基于中文文本相似度評估的情感勒索話語檢測系統
2024-10-14 00:00:00林文晟楊觀賜鐘世昊
計算機應用研究 2024年10期












摘 要:情感勒索是通過情感壓力迫使周圍人聽從自己要求的交流方式,容易導致對方的負面情緒甚至心理問題從而影響交流效果。為了檢測日常交流場景下的情感勒索話語進而改善交流效果,開發了基于中文文本相似度評估的情感勒索話語檢測系統。首先,基于Susan Forward的情感勒索理論標注收集到的數據,構建情感勒索語料庫和測試集;其次,分析情感勒索的表達方式,分別基于詞性和語義詞設計文本相似度評估方法,進而形成基于中文文本相似度評估的情感勒索話語檢測算法;然后,在構建的數據集上開展實驗,該算法獲得的平均recall與F1-score分別為95.21%和79.95%,優于對比算法;最后,基于該算法開發情感勒索話語檢測原型系統,系統在不同測試條件下的平均recall為87.24%,展現出良好的魯棒性和檢測性能。
關鍵詞:智能系統; 情感勒索話語檢測; 文本表達方式; 相似度評估
中圖分類號:TP391 文獻標志碼:A
文章編號:1001-3695(2024)10-027-3073-08
doi:10.19734/j.issn.1001-3695.2024.02.0052
Emotional blackmail utterance detection system based on Chinese text similarity evaluation
Lin Wensheng, Yang Guanci, Zhong Shihao
(Key Laboratory of Advanced Manufacturing Technology of the Ministry of Education, Guizhou University, Guiyang 550025, China)
Abstract:Emotional blackmail is a way of communication that forces people around them to listen to their requirements by emotional pressure. It can easily lead to negative emotions and even psychological problems of the other side, then affect the communication effect. In order to detect emotional blackmail utterance in daily communication scenarios and improve the communication effect, this paper developed an emotional blackmail utterance detection system based on Chinese text similarity evaluation. Firstly, this paper labelled the collected data based on Susan Forward’s emotional blackmail theory, and constructed an emotional blackmail corpus and a test set. Secondly, this paper analyzed the expression modes of emotional blackmail, and designed text similarity evaluation methods based on part of speech and semantic words respectively, then formed an emotional blackmail utterance detection algorithm based on Chinese text similarity evaluation. Thirdly, this paper carried out experiments on the constructed datasets. The average recall and F1-score of the proposed algorithm are 95.21% and 79.95% respectively, which are better than the compared algorithms. Finally, this paper integrated an emotional blackmail utterance detection prototype system based on the proposed algorithm. Under different testing conditions, system test results show that the average recall is 87.24%, which shows good robustness and detection performance.
Key words:intelligent system; emotional blackmail utterance detection; expression modes of text; similarity evaluation
0 引言
