基于隱性句逗號識別的漢語長句機器翻譯
2025-01-26 00:00:00馮文賀李熳佳張文娟
外語學刊 2025年1期


提 要:長句翻譯一直是機器翻譯的難題。本文根據漢語中相當數量的逗號和句號可相互轉化的特點,提出“隱性句號”和“隱性逗號”概念,并實現其自動識別,以將漢語長句變為短句用于漢英機器翻譯。為此,首先通過人工與半監督學習結合方法構建一個隱性句逗數據集,實現基于預訓練模型的隱性句逗識別方法,其中性能最好的Hierarchical BERT作為后續應用模型。進而,實現基于隱性句逗識別的漢英機器翻譯方法。在新聞和文學公開翻譯測試語料上基于預訓練機器翻譯模型的實驗表明,對于漢語長句的英譯,本文方法相比基準翻譯的BLEU值整體有所提高,而且在相對穩健機器翻譯模型上,呈現為句子越長本文方法效果越明顯。
關鍵詞:機器翻譯;長句翻譯;隱性句逗號;漢語長句;逗號識別;句內標點
中圖分類號:H08 """"文獻標識碼:A """"文章編號:1000-0100(2025)01-0039-8
DOI編碼:10.16263/j.cnki.23-1071/h.2025.01.005
Machine Translation of Chinese Long Sentences Based on
Recognition of" Implicit Period and Comma
Feng Wen-he1 Li Man-jia1 Zhang Wen-juan2
(1.Lab of" Language Engineering and Computing, Center for Linguistics and Applied Linguistics,
Guangdong University of" Foreign Studies, Guangzhou 510420, China; 2.School of Computer Science and
Engineering, Guangzhou Institute of" Science and Technology, Guangzhou 510420, China)
The translation of long sentences has always been a difficult task for machine translation. In this paper, based on the feature that a considerable number of commas and periods" in Chinese text can be transformed into each other, we propose the concepts of" “implicit period” and “implicit comma”, and realize their automatic recognition to transform Chinese long sentences into short sentences for Chinese-English machine translation. In this paper, a dataset of implicit period and comma is constructed by combining manual and semi-supervised learning methods, and an implicit period and comma recognition method is realized based on a pre-trained model, in which Hierarchical BERT, which has the best performance, is used as the subsequent application model. In this paper, a Chinese-English machine translation method based