基于XGBoost模型的海上壓力容器設備壁厚預測研究
2024-12-27 00:00:00李雪路通
中國新技術新產品 2024年18期
摘 要:海洋平臺壓力容器在運行中承受較大的工作載荷,服役環境復雜,常出現裂紋、腐蝕等失效問題,常用超聲波測厚無損檢測技術對設備服役狀況進行定期檢測。本文采用機器學習算法構建設備壁厚預測模型,基于歷史檢測數據實現海上壓力容器減薄情況的預測功能。經樣本數據的特征工程處理,以容器壁厚作為模型預測目標,設計溫度、工作壓力、容器類型等基礎數據作為輸入,對模型進行訓練及測試。結合模型預測性能的評估及調參處理,獲取預測評價指標較優的XGBoost模型。該模型能夠為設備狀態的評估及風險策略提供指導作用,對海洋平臺的安全生產具有重要意義。
關鍵詞:壓力容器;壁厚預測;XGBoost模型
中圖分類號:TE 951 文獻標志碼:A
海上壓力容器是海洋石油平臺的重要設備,分為存儲類、換熱類、分離類和反應類。由于海洋環境的特殊性及運行條件的復雜性,海上平臺壓力容器的損傷及失效風險增加。為提高其穩定運行能力,需要定期進行超聲波測厚等無損檢測技術指導維修或更換,確保設備穩定運行[1]。隨著計算機及通信技術進步,特種設備檢驗檢測行業迎來轉型升級的關鍵期。人工智能在機器學習、知識圖譜、人機交互等技術上不斷突破,具有廣闊的研究及應用前景[2]。本文基于壓力容器設備檢測的歷史數據,結合XGBoost、LightGBM、Random Forest等機器學習算法構建預測模型,實現容器壁厚或減薄率的精準預測,提升設備運維的智能化水平。研究結果對機器學習預測算法的應用及不同類型容器壁厚的準確評估具有指導意義。
1 數據處理及準備
1.1 數據來源及數據文件解析
本研究主要基于同一年份不同類型的壓力容器設備年度檢驗數據,通過數據清洗及處理,引進數據統計和分析技術,并結合機器學習智能算法,完成容器設備壁厚的預測工作。其中,對Excel格式數據文件進行解析,獲取用于訓練的數據,運用Python的工具Pandas讀入Excel格式文件,將處理后的數據保存為csv格式并進行數據引入。
1.2 數據預處理及數據特征工程
基于壓力容器的基礎數據信息進行預處理,避免因數據未處理而導致數據信息紊亂、缺失、數據的邏輯不符等影響數據分析的問題,主要包括數據清洗、數據歸一化等。采用正則表達式并制定判定規則,對數據進行清洗及特征構建,保證數據信息的一致性,提高建模的收斂速率和精度。對需要使用的特征進行篩選,利用頻率統計篩選包括信息量過少、數據缺失量較大特征及取值單一的特征,當樣本空值特征占比大于30%時,去除該樣本數據。
針對模型訓練和測試開展的數據特征工程主要包括以下3個方面的內容。1)直接特征。“工作溫度”,采用正則方式對溫度的數值進行提取及標準處理。針對含管程與殼程的換熱類設備進行組合及劃分,提取溫度的個數,針對“常溫”等具有含義的內容,將其轉換為數據;“工作壓力”,與工作溫度特征提取流程一致,對“量綱”進行處理,例如統一壓力單位量級;“腐蝕余量”,分析其數據模式并取數字中最小值作為特征;“設計壽命”,運用3sigma原理進行過濾;“公稱容積”、“內徑”,直接提取各值;“制造日期”、“投產日期”,統一為年月格式,“投產月數”為“投產日期”減去“制造日期”,經Excel對日期進行特征處理及提取。2)類別型特征。篩選可進行onehot的特征,例如殼體材質、容器類型、油田群、系統名稱,對取值進行規范化處理,即對描述同一內容而使用了不同表達的特征值進行處理,并對數量過少的類型用“其他”代替。3)檢測數據處理。針對“厚度”進行數據處理,設置代碼通過厚度計算的方式獲得“減薄量”,即名義厚度減去實測厚度。
2 預測模型的建立
2.1 基于機器學習算法構建預測模型