在日常交流中,人們為了讓周圍人聽從自己的要求,有時候會通過情感壓力來向他們施壓。例如,在提出建議時強調“為你好”;告知對方若不服從要求自己會受到傷害等。美國心理治療師Forward等人[1]從心理學角度研究了上述行為,發現該行為的動機皆為逼迫對方滿足自己的要求,與勒索的心理相似,故將其命名為情感勒索。之所以在“勒索”前面加上“情感”二字,是因為情感勒索發生在周圍人的日常交流中,雙方關系密切導致一方難以擺脫另一方的控制。而勒索是為了圖財而專門采取的違法行為,可以尋求法律保護。因此,情感勒索的受害者往往受困于情感紐帶從而難以擺脫對方的控制,容易陷入負面情緒[2]而變得敏感易怒而不聽建議[3],甚至引發抑郁等心理問題[4]作出自殺舉動[5],難以與外界進行有效交流。隨著人工智能技術的發展,關于機器自動檢測話語表達方式的研究方興未艾,如諷刺檢測[6]、幽默檢測[7]等。因此,如何利用人工智能技術檢測情感勒索話語進而改善交流效果是值得深入研究的課題。
利用人工智能技術檢測情感勒索話語,需要使機器自主區分情感勒索話語和非情感勒索話語。常規思路是采用積極學習,即在訓練階段構建出情感勒索話語分類器模型來對未知數據進行預測的方式。情感勒索話語模型的構建,需要通過數據多樣且數據量充足的情感勒索數據集實現。若數據集條件不滿足,則容易導致分類器的過擬合或欠擬合,從而影響分類性能。目前沒有公開的情感勒索數據集。現有的中文對話數據集要么是特定領域的對話語料庫(如豆瓣對話語料庫[8]、電子商務對話語料庫[9]等),要么是情感對話數據集(如M3ED[10]、CPED[11]等)。情感勒索發生在提出要求的情境。因此,不論是特定領域對話還是情感對話,都只有少量話語符合情感勒索的發生情境。故難以根據現有數據集,構建數據多樣且數據量充足的情感勒索數據集來訓練情感勒索分類器。因此,受限于情感勒索話語數據量不足的現有數據條件,積極學習的方式不適用于情感勒索話語檢測。
除了積極學習這種常規思路,還有基于預定義語法規則的非訓練方法,以及在訓練階段只存儲數據而在預測階段比較訓練數據與待預測數據的相似性的惰性學習方法兩種思路。關于前者,語法規則只能獲取表面詞匯和句法結構等文本淺層信息,難以獲取語義和主題等文本深層信息[12]。情感勒索話語與非情感勒索話語的區別在于是否包含通過施壓迫使對方聽從自己要求的語義表達,屬于文本深層信息,故基于預定義語法規則的非訓練方法不適用于情感勒索話語檢測。關于后者,無須通過充足的數據進行訓練,關鍵在于通過合適的方法比較訓練數據與待預測數據的相似性,適用于情感勒索話語數據量不足的現有數據條件。因此,本文考慮采用惰性學習的思路,通過構建小型情感勒索語料庫,將待測話語與情感勒索語料庫內的所有情感勒索話語進行相似度評估,最后綜合所有的相似度評估結果來判斷待測話語是否為情感勒索話語。在惰性學習的思路中,關鍵在于相似度評估方法的設計。于是本文調研了中文文本相似度評估方法的研究現狀,具體如下。
在中文文本相似度評估方面,文獻[13]提出基于暹羅網絡的多粒度匹配模型(multi-granularity matching model based on siamese neural network,MGMSN),不僅基于字粒度和詞粒度的深層語義匹配模塊來提高相似度評估的準確性,而且添加了基于余弦相似度的淺層語義匹配模塊以提高模型的泛化能力。文獻[14]提出基于雙向時域暹羅網絡的中藥文本相似度評價模型(traditional Chinese medicine text similarity calculation model based on the bidirectional temporal siamese network,BTSN),使用基于知識增強的持續學習語義理解框架(enhanced representation through knowledge integration,ERNIE)訓練字向量以解決中藥文本分詞不準確的問題,并使用雙向長短期記憶網絡(bi-directional long short-term memory,Bi-LSTM)[15]綜合考慮句子上下文的時間信息。文獻[16]提出圍繞結構和語義的句子相似度評估方法(two-domain coordinated sentence similarity scheme for question-answering robots regarding unpredictable outliers and non-orthogonal categories,TDCS),基于雙語評估替補方法(bilingual evaluation understudy,BLEU)進行N元匹配搜索來評估結構相似度,并采用結合基于Transformer的雙向編碼器表征方法(bidirectional encoder representation from Transformers,BERT)[17]和多核卷積神經網絡(convolutional neural networks,CNN)的深度學習方法評估語義相似度。文獻[18]提出基于多屬性融合的句子相似度評價方法(multi-attribute fusion similarity calculation method based on sentence,MAFS)。首先提取句子的語序、詞性和句子長度等屬性,其次分別計算各屬性的相似度,最后通過層次分析法[19]對各屬性的相似度進行加權融合。文獻[20]提出用于評估標準答案和學生答案之間的相似性的自動漢語評分系統(effective hybrid automated Chinese scoring system for medical education,ASS),通過《同義詞詞林》計算關鍵詞相似度[21],基于句法結構分析量化關系詞對的語義相似度。
