基于Python的加權K-means聚類算法研究
2024-12-10 00:00:00孫晶
中國新技術新產品 2024年19期


摘 要:本文針對K均值聚類算法在現實問題中的復雜性提出一種加權的聚類算法。K-means算法是一種經典的聚類算法,針對這種算法中的問題,目前有很多處理方法,例如確定初始聚類數K值、選擇初始聚類中心點、數據點的權重影響以及孤立點的處理方式等。在實際問題中,坐標數據點的權重不同,本文將權值附加在數據點中,再使用肘部法則計算聚類數K值的最佳選擇,分析數據點歸屬的簇。在數據集中進行比較,試驗結果表明,與原算法相比,本文算法更接近實際數據分布,輪廓系數更接近1,聚類效果更好。
關鍵詞:加權K-means算法;肘部法則;輪廓系數
中圖分類號:TP 312" " " " " " 文獻標志碼:A
21世紀是信息時代,大量數據利用聚類算法挖掘有效的信息,聚類算法在各個方面得到了新的發展。例如其與深度學習結合,利用深度學習來提高聚類性能,成為無監督學習領域的研究熱點。再例如其與圖像識別領域結合,有研究提出一種基于余弦定理和K-means的識別方法[1]。將聚類算法應用于大規模數據集,探索在串行計算環境中基于樣例選擇、增量學習、特征子集和特征轉換的聚類算法[2]。K-means算法在確定算法中聚類數目 K值、初始聚類中心選取、離群點的檢測與去除以及距離與相似性度量等方面有一定的局限性[3]。針對初始點問題,可以使用粒子群優化(Particle Swarm Optimization,PSO)算法,收斂速度較快[4]。在全局搜索能力提升的基礎上,優化局部搜索策略,使其在進化過程中始終保持勘探能力最佳[5]。基于密度算法優化初始聚類中心,這種方法能夠優化聚類結果[6],根據距離和的思想消除聚類分析結果中的孤立點的影響[7-8]。
