信創(chuàng)知識倉庫的設(shè)計(jì)與構(gòu)建
2024-12-25 00:00:00蘇靜吳晨帆毛遠(yuǎn)欣
消費(fèi)電子 2024年10期
[關(guān)鍵詞]知識圖譜;信創(chuàng)知識倉庫;本體語義模型;Neo4j;pagerank算法
引言
過去,我國所使用的信息技術(shù)產(chǎn)業(yè)基礎(chǔ)框架、行業(yè)標(biāo)準(zhǔn)和核心產(chǎn)品等多由國外廠商制定,這使我國在行業(yè)基礎(chǔ)設(shè)施和信息系統(tǒng)關(guān)鍵核心產(chǎn)品方面缺乏自主主動權(quán)。信創(chuàng)產(chǎn)業(yè)即為我國信息技術(shù)領(lǐng)域進(jìn)一步發(fā)展和國家數(shù)據(jù)安全不被泄露,使我國信息技術(shù)領(lǐng)域達(dá)到可掌控、可研究、可發(fā)展的終極目標(biāo)。因此,發(fā)展信創(chuàng)產(chǎn)業(yè)對于解決我國在信息與網(wǎng)絡(luò)安全乃至國家安全方面所面臨的諸多問題至關(guān)重要。
信創(chuàng)領(lǐng)域作為知識密集型領(lǐng)域,其知識構(gòu)成具有大規(guī)模、更新快、多維度、多源頭的特點(diǎn),因此傳統(tǒng)的知識管理方式不利于信創(chuàng)領(lǐng)域的資源整合和科普推廣。構(gòu)建基于知識圖譜的信創(chuàng)知識倉庫對信創(chuàng)領(lǐng)域知識的有效管理與廣泛推廣具有重要的研究意義與應(yīng)用價(jià)值。
一、知識圖譜發(fā)展現(xiàn)狀
(一)信創(chuàng)知識管理現(xiàn)狀
現(xiàn)有的知識管理系統(tǒng):
SharePoint: Microsoft的SharePoint是一個(gè)企業(yè)級協(xié)作平臺,用于創(chuàng)建、管理和共享文檔和信息。它與Microsoft365集成,支持團(tuán)隊(duì)協(xié)作、版本控制和工作流程48。
MediaWiki: MediaWiki是維基百科背后的平臺,也是一個(gè)開源的知識管理系統(tǒng)。它提供了一個(gè)靈活的平臺,可以創(chuàng)建和維護(hù)文檔,適用于協(xié)作性的知識管理。
Evernote: Evernote是一個(gè)數(shù)字筆記應(yīng)用,可用于組織和存儲文檔、圖片、筆記和聲音記錄。它支持跨設(shè)備同步,適用于個(gè)人和團(tuán)隊(duì)。
目前現(xiàn)有的知識管理系統(tǒng)通常通過提高系統(tǒng)內(nèi)部的信息流動來促進(jìn)團(tuán)隊(duì)協(xié)作,加速問題解決。這顯然無法匹配信創(chuàng)領(lǐng)域知識資源多維度、多源頭、更新快的特性。
(二)知識圖譜在不同領(lǐng)域的應(yīng)用
1.知識圖譜的概念與特點(diǎn)
知識圖譜是一種圖形化的知識管理結(jié)構(gòu),它將實(shí)體間的關(guān)系以圖的形式建模,圖上的節(jié)點(diǎn)表示實(shí)體,邊表示關(guān)系。知識圖譜通過語義化的關(guān)系將實(shí)體連接起來并以一種結(jié)構(gòu)化的方式組織和存儲信息。此外,知識圖譜還具有良好的可拓展性。新的內(nèi)容可以方便地添加到圖譜中,來更新知識庫,充盈知識庫。
2.知識圖譜在不同領(lǐng)域的成功應(yīng)用
目前,知識圖譜在眾多行業(yè)中都有成功應(yīng)用的案例:
在生物醫(yī)學(xué)領(lǐng)域:用于整合和分析醫(yī)學(xué)文獻(xiàn),幫助研究人員了解基因、蛋白質(zhì)、藥物等的關(guān)系,支持疾病診斷、基因組學(xué)研究和藥物發(fā)現(xiàn)。