on implicit period and comma recognition is realized. The experiments based on pre-trained machine translation models on the News" and Literature corpus show that for the English translation of Chinese long sentences, the method in this paper improves the BLEU value compared to the benchmark translation as a whole, and the effect of the method in this paper is more obvious the longer the sentence is for the relatively robust machine translation model.
Key words:machine translation; long sentence translation; implicit period and comma; Chinese long sentence; recognition of comma; intra-sentence punctuation
1 引言
篇章翻譯是當前制約機器翻譯技術性能的一個突出問題,其困難集中體現于長句翻譯上(Koehn, Knowles" 2017)。原因在于長句一般由多個小句(clause)構成,而不同語言的小句及其間結構差異巨大。如表現在漢英語言間,漢語小句無系統的語法主從之別,長句多流水句,小句間“可斷可連”(呂叔湘 1979:27),反映在標點上即逗號(句內標點)、句號(句間標點)可相互轉換,句子邊界相對模糊;而英語小句則有系統的語法主從之別,句號、逗號分明,相互轉化性弱,句子邊界相對清晰(趙朝永 王文斌 2020,馮文賀" 李青青 2022)。句子邊界差異自然引發雙語長句的翻譯問題。長句機器翻譯困難也有其計算機制的原因。如對于基于循環神經網絡的翻譯模型(Sutskever et al. 2014),長句會造成更多長距離依賴關系需要維護,以致難以記住大量上下文信息;對于基于注意力機制的翻譯模型(Vaswani et al. 2017),長句會造成注意力分散到更多信息點,以致難以持續聚焦于最關鍵信息。
對于長句翻譯問題,一種解決思路就是將其化為短句翻譯。問題是如何將長句合理化為短句。本文認為,可從漢語句逗號中有大量可相互轉化而又不影響原義表達的特點入手,解決漢語長句的翻譯問題。例如:
(1) a. "①少年姓孫,②屬馬[,]③比小水小著一歲,④個頭也沒小水高,⑤人卻本分實誠。(賈平凹《浮躁》)
b. ①This boy,a member of Sun Family, ②was born in the year of the horse[.] ③Although he was a year younger ④and a head shorter than water girl, ⑤he was honest and sincere.(Goldblatt 1991)
c. ①The young Sun, ②a horse③, is one year younger than Xiaoshui, ④and the individual is no higher than Xiaoshui, ⑤but the person is sincere.(有道翻譯 2023.11.18)
d. ①The young man’s surname is Sun," ②he was born in the year of the horse, ③and is one year younger than Xiao Shui. ④He is not as tall as Xiao Shui, ⑤but he is honest and earnest.(ChatGPT4 2023.12.10)①