1 相關概念介紹
1.1 K-means聚類算法
K-means算法是一種基于劃分的無監督學習的聚類算法,采用歐式距離作為衡量數據對象間相似度的指標,相似度與數據對象間的距離成反比,相似度越大,距離越小。K-means算法預定義K的值[4],指定K個初始聚類中心,并將給定數據集劃分為K個簇,經過多次迭代不斷降低類簇的誤差平方和(Sum of Squared Error,SSE),最小化簇內平方和(Within-Cluster Sum of Squares,WCSS),當簇中心點以及數據所屬簇趨于穩定時,聚類結束,得到最終結果。
給定一個數據集X={x1,x2,...,xn},每個xi屬于d維空間,預定義簇的數量 K,K-means的作用是找到使以下目標函數最小化的簇中心μ={μ1,μ2,...,μK},如公式(1)所示。
數據點至其所屬簇的中心點的距離的平方和,其值越小,聚類效果越好。
該算法計算數據集中每個數據點至所有初始數據中心的距離的最小值,將其分配至最近的中心點所屬的簇中,并不斷更新簇中心點的坐標,迭代計算數據點所屬的新簇,直至算法收斂為止,將數據分割為誤差平方和最小的K個簇。
1.2 加權K-means聚類算法
在傳統的K-means聚類算法中,每個數據點對聚類的貢獻都是相同的。但是,在實際問題中,有許多要素對數據點有加成或削弱作用。為了解決這個問題,采用數據點加權的聚類算法。一種常見的加權聚類算法是加權K-means算法,這種加權距離能夠同時捕捉數據點之間的全局空間關聯和局部變化趨勢。在這個算法中[9],每個目標數據點都賦予1個權值,這個權值反映了數據點在聚類過程中的重要程度,將權值附加在計算K-means算法過程中,得到更具有代表性的聚類結果。
具體來說,假設數據點X={x1,x2,...,xn},每個點xi都有一個相應的權重wi,那么加權K-means算法的目標函數如公式(2)所示。
加權K-means算法的基本步驟如下。輸入:數據集為X,數據點權重為W,預定義的簇數量為K。輸出:簇中心為μ,數據點所屬簇為C。
采用加權 K-means 算法可以有效地將數據點分配至最佳的簇中。該算法有以下5個核心步驟。1)隨機選擇K個點作為初始簇中心μ0。2)計算數據集X中的每個數據點xi至每個簇中心點μi的加權距離,將該數據點分配至與其加權距離最短的簇中心點所對應的簇Ci。3)計算每個簇Ci中所有數據點的加權平均值,將其作為新的簇中心點μi。4)重復步驟2、3,直至目標函數G不再變化,算法收斂。5)輸出結果,返回簇中心μ和數據集中所有數據點所屬簇C。
加權聚類算法在計算過程中考慮了數據點差異性,提高了聚類結果的準確性和可信度,在實際生產中應用前景廣闊。
1.3 肘部法則
在聚類算法中,確定簇的個數K值是一個重要的研究方向。常用的方法包括經驗法則、肘部法則和輪廓系數等。經驗法則是基于經驗或知識來確定個數的一種常用方法,在準確性要求不高的情景中可以采用。當使用加權聚類算法時,將每個數據點按照重要程度賦予不同的權值,問題分析的緯度更多,對K的確定要求更高,因此肘部法則是一個很好的選擇。