結合機器學習算法模型的應用及要求,其運行機制主要基于檢驗數據的格式和數據結構,對預測模型進行設計、訓練和測試等,以達到設備壁厚預測的目標。綜合考慮數據類型、模型效果和運行效率,選擇機器學習中的XGBoost、LightGBM、Random Forest集成模型[3-5]。其中,LightGBM主要基于決策樹學習算法,其分支為測試的輸出,葉節點為各個類別,按葉子(leaf-wise)生長的策略,即按照最大分裂增益為葉子節點進行分裂計算,每個樣本通過變量進行樹結構的映射;XGBoost采用極端層次增強方法,基于梯度增強決策樹,以優化目標函數值為主的改進算法,每棵樹(函數)逐次添加,樹與樹之間串行,可在同一級結點并聯,分離結點的增益以多線程方式并行;Random Forest為集成學習算法,參數以強學習器最大迭代次數、隨機發生器種子數、最大特征數等為主,經抽樣集成多顆決策樹優化模型,基于多個決策樹模型的融合,提高其擬合能力。
在選擇對應的集成模型架構后,針對同一數據集樣本進行劃分,隨機選取上述結構化及處理后的數據中的80%作為訓練集,20%作為測試集。以容器測厚作為模型預測目標,其他基礎特征作為模型輸入,模型提取特征后分別進行訓練和測試,結合模型預測精度的評估結果進行優化,達到精度要求后保存最優模型,以此實現容器設備壁厚的機器學習回歸預測模型的構建。
2.2 模型預測性能評估
本研究主要采用評估模型的預測性能方法,包括均方誤差mse、平均絕對誤差mae、平均相對誤差mre、決策系數r2、皮爾遜相關系數pearson。對結果進行處理后,采用適用于分類任務的評價指標,包括準確率accuracy、精準率precision、召回率recall、精準率與召回率的調和均值f1、正例排在負例前的概率auc等評估模型整體的預測趨勢,以全方位評估模型效果。經過對3種模型的訓練及結果驗證,計算各個模型的均方根誤差損失,在運行效率滿足的條件下,選擇損失得分較小的模型進行應用。
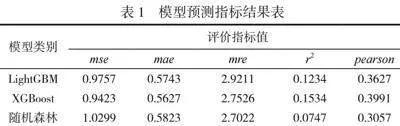
對各設備測量部位不同測厚電位的減薄量進行匯總統計,以減薄量的均值作為預測特征值。通過分類指標對預測模型進行評估,不同預測模型的評價結果值見表1。經比對,綜合分析XGBoost模型的均方誤差、平均絕對誤差評價指標值相對較小,r2較接近1,表明XGBoost模型的預測性能較優,選用XGBoost模型進行進一步調參優化。
2.3 XGBoost模型優化
為提高模型的準確性,對該機器學習模型進行調優,并降低過擬合,使模型預測性能最大化。對learning_rate(學習率)、max_depth(數的最大深度)、min_child_weights(最小葉子節點樣本權重)、num_leaves(決策樹葉子數量)等進行調整,提高準確率,其他參數為默認值。經模型調參后,XGBoost模型的mse最小值為0.7491,此時的模型預測性能達到最優,即對應的最優參數如下:max_depth=9,min_child_weight=1,n_estimators=200,colsample_bytree=0.7,learning_rate=0.07。
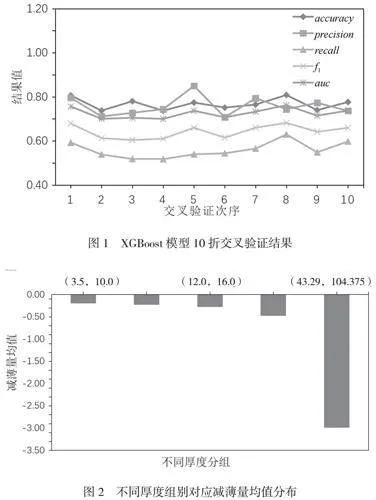
對優選的模型參數進行K折交叉驗證,以進一步對模型參數進行調優,主要將數據集分割為K個子集,經K-1折作為訓練數據,對模型進行訓練后,對數據的剩余1折做驗證,使各樣本均有一次機會進行驗證。如圖1所示,表現了10折交叉驗證結果,相關評價指標的查準率(Precision)為70%~80%,查全率(Recall)為50%~60%,F1-Score為70%~75%。整體來說,相關指標較高并且較穩定,驗證XGBoost模型能夠用于容器類設備減薄情況的預測。
2.4 結果與分析
2.4.1 容器厚度及預測差異的影響分析
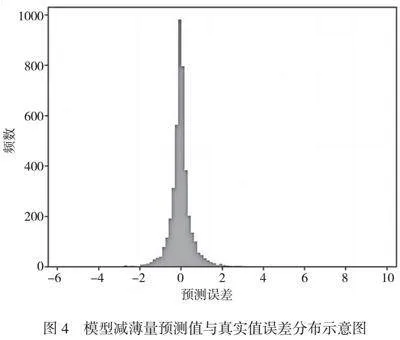
不同類型容器的厚度差異較大,部分厚度較大的容器其誤差相對較大,圖2展示了不同厚度組別所對應統計的減薄量均值情況。由圖2可知,厚度越大的分組所出現增厚的可能性越大(減薄量為負值表示增厚)。查看減薄量差異較大的樣本數據部分,減薄量預測值或真實值過大均會造成誤差偏大的情況。