例(1)a漢語復句包含5個小句。語義主題上,小句①②描述少年的個人特征;小句③④和小句⑤雖然也描述少年的個人特征,但相比卻有了對比人物“小水”。據此,前兩個小句和后3個小句所表達語義主題有所差異,其間語義關系也遠近有別。也因此,可將小句②后逗號改為句號,而且原文小句間的語義關系遠近及具體邏輯語義等不變。本文將此類可轉化為句號而不改變原文小句間語義關系遠近及邏輯語義的逗號視為“隱性句號”。同理,漢語文本中也存在句號可變為逗號的情況,本文將此類句號視為“隱性逗號”。
將漢語長句變為短句,相比可以實現更好翻譯。如專業譯者(例(1)b)在小句②后斷句翻譯,更好翻譯表達了源語小句間的語義遠近關系,句子的內部結構也更符合英文習慣。相比之下,機器譯文例(1)c中句逗號與源語一致,小句間的語義關系不明,句子結構也顯得冗長,不符合英文結構習慣。但是,如果不能恰當地化長句為短句,也可能導致不良翻譯。如機器譯文例(1)d中在小句③后斷句翻譯,根本上改變源語小句間的結構關系,其中割裂了小句③④間密切的并列關系(由連接詞“也”表示),隔斷了小句⑤對小句③④整體的轉折關系(由此也導致譯文連接詞but不能準確翻譯原文連接詞“卻”的管轄范圍)。可以說,長句化短后翻譯,在根本上會影響句子內外的結構組織,影響是全局性的。
本文認為,如果能夠識別漢語文本中隱性句逗號,就可能將相當一部分長句經切分重組為較短句子,而經此處理后再進行機器翻譯,就可能達到更好的翻譯效果。基于此,本文提出基于隱性句逗號識別的漢語長句機器翻譯方法。為此,本文首先構建漢語隱性句逗號數據集,并實現其識別模型;進而將隱性句逗號識別模型用于機器翻譯的漢語源語數據預處理,以使機器翻譯獲得更好的長句翻譯效果。
2 相關工作
現有機器翻譯模型處理短句表現良好,但對于長句,往往無法給出優質翻譯。為改善長句翻譯效果,主要進行了兩類研究:一類是進行篇章級機器翻譯建模,綜合解決包括長句在內的篇章翻譯問題;另一類是專門針對長句的機器翻譯研究。
在篇章機器翻譯建模研究中,一般既關注句內詞語間結構關系,也關注上下文句子間的一致性、連貫性、結構層次、銜接性等信息(Tan et al. 2019;Chen et al. 2020;Guo et al. 2022; 賈愛鑫等 2024)。由于更多關注上下文,一定程度上有利于緩解長句翻譯問題。在篇章機器翻譯建模中,有研究特別注意到句長的影響。如研究指出篇章級機器翻譯中源語和目標語的句長偏差會導致翻譯質量下降;提出動態采樣訓練數據,以確保不同序列長度可均勻分布;引入長度歸一化注意力機制,以使模型聚焦于目標信息,緩解處理較長序列時的注意力偏離問題;提出在解碼過程中采用滑動窗口策略,以在不超過最大序列長度的前提下整合更多上下文信息(Zhang" et al. 2023)。然而,根本上篇章機器翻譯建模并不著重于解決由于(漢英)雙語句子邊界差異帶來的長句翻譯問題。
在專門針對長句的機器翻譯研究中,一般將長句化為較短的語言單位再翻譯。在傳統機器翻譯(基于規則、基于統計)下,不同語言的翻譯上均有研究嘗試將長句劃分為較短的語言單位再翻譯,一般是利用一些語言特征,如句法模板、結構層次、小句、連接詞、標點等,將長句劃分為較短的短語、小句、結構片段等后,先翻譯較短單位后再進行組合(Oliveira et al. 2010;Goh, Sumita" 2011;Yin et al. 2012;Hung et al. 2012;Pouget-Abadie et al. 2014)。在漢英翻譯中,也有一些研究嘗試利用標點符號、關系代詞、層次結構等長句劃分為簡單句、子句等后再進行翻譯(黃河燕 陳肇雄 2002;李幸" 宗成慶 2006;Xiong et al. 2009)。在神經機器翻譯(NMT)技術框架下,也有研究考慮將長句化短后分別翻譯再組合。如有研究在漢英翻譯中引入一個拆分和重新排序模型來共同檢測源語長句的最佳分割點序列,進而將每個源語子句由NMT系統獨立轉換為目標子句,并將翻譯的目標子句連接起來形成長句的最終翻譯(kuang, Xiong 2016)。