上述工作雖然評估方法不同,但都是從兩段話是否用相同的方式表達相同含義,即表達方式一致性和表達內容一致性展開評估。而判斷待測話語是否與情感勒索話語相似,關鍵在于判斷待測話語是否像情感勒索話語那樣通過施壓迫使對方聽從自己要求,即兩者的表達方式一致性。至于要求的具體內容則不需要關注,從而無須評估表達內容一致性。對此,本文在參考現有中文文本相似度評估工作的基礎上,設計用于情感勒索話語檢測的中文文本表達方式相似度評估方法。在此基礎上,提出基于中文文本相似度評估的情感勒索話語檢測算法(emotional blackmail utterance detection algorithm based on Chinese text similarity evaluation,EBDCH),并面向日常交流場景集成基于EBDCH的情感勒索話語檢測原型系統。
1 中文情感勒索話語數據集構建
鑒于從目前的公開數據集中難以發現情感勒索話語,本章首先從三個來源收集情感勒索話語,分別是:書籍《情感勒索》[1];知乎、豆瓣等中文論壇網站;開展的情感勒索問卷調查。其中,通過閱讀書籍《情感勒索》記錄了其中的84段情感勒索話語;通過在中文論壇網站中搜索“情感勒索”,閱讀并記錄了搜索結果中的164段情感勒索話語;通過微信、QQ分享問卷鏈接進行問卷調查,收集到了986段情感勒索話語。
其次,根據相關心理學理論,制定標注規則來篩選收集到的話語。目前,關于情感勒索的心理學理論有Blau的社會交換理論[22]、Forward的情感勒索理論[1]等。其中,只有Forward的情感勒索理論定義了情感勒索的表達方式。Forward認為,情感勒索以引誘者、施暴者、自虐者和悲情者四種形態中的一種或者多種出現,讓對方感受到由恐懼感、責任感、罪惡感帶來的情感壓力,不得不服從要求。其中,引誘者強調自己這么要求是為了對方考慮,施暴者威脅對方如果不服從要求會把他們怎么樣,自虐者威脅對方如果不服從要求會對自己怎么樣,悲情者強調若對方不服從要求自己會面臨怎樣的困境。由此可見,引誘者的施壓方式是強調提出要求是為了對方好,施暴者、自虐者和悲情者的施壓方式是強調不服從要求會給對方或自己帶來的傷害。
根據該理論制定了情感勒索話語標注規則,具體如下:a)話語內容包含對于對方的要求;b)在話語內容中強調提出要求是為了對方好,或強調不服從要求會給對方或自己帶來的傷害;c)若符合規則1、2,則將話語標注為正樣本(情感勒索話語),否則標注為負樣本(非情感勒索話語);d)由3人標注,標注結果采用少數服從多數原則。
然后,基于標注規則對話語進行篩選,并刪除話語中與情感勒索表達無關的修飾詞,獲得了1 136段字數均低于50的正樣本,最后獲得情感勒索語料庫(Chinese emotional blackmail corpus,EB-CH)。表1展示了EB-CH語料庫的部分樣本,及其對應的情感勒索形態和施壓方式。
考慮到當代生活題材電視劇聚焦于本文面向的日常交流場景,因此基于《小歡喜》《小別離》和《都挺好》三部當代生活題材電視劇的對話文本構建后續實驗的測試集。首先,從CPED數據集[11]獲取上述三部電視劇的對話文本;其次,切分每段對話中不同角色的話語;然后,根據標注規則標注切分后的話語;之后,將標注的三部電視劇話語分別作為3個測試案例,最后形成測試集。表2是測試集的統計信息。
由表2可知,3個測試案例中正樣本所占比例很低。如此設置的原因如下。本文目的是檢測日常交流場景下的情感勒索話語進而改善交流效果,意味著所提算法需要在日常交流情境下的任何情境進行情感勒索話語檢測,而不是只在可能發生情感勒索的提出要求情境。因此,在篩選數據時保留了所有日常交流場景下的話語,從而導致3個測試案例中正樣本,即情感勒索話語所占比例很低。
2 基于詞性和語義詞的中文文本相似度評估方法
考慮到現有的情感勒索數據集規模不足以訓練情感勒索分類器,于是將情感勒索話語檢測由單文本分類轉變為多文本相似度評估。相應地,檢測內容就由是否具備情感勒索文本特征轉變為是否與已標注的情感勒索文本相似。如此轉變之后,機器無須從少量文本中學習情感勒索文本與非情感勒索文本之間的區別,只需要在給定角度下評估文本之間的相似程度,從而降低了檢測難度。為此,本章根據情感勒索文本表達方式給出評估角度,然后圍繞評估角度設計評估方法。
情感勒索文本表達方式為向對方施壓讓對方聽從要求,屬于行為動作,需要圍繞動詞展開。在施壓過程中,需要表達否定、轉折、強調或假設等語義,將表達這些語義的詞匯定義為語義詞。通過動詞與語義詞的各自搭配以及相互搭配,實現施壓過程。因此,將詞匯搭配作為評估角度。并把典型的詞匯搭配對應的詞性定義為詞性組合,每個詞性組合由若干詞性以及詞性之間的位置關系組成。
此外,施壓對象是對方。相應地,需要判斷詞匯搭配的關聯代詞是否指代對方。因此,也將關聯代詞作為評估角度。并把指代對方的詞定義為特定代詞,其中包括“你”“我們”及其所有格形式的代詞。
基于上述思考和定義,圍繞詞匯搭配以及關聯代詞兩個評估角度,分別基于詞性和語義詞設計中文文本相似度評估方法。
2.1 基于詞性的中文文本相似度評估方法
圍繞詞匯搭配,定義句子中任意兩個及以上的相鄰詞性組成的序列定義為詞性子序列。圍繞關聯代詞,定義與詞性子序列里每個詞性距離之和最小的代詞為詞性子序列的最近代詞。若最近代詞包含特定代詞,則用1表示最近代詞;否則用0表示最近代詞。圍繞詞性子序列及其最近代詞,設計基于詞性的中文文本相似度評估方法,具體步驟見算法1。
算法1 基于詞性的中文文本相似度評估方法
輸入:待測話語d;情感勒索文本集合Ctext(Ctext={ t1,t2,…,tj,…,tN})。
輸出:話語d與集合Ctext中所有元素的詞性相似度向量rp(rp={rp1,rp2,…,rpi,…,rpN})。
a)加載集合Ctext;將rp初始化為零向量;讀取話語d。
b)基于LTP平臺[23]獲取話語d的詞性序列Pd。
c)根據詞性類型去除詞性序列Pd的停用詞。
d)將詞性序列Pd里所有代詞和代詞位置存儲到集合Cir。
e)從j=1到j=N:
(a)基于LTP平臺獲取文本tj的詞性序列Ptext(Ptext={p1text,p2text,…,pytext,…,pmtext})。