在通常情況下,隨著K值遞增,WWCSS會逐漸降低,當到達某一點后,誤差幅度會顯著降低,出現1個肘部拐點,整條曲線呈現為肘部形狀。這個肘部對應的點的K值即最佳K值。在后續加權聚類算法中,根據K值進行計算,得到的聚類效果最好,呈現的簇的區分最明顯,也更符合實際情況。
使用肘部法則確定的合理 K值不僅可以保持聚類精度,而且可以降低算法的復雜度,為加權聚類算法的應用提供重要的指導。
2 試驗結果和分析
本文將傳統K-means算法應用于實際聚類問題中,將數據點用特征值進行加權,分析聚類效果。本文采用的測試數據集是Yelp平臺在美國賓夕法尼亞州所有餐廳的數據。在數據集中共有514條餐廳數據,每條數據包括餐廳的15個屬性信息:'business_id', 'name','neighborhood','address', 'city','state','postal_code','latitude','longitude','stars','review_count','is_open','attributes','categories','hours'。其中星級評價分為1~5級,由用戶給出,該評價是1個餐廳非常重要的信息,決定后根據餐廳星級,用戶是否會去這個餐廳就餐,因此可以將這個參數作為每行數據的權重。計算這個地區哪個范圍內的餐廳密度最高,基于城市聚集效應,以此作為推薦后續新餐廳的選址依據。為解決這個問題,采用K-means算法計算坐標點的聚類結果,并比較傳統K-means算法與加權聚類算法在聚類效果方面的差異,本文主要比較輪廓系數的值。
