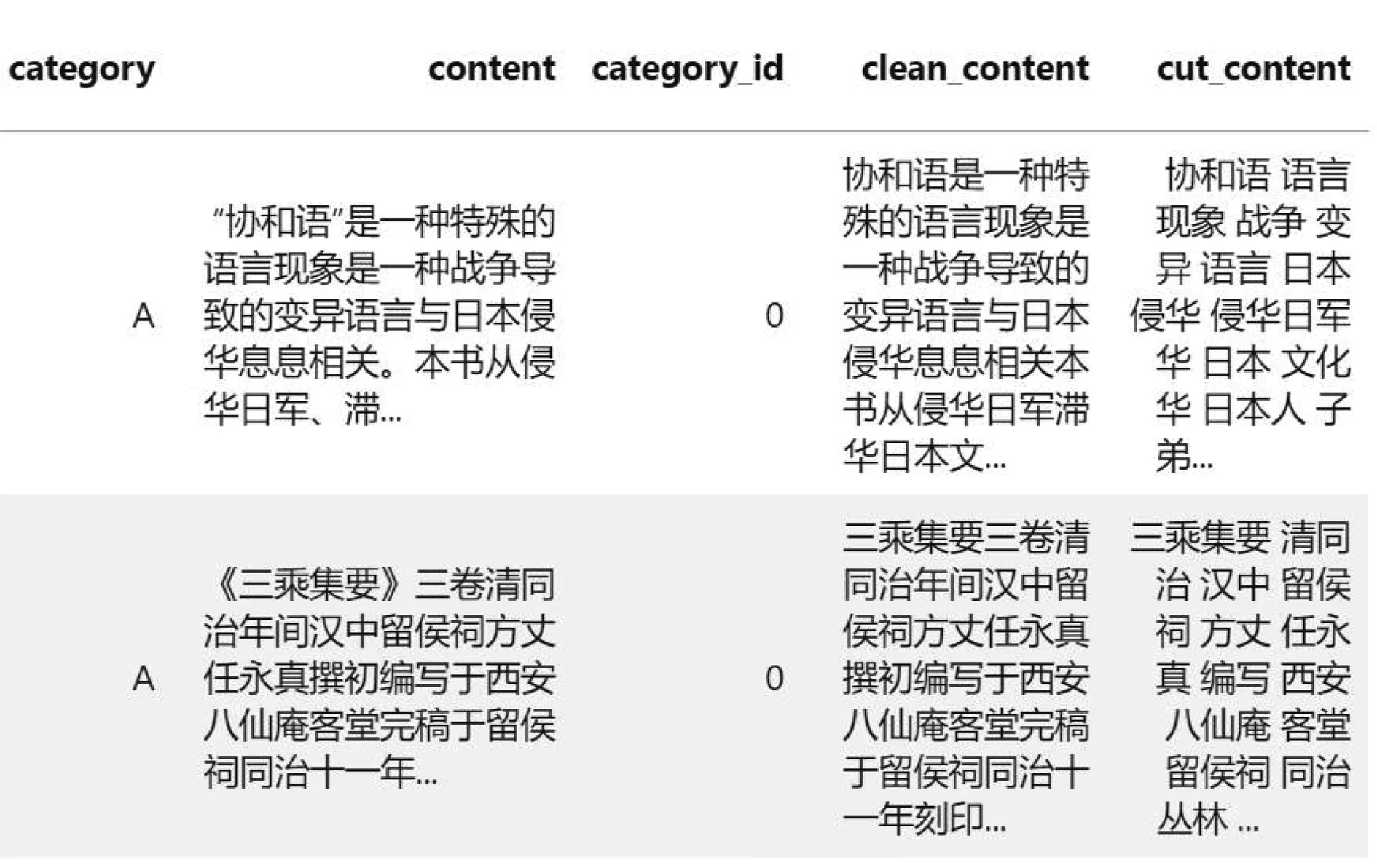
圖2 數(shù)據(jù)預(yù)處理結(jié)果(部分)Fig.2 Data pre-processing results(part)
圖2中,category表示圖書類別A,B,C,...,Z;category_id表示類別的數(shù)值化,0表示A,1表示B...;content表示圖書內(nèi)容簡介;clean_content表示清洗后的文本;cut_content表示每個文本的分詞結(jié)果。
3.2 TF-IDF特征提取
采用train_test_split()函數(shù),設(shè)置size=0.25,將數(shù)據(jù)集劃分為訓(xùn)練集和測試集。調(diào)用TfidfVectorizer類,ngram_range設(shè)置為(1,2),表示除了抽取每個詞語外,再抽取每個詞相鄰的詞并組成一個“詞語對”,擴(kuò)展特征集的數(shù)量,提高分類的準(zhǔn)確度。實驗結(jié)果可知,維度是(36 046,684 175),前者表示總共有36 046條數(shù)據(jù),后者表示共有684 175個特征數(shù)量,特征數(shù)量包括所有詞語和詞語對。特征提取結(jié)果如圖3所示。
圖3 TF-IDF特征提取結(jié)果(部分)Fig.3 TF-IDF feature extraction results(part)
3.3 卡方檢驗降維
針對特征維度較高的情況,實驗使用sklearn中的chi2卡方檢驗法進(jìn)行降維,參數(shù)n=4表示找出每個分類中關(guān)聯(lián)度最強(qiáng)的4個詞語和4個詞語對,加入到詞表中,將詞表中的詞作為保留特征。以TH類為例,部分檢驗結(jié)果如圖4所示。

圖4 卡方檢驗結(jié)果(TH類)Fig.4 Chi-square test results(TH type)
3.4 模型構(gòu)建與訓(xùn)練
