基于YOLOv8n的交通標志檢測研究
2025-02-23 00:00:00宋京京吳章福
物聯網技術 2025年4期




摘 要:針對傳統交通標志檢測算法識別精度較低、受環境因素影響較大等問題,提出一種基于YOLOv8n的交通標志檢測算法。為解決卷積運算帶來的參數共享問題,利用感受野注意力(RFA)機制為每個卷積核滑窗生成不同的特征權重,并通過坐標注意力(CA)獲取長距離信息,以加強網絡對全局與局部信息的關注度;同時引入聚焦邊界框自身形狀與尺度的Shape-IoU損失函數計算預測框回歸損失。在GTSDB數據集上進行驗證實驗。實驗結果表明,相較于基礎模型,改進后的模型平均精確度達到了94.8%,參數量僅為3.210 MB,能夠滿足實時檢測標準,適用于復雜交通場景下的交通標志檢測任務。
關鍵詞:YOLOv8n;交通標志;實時檢測算法;Shape-IoU損失函數;RFA機制;GTSDB數據集
中圖分類號:TP391.4 文獻標識碼:A 文章編號:2095-1302(2025)04-00-04
0 引 言
交通標志檢測算法作為智能駕駛系統的重要組成部分,可以為行駛車輛提供前方道路的交通標志信息,以保障道路交通安全。因此,精確且高效的交通標志檢測算法可以極大地減少交通事故的發生,對于實現智能駕駛與交通調控具有重要意義[1]。
交通標志檢測可以分為基于傳統方法與基于深度學習的方法。基于傳統方法的交通標志檢測算法根據目標的顏色、形狀等人工提取圖像特征,再通過分類器將目標分類。手工提取的特征無法表達目標的深層語義,使得傳統方法的精確度較低。卷積神經網絡(Convolutional Neural Network, CNN)的發展,讓目標檢測的性能得到極大提高,使得基于深度學習的交通標志檢測算法逐步取代了傳統檢測算法。基于深度學習的目標檢測算法可以分為單階段與雙階段算法。雙階段算法通過區域候選網絡(Region Proposal Network, RPN)提取可能存在物體的候選區域,再對每個候選區域的目標進行定位與識別,通常具有更高的檢測精度,如R-CNN與Faster R-CNN算法[3-4]等。單階段算法能夠直接由輸入圖像得到目標物體的類別與位置信息,通常具有更快的檢測速度,如SSD和YOLO系列算法[4-5]等。