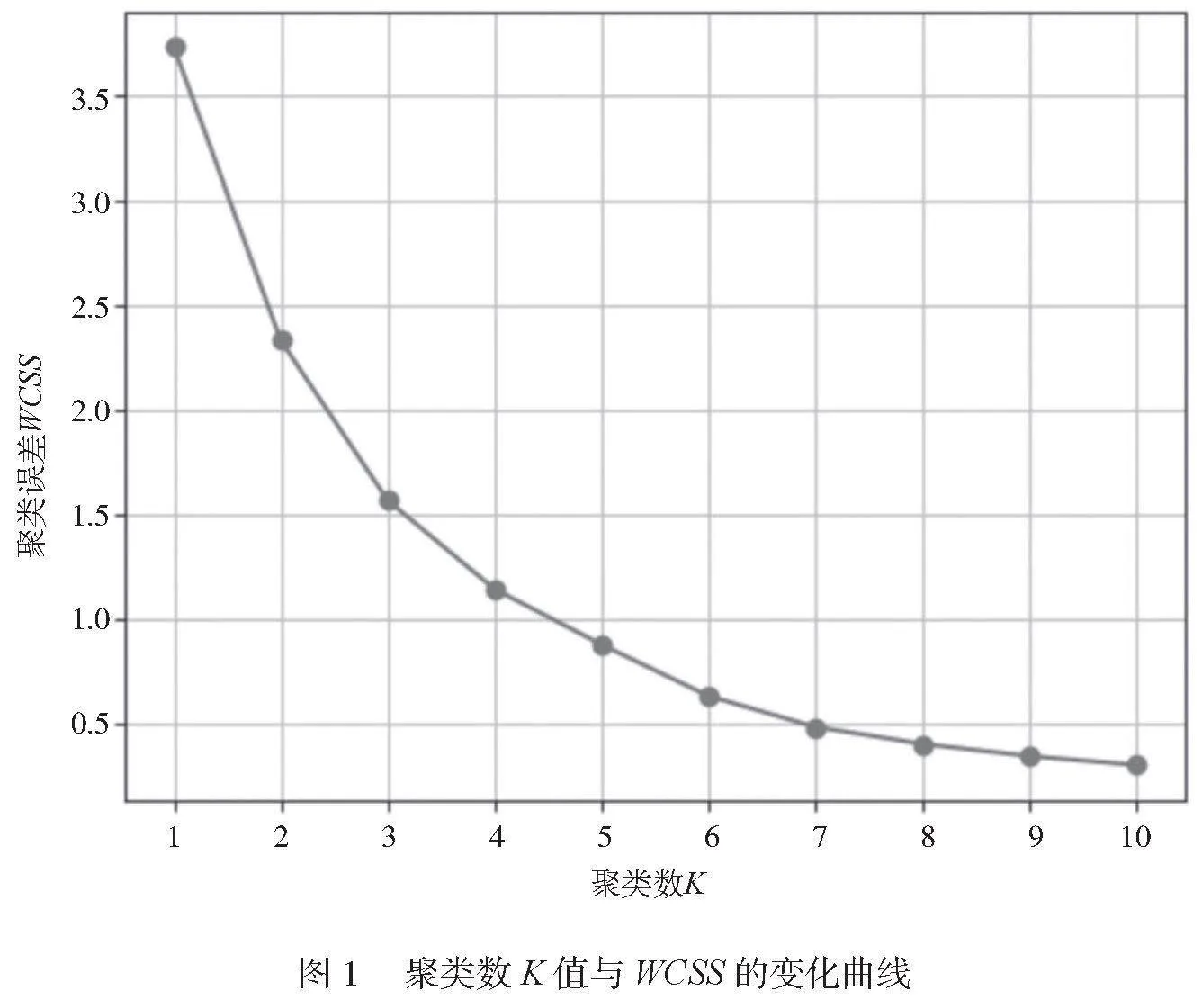
當比較2個聚類方法的問題時,通常比較2個算法的聚類誤差,誤差越小,聚類效果越好。但是本文比較的是加權聚類和傳統聚類的聚類效果,在加權的情況下考慮了每個數據點的權重,自然加權聚類誤差的WWCSS應該大于傳統聚類誤差的WCSS,因此,比較2種聚類的輪廓系數(Silhouette Coefficient)來判斷效果。輪廓系數是一種常用的聚類效果評估指標,其作用是衡量聚類的緊密度和分離度。輪廓系數的取值范圍為[-1,1],其值越接近1,聚類效果越好;其值越接近-1,聚類效果越差,值接近0表示聚類效果不明顯。基于傳統K-means算法,采用肘部法則計算這514個數據的聚類數K值,數據點使用'latitude','longitude'這2個參數作圖,聚類數K值與WCSS的變化曲線如圖1所示。
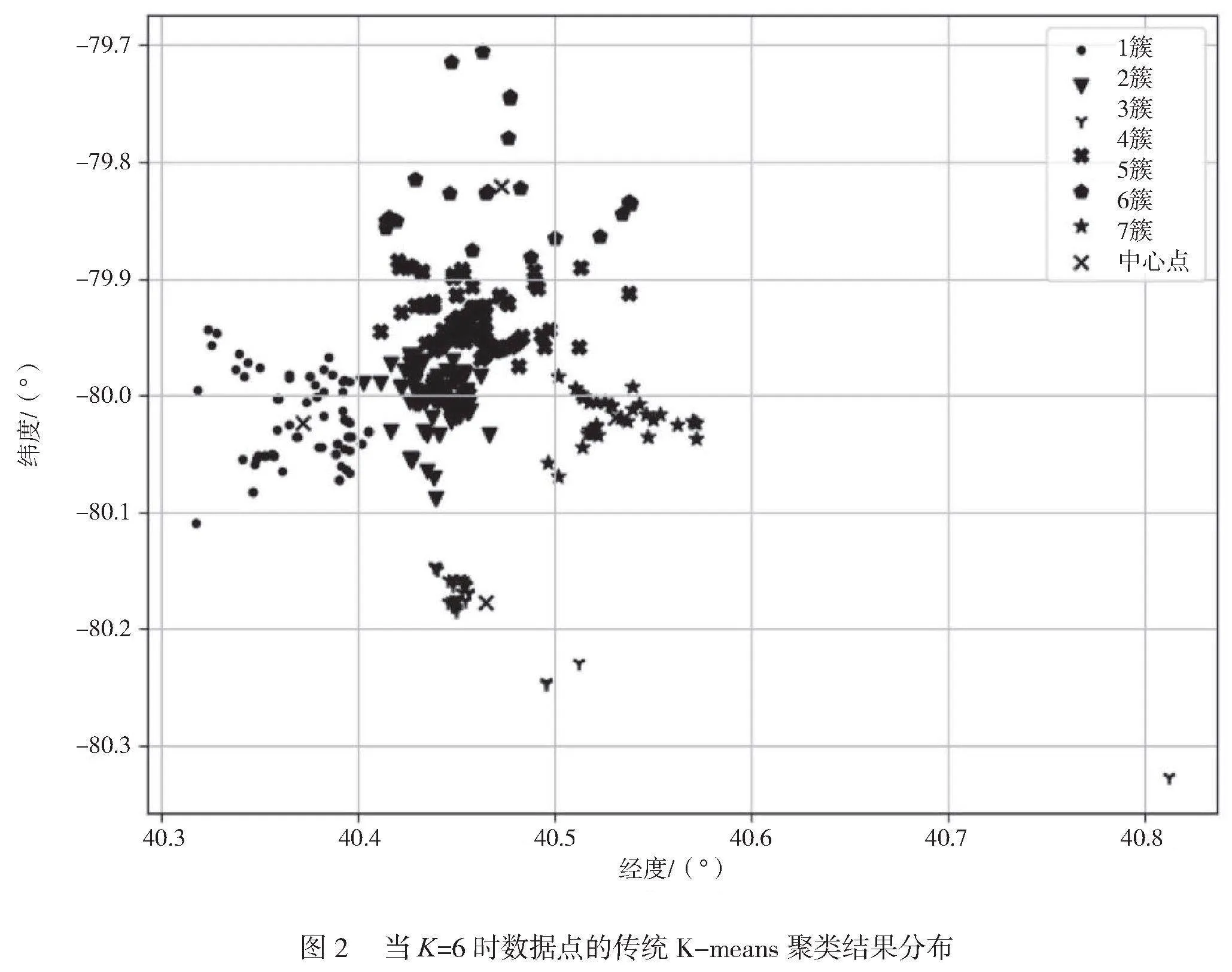
由圖1可知,曲線肘部的取值為k=6,即當聚類數為6時,聚類的效果最好。當聚類數K=6時,測試集中數據點的聚類結果分布如圖2所示。
由圖2可知,Cluster 的數據點最多,當經緯度為[40.40~40.47, -80.11~-79.94]時,可以作為后續新餐廳的選址推薦。在傳統K-means算法中,WCSS為0.632,輪廓系數為0.518。
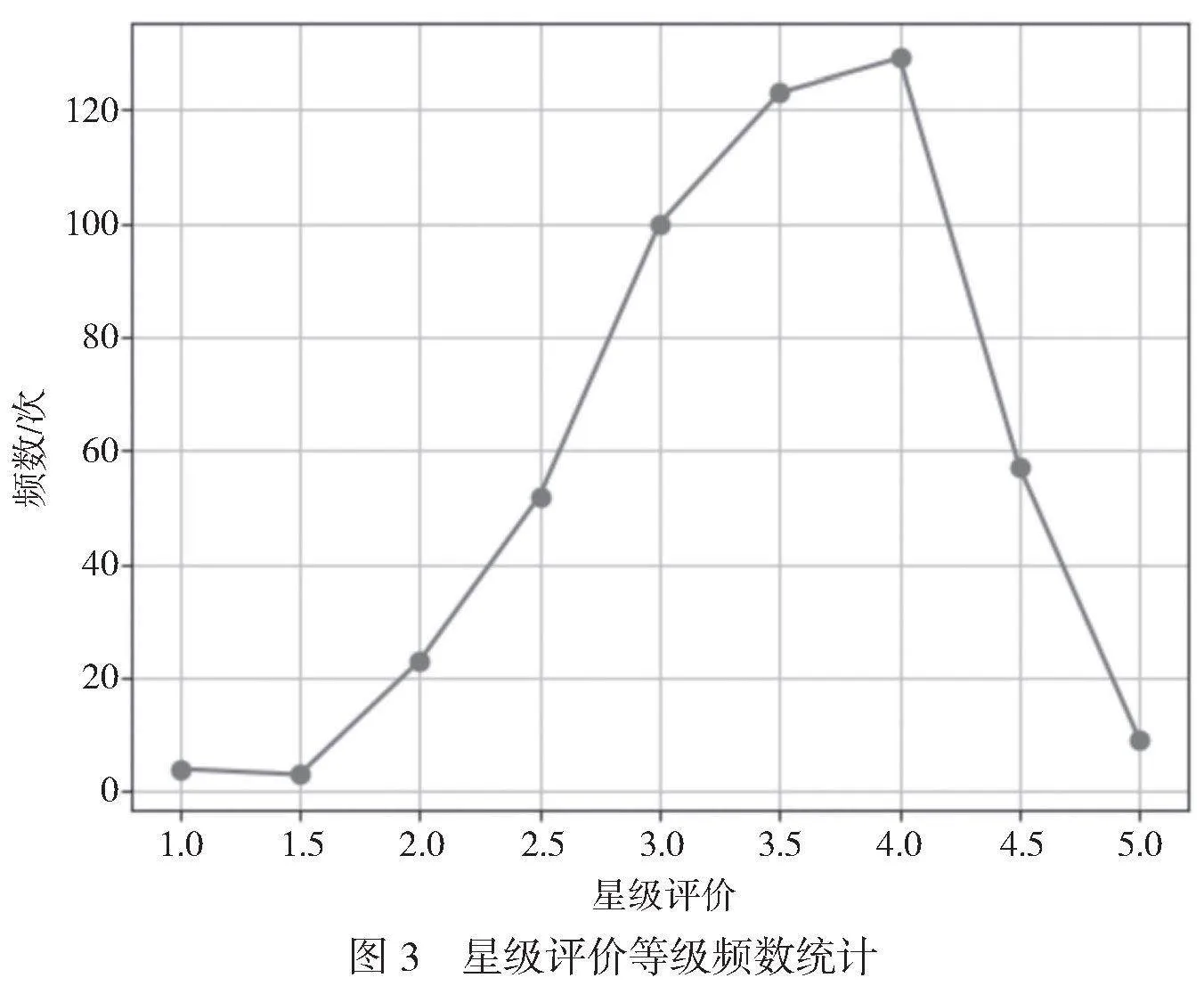