有研究提出雙語短語提取方法,以構建雙語短語對齊語料庫,并實現了一種長句預處理技術,以切分長句為短語,解決長句翻譯問題(Tien, Minh 2019)。長句分割與句子邊界相關,有研究發現句子邊界分割對口語翻譯質量影響顯著,提出一種數據增強策略,即在訓練過程中將模型暴露于各種邊界分割錯誤中,以提高NMT系統對句子邊界分割錯誤處理的魯棒性和機器翻譯的準確性(Li et al. 2021)。然而這些研究只是一般地將長句化為較短的語言單位再翻譯,而不考慮長句化短后是否改變了源語長句內外,小句間語義關系的遠近與邏輯類別等。但事實上,隨意切斷長句后翻譯可能導致原文小句間的邏輯語義結構的改變,如例(1)d的譯文。為此,本文基于漢語部分句逗號可相互轉化的特點,提出“隱性句逗號”概念,實現其機器識別,并用以解決漢語長句的機器翻譯難題,其中特別關注長句內外小句間語義關系的遠近與邏輯類別等是否得到了準確翻譯。
3 隱性句逗號識別
本文構建了漢語隱性句逗號數據集,并實現了基于預訓練語言模型的隱性句逗號識別方法。考慮到原始文本中句逗號的數據不平衡(句號少,逗號多),及相應隱性句逗號的不平衡,和預訓練語言模型中本身句逗號知識的不平衡,本文專門構建了一個只包含隱性句逗號的數據集。基于該數據集上,我們訓練實現了最優隱性句逗號識別模型,該模型可以相對集中地反映隱性句逗號的特征差異。在機器翻譯中,該模型將用于預處理源語漢語文本,由于該模型并未關注真句逗號,其識別結果將與現實文本中的句逗號進行一致性對比調正后作為源語文本預處理結果,輸入機器翻譯模型進行翻譯。
首先,本文構建了隱性句逗號數據集。在不同體裁(含政府工作報告、法律文本、新聞、小說、學術等)的漢語文本(其中一部分來自經典漢英翻譯的平行語料)上人工標注一定規模隱性句逗號數據;然后通過self-training半監督學習方法大規模擴充數據集。人工標注由漢語母語者實施,通過兩種方式實現。第一,標注者根據母語者的語感直接對漢語文本標注。基本判斷標準:句逗號相互轉變后,語法合理、且不改變原句所含邏輯語義關系的,為隱性句逗號。第二,參照漢英翻譯標注。標準為:在經典漢英翻譯平行語料上,如果英譯文本為句號斷句,而漢語文本的對應標點處為逗號,則認定該漢語標點為隱性句號;隱性逗號的確定方法同理。具體做法如表1所示,其中紅色標注出隱性句逗號,連同其左右各一個標點句(用S1、S2等標注)(宋柔 2022)構成一條數據。如其中的隱性句號數據由S3-S4構成,隱性逗號數據由S3-S4構成。最終,人工標注共3,100條隱性句逗號樣本,其中包含1,847條隱性句號標注,1,253條隱性逗號標注。
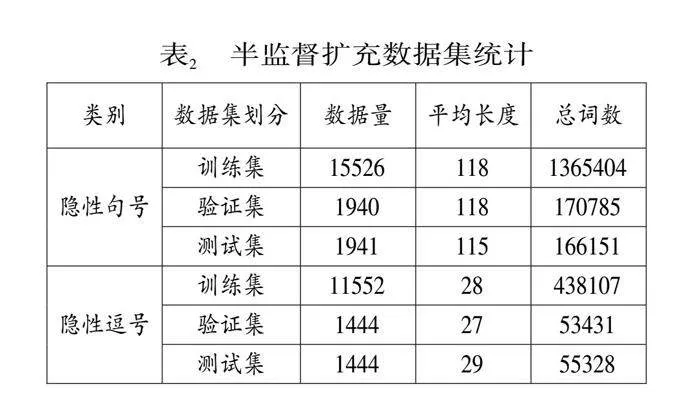
隨后,采用了self-training半監督學習方法(Du et al. 2021)大規模擴充數據集。先將這些標注樣本作為初始數據,然后構建一個基礎模型在已有人工標注數據上進行訓練,使得模型能夠學習到隱性句逗號的標注邏輯和文本特征。接著,利用訓練好的模型對未標注數據進行推斷,生成偽標簽。當模型輸出的標簽概率高于設定閾值時,將其作為新的標簽數據,擴充至初始數據中。通過該方式,最終構建了一個包含33,847條數據的隱性句逗號數據集,其中隱性句號19,407條,隱性逗號14,440條。識別實驗中,將該數據集按照8:1:1的比例切分為訓練集、驗證集和測試集。具體統計結果如表2所示。
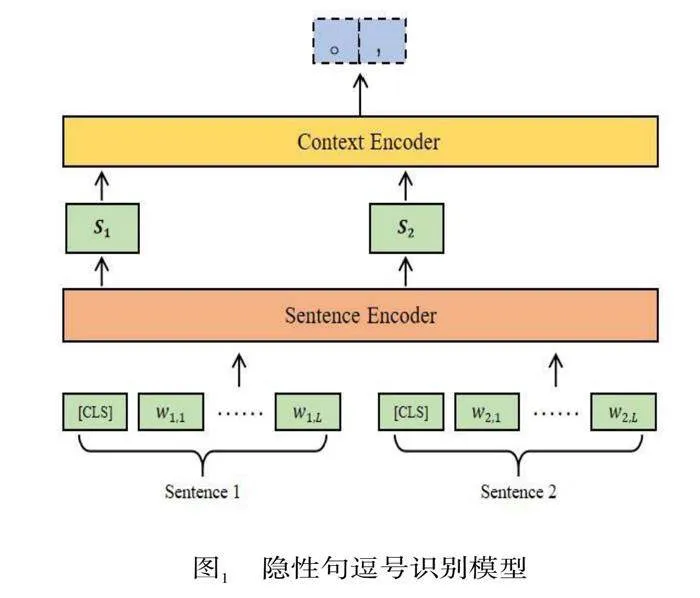