YOLO算法為經典的單階段算法之一,采用端到端的卷積神經網絡模型,相較于雙階段算法,更適用于實時性較高的應用場景。2023年,Ultralytics發布YOLOv8版本,進一步提高了模型的檢測準確性。YOLOv8可以完成分類、分割與姿態估計等任務。通過調整網絡寬度與深度,YOLOv8可以分為YOLOv8n、YOLOv8s、YOLOv8m、YOLOv8l和YOLOv8x。這些不同大小的模型,能夠更好地權衡精度與速度,從而高效完成檢測。
與其他目標檢測任務相比,交通標志檢測通常需要算法具有更強的小目標檢測性能,且由于交通標志的應用場景復雜多樣,光照與氣候條件也會對算法的檢測效果造成不同程度的影響,導致交通標志檢測時存在較多的漏檢與誤檢情況。
針對上述問題,本文提出了一種改進YOLOv8n的交通標志檢測算法。該算法主要工作如下:
(1)使用CA注意力使網絡關注顯著特征,并通過RFA模塊彌補CA注意力的不足,使注意力圖無需在卷積核滑窗間共享參數;
(2)采用Shape-IoU計算邊界框回歸損失,綜合考慮邊界框自身的尺寸與形狀。
1 改進YOLOv8n算法
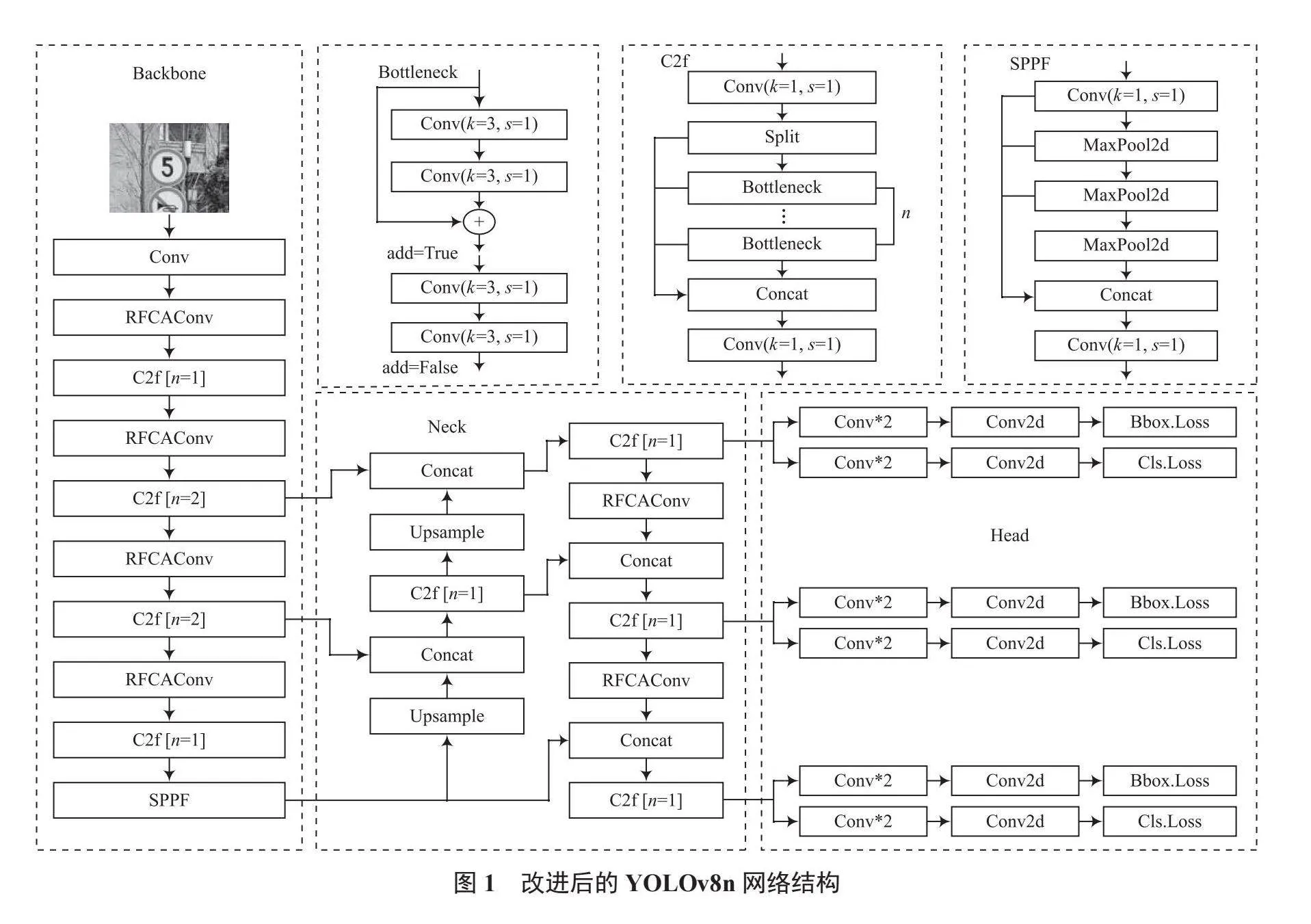
YOLOv8網絡主要由3個部分組成:特征提取網絡(Backbone)、特征融合網絡(Neck)與檢測頭(Head)。相比于YOLOv5,YOLOv8將C3模塊替換為C2f模塊,使模型獲得更豐富的梯度流信息;其次,YOLOv8使用解耦頭(Decoupled Head)與Anchor-Free策略,且不再有之前的Objectness分支;再次,YOLOv8使用二進制交叉熵損失作為分類損失,使用DFL(Distribution Focal Loss)與CIoU作為邊界框回歸損失;最后,YOLOv8采用Task-Aligned Assigner動態分配策略,能夠動態地調整正負樣本的分配比例,以適應不同的任務和數據分布。考慮到YOLOv8不同模型的訓練時間與檢測效果,本文對YOLOv8n網絡進行改進。改進后的YOLOv8n網絡結構如圖1所示。
1.1 RFCAConv模塊
卷積運算作為卷積神經網絡的基本運算,雖然能夠極大地提升深度學習模型在計算機視覺方面的性能,但也存在著許多局限性。如一味地增加網絡深度,并不會提升模型性能,反而會出現退化現象。在降低模型計算開銷和復雜性的同時,卷積計算中的參數共享策略也限制了網絡的性能。