(b)檢測詞性序列Pd與Ptext的相同詞性子序列,將檢測到的序列存儲到集合Pp;將檢測到的序列在話語d的位置存儲到集合Ldp;將檢測到的序列在文本tj的位置存儲到集合Lsd。
(c)統計集合Pp包含的詞性子序列數量mp以及詞性數量mdp。
(d)根據集合Ldp和Cir,獲取檢測到的序列在話語d的最近代詞,存儲到集合Udp。
(e)將詞性序列Ptext里所有代詞和代詞位置存儲到集合Ctr。
(f)根據集合Ldp和Ctr,獲取檢測到的序列在文本tj的最近代詞,存儲到集合Usd。
(g)統計集合Udp與Usd的相同最近代詞數量mdpsd。
(h)rpj=mdp/m×mdpsd/mp。
f)輸出rp。
步驟b)所用的LTP平臺是個開放的中文語言技術平臺,基于該平臺依次進行分詞和詞性標注,獲取話語d的詞性序列Pd。
步驟c)的目的是消除與情感勒索文本表達無關的詞性對相似度評估的影響,其中包括標點符號、量詞等詞性類型的詞,將它們稱為停用詞。去除停用詞后,每段文本僅由助詞、形容詞、副詞、連詞、代詞、動詞、方位詞、時間名詞和介詞組成。
在步驟e)中,用rpj=mdp/m×mdpsd/mp評估待測話語d與集合Ctext中任意情感勒索文本tj的詞性相似度。其中,mdp/m表示檢測到的序列的詞性數量之和與文本tj詞性數量之間的比值,用于表示兩文本的詞匯搭配相似度。mdpsd/mp用于評估每段檢測到的序列在兩文本的最近代詞是否相同,表示兩文本的關聯代詞相似度。
2.2 基于語義詞的中文文本相似度評估方法
圍繞語義詞搭配進行相似度評估,首先需要獲取待測話語和情感勒索文本的語義詞。待測話語屬于未知文本,因此無法事先獲取到待測話語的語義詞。于是從已知的情感勒索文本出發,標注情感勒索文本集合Ctext里每段文本的語義詞,進而獲取到每段文本的語義詞序列WjSW={w1sw,w2sw,…,wysw,…,wesw},最后獲得情感勒索文本的語義詞序列集合Csw={W1sw,W2sw,…,Wjsw,…,WNsw}。圍繞關聯代詞,定義與語義詞距離最小的代詞為語義詞的最近代詞,表示方法與2.1節詞性子序列的最近代詞相同。圍繞語義詞及其最近代詞,設計基于語義詞的中文文本相似度評估方法,具體步驟見算法2。
算法2 基于語義詞的中文文本相似度評估方法
輸入:待測話語d;情感勒索文本集合Ctext(Ctext={ t1,t2,…,tj,…,tN});情感勒索文本的語義詞序列集合Csw={W1sw,W2sw,…,Wjsw,…,WNsw}。
輸出:話語d與集合Ctext中所有元素的詞性相似度向量rw(rw={rw1,rw2,…,rwj,…,rwN})。
a)加載集合Ctext和Csw;將rw初始化為零向量;讀取話語d。
b)基于LTP平臺獲取話語d的詞序列Wd和詞性序列Pd。
c)將詞性序列Pd里所有代詞和代詞位置存儲到集合Cir。
d)從j=1到j=N:
(a)基于LTP平臺獲取文本tj的詞序列Wtext和詞性序列Ptext(Wtext={w1text,w2text,…,wytext,…,wmtext},Ptext={p1text,p2text,…,pytext,…,pmtext})。
(b)基于OpenHowNet知識庫[24]檢測詞序列Wd與語義詞序列Wjsw的相似語義詞,將檢測到的相似語義詞存儲到集合Ww;將檢測到的相似語義詞在序列Wd的位置存儲到集合Lds;將檢測到的相似語義詞在序列Wtext的位置存儲到集合Lss。
(c)統計集合Ww包含的相似語義詞數量ew。
(d)根據集合Lds和集合Cir,獲取相似語義詞在詞序列Wd的最近代詞,存儲到集合Uds。
(e)將詞性序列Ptext里所有代詞和代詞位置存儲到集合Ctr。
(f)根據集合Lds和Ctr,獲取相似語義詞在詞序列Wtext的最近代詞,存儲到集合Uss。
(g)統計集合Uds與Uss的相同最近代詞數量edsss。
(h)rwj=ew/e×edsss/ew。
e)輸出rw。
步驟d)中,子步驟(b)所用的OpenHowNet知識庫是開源的語義網絡知識庫,使用該知識庫實現基于義原的詞相似度計算,獲取詞序列Wd與語義詞序列Wjsw的相似語義詞。子步驟(h)用rwj=ew/e×edsss/ew評估待測話語d與集合Ctext中任意情感勒索文本tj的語義詞相似度。其中,ew/e表示檢測到的相似語義詞數量之和與文本tj的語義詞數量之間的比值,用于表示兩文本的詞匯搭配相似度。edsss/ew用于評估每個相似語義詞在兩文本的最近代詞是否相同,用于表示兩文本的關聯代詞相似度。
3 基于中文文本相似度評估的情感勒索話語檢測算法EBDCH
為了檢測話語內容中是否包含情感勒索,本章從自然語言處理角度出發,在第2章提出的相似度評估方法基礎上,提出了基于中文文本相似度評估的情感勒索話語檢測算法EBDCH,具體步驟見算法3。
算法3 基于中文文本相似度評估的情感勒索話語檢測算法EBDCH
輸入:待測話語d;情感勒索文本集合Ctext;相似度評估的閾值T。
輸出:話語d的情感勒索檢測結果R(true或false)。
a)加載集合Ctext;初始化R=false;讀取話語d。
b)根據標點將話語d切分成字數不超過50的文本集合Cd={d1,d2,…,di,…,dn}。
c)從i=1到i=n:
(a)在文本di檢測特定代詞和詞性組合,獲得檢測結果Di(true或false)。
(b)如果Di==false,即沒有檢測到特定代詞和詞性組合,則R=false。
(c)如果Di==true,即檢測到了特定代詞和詞性組合:
運用算法1計算文本di與集合Ctext中所有元素的詞性相似度向量rip,運用算法2計算文本di與集合Ctext中所有元素的語義詞相似度向量riw;將詞性相似度向量rip與語義詞相似度向量riw進行融合,獲取最大總相似度ritotal;
如果ritotal≥T,則R=true,結束循環;否則,R=false。
d)輸出R。