其次,本文提出基于預訓練語言模型的隱性句逗號分類識別方法。為充分考慮隱性句逗識別中相關語段特征,具體采用Hierarchical BERT模型(Lukasik et al. 2020)對句子對進行編碼。如圖1所示,其包含嵌入層、Sentence Encoder、Context Encoder層,模型輸出為隱性句逗號的預測結果。其中Sentence Encoder使用BERT預訓練模型(Devlin et al.2019),Context Encoder使用GRU模型。模型的輸入為兩段文本,分別表示為Sentence1和Sentence2,此處并不是直接拼接兩個句子,而是將其層次化并行輸入模型。隨后Sentence Encoder將學習每個Sentence句內的局部特征并聚合至對應的[CLS]向量中;將兩個Sentence的[CLS]表征輸入到Context Encoder層中,該層可賦予文本前后的順序特征以及上下文關系特征,并最終得到文本對的全局特征。全局特征通過線性分類層,將輸出映射到隱性句逗的類別標簽上,其中線性分類層通過Softmax函數對輸出的概率進行歸一化,并利用交叉熵損失函數計算損失。
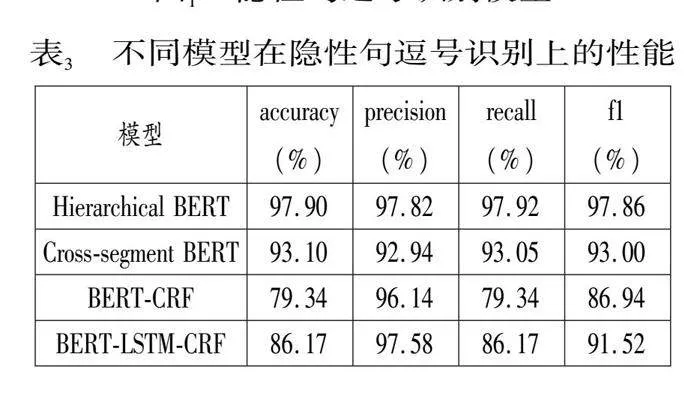
最后,進行隱性句逗號識別實驗。除基于Hierarchical BERT模型外,我們也進行了基于Cross-segmen BERT模型(Wicks, Post 2021)的方法。與此同時,我們還對比實現了基于序列標注的方法,包括BERT-CRF(Liu et al.2020)、BERT-LSTM-CRF(Yang et al.2022)。各模型結果見表3。實驗表明,基于Hierarchical BERT模型的方法性能最佳。原因在于Hierarchical BERT相比可以充分學習到句逗號相關語段文本的詞匯、語序及上下文特征。而序列標注方法的問題在于,當前的隱性句逗號識別任務下相關數據是獨立的文本段,并非實際文本中的句逗號序列。基于Hierarchical BERT的隱性句逗號識別模型將用于后續機器翻譯漢語長句化短的預處理。
4 基于隱性句逗號識別的長句機器翻譯
4.1 本文方法模型
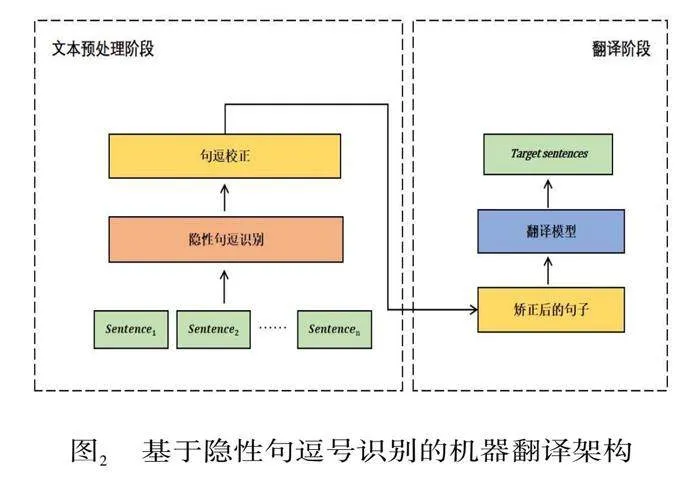
為驗證基于隱性句逗號識別的長句機器翻譯方案效果,本文使用PipeLine方案(Atrio et al. 2023)進行實現。首先,對源語漢語進行預處理,即進行隱性句逗號識別,并與源語文本的句逗號比對校正,確定最終句逗號;然后對預處理文本進行機器翻譯,如圖2。
模型所輸入的文本為一個句逗號切分的標點句序列(記為sentence1,2,……n)。為適配本文基于Hierarchical BERT的隱性句逗號識別模型,相鄰的兩個標點句組合作為一個輸入,經過識別模型,預測其間的標點位置為隱性句號或隱性逗號。由于隱性句逗號識別模型僅考慮了隱性句逗號,而實際文本中為所有句逗號(既包括隱性句逗號,也包括真句逗號),這里須對隱性句逗號模型識別結果進行校正,以獲得最終句逗標點。具體做法是:將隱性句逗識別模型輸出結果與原文結果進行比對,當模型輸出結果與原文一致,保留原文本標點;當模型輸出結果與原文本不一致,保留隱性句逗的識別結果。這樣做的原因在于,由于受預訓練語言BERT自身所包含的大量一般句逗號文本知識的影響,隱性句逗號識別模型并不能很好地從真實文本(包含所有句逗號)中識別出隱性句逗號。具體而言,當其標點分類結果與原文本不一致時,可以認為是,句逗模型增強了本文隱性句逗號知識后的結果,即為隱性句逗號;當其與原文一致,可以認為是BERT自身包含的大量真句逗號知識的結果。校正后的句逗標點文本,作為預處理結果輸入機器翻譯模型。
4.2 實驗設計
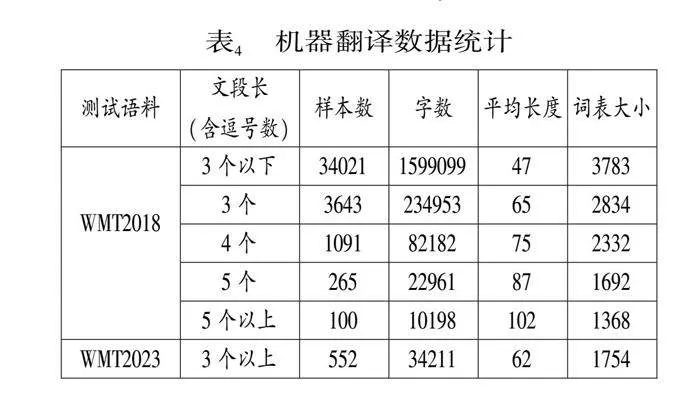
為驗證本文方案效果,本文在公開機器翻譯任務WMT2018的漢英翻譯(新聞)②和WMT2023中的漢英翻譯(文學)③的測試集上進行實驗。引入文學語料的考慮在于,文學文本是機器翻譯難點,而且文學文本相比一般文本口語性強,可逗可句或可斷可連的情況更突出,特別適于本文方法的驗證。為了充分驗證本文方法在漢語長句上的效果,進一步按照文本長度(以包含的逗號數計算)將數據集劃分如表4。如此考慮在于,逗號是句內標點,一個文本包含的逗號數越多,往往意味著其中的句子包含的小句越多,句子越長。