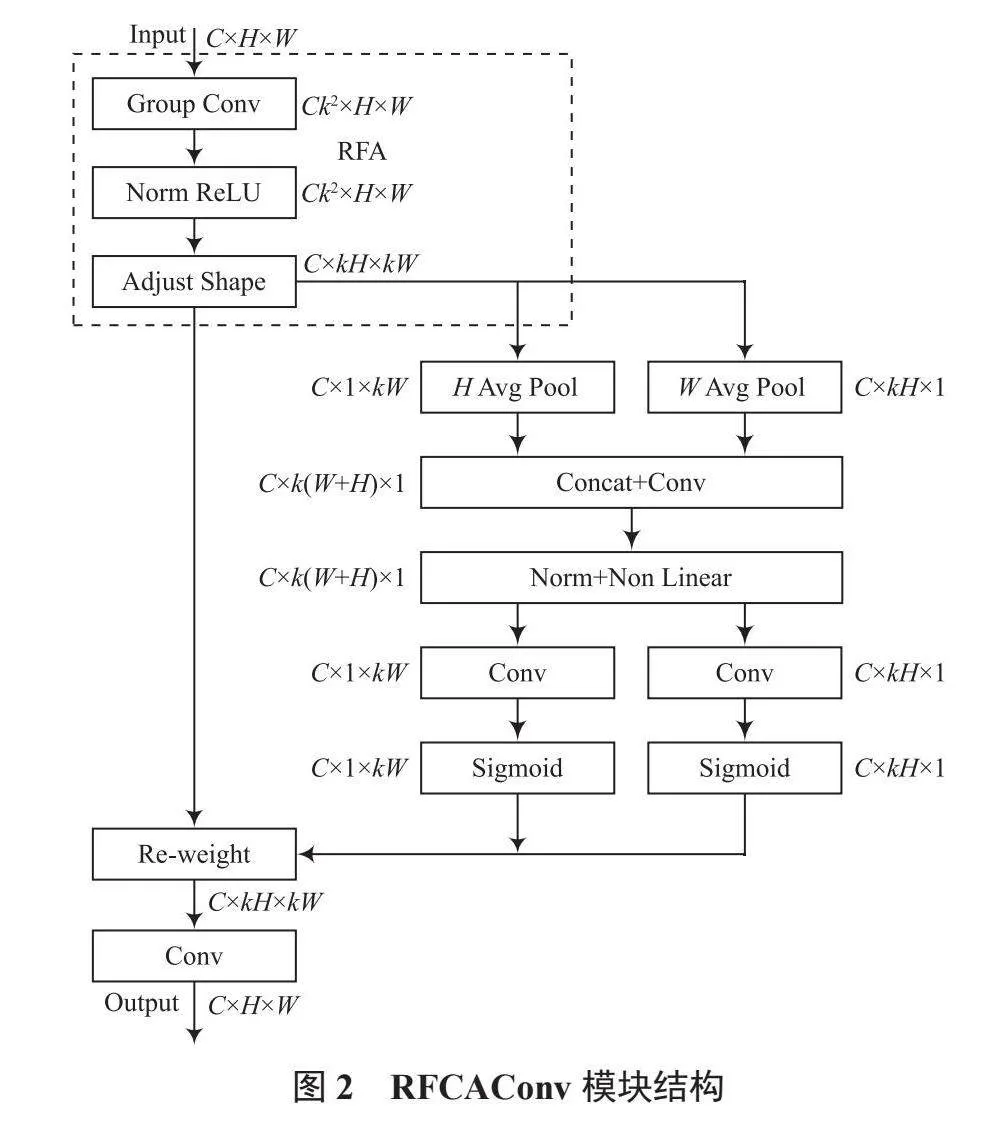
針對CNN的內在局限性,注意力機制是很好的解決方法。注意力機制的屬性使網絡能夠集中于顯著特征,進一步提升模型捕獲深層語義特征的能力。雖然現有的空間注意力機制已經可以很好地解決卷積運算中參數共享的問題,如卷積塊注意力模塊(Convolutional Block Attention Module, CBAM)和CA(Coordinate Attention)等。但面對較大卷積核運算時,它們無法強調感受野中每個特征的重要性,仍會存在參數共享問題。為全面解決參數共享問題,提升模型關注度,本文引入了感受野注意力(Receptive-Field Attention, RFA)[9],并將其與CA [10]結合為RFCAConv模塊。RFCAConv結構如圖2所示。
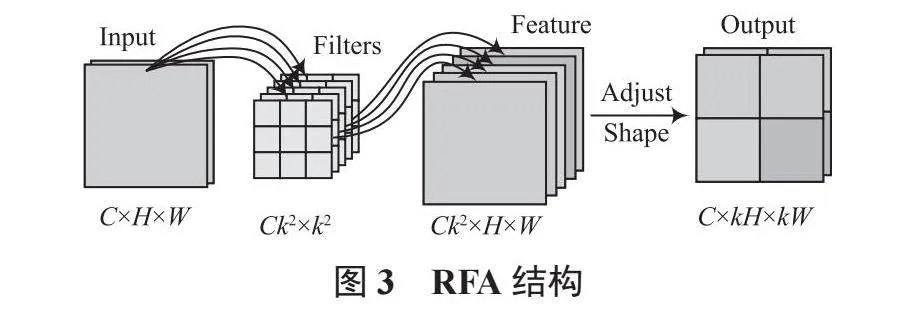
RFCAConv模塊首先通過RFA獲取感受野空間特征,再使用CA獲取全局信息與長距離信息,最后聚合注意力圖與空間特征圖,使網絡學習到感受野滑塊內不同特征的重要性。RFA結構如圖3所示。RFA主要由分組卷積與形狀調整部分組成。分組卷積的輸入通道數為C,卷積核大小為k,輸出通道數為Ck2。RFA將輸入特征圖分為C組,以最小化計算開銷和參數數量。形狀調整部分通過拼接特征圖,使通道數減小k2倍,特征圖尺寸增加k倍,從而使每個卷積核滑窗都有與之對應的注意力權重。將普通卷積替換為RFCA模塊能夠消除卷積運算中的參數共享問題,使網絡關注到每個感受野內的空間特征。
1.2 Shape-IoU損失函數
計算邊界框回歸損失是目標檢測中的重要步驟。一個良好的回歸損失函數能夠更準確地定位目標位置。YOLOv8網絡使用CIoU[11]作為回歸損失。CIoU的表達式如下:
(1)
(2)
式中:ρ(b, bgt)表示兩框中心點之間的歐氏距離;c表示最小外接矩形的對角線長度;v表示長寬比的一致性;α表示權重參數。
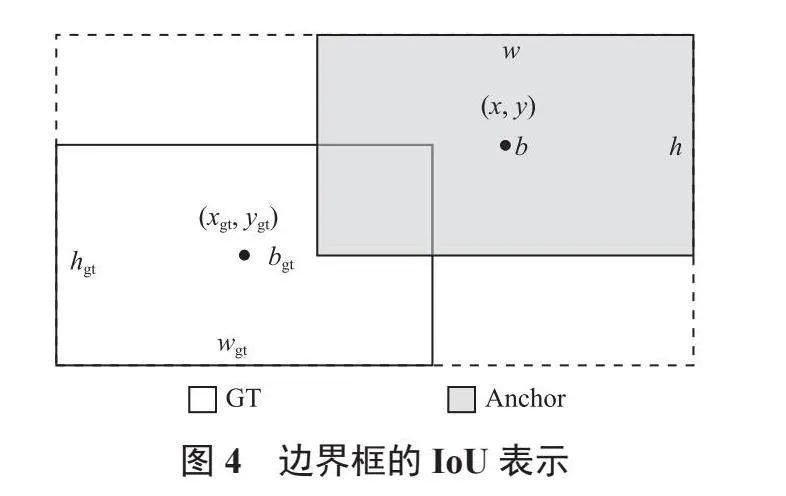
