IT監控中的三層智能關聯實現及應用實踐
2024-12-08 00:00:00邊江濤
中國新技術新產品
2024年9期




摘 要:本文提出了一種基于三層智能關聯的監控框架。該框架專注于SaaS/PaaS/IaaS三層資源的統一管理和關聯,利用智能關聯技術自動識別資源實體并構建資源間的關聯關系。采用多維時序指標算法和事件鏈法2種方法,針對異常檢測和根因分析提供有效的解決方案。在北京電信CRM系統中的實際應用中驗證了這些方法的有效性,成功診斷了多個異常情況,證明了該監控框架在實踐中的可行性。該框架為各種IT系統監控提供新的思路和解決方案,提高資源管理的自動化水平和故障排除的效率,對企業的運維和管理有重要的價值。
關鍵詞:IT監控;智能關聯;SaaS;PaaS;IaaS;根因定位
中圖分類號:TP 391 " " " " " " 文獻標志碼:A
隨著IT系統數字化架構不斷更新,其架構復雜度逐漸提升。當面臨復雜多變的IT基礎設施時,傳統的IT監控系統面臨很多挑戰,由于數據增長速度快,因此監控范圍變得更廣。通過監控系統只能看到表面現象,不能看出潛在的問題。因此,智能關聯技術的應用顯得尤為重要。智能關聯允許監控系統跨越不同層級的IT資源,通過關聯分析和智能處理,將不同層級的資源關聯起來。采用該技術可以通過監控系統快速追溯問題的根源。
1 三層智能關聯的總體設計
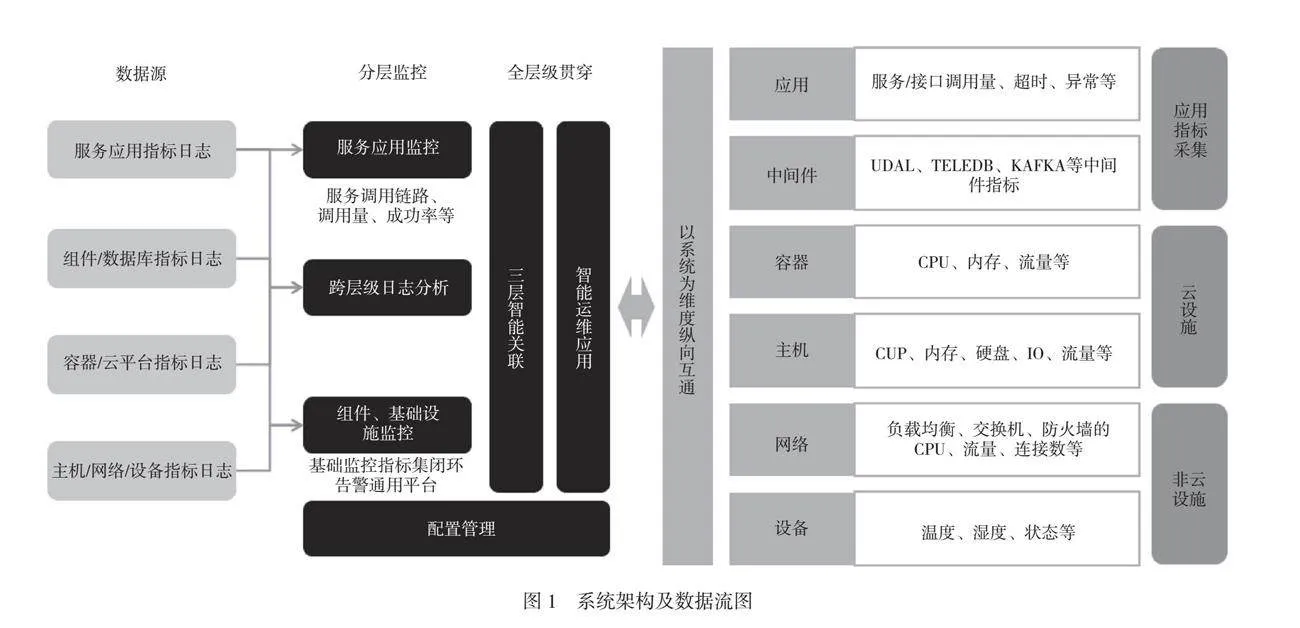
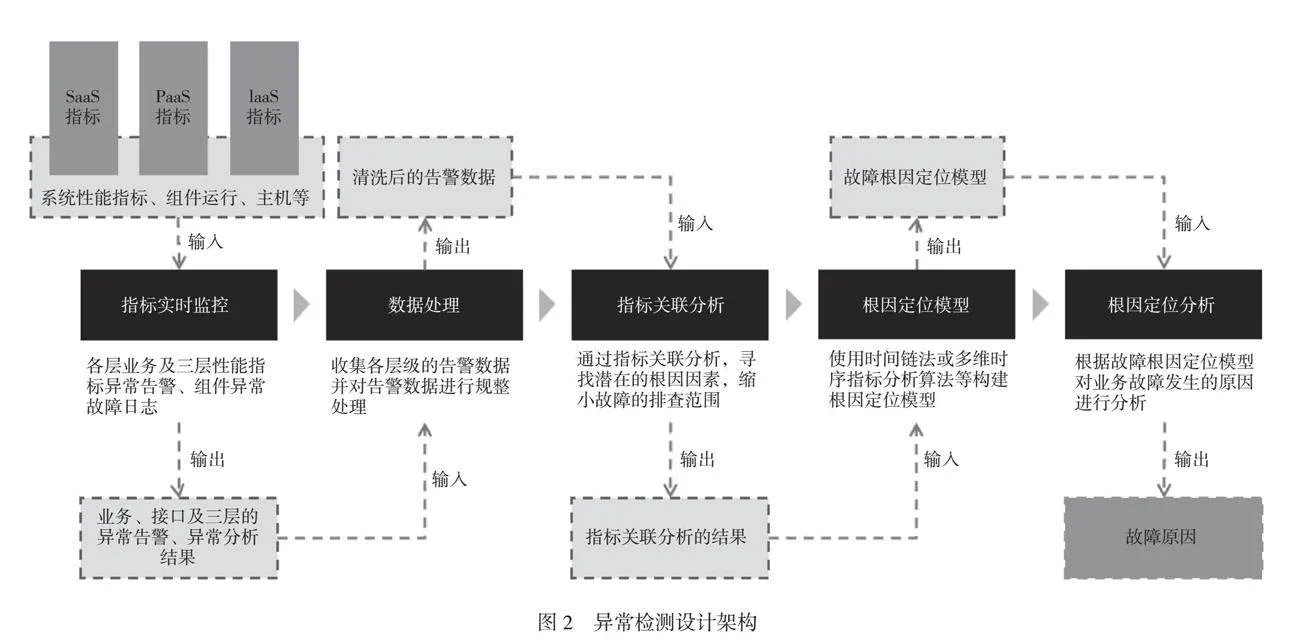
本文搭建基于三層智能關聯的一體化運維監控平臺,該平臺監控對象范圍覆蓋信息系統數據流轉和業務處理全過程,從上到下依次為SaaS、PaaS、IaaS三層的全部軟、硬設備和資源對象。平臺通過配置數據庫(CMDB)集中統一管理服務間調用關系、實體間的承載關系、設備的物理連接關系三類關系信息,具有告警收斂、異常檢測以及根因定位等智能運維功能。……
登錄APP查看全文