實驗調(diào)用LinearSVC構(gòu)造分類模型,設(shè)置kernel=“rbf”,表示使用rbf核;gamma=0.05,表示rbf核相對應(yīng)的參數(shù)為0.05;degree=3表示模型的冪次方等于3次。得到模型后,使用訓(xùn)練集對模型進(jìn)行訓(xùn)練,編寫函數(shù)myPredict,代碼如下,驗證訓(xùn)練集內(nèi)容的分類情況,并抽取不準(zhǔn)確的分類進(jìn)行增量訓(xùn)練。
def myPredict(sec):
format_sec="".join([w for w in list(jieba.cut(remove_punctuation(sec))) if w not in stopwords])
pred_category_id=clf.predict(count_vect.transform([format_sec]))
print(id_to_category[pred_category_id[0]])
例如,當(dāng)sec=“本書吸收了國內(nèi)經(jīng)濟(jì)學(xué)教材的優(yōu)點(diǎn),按照微觀經(jīng)濟(jì)學(xué)和宏觀經(jīng)濟(jì)學(xué)的構(gòu)架,對經(jīng)濟(jì)學(xué)的一些基本理論和專業(yè)知識、技術(shù)和研究方法進(jìn)行講解與分析。”時,執(zhí)行函數(shù),結(jié)果顯示為F,驗證結(jié)果準(zhǔn)確。
3.5 模型評估
模型在測試集上的精確率、召回率、f1分?jǐn)?shù)及準(zhǔn)確率等性能指標(biāo),如表1所示。
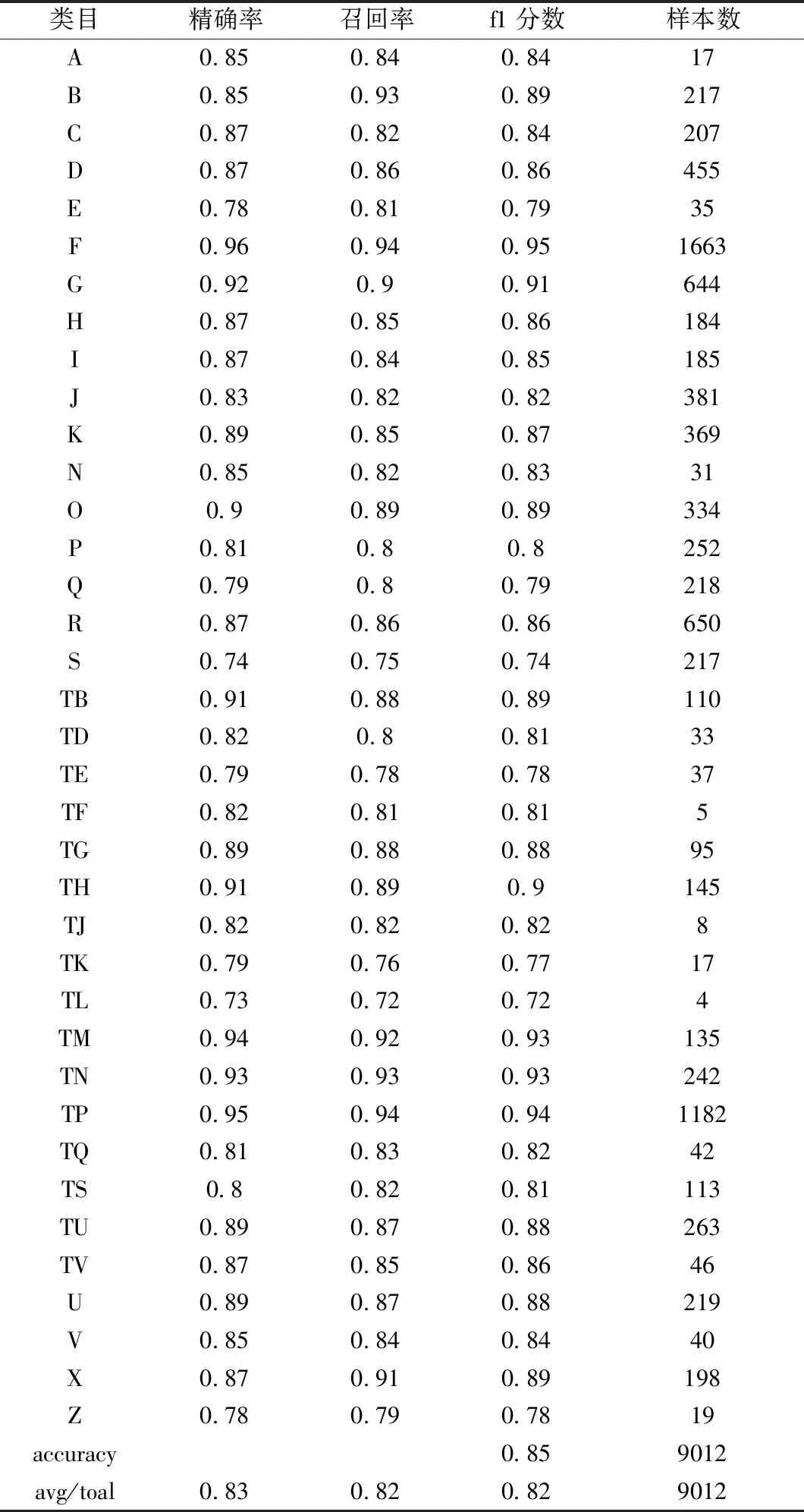
表1 模型評估指標(biāo)Tab.1 Indexes of model evaluation
由表1可見,模型的精確率平均達(dá)到0.83,召回率平均達(dá)到0.83,F(xiàn)1分?jǐn)?shù)平均值為0.82,超過80%。TE、TK、TL、Z各項指標(biāo)低于0.8,一方面是因為分類的訓(xùn)練數(shù)據(jù)少,模型學(xué)習(xí)不充分;另一方面是因為錯誤分類涉及多個主題,機(jī)器無法識別。總體上,模型準(zhǔn)確率為0.85,達(dá)到預(yù)期目的。