CIoU雖然考慮了邊界框回歸的重疊面積、中心點距離與縱橫比,使訓練過程更加穩定,但是式(1)的v反映的為相對值,而非絕對值,且CIoU忽略了邊界框自身的形狀與尺度等固有屬性對回歸的影響。因此本文引入Shape-IoU[12]替代CIoU,如圖4所示。其表達式為:
(3)
(4)
(5)
(6)
(7)
式中:ww與hh分別表示水平和豎直方向的權重系數。與CIoU相比,Shape-IoU聚焦了邊界框自身的形狀與尺度,可以適應重疊或非重疊的邊界框回歸,有效提高了邊界框的回歸性能。
2 實驗結果與分析
2.1 實驗環境與配置
本文實驗基于Windows 11操作系統,計算機配置為CPU13th Gen Intel? CoreTM i7-13700H、GPUNVIDIA RTX 4060,顯存8 GB。實驗采用PyTorch框架搭建深度學習環境,在Pycharm平臺上完成模型的訓練與測試,采用Mosaic進行數據增強,其中epoch為300,batch size為8,同時在訓練過程中不使用預訓練權重。
2.2 實驗數據集與評價指標
本文選用GTSDB作為實驗數據集。GTSDB為德國交通標志數據集,樣本選自德國不同自然條件下的街道場景圖像,共包含圖片900張,含有指示(Mandatory)、禁令(Prohibitory)、危險(Danger)及其他(Others)3大類交通標志,圖片分辨率為1 360×800。將數據集按8∶1∶1的比例劃分為訓練
集(約599張)、驗證集(約67張)與測試集(75張)。
本文采用不同的性能指標對各模型進行對比分析,如平均精確度(mAP50)、每秒檢測幀數(FPS)與參數量等。其中mAP50表示IoU的閾值為0.5時,所有類別的平均精確度。AP為單個類別的平均精確度,通過精確度(Precision)與召回率(Recall)曲線計算而來。其表達式為:
(8)
(9)
(10)
式中:TP為正樣本被正確分類的數量;FP為負樣本被錯誤分類的數量;FN為正樣本被錯誤分類的數量。
2.3 實驗設計及結果分析
2.3.1 對比實驗
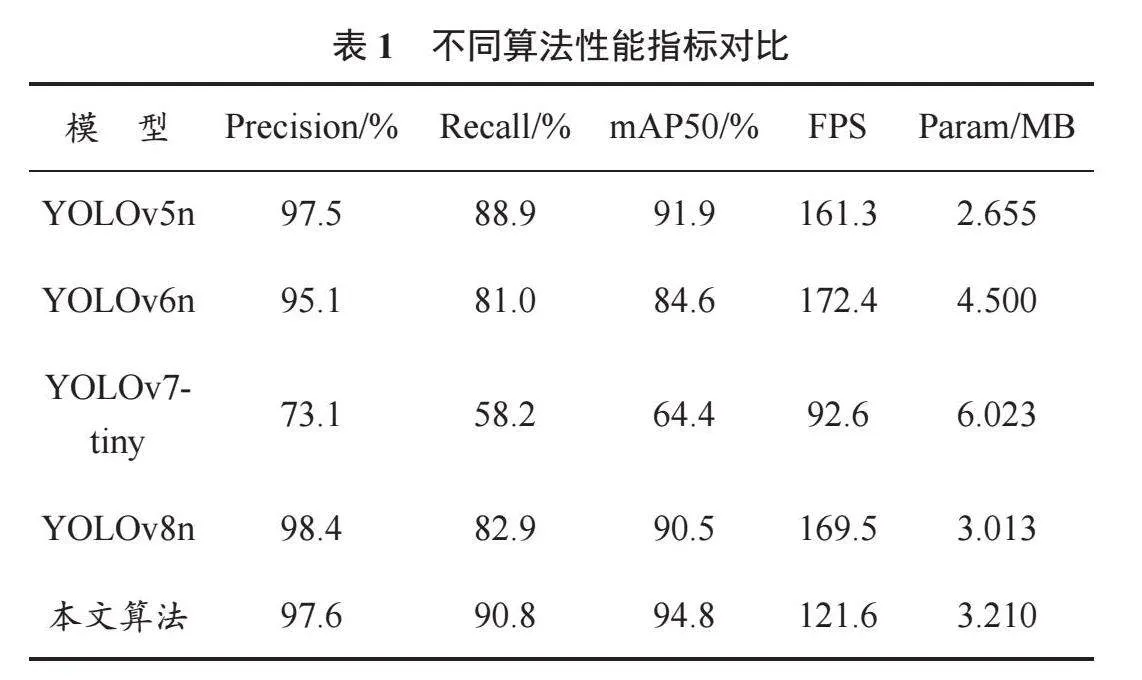
為驗證改進算法的檢測性能,本文將YOLOv5n、YOLOv6n、YOLOv7-tiny、YOLOv8n模型與本文算法置于相同的實驗環境下[5-8],在數據集GTSDB上進行對比分析。不同算法性能指標對比見表1。