在翻譯階段,本文使用兩個表現優異的預訓練機器翻譯模型進行實驗,分別是opus-mt (Tiedemann, Thottingal 2020)和Randeng-mt(Zhang et al.2022)。二者均基于transformer的端到端架構,并基于大型中英平行語料庫訓練,包含了豐富的雙語知識。實驗中二者具體設置相同,主要是:設置束搜索寬度為2;采用多概率采樣;top_k為40,其可以在生成過程中過濾掉不太可能的詞,僅保留頭部的40個詞;top_p概率為0.8,其代表輸出詞的概率之和達到或超過0.8,才會在生成過程中保留;此外為確保模型不重復地連續輸出,限制了模型連續重復生成單詞的個數為5。
評估標準采用通用的BLEU值(Papineni" et al.2002)。其主要通過比較機器翻譯的輸出和參考譯文的n-gram相似度計算得出。BLEU值中n-gram的取值為4。另外,也進行了翻譯實例分析。主要對比分析標點修正前后機器翻譯對于小句間關系疏密的處理等。
4.3 實驗結果
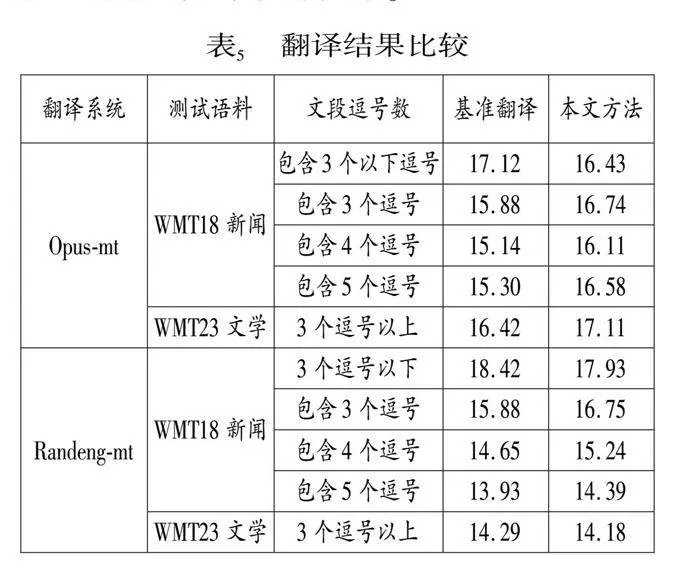
由實驗結果(表5)可見:
(1)隨著逗號增多,即句子包含的小句數增多,句長增大,機器翻譯效果變差,充分證明長句越長對機器翻譯的挑戰越大。
(2)在包含3到5個逗號的語段文本內,本文比基準方案的翻譯質量整體有所提高;其中在更穩健翻譯系統(Opus-mt)上,本文的BLEU值分別提高0.86、0.97和1.28,也即隨著源語文本長度的增加,本文的優勢更明顯。
(3)本文也適應于文學翻譯,在Opus-mt系統上,本文方法比基準模型提升0.69個BLEU值。一般認為文學翻譯難度大,主要是文學文本中更多人物對話和敘事,也更多涉及日常生活,內容容易理解,但也因此句子口語性強,結構更靈活,可斷可連的句子更多,句子邊界相比更模糊,翻譯斷句等難度更大。本文可為文學機器翻譯難題的解決提供一種特別思路。
(4)本文方法對于相對較短的句子(包含3個以下逗號的語段文本)翻譯,并沒有體現出優勢。這一方面反映出短句翻譯并非機器翻譯難題,另一方面也反映出本文方法也還未能更好識別真句逗號。這是因為隱性句逗號識別模型僅專注于隱性句逗號的識別,而暫時忽視了真句逗號的問題。這無疑需要在進一步工作中予以合理解決。
4.4 實例分析
表6分別給出了漢語原文與其機器翻譯結果和經本文方法修正標點后的漢語修正文本與其機器翻譯結果。
實例1 文本選自WMT2018的新聞文本。修正文本將S4后的逗號改為句號,修正后S3、S4、S5、S6間的關系遠近更清晰,邏輯語義更明確。對比修正文本翻譯與原文翻譯可以發現,修正文本翻譯更好地反映了S3與S4的關系,S5與S6的關系,而且相比原文翻譯語法結構也更合理。
實例2 文本選自WMT2023的文學文本。修正文本將S2后的逗號改為句號,將S3后的句號改為逗號,將S5后的逗號改為句號。修正后S3、S4、S5間的緊密關系得以凸顯,包括S3與S4的遞進性關系(都是“他們都認為”的內容,并且用“而”連接),S5與S3、S4間的因果性關系(由“因此”體現)。并S3-5與S1-2和S6-6的關系距離也相對拉開,顯得更清晰。對比修正文本翻譯與原文翻譯,修正文本翻譯較好地反映各S間關系的語義遠近與邏輯關系關系。
5 結束語
針對長句機器翻譯難題,本文提出基于隱性句號逗識別的漢語長句機器翻譯方法。本文首先構建了隱性句逗號數據集,并基于預訓練模型實現隱性句逗自動識別;進而將隱性句逗號識別模型作為翻譯數據預處理模塊與翻譯模型結合,以解決漢語長句翻譯難題。實驗結果顯示本文方法對長句的翻譯性能有顯著提升,而且長句越長效果越佳;這一方法對于提升文學翻譯的長句翻譯也有明顯效果。未來我們將進一步完善隱性句逗號識別方法,特別是考慮真實語境中所有句逗號(真實句逗號與隱性句逗號)的識別問題,并將探索直接在機器翻譯模型中融入隱性句逗號的理解。
注釋
①數字序號代表漢英小句序號;漢語隱性句逗號與其對應英譯標點用紅色[]標出,下同。例①a、b及其小句切分采用自馮文賀(2019:1)。
②網址分別為:https://www.statmt.org/wmt2018/translation-task.html;https://aclanthology.org/events/wmt-2023/2023wmt-1.