基于加權K-means算法,先統計測試集中每個數據點的權重分布情況,星級評價等級頻數統計如圖3所示。利用肘部法則計算這些數據的最佳聚類數K值。
餐廳星級評價等級為1~5。由圖3可知,顧客星級評價等級主要集中在3.0、3.5和4.0,等級兩端的出現頻率最低。也就是說514個數據點的權值分布在1~5的離散數中,3.0、3.4和4.0的出現頻率最高。
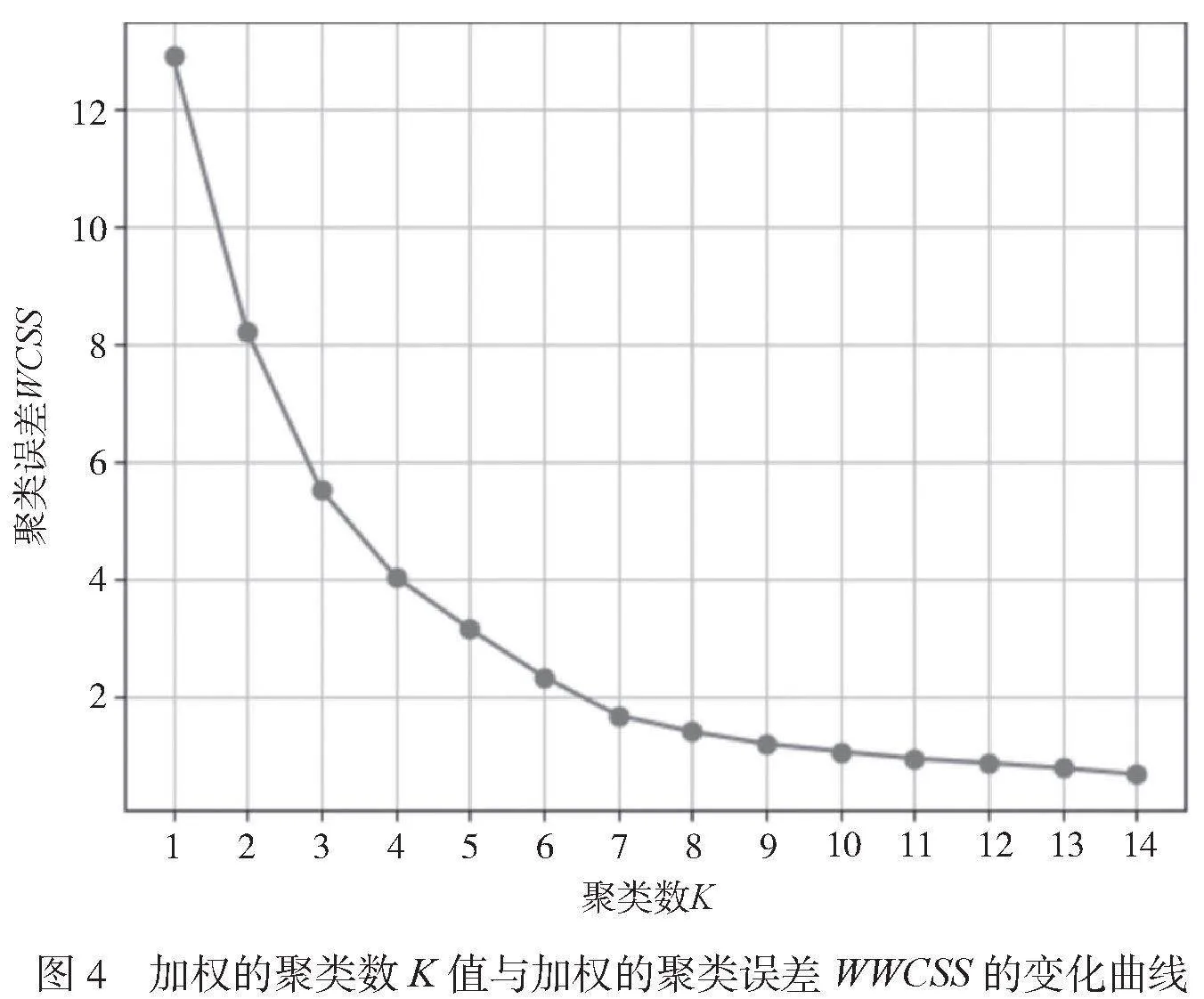
采用肘部法則計算這514個數據當使用加權聚類算法時的最佳K值,K值與WWCSS的變化曲線如圖4所示。其中橫坐標為聚類數K的值,縱坐標為加權的WWCSS。
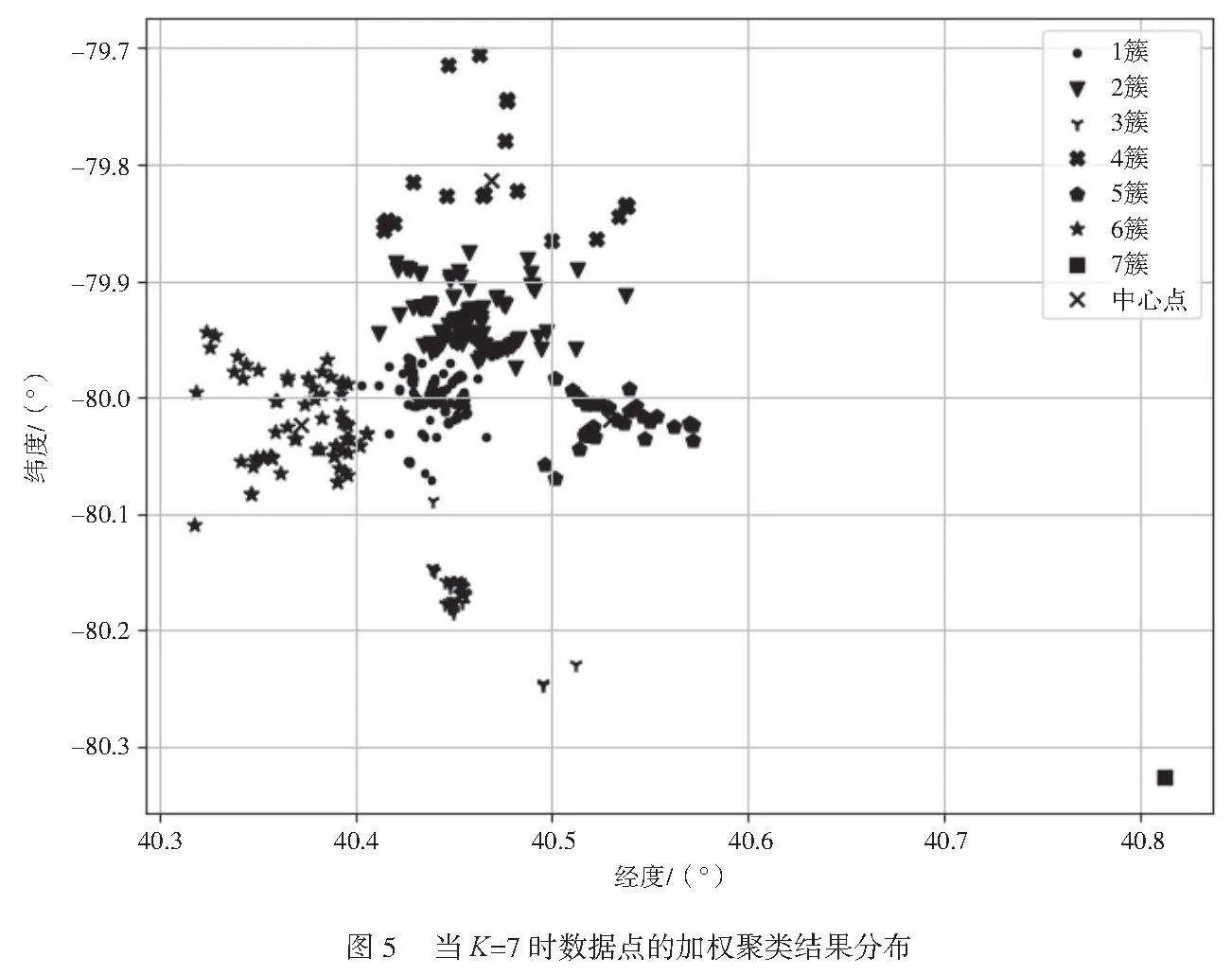
由圖4可知,拐點在7。當數據集簇的個數定位7時,WWCSS的下降趨勢有了明顯的變化,即K值確定。測試集中數據點的加權聚類結果分布如圖5所示。
由圖5可知,Cluster2的數據點最多,當經緯度為[40.41~40.54,-79.98~-79.88]時餐廳的密集度最高,可以作為后續新餐廳的選址推薦。在加權K-means算法中,WWCSS為1.669,輪廓系數為0.523。
3 結論
本文采用特征值加權的聚類方法處理坐標數據點,將聚類問題應用于復雜因素影響的數據集中。使用肘部法則確定最佳簇個數K值,最后完成數據點集合。與傳統K-means算法得到的輪廓系數相比,加權K-means得到的輪廓系數更大,更接近1,因此聚類效果更好,更符合實際情況。在實際問題中,數據點的信息是復雜的,下一步的研究重點是基于多維度給數據點加權。
參考文獻