根據表1可知,相比于其他模型,本文算法在GTSDB數據集上的Precision、Recall與mAP50均有提升;雖然參數量略微增加,但識別精度比參數量最低的YOLOv5n提升了2.9個百分點,比基線模型提升了4.3個百分點,達到了94.8%;改進算法的FPS已滿足實時監測需求。這表明本文算法檢測性良好,具有較好的特征提取與目標定位能力,能夠強調網絡中的目標特征,提升交通標志檢測精度。
2.3.2 消融實驗
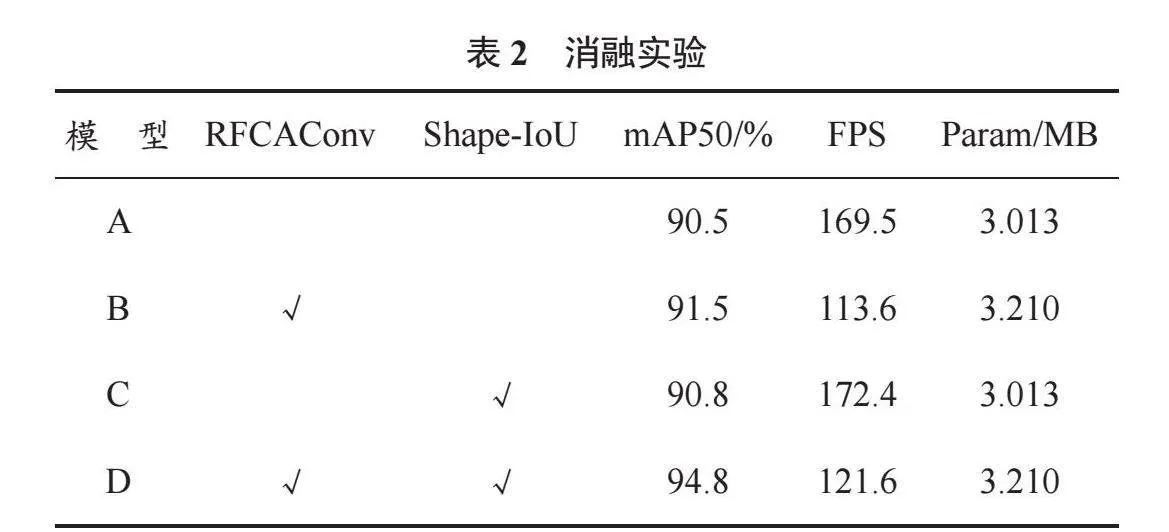
為驗證本文模型中改進方法的有效性,本文設計了一組消融實驗。在YOLOv8n網絡中添加不同的改進方法,以相同策略在數據集GTSDB上進行訓練與測試,見表2。
表2中,模型A為YOLOv8n原模型,“√”表示在原模型基礎上添加對應的改進方法。根據表2可知,在分別添加兩種改進方法后,模型檢測精度均有提升。其中,使用RFCAConv模塊替換普通卷積有效解決了參數共享問題,使mAP提升了1個百分點;引入損失函數Shape-IoU進一步優化邊界框回歸損失,使mAP提升了0.3個百分點;同時添加兩種改進方法時提升效果最明顯,mAP達到了94.8%。上述測試驗證了本文改進方法的有效性,表明本文改進方法能夠有效增強模型對目標特征的感知能力。
2.3.3 算法可視化分析
為了更加直觀地分析算法改進后的檢測效果,使用YOLOv8n與本文算法的權重模型對GTSDB測試集進行推理,并選取其中1組具有代表性的圖片進行分析,如圖5所示。
在圖5中,不難發現圖片中的標志均為遠距離小目標,且光線較暗也加大了檢測難度,導致YOLOv8n對圖中的兩個標志均未識別成功,其中一個被漏檢,另一個則被誤檢為禁令標志;而在本文算法的檢測結果中,兩個交通標志均被正確定位與分類,表明本文算法檢測性能良好。可視化分析驗證了本文算法出色的小目標信息拾取能力。
3 結 語
為進一步提高交通標志檢測算法的準確性,盡可能保障道路行駛安全,本文提出了一種改進YOLOv8n的交通標志檢測算法。該算法以YOLOv8n為基礎網絡,使用RFCAConv模塊,提高了網絡對遠距離小目標的關注能力,在復雜環境下有效提取了目標特征信息,同時采用Shape-IoU損失函數,聚焦邊界框自身固有屬性,提升了模型泛化能力。本文在GTSDB數據集上進行實驗,使改進模型的檢測精度提高了4.3個百分點,檢測速度達到了121.6 FPS。與原算法相比,本文算法更適用于復雜交通場景下的交通標志檢測任務。