金融領(lǐng)域:用于構(gòu)建客戶關(guān)系圖,幫助銀行和金融機(jī)構(gòu)更好地了解客戶,支持風(fēng)險(xiǎn)管理,通過分析實(shí)體和關(guān)系來識別潛在的金融風(fēng)險(xiǎn)。
智能交通系統(tǒng):建立城市交通網(wǎng)絡(luò)的知識圖譜,幫助優(yōu)化交通流和規(guī)劃交通路線,并利用實(shí)時(shí)數(shù)據(jù)更新圖譜,提高交通系統(tǒng)的智能化水平。
制造業(yè):支持供應(yīng)鏈管理,幫助企業(yè)優(yōu)化物流和生產(chǎn)過程,構(gòu)建設(shè)備和零部件之間的關(guān)系圖,支持設(shè)備維護(hù)和故障診斷。
綜上所述,不難看出知識圖譜在與信創(chuàng)領(lǐng)域相關(guān)的各行各業(yè)中都起到了不錯(cuò)的效果。由此,知識圖譜能夠充分滿足信創(chuàng)領(lǐng)域的知識管理需求。
二、構(gòu)建知識圖譜的方法
(一)建立知識圖譜的框架
領(lǐng)域知識圖譜的構(gòu)建通常采用自上而下的方法,先通過相關(guān)領(lǐng)域現(xiàn)有的知識研究,確定其范圍,定義實(shí)體性完成本體的構(gòu)建,然后根據(jù)本體模型確定所需要的數(shù)據(jù)類型,再通過知識采集、知識抽取等技術(shù)獲取所需的數(shù)據(jù),并通過圖數(shù)據(jù)庫進(jìn)行數(shù)據(jù)存儲與可視化展示,最后通過引入圖形算法增強(qiáng)知識圖譜的可視化程度。
1.本體語義模型構(gòu)建
本體語義模型的構(gòu)建有許多方法,如經(jīng)典的七步法、IDEF5法和骨架法等。領(lǐng)域類知識圖譜構(gòu)建通常采用七步法,步驟為:
確定本體范圍:領(lǐng)域類知識圖譜首先構(gòu)建領(lǐng)域本體的范圍,確定本體范圍常用的方法是列出幾個(gè)專注于領(lǐng)域本體的問題,檢測本體能否提供足夠的信息來回答此類問題,以此對本體進(jìn)行不斷完善。
重用現(xiàn)有的本體:在構(gòu)建本體之前應(yīng)先調(diào)研是否相關(guān)的本體已經(jīng)存在,如果存在可以對其進(jìn)行改進(jìn)和拓展,無需重新構(gòu)建。
列舉本體核心概念:以本體的全面性為前提,盡可能地列舉出本體可能存在的全部概念。
定義本體概念的上下級描述:通過自上而下的方式對領(lǐng)域中的概念進(jìn)行結(jié)構(gòu)化的梳理,定義本體概念的上下級描述,即定義關(guān)系。
定義概念具有的屬性:對已經(jīng)定義的概念通過賦予不同的屬性加以描述。
定義屬性的限制:即定義屬性的值的限制。
添加實(shí)例:以之前提出的概念為藍(lán)本添加實(shí)例數(shù)據(jù)進(jìn)行測試,對模型的范圍、準(zhǔn)確性等進(jìn)行檢測。
2.?dāng)?shù)據(jù)采集與整合
(1)數(shù)據(jù)采集
數(shù)據(jù)采集是從不同來源收集數(shù)據(jù)的過程,數(shù)據(jù)采集的方法有很多,常見的有以下幾種:
①網(wǎng)絡(luò)爬蟲:使用自動化工具從網(wǎng)站上提取信息。這可以是結(jié)構(gòu)化的數(shù)據(jù),如表格或非結(jié)構(gòu)化的數(shù)據(jù),如文本。
②傳感器數(shù)據(jù)采集:許多物理設(shè)備和系統(tǒng)使用傳感器生成數(shù)據(jù),如溫度傳感器、濕度傳感器、壓力傳感器等。
③日志文件分析:分析服務(wù)器、應(yīng)用程序或系統(tǒng)生成的日志文件,以獲取關(guān)于其運(yùn)行和用戶行為的信息。
④社交媒體監(jiān)測:通過監(jiān)控社交媒體平臺上的活動來收集用戶反饋、趨勢和輿論。