步驟b)用于限制輸入文本長度。文本切分方式如下:首先,切分出前50個字組成的文本d1。其次,在d1中使用逐字匹配的方式檢測標點。若檢測到標點,則d2的起點為標點后一個字;否則,d2的起點為d1后一個字。然后,在選定切分起點后,判斷剩余文本字數是否超過50。若超過50,則d2為50字文本,否則d2為剩余文本。之后,循環上述基于標點的切分過程,直到剩余文本字數不超過50為止,這樣便得到了d3,d4,…,dn。最后,得到字數不超過50的文本集合Cd。這里把輸入文本的字數限制設為50,是因為后續實驗由EB-CH語料庫提供情感勒索文本集合Ctext,而EB-CH語料庫的文本字數均低于50。
在步驟c),特定代詞和詞性組合的定義見第2章。其中,特定代詞是文本di與對方相關的必要條件,詞性組合是施壓的必要條件。只有當文本di同時具有特定代詞和詞性組合時,該文本才具備情感勒索表達的必要條件,檢測結果Di=true;否則該文本不具備情感勒索表達的必要條件,檢測結果Di=false。當文本不具備情感勒索表達的必要條件時,自然無法表達情感勒索,故若Di==false,則R=false。子步驟(c)獲取最大總相似度ritotal的過程如下。首先,計算總相似度向量ritotal=a·rip+b·riw,其中a和b為互補權重,有a+b=1。其次,找出向量ritotal中數值最大的元素,記為最大總相似度ritotal。若ritotal≥T,則R=true,說明文本di包含情感勒索,從而輸入文本d包含情感勒索,循環終止;否則R=false,循環繼續。權重a和b以及閾值T的取值將在第4章通過實驗確定。
4 EBDCH算法性能測試與分析
在本章實驗中,EBDCH算法的待測話語d來源于測試集,情感勒索文本集合Ctext來源于EB-CH語料庫。評價指標均采用precision、recall和F1-score,它們的計算公式分別為
precision=TPTP+FP(1)
recall=TPTP+FN(2)
F1-score=2×precision×recallprecision+recall(3)
其中:TP(true positive)表示預測結果為真,標簽為正的樣本;FP(false positive)表示預測結果為假,標簽為正的樣本;FN(false negative)表示預測結果為假,標簽為負的樣本。
4.1 參數選擇實驗
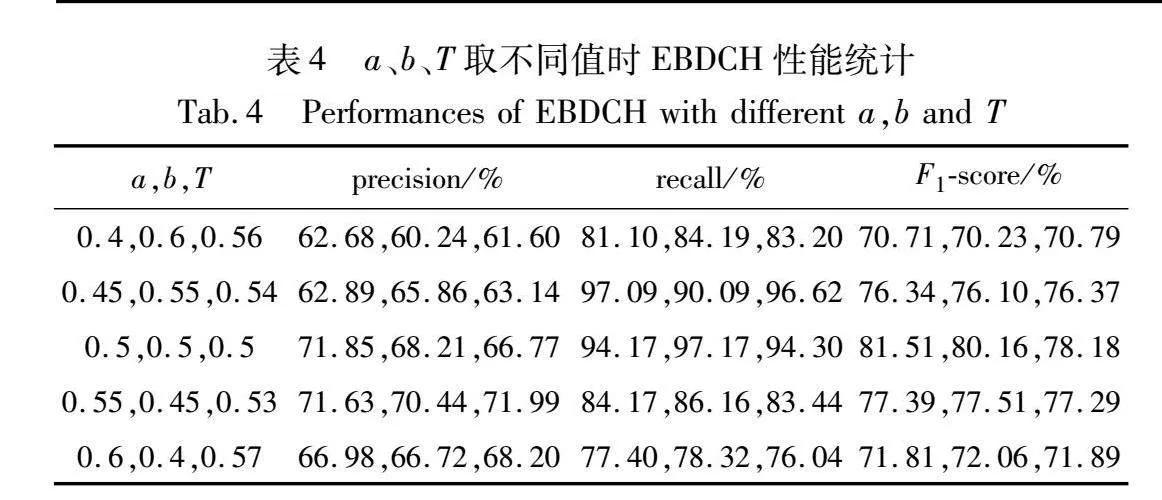
為了給EBDCH算法選擇合適的a、b、T的值,在本節中,首先設置不同的a、b值,然后進行受試者工作特征(receiver operating characteristic curve,ROC)曲線分析,得到T值,進而得到EBDCH算法的結果。最后,通過比較EBDCH算法在不同的a、b、T值下的結果,選擇合適的a、b、T值。
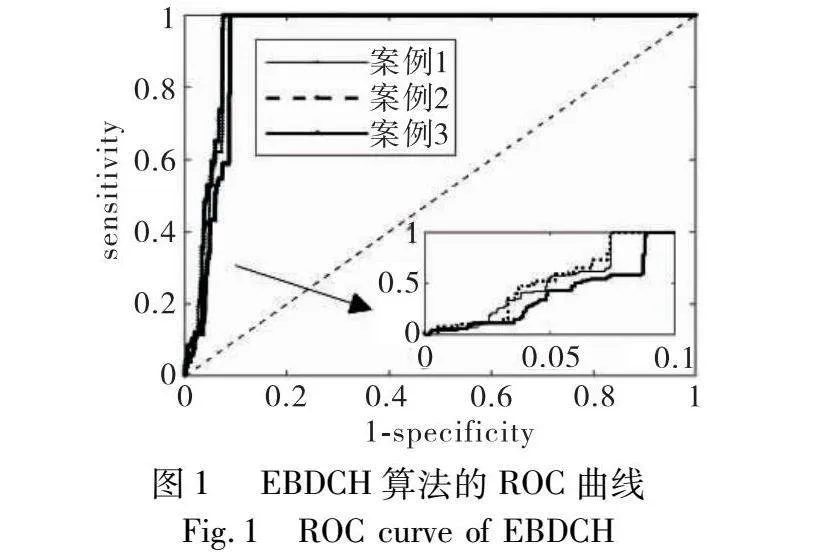
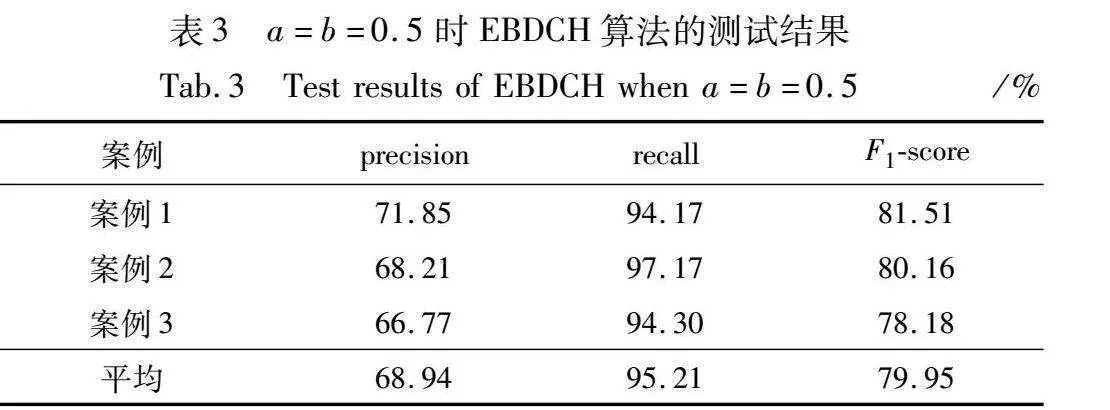
首先設置a=b=0.5,然后進行ROC曲線分析(見圖1)。不同曲線下的面積幾乎相等,說明EBDCH算法在不同測試案例上分類器性能相似,說明EBDCH算法的泛化性較好。ROC曲線的截斷點為youden index=sensitivity+specificity-1取最大值所對應的點。其中,sensitivity=TP/(TP+FN),specificity=TN/(TN+FP),TN(true negative)表示預測結果為真,標簽為假的樣本。經計算,三個測試案例的ROC曲線截斷點分別為0.496、0.503、0.501。取T=0.5,獲得了EBDCH算法在測試集上的結果(見表3)。
設置不同的a、b值,重復上述步驟。表4統計了EBDCH算法在不同a、b、T值下的結果。a=b=0.5時的F1-score明顯高于a、b、T取其他值時的F1-score,且隨著|a-b|的增大,F1-score逐漸降低,因此選取a=b=0.5。
4.2 中文文本相似度評估方法對比實驗
為了給EBDCH算法選擇合適的文本相似度評估方法,將引言中討論的5種中文文本相似度評估方法與本文方法進行對比實驗。首先,根據是否需要在訓練階段構建模型將這些方法分為兩類。一種是需要在訓練階段構建模型的三種深度學習方法,包括MGMSN[13]、BTSN[14]和TDCS[16]。另一種是不需要在訓練階段構建模型的學習方法,包括MAFS[18]、ASS[20]和本文方法。其中,對于深度學習方法,訓練集選用中文文本相似度數據集LCQMC[25]。這是因為構建的EB-CH語料庫和測試集的規模不足以分出一個中文文本相似度數據集用于深度學習的訓練。對比方法的運行環境見表5。
關于上述方法的測試,需要考慮測試數據集和測試結果評估兩個方面。測試數據集方面,將表2所示測試集與EB-CH語料庫分別視為兩個文本集合A和B,對兩集合進行笛卡爾積運算,則有A×B={(x,y)|x∈A∧y∈B},得到文本對(x,y)的集合。其中,x為表2所示測試集中的文本,y為EB-CH語料庫的文本。由文本對(x,y)的集合構建對比實驗的測試集。測試結果評估方面,通過邏輯或運算,將每段文本x與不同文本y的相似度評估邏輯結果融合為每段文本x的情感勒索檢測結果。
然后,對上述方法都通過調整參數和去除停用詞的方法,使它們適用于本文的情感勒索話語檢測任務。最后,對上述方法展開測試,測試結果見圖2。
從圖2可以看出:
a)本文方法的precision均低于其他方法。相比于其他方法,本文方法在語義方面只考慮表達方式一致性,無須像其他方法那樣還得考慮表達內容一致性。這意味著,本文方法把負樣本識別為正樣本的概率更大,即FP/(TP+FP)的值要高于其他方法。由式(1)可知,precision=TP/(TP+FP)=1-FP/(TP+FP)。當FP/(TP+FP)的值越高,precision的值越低。因此本文方法的precision均低于其他方法。
