鐵路信號系統故障預警與預防維護技術探索
2024-12-08 00:00:00趙寶全
中國新技術新產品
2024年9期
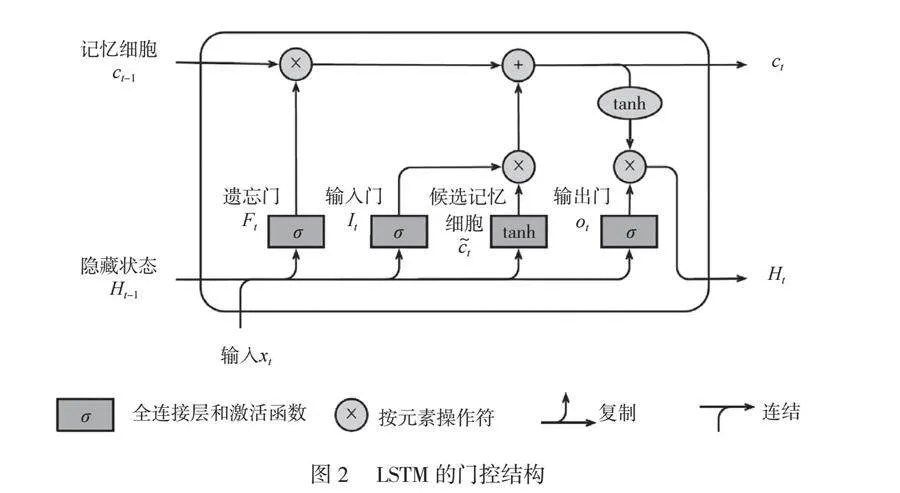

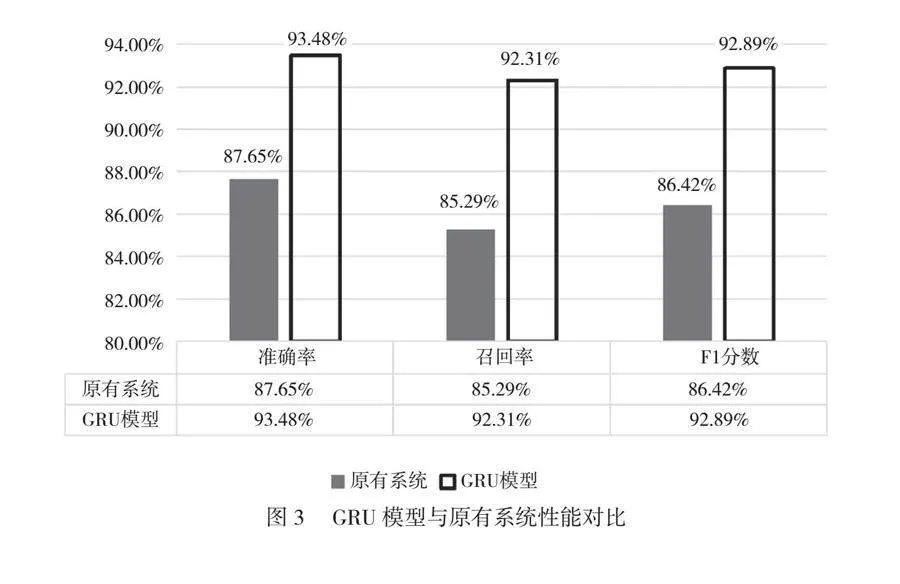
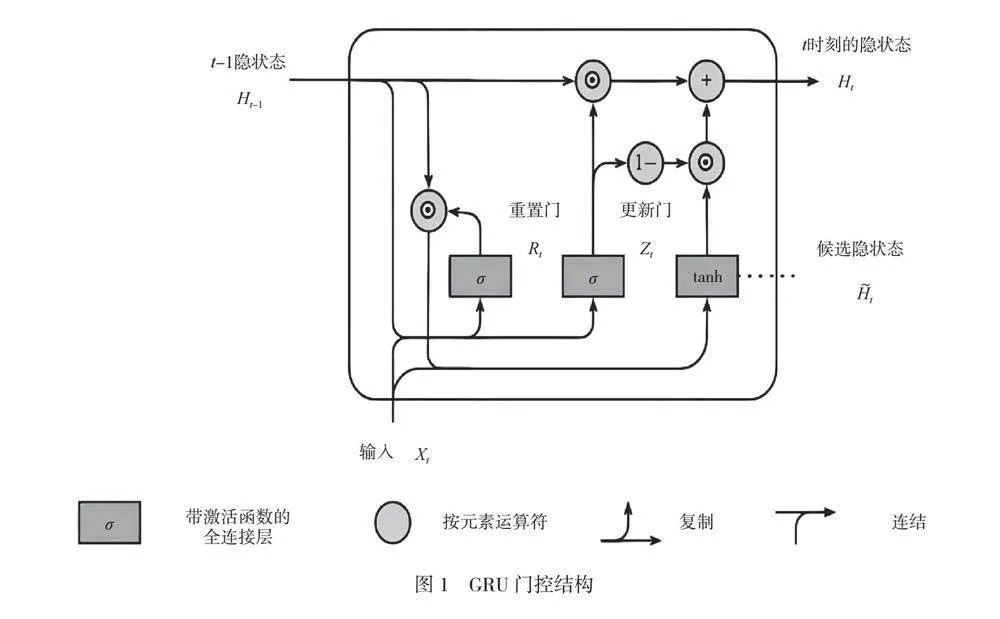





摘 要:隨著信息技術發展,鐵路信號系統的復雜性和外界環境的不確定性使故障發生的概率越來越高。為了優化故障預警系統,更好地應用預防維護技術,本文提出了基于局部加權回歸(Locally Weighted Regression,LOESS)和經驗模態分解(Ensemble Empirical Mode Decomposition,EEMD)的數據預處理系統,利用主成分分析(Principal Component Analysis,PCA)和自動編碼器提取并優化數據特征,構建基于門控循環單元(Glavnoe Razvedivatelnoe Upravlenie, GRU)的故障預測模型以及基于長短期記憶網絡(Long Short-Term Memory,LSTM)的預測性維護模型。研究結果表明,本文提出的模型能夠提高故障預警的準確性,為鐵路信號系統的穩定運行提供技術支持,保障鐵路交通的安全性,提升了運行效率。
關鍵詞:鐵路信號系統;故障預警;預防維護
中圖分類號:U 284 " " " " 文獻標志碼:A
鐵路交通是現代交通體系的重要組成部分,其安全性和可靠性受到廣泛關注。由于鐵路信號系統具有復雜性,因此故障發生的概率較高,一旦出現故障,就可能導致列車晚點、停運,甚至發生重大安全事故。因此,本文研究鐵路信號系統故障預警技術,優化數據預處理、提取特征、構建故障預測模型以及設計預防維護策略等環節,提高鐵路信號系統的故障診斷準確率和維護效率,保障鐵路交通安全。
1 數據預處理與特征提取技術
1.1 數據預處理與特征提取
采用數據預處理與特征提取技術進行故障檢測。LOESS能夠探索信號數據中的局部結構,以提高故障檢測的準確性。LOESS的核心思想是在給定數據點附近擬合一個簡單模型。對每個預測點Xi來說,LOESS對第i個數據點Yi進行局部擬合,如公式(1)所示。……
登錄APP查看全文