3.6 比較試驗
采用邏輯回歸(Logistic Regression)、隨機(jī)森林(Random Forest Classifier)、樸素貝葉斯(Multinomial NB)與SVM進(jìn)行對比實驗,不同模型對比實驗結(jié)果如表2所示。
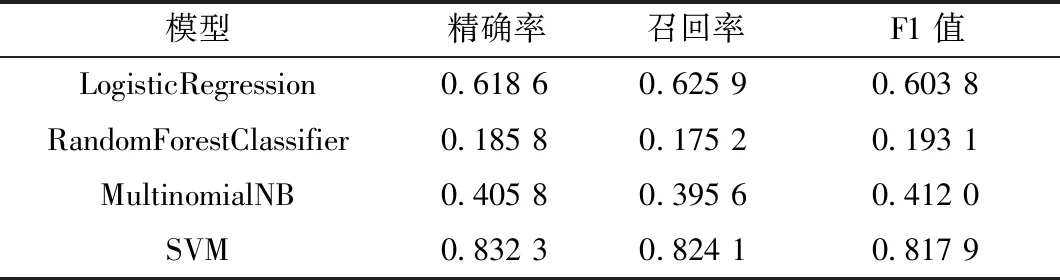
表2 不同模型試驗結(jié)果Tab.2 Results of different model tests
Logistic Regression形式簡單,難以擬合數(shù)據(jù)的真實分布;Random Forest Classifier限于訓(xùn)練集數(shù)據(jù)的驗證,在對特定噪聲的數(shù)據(jù)進(jìn)行建模時會出現(xiàn)過擬合;Multinomial NB需要知道先驗概率,由于假設(shè)的先驗?zāi)P蛯?dǎo)致預(yù)測效果不佳。如表2所示,SVM的各項評估指標(biāo)都高于其他模型。
4 結(jié)語
針對傳統(tǒng)分類標(biāo)引系統(tǒng)算法模型準(zhǔn)確率低、難以有效解決線性不可分?jǐn)?shù)據(jù)的分類問題,引進(jìn)了SVM模型,設(shè)計了基于SVM的書目數(shù)據(jù)智能分類檢測系統(tǒng),以西安航空學(xué)院圖書館書目數(shù)據(jù)為樣本,通過數(shù)據(jù)預(yù)處理、TF-IDF特征提取、chi2特征降維、LinearSVC建模等完成分類器的初次訓(xùn)練,在測試集上完成分類器的性能評估,并與邏輯回歸、隨機(jī)森林、樸素貝葉斯進(jìn)行對比實驗。實驗結(jié)果表明,召回率為0.82,f1分?jǐn)?shù)為0.82,精確率為0.83,準(zhǔn)確率為0.85,高于其他機(jī)器學(xué)習(xí)模型,精度較高,泛化能力較強(qiáng),具有良好的適用性。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