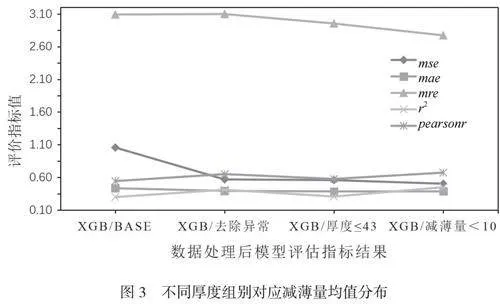
同時,對厚度差異過大的樣本中存在不合理的數值進行篩選,并刪除平均測量厚度小于1的樣本數據,處理后經10折交叉驗證,并對比前后結果,如圖3中XGBoost(去除異常)顯示,mse明顯降低。
此外,當容器厚度大于43時,減薄量數值變化明顯,通過去除厚度過大的容器,保留99分位數(43)以內的厚度樣本,并對數據集進行預測,結果顯示mse指標略有提升。為了避免出現預測值過大的可能,刪除真實減薄值過大的樣本,以降低偏差,經篩選發現數據中僅有1條數據減薄量大于5并達10以上,將其刪除后,預測結果mse有所提升(如圖3所示)。
2.4.2 厚度分段建模及效果分析
由于隨著容器厚度增加,減薄量方差變大,考慮厚度較大的容器樣本可能會對較小厚度樣本的預測產生負面影響,因此選用容器厚度為43以內的數據樣本進行容器厚度分段建模,即通過選擇50分位數(12),對厚度小于12和大于等于12的樣本分別建模。分析得知,厚度小于12時,建模進行預測后的mse指標值約為0.336,當厚度大于12時,預測指標mse變大,約為0.685。由此表明,厚度大的樣本對厚度小的樣本的預測可能產生干擾。
2.4.3 特征優化
由于厚度分組后對模型的預測結果影響較大,因此在特征中增加“設計厚度”。將增加“設計厚度”特征后預測模型的評價指標值(mse2)與原結果(mse1)進行對比,見表2。
經對比以上結果可知,一方面,增加設計厚度特征后各組中的mse結果大多數呈下降的趨勢,表明模型預測效果有所提升。另一方面,各項措施趨勢基本與原有試驗結果一致,驗證預測效果提升并非隨機。因此,增加“設計厚度”特征后,對比分析評價指標,其預測性能獲得了相對全面的提升。
2.4.4 結果分析
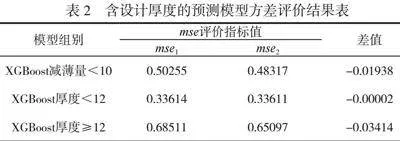
經比對,使用該XGBoost模型對容器設備減薄的預測值與真實值進行誤差分析(如圖4所示),根據預測誤差的分布情況得知,該XGBoost模型預測的誤差符合正態分布,獲得的模型可用于相關場景的預測并有較好的效果。
3 結語
本文基于海上壓力容器超聲測厚檢測檢驗數據集,選取設備對象的基礎數據及檢測數據特征進行數據處理,使用XGBoost機器學習算法建立容器類設備壁厚預測模型,運用評價指標對模型預測性能進行分析評估,并對模型進行優化調參。結果表明,本文測得XGBoost算法比另外2種機器學習模型的預測性能更高,模型經調參優化后,準確率及查準率均有提升。通過分析容器本身的厚度以及預測減薄量的差異等情況對模型預測效果產生偏差的影響,分別對容器厚度進行分段模型預測,厚度小的模型的預測效果比厚度大的模型好,并且采用對厚度預測特征的數據處理及設計厚度特征的增加的方式,方差減小,預測效果全面提升。該模型用于容器類設備壁厚的預測誤差符合正態分布,具有較好的應用效果。本文模型后續將嘗試積累更多不同類型容器數據,并對介質進行分類及采集,擴展應用范圍,對XGBoost模型進行進一步更新訓練,并嘗試引入神經網絡算法對容器類設備壁厚進行預測及優化。
參考文獻
[1]紀玉磊.探究海上壓力容器腐蝕檢測技術[J].中國石油和化工標準與質量,2023,43(1):57-59.
[2]李奇,牟善軍,姜巍巍,等.海上石油平臺定量風險評估[J].中國海洋平臺,2007,22(6):38.
[3]周志華.機器學習[M].北京:清華大學出版社,2016.
[4]BREIMAN L.Randomforests[J].Machine learning,2001,45(1):5-32.
[5]CHEN T,HE T,BENESTY M,etal.Xgboost:extreme"gradient boosting[J].R package version 0.4-2,2015,1(4):1-4.