*張文娟為本文通訊作者。
參考文獻
馮文賀. 漢英篇章結構平行語料庫構建與應用研究[M]. 北京: 科學出版社, 2019.‖Feng, W.-H. The Construction and Application of Chinese-English Discourse Treebank[M]. Beijing: Science Press, 2019.
馮文賀 李青青. 漢語復句的成分共享與英譯斷句[J]. 外語教學與研究, 2022(5).‖Feng, W.-H.," Li, Q.-Q. Constituent Sharing in Chinese Complex Sentence and the Segmentation of" Its English Translation[J]. Foreign Language Teaching and Research, 2022(5).
黃河燕 陳肇雄. 基于多策略分析的復雜長句翻譯處理算法[J]. 中文信息學報, 2002(3).‖Huang, H.-Y., Chen, Z.-X. The Hybrid Strategy Processing Approach of" Complex Long Sentence[J]. Journal of Chinese Information Processing, 2002(3).
賈愛鑫 李軍輝 貢正仙 張 民. 融合目標端上下文的篇章神經機器翻譯[J]. 中文信息學報, 2024(4).‖Jia, A.-X., Li, J.-H., Gong, Z.-X., Zhang, M. Mo-deling Target-side Context for Document-level Neural Machine Translation[J]. Journal of Chinese Information Processing, 2024(4).
李 幸 宗成慶. 引入標點處理的層次化漢語長句句法分析方法[J]. 中文信息學報, 2006(4).‖Li, X., Zong, C.-Q. A Hierarchical Parsing Approach with Punctuation Processing for Long Chinese Sentences[J]. Journal of Chinese Information Processing, 2006(4).
呂叔湘. 漢語語法分析問題[M]. 北京:商務印書館, 1979.‖Lv, S.-X. Analyses of Chinese Grammar[M]. Beijing: The Commercial Press, 2022.
宋 柔. 小句復合體的語法結構[M]. 北京:商務印書館, 2022.‖Song, R. Grammatical Structure of Clause Complexes[M]. Beijing: The Commercial Press, 2022.
趙朝永 王文斌. 漢語流水句與英語復雜句結構特性對比:英漢時空特質差異視角[J]. 外語教學, 2020(5).‖Zhao, C.-Y., Wang, W.-B. A Structural Contrast Between Chinese Run-on Sentences and English Complex Sentences from the Perspective of English Temporality and Chinese Spatiality[J]. Foreign Language Education, 2020(5).
Atrio, L.R., Allemann, A., Dolamic, L., Popescu-Belis, A. A Simplified Training Pipeline for Low-resource and Unsupervised Machine Translation[R]. Proceedings of" the Sixth Workshop on Technologies for Machine Translation of" Low-Resource Languages(LoResMT 2023), 2023.
Chen, J., Li, X., Zhang, J., Zhou, C., Cui, J., Wang," B., Su, J. Modeling Discourse Structure for Document-level Neural Machine Translation[J]. arXiv Preprint arXiv:2006.04721. 2020.
Devlin, J., Chang, M.W., Lee, K., Toutanova, K. Bert: Pre-training of Deep Bidirectional Transformers for Language Understanding[R]. Proceedings of the 2019 Conference of the North American Chapter of" the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019.
Du," J., Grave, E., Gunel, B., Chaudhary, V., Celebi, O., Auli, M., Stoyanov, V., Conneau, A. Self-training Improves Pre-training for Natural" Language Understanding[R]. Proceedings of the 2021 Conference of North American Chapter of the Association for Computational Linguistics, 2021.