⑤數(shù)據(jù)庫查詢:通過查詢數(shù)據(jù)庫來檢索所需的信息,這可以是關(guān)系型數(shù)據(jù)庫或非關(guān)系型數(shù)據(jù)庫。
(2)數(shù)據(jù)清洗
數(shù)據(jù)清洗是指在進(jìn)行數(shù)據(jù)分析或建模之前,對原始數(shù)據(jù)進(jìn)行處理和修復(fù),以解決數(shù)據(jù)質(zhì)量問題。進(jìn)行數(shù)據(jù)清洗的常規(guī)方法如下:
①數(shù)據(jù)類型轉(zhuǎn)換:確保數(shù)據(jù)類型正確,例如將字符串轉(zhuǎn)換為數(shù)值型。處理日期和時(shí)間數(shù)據(jù),確保格式一致。
②處理異常字符:刪除或替換包含異常字符的數(shù)據(jù)。
③處理不一致性:統(tǒng)一數(shù)據(jù)的格式和表示,確保一致性。處理異義詞和同義詞,以便在分析中能夠正確理解數(shù)據(jù)。
(3)數(shù)據(jù)抽取
數(shù)據(jù)抽取是從結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù)中提取有用信息的過程。對大規(guī)模數(shù)據(jù)的抽取一般需要和命名實(shí)體識別結(jié)合使用,命名實(shí)體識別是自然語言處理中的一項(xiàng)重要任務(wù),其目標(biāo)是從文本中識別并分類出命名實(shí)體,如人名、地名等。常見的命名實(shí)體識別方法一般分為三種,基于規(guī)則、基于統(tǒng)計(jì)和基于深度學(xué)習(xí)。
基于規(guī)則的方法使用手工設(shè)計(jì)的規(guī)則來識別實(shí)體,這些規(guī)則可以基于詞性、詞典、語法等。基于規(guī)則的命名實(shí)體識別一般簡單且可解釋,適用于特定領(lǐng)域的規(guī)律性較強(qiáng)的任務(wù),可以手動定義規(guī)則來適應(yīng)不同的文本結(jié)構(gòu)。但對于復(fù)雜的文本結(jié)構(gòu)和多樣的實(shí)體命名規(guī)律,基于規(guī)則的命名實(shí)體識別可能不夠靈活和泛化。
基于統(tǒng)計(jì)的命名實(shí)體識別統(tǒng)計(jì)方法通常使用機(jī)器學(xué)習(xí)算法,如條件隨機(jī)場或隱馬爾可夫模型。這些模型通過學(xué)習(xí)從標(biāo)注的語料庫中提取的特征來預(yù)測實(shí)體類別。基于統(tǒng)計(jì)的命名實(shí)體識別通常適用于有標(biāo)注數(shù)據(jù)的任務(wù)。
基于深度學(xué)習(xí)的方法,通常指基于神經(jīng)網(wǎng)絡(luò)的方法,如卷積神經(jīng)網(wǎng)絡(luò)和變壓器(Transformer)。這些方法通常能夠?qū)W習(xí)到更復(fù)雜的語言模式,適用于大規(guī)模和多領(lǐng)域的數(shù)據(jù)。最近,預(yù)訓(xùn)練模型,如BERT和GPT等,已經(jīng)在命名實(shí)體識別任務(wù)上取得了顯著的成果。
3.?dāng)?shù)據(jù)存儲與可視化
知識圖譜數(shù)據(jù)的存儲通常采用圖數(shù)據(jù)庫來管理和查詢。圖數(shù)據(jù)庫是專門設(shè)計(jì)用于存儲和處理圖結(jié)構(gòu)的數(shù)據(jù)庫系統(tǒng),它們能夠有效地表示實(shí)體之間的關(guān)系。
Neo4j是目前使用人數(shù)最多的圖數(shù)據(jù)庫,其獨(dú)特的圖結(jié)構(gòu)存儲模型使得表示實(shí)體和復(fù)雜關(guān)系變得自然而高效。Neo4j優(yōu)秀的可擴(kuò)展性能夠輕松應(yīng)對大規(guī)模圖數(shù)據(jù),其跨平臺支持、活躍的社區(qū)和豐富的生態(tài)系統(tǒng)也使得Neo4j成為處理關(guān)系型數(shù)據(jù)的首選。