b)本文方法的recall均高于其他方法。受EB-CH語料庫大小限制,測試集中的部分文本只能在EB-CH語料庫中找到表達方式相似的文本,而不能找到語義一致的文本。因此,相比于其他方法,本文方法把正樣本識別為負樣本的概率更小,即FN/(TP+FN)的值要低于其他方法。由式(2)可知,recall=TP/(TP+FN)=1-FN/(TP+FN)。當FN/(TP+FN)的值越低,recall的值越高。因此本文方法的recall均高于其他方法。
c)本文方法的F1-score均高于其他方法。由式(3)可知,F1-score綜合考慮了precision和recall。因此在相似度評估方法中,本文方法最適用于EBDCH算法。
4.3 消融實驗
為了驗證相似度評估方法外的步驟(如特定代詞檢測、詞性組合檢測等)和相似度評估方法中的步驟(如停用詞去除、最近代詞檢測等)的有效性,即它們對于EBDCH算法的測試結果均有影響,開展了如下的消融實驗。首先,從描述的間接性出發,采用大寫字母組成的標簽來表示EBDCH算法的消融步驟(見表6)。其次,在上述標簽的基礎上,用Euclid SymbolXCp表示消融。例如,Euclid SymbolXCpSWR表示消融SWR代表的步驟,即停用詞去除。然后,在消融每個步驟后,需要重新進行3.1節的參數選擇實驗,選擇合適的a、b、T值。最后,依次對表6的每個步驟展開消融實驗,實驗結果如表7所示。
由表7可知,消融表6的任意步驟,都會導致EBDCH算法的F1-score顯著降低,驗證了上述步驟在EBDCH算法的有效性。
4.4 EBDCH算法的對比實驗
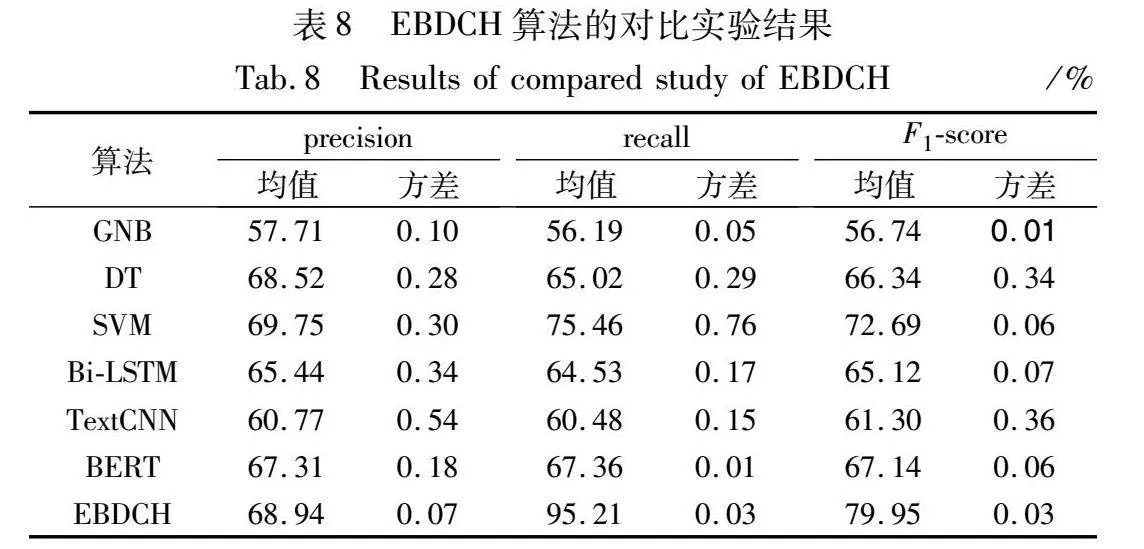
為了評估EBDCH算法的性能,本節對六種相關算法進行對比實驗,其中包括三種傳統機器學習算法:高斯樸素貝葉斯(Gaussian naive Bayes,GNB)[26]、決策樹(decision tree,DT)[27]、支持向量機(support vector machine,SVM)[28],三種深度學習算法:Bi-LSTM[15]、用于句子分類的卷積神經網絡(convolutional neural network for sentence classification,TextCNN)[29]、BERT[17]。上述六種對比算法均為在訓練階段構建分類器模型的積極學習模型,對訓練數據的需求量較大,故對EB-CH語料庫進行數據增強。
由引言可知,情感勒索話語與非情感勒索話語之間的區別主要在于語義層面,意味著要盡可能保證數據增強前后的語義一致性,否則情感勒索話語可能在數據增強后轉變為非情感勒索話語。于是,本文通過同義詞替換結合停用詞插入的方式進行數據增強,具體實現方式如下:a)基于LTP平臺[23]對文本進行分詞;b)基于OpenHowNet知識庫[24]以20%的概率進行同義詞替換;c)在詞序列的任意位置以20%的概率隨機插入哈工大停用詞表中的停用詞。通過數據增強,將EB-CH語料庫包含的情感勒索話語數量由1 136增至3 408。
分類器模型的訓練數據不僅需要正樣本(情感勒索話語),還需要負樣本(非情感勒索話語),且正負樣本的數量要盡可能接近以保證數據平衡,否則將導致模型在預測階段偏向于多數類。于是基于情感勒索話語標注規則從M3ED數據集[10]中獲取3 408句非情感勒索話語,將正樣本和負樣本整合為對比算法的訓練集。這樣形成的訓練集的總樣本數為6 816,正負樣本的比例為1∶1。
對比算法的測試集與EBDCH算法保持一致,即表2所示測試集。對比模型的運行環境采用表5所示的軟硬件環境。基于上述數據集條件和模型運行環境展開實驗,實驗結果如表8所示。
由表8可知:a)EBDCH算法的平均recall、F1-score明顯高于對比算法,平均precision僅略低于SVM,說明EBDCH算法的情感勒索話語檢測準確性優于對比算法;b)與對比算法相比,EBDCH算法的precision方差取得最優,recall和F1-score的方差取得次優,說明EBDCH算法在面對不同測試案例保持了較高的魯棒性。綜上,在對比實驗中,EBDCH算法取得了最優的情感勒索話語檢測準確性并保持了較高的魯棒性。
5 基于EBDCH的情感勒索話語檢測原型系統
5.1 系統集成
為了在日常交流場景下自動檢測情感勒索話語,提示對話參與者哪些話語包含情感勒索表達,原型系統需要具備采集對話語音、檢測對話語音中的情感勒索話語、以及顯示檢測結果三方面功能。圍繞系統的功能需求,本節搭建了硬件平臺,并設計了系統的工作流程。
圖3為原型系統的硬件平臺,其中,全向麥克風的拾音半徑為5 m,用于采集用戶對話語音。Intel NUC的型號是NUC6i7KYK,內置Ubuntu 20.04操作系統,用于處理采集到的語音數據并進行情感勒索話語檢測。觸摸屏用于原型系統的開啟和關閉,以及顯示情感勒索話語檢測結果。
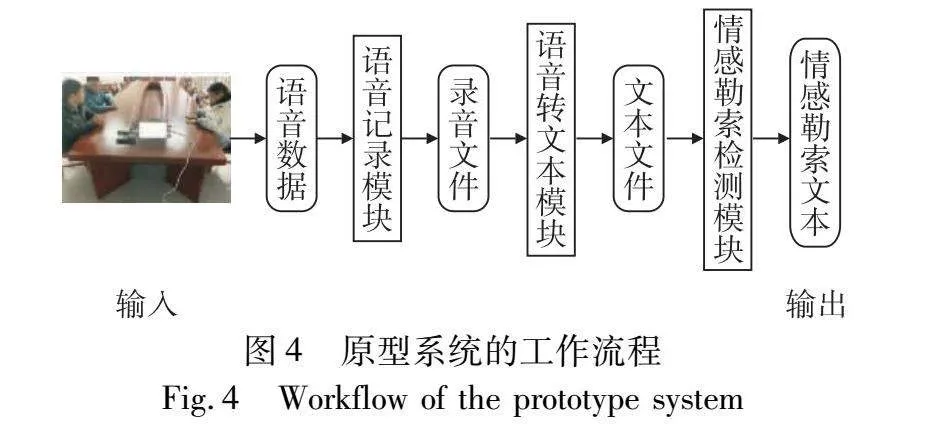
圖4為原型系統的工作流程,詳細步驟見算法4。其中,語音記錄模塊對應于步驟c)中子步驟(a)~(c),語音轉文本模塊對應于步驟c)中子步驟(d),情感勒索文本檢測模塊對應于步驟c)中子步驟(e)。在后續的系統測試中,通過設置算法4的參數,可實現對整個系統參數的設置。
算法4 情感勒索話語檢測原型系統的工作步驟
輸入:用戶實時輸入的語音Su;將實時語音存儲為錄音文件的周期Tr;錄音文件切分的靜默時長閾值Ts。
輸出:情感勒索文本集合Ceb。
a)初始化:錄音文件集合Fu=,包含完整發言的錄音文件集合Fc=,從錄音文件轉換的文本文件集合Ft=,情感勒索文本集合Ceb=。
b)開始錄音并計時。
c)時間每過去Tr:
(a)將實時語音Su存儲為錄音文件fu,并添加到集合Fu。