Goh, C.L., Sumita," E. Splitting Long Input Sentences for Phrase-based Statistical Machine Translation[R]. The Association for Natural" Language Processing, 2011.
Guo, J., Chen, X., Liu, Z., Yuan, W., Zhang, J., Liu, G. Context Modeling with Hierarchical Shallow Attention Structure for Document-level Nmt[R]. 2022 Internatio-nal Joint Conference on Neural Networks (IJCNN), 2022.
Hung, B.T., Minh, N.L., Shimazu, A. Sentence Splitting for Vietnamese-English Machine Translation[R]. Fourth International Conference on Knowledge and Systems Engineering, 2012.
Koehn, P., Knowles, R., Six Challenges for Neural Machine Translation[R]. Proceedings of the First Workshop on Neural Machine Translation, 2017.
Kuang, S., Xiong, D. Automatic Long Sentence Segmentation for Neural Machine Translation[A]. In: Lin, C.Y., Xue, N., Zhao, D., Huang, X., Feng, Y.(Eds.), Natural Language Understanding and Intelligent Applications[C]. Cham: Springer, 2016.
Li, D., Arivazhagan, N., Cherry, C., Padfield, D. Sentence Boundary Augmentation For Neural Machine Translation Robustness[R]. ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing, 2021.
Liu, M., Tu, Z., Wang, Z., Xu, X. LTP: A New Active Learning Strategy for Bert-CRF Based Named Entity Re-cognition[J]. arXiv preprint arXiv: 2001.02524. 2020.
Lukasik, M., Dadachev, B., Papineniet, K., Simoes, G. Text Segmentation by Cross Segment Attention[R]. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, 2020.
Oliveira, F., Wong, F.," Hong, I.S. Systematic Processing of" Long Sentences in Rule Based Portuguese-Chinese Machine Translation[R]. Computational Linguistics and Intelligent Text Processing: 11th International Conference, 2010.
Papineni," K., Roukos, S., Ward, T.," Zhu, W.J." Bleu: a Method for Automatic Evaluation of Machine Translation[R]. Proceedings of the 40th Annual meeting of the Association for Computational Linguistics, 2002.
Pouget-Abadie, J., Bahdanau, D., Van Merrienboer, B., Cho, K., Bengio, Y. Overcoming the Curse of Sentence Length for Neural Machine Translation Using Automatic Segmentation[R]. Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, 2014.
Sutskever, I., Vinyals, O., Le, Q.V., Sequence to Sequence Learning with Neural Networks[R]. Proceedings of the 27th International Conference on Neural Information Processing Systems, 2014.
Tan, X., Zhang, L., Zhou, G. Document-Level Neural Machine Translation with Hierarchical Modeling of Global Context[J]. Journal of Computer Science and Technology, 2022(2).
Tiedemann, J., Thottingal, S. OPUS-MT-building Open Translation Services for the"" World[R]. Proceedings of" the 22nd Annual Conference of the European Association for Machine Translation, 2020.
Tien, H.N., Minh, H.N.T." Long Sentence Preprocessing in Neural Machine Translation[R]. IEEE-RIVF International Conference on Computing and Communication Technologies (RIVF), 2019.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I. Attention is all You Need[R]. Proceedings of the 31st International Conference on Neural Information Proces-sing Systems, 2017.
Wicks, R., Post, M. A Unified Approach to Sentence Segmentation of Punctuated Text in Many Languages[R]. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, 2021.
Xiong, H., Xu, W., Mi, H., Liu, Y., Liu, Q. Sub-sentence Division for Tree-based Machine Translation[R]. Proceedings of the ACL-IJCNLP 2009 Conference, 2009.
Yang, C., Sheng, L., Wei, Z., Wang, W. Chinese Named Entity Recognition of" Epidemiological Investigation of Information on COVID-19 Based on BERT[J]. IEEE Access, 2022(10).
Yin, B., Zuo, J., Ye, N. Long Sentence Partitioning Using Top-down Analysis for Machine" Translation[R]. IEEE 2nd International Conference on Cloud Computing and Intelligence Systems, 2012.
Zhang, J., Gan, R., Wang, J., Zhang, Y., Zhang, L., Yang, P., Gao, X., Wu, Z., Dong, X., He, J., Zhuo, J., Chen, C. Fengshenbang 1.0: Being the Foundation of" Chinese Cognitive Intelligence[J]. arXiv preprint arXiv: 2022.2209.02970.
Zhuocheng," Z., Gu, S., Zhang, M., Feng, Y. Addressing the Length Bias Challenge in Document-Level Neural Machine Translation[R]. Findings of the Association for Computational Linguistics: EMNLP, 2023.
定稿日期:2024-12-10【責任編輯 謝 群】