知識圖譜可視化通常選擇使用圖數(shù)據(jù)庫可視化工具如Neo4j browser、Gephi等或者使用Vis.js、Cytoscape.js等在web程序中嵌入。
4.Pagerank算法與社區(qū)檢測算法
PageRank是通過分析頁面之間的鏈接關(guān)系來確定頁面重要性的一種算法,可用于知識圖譜中檢測節(jié)點(diǎn)的重要性,從而向使用者提供更好的可視化效果。
社區(qū)檢測算法是用于在圖識別子圖結(jié)構(gòu)的一類算法。社區(qū)檢測算法用于知識圖譜中通常可以將發(fā)展度相似的節(jié)點(diǎn)分為一組,以便管理人員進(jìn)行分析。
(二)基于知識圖譜的信創(chuàng)知識倉庫實(shí)施
1.信創(chuàng)領(lǐng)域本體語義模型構(gòu)建
本文在定義信創(chuàng)領(lǐng)域知識圖譜的本體語義模型時(shí)發(fā)現(xiàn),信創(chuàng)領(lǐng)域知識具有自上而下、從抽象到具體、從簡單到復(fù)雜的樹狀特征。基于這一特征和對現(xiàn)有數(shù)據(jù)的分析,本文得到了信創(chuàng)這一核心類和基礎(chǔ)軟件、應(yīng)用軟件、網(wǎng)絡(luò)安全、外設(shè)終端、CPU設(shè)計(jì)和集成電路這五個(gè)二級類目和操作系統(tǒng)、中間件、數(shù)據(jù)安全等21個(gè)三級類目。如下圖所示:
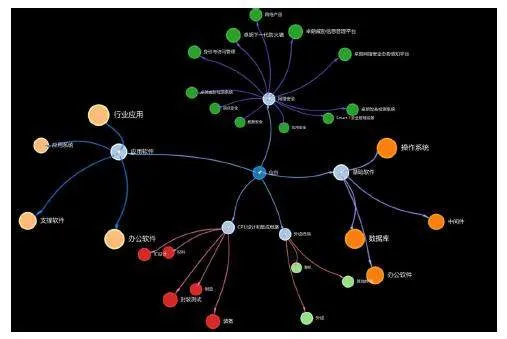
2.信創(chuàng)數(shù)據(jù)采集
由于信創(chuàng)領(lǐng)域的數(shù)據(jù)具有零散不易收集的特征,一般采用以下幾種采集方法:
網(wǎng)絡(luò)爬蟲:使用自動化工具從中國信創(chuàng)網(wǎng)等網(wǎng)站上提取知識.作為信創(chuàng)知識圖譜的數(shù)據(jù)基礎(chǔ)。
文獻(xiàn)調(diào)研:搜索學(xué)術(shù)文獻(xiàn)、行業(yè)報(bào)告和技術(shù)文檔,了解關(guān)于信創(chuàng)的最新研究和發(fā)展。
企業(yè)報(bào)告和新聞:分析公司發(fā)布的報(bào)告和新聞,了解企業(yè)在信創(chuàng)領(lǐng)域的創(chuàng)新和發(fā)展。
3.信創(chuàng)數(shù)據(jù)清洗
在信創(chuàng)領(lǐng)域,常見的數(shù)據(jù)問題一般有缺失、異常、重復(fù)等,處理方法如下:
缺失值處理:刪除包含缺失值的行或列。使用特定值填充缺失值或使用插值方法來估算缺失值。
異常值處理:識別并處理異常值。這可以通過統(tǒng)計(jì)方法或?qū)iT的異常檢測算法來完成。
重復(fù)值處理:檢測并刪除重復(fù)的記錄。確保唯一性,特別是對于主鍵。
4.信創(chuàng)知識抽取
由于信創(chuàng)領(lǐng)域的數(shù)據(jù)具有多維度的特點(diǎn),因此本文采用基于規(guī)則與預(yù)訓(xùn)練模型結(jié)合的知識抽取方式,然后在命名實(shí)體的基礎(chǔ)上,直接從文本中提取與每個(gè)命名實(shí)體相關(guān)的信息。
首先,通過爬蟲獲得的信息都有較為明顯的產(chǎn)品名稱、特點(diǎn)等語料,可以通過制定匹配規(guī)則進(jìn)行提取,同時(shí)由于信創(chuàng)領(lǐng)域知識的樹狀特點(diǎn),實(shí)體間的關(guān)系可通過人為設(shè)置。其次,對于專業(yè)期刊、文獻(xiàn)、企業(yè)報(bào)告等數(shù)據(jù),采用BERT預(yù)訓(xùn)練模型來完成產(chǎn)品名稱識別任務(wù),然后通過識別出的產(chǎn)品對數(shù)據(jù)進(jìn)行分類再通過規(guī)則提取需要的數(shù)據(jù)。