[1]姬強,孫艷豐,胡永利,等.深度聚類算法研究綜述[J].北京工業大學學報,2021,47(8):912-924.
[2]朱顥東,申圳.基于余弦定理和K-means的植物葉片識別方法[J].華中師范大學學報(自然科學版),2014,48(5):650-655.
[3]何玉林,黃哲學.大規模數據集聚類算法的研究進展[J].深圳大學學報(理工版),2019,36(1):4-17.
[4]楊俊闖,趙超.K-means聚類算法研究綜述[J].計算機工程與應用,2019,55(23):7-14,63.
[5]劉靖明,韓麗川,侯立文.基于粒子群的K均值聚類算法[J].系統工程理論與實踐,2005(6):54-58.
[6]陶新民,徐晶,楊立標,等.一種改進的粒子群和K均值混合聚類算法[J].電子與信息學報,2010,32(1):92-97.
[7]傅德勝,周辰.基于密度的改進K均值算法及實現[J].計算機應用,2011,31(2):432-434.
[8]周愛武,于亞飛.K-Means聚類算法的研究[J].計算機技術與發展,2011,21(2):62-65.
[9]NING" Z" L,CHEN" J,HUANG" J" J ,et al.WeDIV -An improved"k-means clustering algorithm with a weighted distance and a novel"internal validation index[J].Egyptian Informatics Journal,2022,23(4):133-144.