參考文獻
[1] JIA X, TONG Y, QIAO H, et al. Fast and accurate object detector for autonomous driving based on improved YOLOv5 [J]. Scientific reports, 2023, 13(1): 1-13.
[2] GIRSHICK R, DONAHUE J, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [J]. IEEE conference on computer vision and pattern recognition, 2014, 81(1): 582-587.
[3] REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [J]. Advances in neural information processing systems, 2016: 1137-1149.
[4] LI Z, ZHOU F. FSSD: feature fusion single shot multibox detector [EB/OL]. (2024-02-23). https://doi.org/10.48550/arXiv.1712.00960.
[5]方強,涂振宇,相敏月,等.一種基于輕量化YOLOv5的PCB缺陷檢測研究[J].物聯網技術,2023,13(8):15-19.
[6] LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications [EB/OL]. (2022-09-07). https://doi.org/10.48550/arXiv.2209.02976.
[7] WANG C Y, BOCHKOVSKIY A, MARK LIAO H Y. YOLOv7: trainable bag-of-freebies sets new state-of-the-art for real-time object detectors [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver, BC, Canada: IEEE, 2023: 7464-7475.
[8] ZHANG L J, FANG J J, LIU Y X, et al. CR-YOLOv8: multiscale object detection in traffic sign images [J]. IEEE access, 2023, 12: 219-228.
[9] ZHANG X, LIU C, YANG D, et al. RFAConv: innovating spatial attention and standard convolutional operation [EB/OL]. (2024-03-28). https://doi.org/10.48550/arXiv.2304.03198.
[10] HOU Q, ZHOU D, FENG J. Coordinate attention for efficient mobile network design [C]// 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA: IEEE, 2021: 13713-13722.
[11] ZHENG Z, WANG P, REN D, et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation [J]. IEEE transactions on cybernetics, 2021, 52(8): 8574-8586.
[12] ZHANG H, ZHANG S. Shape-IoU: more accurate metric considering bounding box shape and scale [EB/OL]. (2024-01-12). https://doi.org/10.48550/arXiv.2312.17663.