5.信創(chuàng)知識存儲
Neo4j作為目前使用人數(shù)最多的圖數(shù)據(jù)庫,其良好的拓展性和通用性以及豐富的圖形算法與知識圖譜的存儲十分契合。因此,本文以Neo4j圖數(shù)據(jù)庫存儲處理的數(shù)據(jù)。Neo4j中的節(jié)點(diǎn)對應(yīng)語義模型中的實(shí)例,標(biāo)簽對應(yīng)各個(gè)級別的核心類目,關(guān)系則體現(xiàn)了各類目之間的上下級關(guān)系。根據(jù)上文提到的語義模型確立Neo4j的節(jié)點(diǎn)和關(guān)系,然后通過py2neo批量導(dǎo)入Neo4j,完成知識圖譜的構(gòu)建。
6.信創(chuàng)知識圖譜可視化
根據(jù)使用人群的不同,本文提出了兩種知識圖譜可視化方式。
針對數(shù)據(jù)分析人員和管理人員,使用Neo4j bloom來進(jìn)行可視化分析和管理。Neo4j Bloom是一款專為Neo4j圖數(shù)據(jù)庫設(shè)計(jì)的可視化工具,它通過直觀的圖形界面提供了探索和分析圖數(shù)據(jù)的方式,如圖所示:

針對想要了解信創(chuàng)發(fā)展現(xiàn)狀的普通用戶,使用neovis.js嵌入web程序進(jìn)行可視化展示,neovis.js是一個(gè)用于Neo4j圖數(shù)據(jù)庫的JavaScript庫,方便地將Neo4j數(shù)據(jù)庫中的節(jié)點(diǎn)和關(guān)系呈現(xiàn)為直觀的圖形,并支持用戶的交互式查詢和導(dǎo)航。如下圖所示:
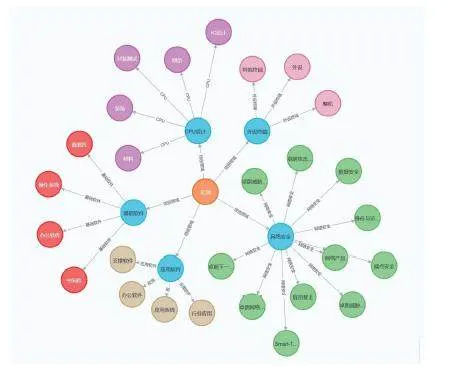
此外,通過在Neo4j browser中導(dǎo)入pagerank算法與社區(qū)檢測算法,并將其作為節(jié)點(diǎn)的屬性寫入知識圖譜中,可以體現(xiàn)出節(jié)點(diǎn)的重要程度和群聚程度,增強(qiáng)可視化效果。
結(jié)語
本文旨在探討基于知識圖譜的信創(chuàng)知識倉庫設(shè)計(jì)和構(gòu)建,并在信創(chuàng)領(lǐng)域中探索知識圖譜的應(yīng)用潛力。通過文獻(xiàn)綜述、方法學(xué)設(shè)計(jì)、基于知識圖譜的信創(chuàng)知識倉庫的具體設(shè)計(jì),得出以下結(jié)論:
首先,信創(chuàng)領(lǐng)域在知識管理方面面臨諸多挑戰(zhàn),現(xiàn)有的知識管理系統(tǒng)無法滿足信創(chuàng)領(lǐng)域的知識管理需求,因此有必要引入新的知識管理方式。
其次,知識圖譜作為一種新興的知識管理工具,在其他許多領(lǐng)域都取得了不錯(cuò)的效果,通過構(gòu)建基于知識圖譜的信創(chuàng)知識倉庫可以更好地對信創(chuàng)領(lǐng)域進(jìn)行有效的資源管理。
最后,本文詳細(xì)介紹了知識圖譜的構(gòu)建過程,并結(jié)合信創(chuàng)領(lǐng)域的特點(diǎn)提出了基于知識圖譜的信創(chuàng)知識倉庫的構(gòu)建思路,以及可視化展示的多種策略。
綜上所述,基于知識圖譜的信創(chuàng)知識倉庫為信創(chuàng)領(lǐng)域的知識管理帶來了新的思路。在未來的發(fā)展中,我們有信心通過不斷地實(shí)踐和創(chuàng)新,進(jìn)一步推動知識圖譜在信創(chuàng)領(lǐng)域的廣泛應(yīng)用。
基金項(xiàng)目:天津市科技計(jì)劃項(xiàng)目(No.22KPXMRC00210)項(xiàng)目資助;天津市普通高校本科教學(xué)質(zhì)量與教學(xué)改革研究計(jì)劃重點(diǎn)項(xiàng)目(A231005701)。