(b)按照時間順序,將集合Fu中的所有錄音文件拼接成一個錄音文件ftotal。
(c)檢測錄音文件ftotal的靜默時間區間,如果檢測到時間長度大于Ts的靜默時間區間:在區間中點將文件fu切分為兩個文件;把前一個文件添加到集合Fc,把后一個文件添加到集合Fu;然后跳轉步驟(b) 。
否則,把文件ftotal添加到集合Fu。
(d)對于集合Fc里的每個文件fc,基于科大訊飛平臺將錄音文件fc轉換為文本文件ft;把文件ft添加到集合Ft;刪除錄音文件fc。
(e)對于集合Ft里的每個文件ft,基于EBDCH算法在文本文件ft里檢測情感勒索文本;將檢測到的情感勒索文本添加到集合Ceb;刪除文本文件ft。
d)結束錄音和計時。
e)輸出Ceb。
為了提高算法處理效率以實現更快地輸出結果,在步驟c)中,每間隔Tr時長進行對話情感勒索話語檢測,即邊錄音邊檢測。其中,子步驟(c)的靜默時間區間檢測是通過檢測錄音文件ftotal每一時刻的聲音強度確定的。若聲音強度低于30 dB,則被視為靜默時刻。連續的靜默時刻組成靜默時間區間。如果靜默時間區間的長度大于靜默時長閾值Ts,則認為發言結束,切分出的錄音文件包含了完整的發言。
5.2 系統性能測試
在日常交流中,不同人的發言存在語義連貫性差異,前后邏輯不通的表達將影響到發言的可理解性。除此之外,不同個體之間存在發音清晰程度的差異,這將影響到語音識別的準確性。為了考察原型系統對于發言語義連貫性和發音清晰程度的魯棒性,從第1章構建的測試集中隨機選取50句正樣本和150句負樣本作為系統的測試樣本,并設計了以下三種測試方案。方案1:連續朗讀話語;方案2:每段話語朗讀結束后,停頓超過Ts,再朗讀下一段話語;方案3:連續播放話語對應的電視劇原聲。
其中,方案1與2的區別在于發言語義連貫性。前者將語義不連貫的話語混合在一起,后者通過刻意停頓使得每段發言的語意連貫。方案1與3的區別在于發音清晰程度,孰高孰低OM8wwlzE+KK++MqM7yVX+CSzpFdoIMrEhLNkum818I0=將通過以下方法比較。用deviation=Ndw/Nw表示由語音轉換的話語文本與原始話語文本之間的差異,其中,Ndw是轉換文本與原始文本中不同詞語的數量,Nw為原始文本中詞語的數量。測試過程中,計算每句測試樣本的deviation,得到兩方案的deviation分布直方圖,然后比較兩方案的deviation分布判斷哪個方案的發音清晰程度高。
結合科大訊飛平臺對輸入語音文件的要求,將系統參數設置如下。采用單聲道采樣,采樣率設為16 kHz。將實時語音存儲為錄音文件的周期Tr設為30 s,錄音文件切分的靜默時長閾值Ts設為3 s。錄音文件的格式為.wav,文本文件的格式為.txt。
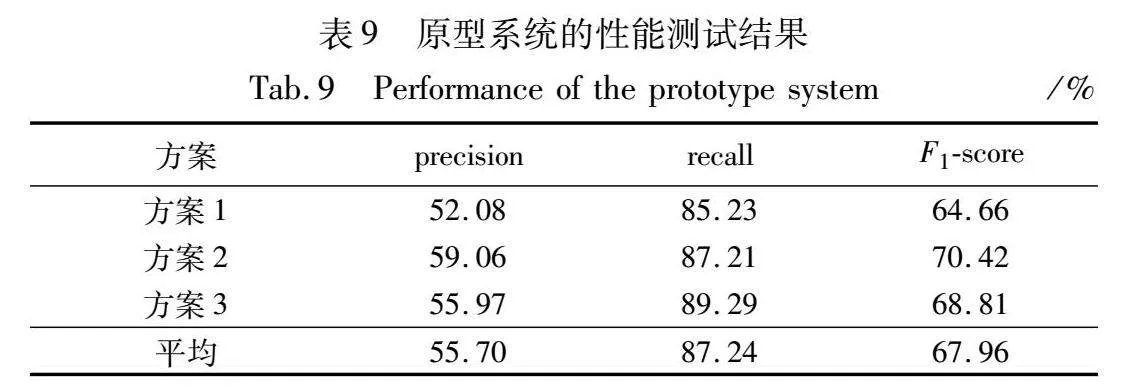
采用三種測試方案對選取的測試樣本進行測試,方案1和3的deviation分布直方圖見圖5,三種測試方案的測試結果統計見表9。
由圖5可知,與方案1相比,方案3有更多話語文本的deviation處在數值較小的區間([0,0.1),[0.1,0.2)),表明方案3語音轉文本的誤差更小,即方案3的發音清晰程度更高。
由表9可知:
a)系統的平均precision和recall分別為55.70%和87.24%。由式(1)可知, precision=TP/(TP+FP)=1-FP/(TP+FP),因此系統把標注的非情感勒索話語檢測為情感勒索話語(犯錯誤1)的概率較高,即FP/(TP+FP)的值較高。但在所有檢測出的情感勒索話語(TP+FP)中,標注的非情感勒索話語(FP)占比為44.30%,數量少于標注的情感勒索話語(TP),說明系統將犯錯誤1的概率控制在一定范圍內。由式(2)可知,recall=TP/(TP+FN)=1-FN/(TP+FN),因此系統把標注的情感勒索話語檢測為非情感勒索話語(犯錯誤2)的概率較低,即FN/(TP+FN)的值較低。比較兩種錯誤可知,犯錯誤1會呈現部分錯誤檢測結果,犯錯誤2會導致部分情感勒索話語無法被發現。在日常交流中,非情感勒索話語的數量遠多于情感勒索話語的數量。這意味著犯錯誤2會導致包含少量情感勒索話語的交流難以被發現,而犯錯誤1只會在檢測出包含情感勒索話語的交流同時呈現出一些非情感勒索話語。相比之下,犯錯誤2的嚴重程度遠高于犯錯誤1。就本文目的(檢測日常交流場景下的情感勒索話語進而改善交流效果)而言,犯錯誤2的概率應盡可能小,犯錯誤1的概率只要控制在一定范圍內即可。原型系統性能符合這一要求,說明原型系統具有良好的情感勒索話語檢測性能。
b)方案2的測試結果在三個評價指標上高于方案1,表明發言連貫性會影響到情感勒索話語檢測性能,且兩者呈現正相關趨勢。方案3的測試結果在三個評價指標上高于方案1,表明發音清晰程度會影響情感勒索話語檢測性能,且兩者呈現正相關趨勢。但縱觀每個評價指標下的測試結果,可以發現不同測試方案的測試結果與平均結果相差均低于5%,說明原型系統對于發言語義連貫性和發音清晰程度具有良好的魯棒性。
綜上,原型系統具有良好的魯棒性和情感勒索話語檢測性能。
6 結束語
為了檢測日常交流場景下的情感勒索話語進而改善交流效果,本文構建了情感勒索話語數據集,提出了基于中文文本相似度評估的情感勒索話語檢測算法EBDCH,并基于該算法集成了情感勒索話語檢測原型系統。在構建的數據集上實驗, EBDCH獲得的平均recall與F1-score優于所比較的算法,系統在不同的測試條件下表現出良好的魯棒性和檢測性能。鑒于算法和系統的precision較低,而數據集對性能有較大影響。因此,下一步工作重點是提升數據集的數據規模和數據多樣性,在此基礎上進行算法和系統的改進。
參考文獻:
[1]Forward S, Frazier D. Emotional blackmail[M]. New York: Bantam, 1997.
[2]Lo Weiyuan, Lin Yukai, Lin Chunyu, et al. Invisible erosion of human capital: the impact of emotional blackmail and emotional intelligence on nurses’job satisfaction and turnover intention[J]. Beha-vioral Sciences, 2023,13(1): article ID 37.
[3]Rooney L, John M, Morison L. Communication strategies used by women to influence male partners to seek professional help for mental health problems: a qualitative study[J]. Clinical Psychologist, 2020,24(1): 55-63.
[4]Al-Kreimeen R A, Alghafary N A, Samawi F S. The association of emotional blackmail and adjustment to college life among warned female students at Al-Balqa university students[J]. Health Psycho-logy Research, 2022,10(3): 34109.
[5]陳琦. 規訓、懲戒與救贖: PUA情感傳播中的“斯德哥爾摩效應”[J]. 現代傳播: 中國傳媒大學學報, 2020, 42(9): 52-59. (Chen Qi. Discipline, punishment and redemption: “Stockholm effect” in PUA emotional communication[J]. Modern Communication: Journal of Communication University of China, 2020, 42(9): 52-59.)
[6]李壘昂, 馬鴻超, 周清雷. 基于遷移學習的諷刺檢測[J]. 計算機應用研究, 2021, 38(12): 3646-3650. (Li Lei’ang, Ma Hongchao, Zhou Qinglei. Sarcasm detection based on transfer lear-ning[J]. Application Research of Computers, 2021, 38(12): 3646-3650.)
[7]顧艷, 夏鴻斌, 劉淵. 一種文本幽默對比的Siamese雙向GRU注意力模型[J]. 計算機應用研究, 2021, 38(4): 1017-1021. (Gu Yan, Xia Hongbin, Liu Yuan. Siamese bidirectional GRU attention model for humor text comparison[J]. Application Research of Computers, 2021, 38(4): 1017-1021.)
[8]Wu Yu, Wu Wei, Xing Chen, et al. Sequential matching network: a new architecture for multi-turn response selection in retrieval-based chatbots[C]//Proc of the 55th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2017: 496-505.
[9]Zhang Zhuosheng, Li Jiangtong, Zhu Pengfei, et al. Modeling multi-turn conversation with deep utterance aggregation[C]//Proc of the 27th International Conference on Computational Linguistics. New York: ACM Press, 2018: 3740-3752.
[10]Zhao Jinming, Zhang Tenggan, Hu Jingwen, et al. M3ED: multi-modal multi-scene multi-label emotional dialogue database[C]//Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2022: 5699-5710.
[11]Chen Yirong, Fan Weiquan, Xing Xiaofen, et al. CPED: a large-scale Chinese personalized and emotional dialogue dataset for conversational AI[EB/OL]. (2022-05-29). https://arxiv.org/abs/2205.14727.
[12]Wu Langtao, Lin Jiarui, Leng Shuo, et al. Rule-based information extraction for mechanical-electrical-plumbing-specific semantic Web[J]. Automation in Construction, 2022,135(1): article ID 104108.
[13]Wang Xin, Yang Huimin. MGMSN: multi-granularity matching mo-del based on Siamese neural network[J]. Frontiers in Bioenginee-ring and Biotechnology, 2022, 10(1): article ID 839586.
[14]Luo Jigen, Xiong Wangping, Du Jianqiang, et al. Traditional Chinese medicine text similarity calculation model based on the bidirectional temporal Siamese network[J]. Evidence-based Complementary and Alternative Medicine, 2021, 2021: article ID 2337924.
[15]Schuster M, Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE Trans on Signal Processing, 1997, 45(11): 2673-2681.
[16]Li Boyang, Xu Weisheng, Xu Zhiyu, et al. A two-domain coordinated sentence similarity scheme for question-answering robots regarding unpredictable outliers and non-orthogonal categories[J]. Applied Intelligence, 2021, 51(12): 8928-8944.
[17]Devlin J, Chang M, Lee K, et al. BERT: pre-training of deep bidirectional Transformers for language understanding[C]//Proc of the 21st Conference of the North American Chapter of the Association for Computational Linguistics. Stroudsburg, PA: Association for Computational Linguistics, 2019: 4171-4186.
[18]袁紹正, 周艷平. 基于句子的多屬性融合相似度計算方法[J]. 計算機系統應用, 2022, 31(4): 303-308. (Yuan Shaozheng, Zhou Yanping. Multi-attribute fusion similarity calculation method based on sentence[J]. Computer Systems & Applications, 2022, 31(4): 303-308.)
[19]劉萬里, 劉衛鋒, 常娟. AHP中互反判斷矩陣的區間權重確定方法[J]. 統計與決策, 2021, 37(6): 33-37. (Liu Wanli, Liu Weifeng, Chang Juan. An interval weight determination method for reciprocal judgment matrices in AHP[J]. Statistics & Decision, 2021, 37(6): 33-37.)
[20]Sun Ran, Li Xiaohong, Shen Jiacheng, et al. An effective hybrid automated Chinese scoring system for medical education[J]. Expert Systems with Applications, 2023, 234: article ID 121114.
[21]王金水, 郭偉文, 陳俊巖, 等. 多特征融合的電氣領域主觀題自動評分方法[J]. 貴州大學學報: 自然科學版, 2022, 39(2): 77-82. (Wang Jinshui, Guo Weiwen, Chen Junyan, et al. Automatic scoring method of subjective questions in electrical field based on multi-feature fusion[J]. Journal of Guizhou University: Natural Sciences, 2022, 39(2): 77-82.)
[22]Blau P M. Social exchange[J]. International Encyclopedia of the Social Sciences, 1968, 7(4): 452-457.
[23]Che Wanxiang, Feng Yunlong, Qin Libo, et al. N-LTP: an open-source neural language technology platform for Chinese[C]//Proc of the 26th Conference on Empirical Methods in Natural Language Processing: System Demonstrations. Stroudsburg, PA: Association for Computational Linguistics, 2021: 42-49.
[24]Qi Fanchao, Yang Chenghao, Liu Zhiyuan, et al. OpenHowNet: an open sememe-based lexical knowledge base[EB/OL]. (2019-01-28). http://arxiv.org/pdf/1901.09957.
[25]Liu Xin, Chen Qingcai, Deng Chong, et al. LCQMC: a large-scale Chinese question matching corpus[C]//Proc of the 27th International Conference on Computational Linguistics. New York: ACM Press, 2018: 1952-1962.
[26]Mccallum A, Nigam K. A comparison of event models for naive Bayes text classification[C]//Proc of ICML Workshop on Learning for Text Categorization. New York: ACM Press, 1998: 41-48.
[27]Quinlan J R. Induction of decision trees[J]. Machine Learning, 1986(1): 81-106.
[28]Corte C, Vapnik V. Support-vector networks[J]. Machine Lear-ning, 1995(20): 273-297.
[29]Yoon K. Convolutional neural networks for sentence classification[C]//Proc of the 19th Conference on Empirical Methods in Natural Language Processing. Stroudsburg, PA: Association for Computatio-nal Linguistics, 2014: 1746-1751.
